Cloud Spanner trims entry cost by 90%, offers sharper observability and easier querying
Vaibhav Govil
Group Product Manager, Google
Customers love Cloud Spanner because it gives them the benefits of relational semantics and SQL while also delivering the scale and availability of non-relational databases. Many of these customers want to move even more of their work to Spanner, and have requested smaller instance sizes to support development, testing and small production workloads. We're happy to announce that they'll soon get what they asked for: more granular instance sizing is coming to Spanner.
Granular instance is available in Public Preview. With this feature, you can run workloads on Spanner at as low as 1/10th the cost of regular instances, equating to approximately $65/month.
In addition, we are launching new enterprise capabilities to break down operational silos for real-time insights and provide greater database observability to developers:
Datastream, now in public preview, is a change data capture (CDC) service that allows enterprises to synchronize data across heterogeneous databases and applications. With Spanner support in Datastream, users will be able to stream data from MySQL or Oracle to Spanner reliably and with minimal latency.
BigQuery federation to Spanner (coming soon) lets users query transactional data residing in Spanner, from BigQuery, without moving or copying data.
Key Visualizer, available now in public preview, provides interactive monitoring so developers can quickly identify trends and usage patterns in Spanner.
Democratizing access with more granular instance sizing
Today, customers provision Spanner instances by specifying the number of nodes they need to run their workloads. Each node can provide up to 10,000 queries per second (QPS) of reads or 2,000 QPS of writes (writing single rows at 1 KB of data per row) and 4 TB of storage. A Spanner node is replicated across 3 zones for regional instances, and 5 or more zones for multi-regional instances. The choice of node count determines the amount of serving and storage resources that are available to the databases in a given instance.
Historically, the most granular unit for provisioning resources on Spanner has been one node. To enable more granular control, we are introducing Processing Units (PUs); one Spanner node is equal to 1,000 PUs. Customers can now provision in batches of 100 PUs, and get a proportionate amount of compute and storage resources. This will allow teams to run smaller workloads on Spanner at much lower cost. With this feature, customers can start at 100 PUs and scale up as needed in batches of 100 PUs, to up to 1,000 PUs (1 node), all with zero downtime. Subsequently, customers can continue to scale up by adding more nodes, just like what they do today. Customers do have the choice of using either PUs or nodes to provision resources within workloads, when those workloads occupy multiple nodes of capacity.
To illustrate with an example, let’s say a game developer creates a Spanner instance called “baseball-game” in us-central1, with 100 PU compute capacity at $65/month price.
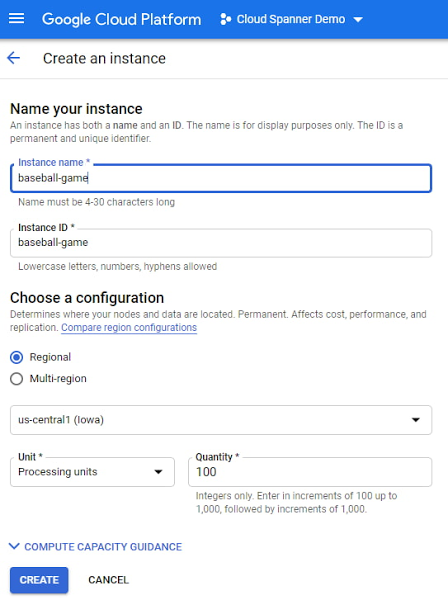
As you can see below, proportional maximum storage of 205 GB is assigned to the 100 PU instance.
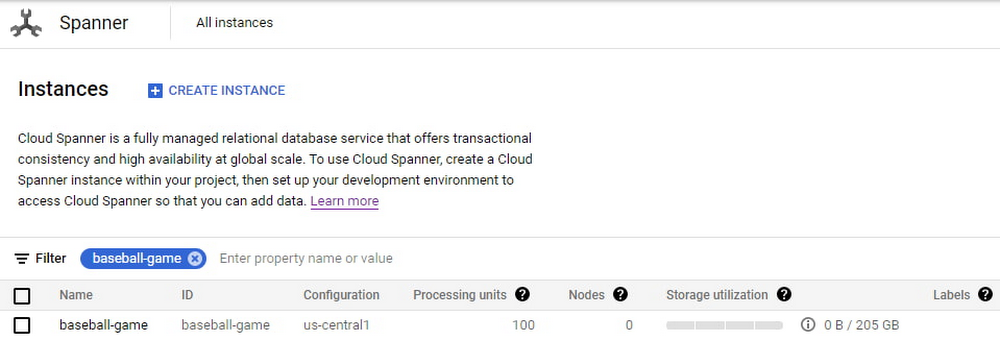
Once the game starts becoming popular and resource demands increase, the user edits the instance to increase the compute capacity to 500 PUs with proportional maximum 1 TB of storage.
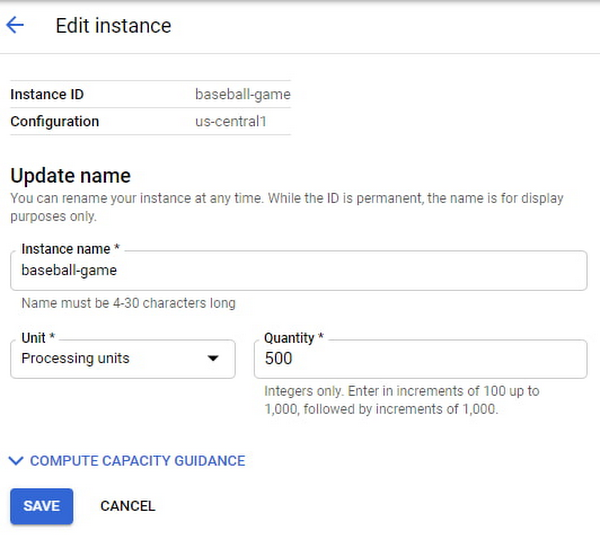
The game grows in popularity, and the gaming company prepares to launch a much-awaited capability in the game. Anticipating a sharp increase in usage at launch day, the game developers increase the compute capacity to 3,000 PUs. Compute capacity assigned to the instance over a period of time can be viewed in Cloud Monitoring graphs:

Request Access
You can request early access to granular instance sizing feature by filling this form.
Breaking down operational silos with Datastream CDC and BigQuery federation
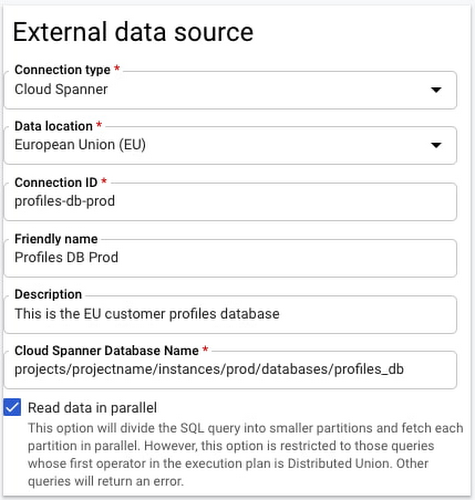
BigQuery Federation. BigQuery has made analytics easy by bringing together data from multiple sources for seamless analysis. Soon you’ll also be able to analyze data in Spanner directly in BigQuery. With Spanner’s BigQuery federation, you’ll be able to instantly query data residing in Spanner in real-time without moving or copying the data. Simply set up the Spanner as an external data source in BigQuery, as shown below.
Change Data Capture ingest. Now in public preview, Datastream lets you stream change data into Google Cloud from MySQL and Oracle databases. As of today, you can ingest this change data directly into Spanner using a built-in Dataflow template. This lets you migrate data from MySQL and Oracle databases into Spanner in near-real time.
Understanding performance and resource usage with Key Visualizer
Key Visualizer is a new interactive monitoring tool that lets developers and administrators analyze usage patterns in Spanner. It reveals trends and outliers in key performance and resource metrics for databases of any size, helping to optimize queries and reduce infrastructure costs. Designed for performance tuning and instance sizing, Key Visualizer is available today in public preview in the web-based Cloud Console for all Spanner databases at no additional cost. Learn more in the Key Visualizer blog.
Learn more
To get started with Spanner today, create an instance or try it out with a Spanner Qwiklab.


