Cloud Spanner で初期費用を 90% 削減し、オブザーバビリティの向上とより容易なクエリを実現
Google Cloud Japan Team
※この投稿は米国時間 2021 年 5 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
ACID トランザクション、SQL サポート、そして非リレーショナル データベースのスケーラビリティと可用性を兼ね備えた強整合性のリレーショナルデータベースとして、Cloud Spanner はすべての主要な市場セグメントで力強い成長を見せています。Spanner を採用していただくお客様が増加するにつれ、「開発、テスト、小規模な本番環境のワークロードをより費用対効果の高い方法でサポートするために、より小さなサイズのインスタンスにも対応させてほしい」というご要望が寄せられるようになっていました。これを受けて、このたび Spanner のインスタンス サイズをより細かく設定できるようになったことをお知らせいたします。きめ細やかなインスタンスのサイズ設定は、まもなく公開プレビュー版で利用可能になる予定です。この機能を使用すると、Spanner でのワークロードを通常のインスタンスの 10 分の 1 のコスト(約 65 ドル / 月相当)で実行できます。
さらに、リアルタイムの分析情報を得るために運用上のサイロ化を解消し、より優れたデータベースのオブザーバビリティをデベロッパーに提供するための新しいエンタープライズ機能をリリースします。
Datastream(現在公開プレビュー版)は、企業が異種データベース間およびアプリケーション間でデータを同期できるようにする変更データ キャプチャ(CDC)サービスです。 Datastream で Spanner をサポートすることで、データを MySQL または Oracle から Spanner に確実かつ最小限のレイテンシでストリーミングできるようになります。
Spanner への BigQuery フェデレーション(近日提供予定)では、ユーザーは Spanner に存在するトランザクション データに対して、データを移動またはコピーすることなく BigQuery からクエリを実行できます。
Key Visualizer(現在公開プレビュー版として提供)は、デベロッパーが Spanner のトレンドと使用パターンをすばやく特定するためのインタラクティブなモニタリングを提供します。
きめ細かなインスタンスのサイズ設定により、アクセスの自由度を高める
現在お客様は、ワークロードを実行するために必要なノードの数を指定することで Spanner インスタンスをプロビジョニングしています。各ノードでは、最大 10,000 クエリ/秒(QPS)の読み取りまたは最大 2,000 QPS(行ごとのデータ量を 1 KB とする)の書き込みが可能で、保存容量は 2 TB です。Spanner ノードは、リージョナル インスタンスの場合は 3 つのゾーンに、マルチリージョン インスタンスの場合は 5 つ以上のゾーンに複製されます。ノード数の選択により、特定のインスタンス内のデータベースで利用可能なサービス リソースとストレージ リソースの量が決まります。
これまで Spanner では、リソースをプロビジョニングするための最小単位は 1 ノードでしたが、一層きめ細かな制御を可能にするため、処理ユニット(PU)と呼ばれる新しい単位を導入しました。Spanner の 1 ノードは 1,000 PU に相当します。今回お客様は、100 PU のバッチ単位でプロビジョニングを行い、それに比例した量のコンピューティング リソースとストレージ リソースを取得できるようになりました。これにより、Spanner 上でこれまでより小さなワークロードをはるかに低コストで実行できます。この機能では、100 PU から開始し、必要に応じてダウンタイムなしで(100 PU のバッチ単位で)最大 1,000 PU(1 ノード)までスケールアップできます。その後も、現在と同じようにノードを追加することでスケールアップを継続できます。お客様が複数のノードの容量を必要とする場合でも、リソースのプロビジョニングに PU とノードのどちらを使用するかを選択できます。
例を挙げて説明すると、あるゲーム デベロッパーが、100 PU のコンピューティング容量の Spanner インスタンス「ベースボール ゲーム」を、月額 65 ドルで us-central1 に作成したとします。
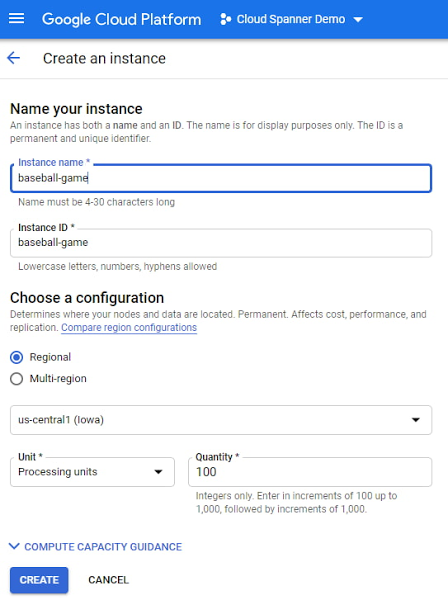
以下に示すように、205 GB の比例最大ストレージが 100 PU のインスタンスに割り当てられます。
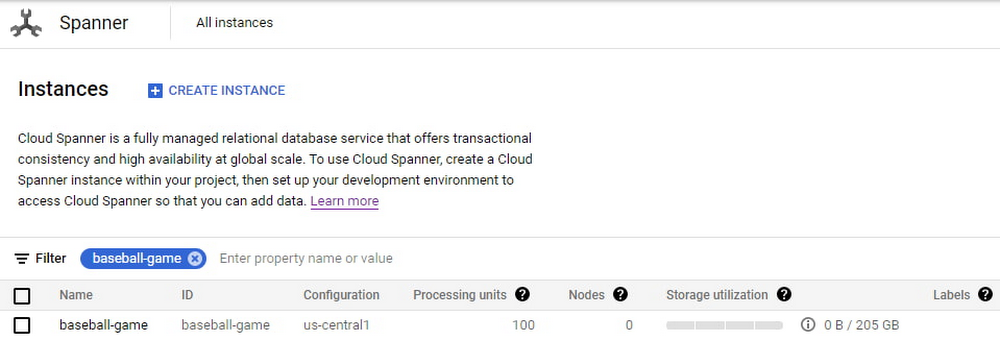
ゲームの人気が高まってきたら、このユーザーはインスタンスを編集してコンピューティング容量を 500 PU に、それに比例して最大ストレージを 1 TB に増やします。
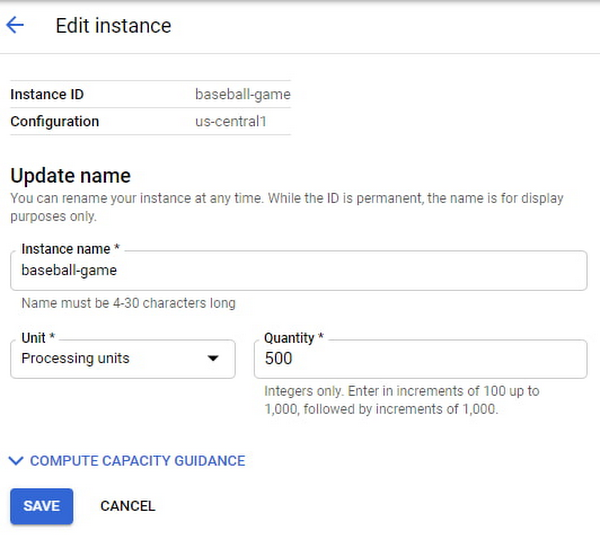
このゲームは人気が高く、ゲーム会社は、ユーザーからの要望が多い大きな新機能をゲームに導入する準備を進めています。新機能のリリース日に使用量が急増することを想定して、ゲーム デベロッパーはコンピューティング容量を 3,000 PU に増強しました。一定期間にインスタンスに割り当てられたコンピューティング容量は、Cloud Monitoring のグラフで確認できます。

アクセスをリクエスト
こちらのフォームに入力することで、詳細なインスタンス サイズ設定機能への早期アクセスをリクエストできます。
Datastream の CDC と BigQuery フェデレーションにより、運用上のサイロ化を解消
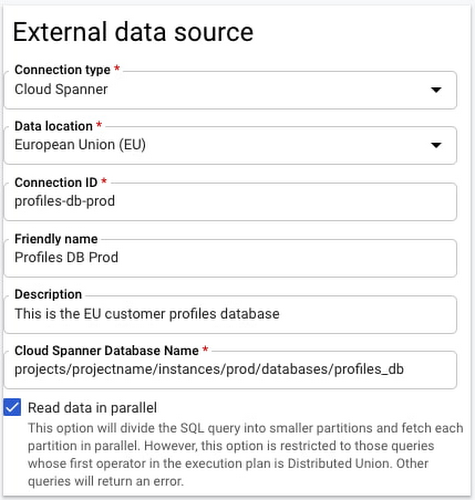
BigQuery フェデレーション。BigQuery は、複数のソースのデータをまとめてシームレスに分析を行うことで、分析の容易性を高めてきました。まもなく、Spanner のデータも BigQuery で直接分析できるようになります。Cloud Spanner の BigQuery フェデレーションでは、Cloud Spanner に存在するデータに対して、移動またはコピーをすることなくリアルタイムで即座にクエリを実行できます。以下に示すように、BigQuery の外部データソースとして Cloud Spanner を設定するだけで利用できます。
変更データ キャプチャの取り込み。現在公開プレビュー中の Datastream では、MySQL や Oracle のデータベースから Google Cloud に変更データをストリーミングできます。今回、組み込みの Dataflow テンプレートを使用して、この変更データを Cloud Spanner に直接取り込むことができるようになりました。これにより、MySQL や Oracle のデータベースから Cloud Spanner にほぼリアルタイムでデータを移行できます。
Key Visualizer によるパフォーマンスとリソース使用状況の把握
Key Visualizer は、デベロッパーと管理者が Cloud Spanner の使用パターンを分析するための新しいインタラクティブなモニタリング ツールです。あらゆるサイズのデータベースで主要なパフォーマンスとリソース指標の傾向、外れ値を明らかにし、クエリの最適化とインフラストラクチャの費用削減に貢献します。パフォーマンス チューニングとインスタンス サイズ設定のために設計された Key Visualizer は、現在公開プレビュー版として、すべての Cloud Spanner データベースのウェブベース Cloud Console で利用可能です(追加費用なし)。詳細については、Cloud Spanner Key Visualizer のブログをご覧ください。
詳細
Spanner の利用を開始するには、インスタンスを作成するか、Spanner Qwiklab でお試しください。
- Google シニア プロダクト マネージャー Vaibhav Govil

