Key Visualizer で大規模な Cloud Spanner パフォーマンス指標を把握する
Google Cloud Japan Team
※この投稿は米国時間 2021 年 5 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
Cloud Spanner は、大規模な可用性と整合性のために設計された、分散型リレーショナル データベースです。よく知られた Google プロダクトと同様に、金融サービス、小売、ゲームなど多くの業種の組織において、特に要求の厳しい「事業経営」ワークロードに Spanner も利用されています。これらのアプリケーションを実行している開発およびオペレーション(DevOps)のチームは、Spanner がどのようにコンピューティング リソースやストレージ リソースを使用して使用量のサイズ設定とスキーマやクエリの最適化を行っているのか把握する必要があります。
Google ではこのたび、Spanner の使用パターンを分析する新しいインタラクティブ モニタリング ツール、Key Visualizer をリリースいたします。このツールにより、あらゆるサイズのデータベースにおいて、重要なパフォーマンスおよびリソース指標の傾向や外れ値を把握できるようになります。パフォーマンス チューニングとインスタンス サイズ設定のために設計されたこの Key Visualizer は、すべての Spanner データベースのウェブベース Cloud Console で、追加費用なしで今すぐご利用いただけます。現時点では一般公開プレビュー版として提供されています。
スケーラビリティと可用性を高めるためのデータ パーティショニング
ほとんどの分散システムと同様に、Spanner は、リージョン構成またはマルチリージョン構成内の複数のマシンにまたがるデータおよび処理のパーティショニングを行います。ただし、通常のスケールアップ データベースとは異なり、Spanner ではパーティションが自動で管理され、脆弱な手動によるシャーディングなしでスケールアウトします。テーブルを動的にスプリット(さらに小さい行範囲)へとパーティショニングし、分離インフラストラクチャ全体にそれらのスプリットを複製することによって、Spanner は最大で 99.999% の可用性を実現します。これは、あらゆるスケールアウト リレーショナル データベースの中で最も高い値です。
行がどのスプリットに含まれるかは、その行の主キーによって決まります。適切なキーを選択すると、Spanner がデータと処理を均等に分散できるようになるため、同一リソース(データにアクセスするための I/O やクエリを実行するための CPU など)を求めて複数の行が競合するホットスポットを回避できます。リソースがデータベースのキー空間全体でどのように使用されるかを把握することにより、データおよびそれにアクセスするワークロードのパターンも明らかになり、サイズ設定とプロビジョニングについての情報が得られます。
Key Visualizer はそのような場合に役立ちます。
使用パターンの把握
以下のスクリーンショットは、Key Visualizer の動作例を示しています。
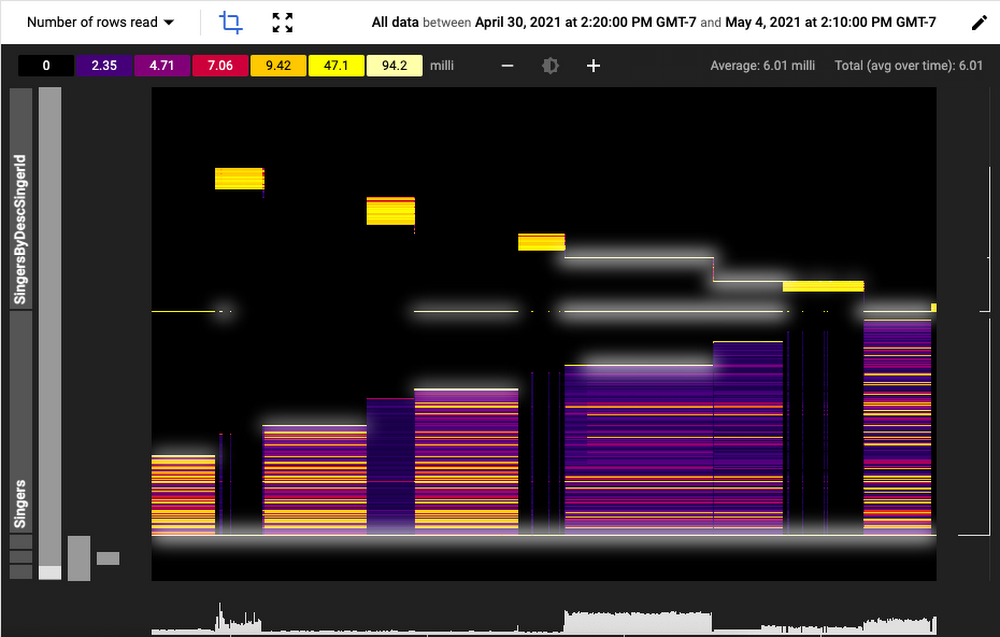
この図では、リソースとパフォーマンスの指標が 3 つの項目とともに表示されています。
時間は X 軸で表されています(この図では「時間」単位)。
キー空間は Y 軸で表されます。現在のデータベース内のすべてのテーブルとインデックスにまたがるすべての行が、最大 1,000 個の順序付けられた行範囲に分割されます。範囲は、テーブルまたはインデックスごとに階層化されて表示されます。
Key Visualizer では、時間と行範囲の各交点について、たとえば書き込まれたバイト数などの指標の集計値が示されます。Key Visualizer は、ただ数字を示すだけでなく、その指標の値範囲の高低を色のスペクトラムで表します。低い値すなわち「冷たい」値は暗い青や紫で表示され、「熱い」値は黄色や白で表示されます。値のスペクトラムとそれぞれに対応する色については、ヒートマップの上に示されています。
この小型のディスプレイによって、個別の数万個の測定値に関する傾向や外れ値を迅速に識別できます。たとえば、前述のヒートマップでは、SingerByDescSingerID インデックス上の高負荷読み込みトラフィックが斜めのパターンになっています。これを、クエリ統計に表示される高レイテンシ クエリ向けの実行プランと相互参照すると、ボトルネックの推測に役立つ場合があります。
切り抜きツールを使ってヒートマップの特定部分に焦点を当て、より詳細な分析、パン、ズームをインタラクティブに行えます。測定値にカーソルを合わせると、その値やその他の詳細が表示されます。
利用可能な指標
Key Visualizer では、それぞれの行範囲および時間枠について、6 種類の指標が自動的に集計されます。これらの集計値は各行範囲の行数によって正規化され、時間とキー空間にわたって相対値が比較されます。左上隅のプルダウンから、表示する指標を選択できます。
CPU 秒数: 行範囲に対する読み書きにかかったおおよその合計時間。
保存された論理バイト数: 使用されたストレージの実効合計量。まだクリーンアップされていない複数バージョンの更新済みデータが含まれる。
読み込み行数: SQL クエリまたは Spanner の読み取り API によってアクセスされた行の数。
読み込みバイト数: 読み込まれた行の合計サイズ。
書き込み行数: SQL DML または Spanner の Mutation API を使用して更新された行の数。
書き込みバイト数: 書き込まれた行の合計サイズ。
ホットスポットのデバッグ
Key Visualizer のキーのメリットの 1 つとして、ホットスポットをピンポイントで特定できることが挙げられます。ホットスポットとは、少数の行範囲によってリソースが過剰に使用されている場所を指します。それにより、他のアクティビティのリソースが不足し、ボトルネックが生じます。ヒートマップでは、ホットスポットは明るい色で水平または斜めの領域として表示されます。ヒートマップ内で明るい色の領域がホットスポットを示している可能性がある一方、健全でアクティブなデータベースは通常、明るい色が時折筋状で出現し、明暗色が適度に分散し混ざり合った状態で表されます。ホットスポットについてはプロダクトのドキュメントで詳細に説明されていますが、Key Visualizer で遭遇する可能性のあるパターンのタイプについて、以下に簡単な概要を示します。
たとえば、持続的に他の範囲より熱い、異なる 2 つの行範囲は、以下のように表されます。

ホットスポットは、多くの場合、断続的に現れます。次の例を見てみましょう。

この図は、2 つの行範囲に集中している突然のアクティビティ バーストを示しています。この原因としては、不正クエリを生じさせるアプリケーション バグ、行キーの分散状況に影響するスキーマ変更、新しいトラフィック パターンのインジケーターなどが考えられます。
しかし、最も一般的なのは、行範囲の経時的パターンが斜めまたは三角形になる状態です。

斜めの線は、データがキーごとに順次アクセスされていることを示します。これは、テーブル全体のスキャンに相当する一括エクスポート、または数字のシーケンスを使用して次のキーを決定する挿入の結果として、生じたと考えられます。順序付けられたキーは、分散したインフラストラクチャ全体の整合性に対処する必要のない典型的な単一インスタンス データベースでは多く見られますが、Spanner では一般にアンチパターンとされます。Spanner ではキーを使用してデータのパーティショニングを行うため、近接して連続するキーを持つ行を挿入または更新すると、多くの場合、リソース競合につながります。ベスト プラクティスとしては、適切に分散した合成主キー(UUID など)を使用し、必要に応じて別の列に自然キー(オーダー番号またはユーザー名など)を維持することをおすすめします。アプリケーションが頻繁に自然キーをフィルタする場合または自然キーと結合する場合には、自然キーをインデックス登録することもできます。
次のステップ
Key Visualizer は、管理者やデベロッパーがアプリケーションと Spanner とのインタラクションをより深く理解するために使用できる、新しいツールです。Spanner の既存のイントロスペクションおよびモニタリング機能セットを補完して、パフォーマンス最適化とリソース管理を簡易化します。Key Visualizer は、現在公開プレビュー版として提供されています。Cloud Console から有効化できます。
- Cloud Spanner プロダクト マネージャー、Justin Makeigr
- Cloud Spanner ソフトウェア エンジニア、Hailong Wen



