Cloud Spanner の変更ストリームでインターネット スケールのイベント ドリブン アプリケーションを構築する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 8 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
そのリリース以来、Cloud Spanner の変更ストリームは、ヘルスケア、小売、金融サービスをはじめとする各業界の Spanner ユーザーに幅広く採用されてきました。
このブログ投稿では、Cloud Spanner の変更ストリームに関する最新のアップデートの概要と、それを使用したイベント ドリブン アプリケーションの構築方法について説明します。
変更ストリームは、Spanner データベースに対する変更(挿入、更新、削除)を監視し、その変更を準リアルタイムでストリーミングするサービスです。変更ストリームの一般的な用途として、分析を目的とした Spanner データの BigQuery への複製が挙げられます。データ定義言語(DDL)を記述して目的のテーブルに変更ストリームを作成し、変更を BigQuery に複製するように Dataflow を構成するだけで、BigQuery の高度な分析機能を活用できるようになります。
とはいえ、分析は、変更ストリームによって実現される内容の一端にすぎません。Pub/Sub と Apache Kafka は、メッセージを生成するサービスとそのメッセージを処理するサービスを分離する非同期でスケーラブルなメッセージ サービスです。このたび、Pub/Sub と Apache Kafka のサポートにより、お客様は Spanner の変更ストリームを通じて Spanner のトランザクション データを使用し、イベント ドリブン アプリケーションを構築できるようになりました。
イベント ドリブンなアーキテクチャの例としては、注文があるたびに在庫管理システムの在庫の更新がトリガーされる注文システムが挙げられます。この例では、注文は order_items というテーブルに保存されます。したがって、このテーブルに変更があれば、在庫システムでイベントがトリガーされます。
order_items に対するすべての変更を追跡する変更ストリームを作成するには、次の DDL ステートメントを実行します。
変更ストリーム order_items_changes が作成されたら、Pub/Sub および Kafka に対するイベント ストリーミング パイプラインを作成できます。
Pub/Sub に対するイベント ストリーミング パイプラインの作成
変更ストリーム Pub/Sub Dataflow テンプレートを使用すれば、変更イベントを Spanner から Pub/Sub に送信し、この種のイベント ストリーミング パイプラインを構築する Dataflow ジョブを作成できます。
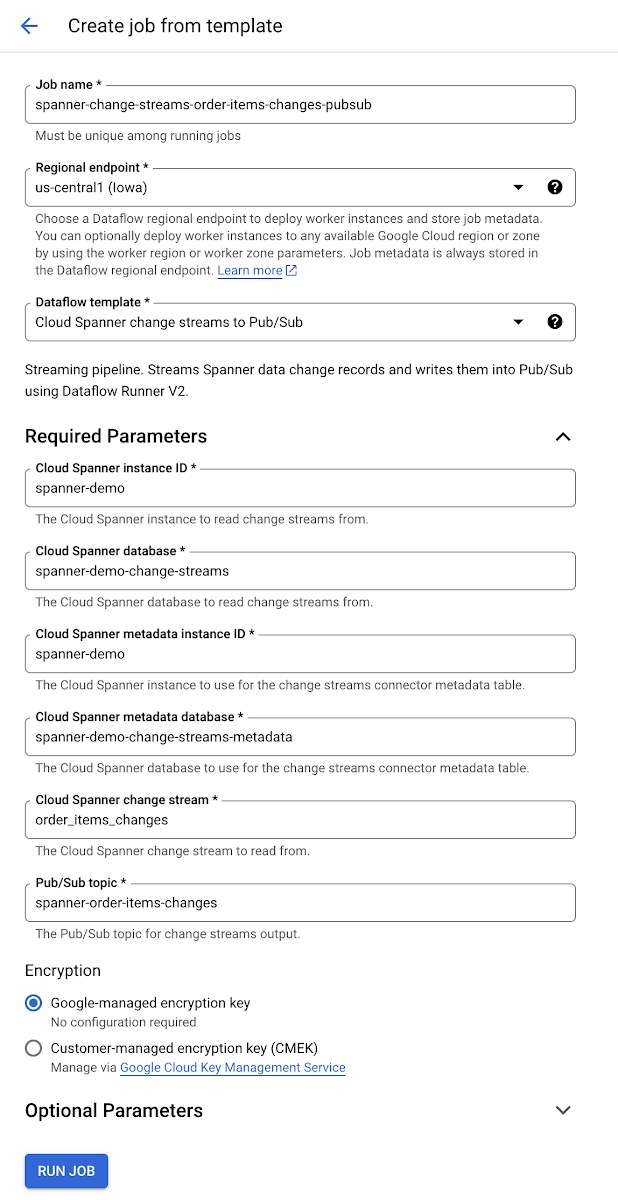
Dataflow ジョブが実行されたら、Spanner データベースに注文のアイテムを挿入して更新することで、在庫の変更をシミュレートできます。
これにより、2 つの変更レコードが Dataflow を通じてストリーミングされ、指定された Pub/Sub トピックにメッセージとしてパブリッシュされます。具体例は以下のとおりです。

最初の Pub/Sub メッセージには在庫の挿入が含まれており、2 番目のメッセージには在庫の更新が含まれています。

ここから、Pub/Sub が提供する多くのインテグレーション オプションを通じてデータを使用できます。
Apache Kafka に対するイベント ストリーミング パイプラインの作成
多くのイベント ドリブンなアーキテクチャでは、Apache Kafka が中心的なイベントストアおよびストリーム処理プラットフォームとして使用されています。新しく追加された Debezium ベースの Kafka コネクタを使用すれば、Spanner の変更ストリームと Apache Kafka を使ってイベント ストリーミング パイプラインを構築できます。
Kafka コネクタは、挿入、更新、削除のたびに変更イベントを生成し、各 Spanner テーブルのグループ単位の変更イベント レコードを個々の Kafka トピックに送信します。次に、クライアント アプリケーションは、対象のデータベース テーブルに対応する Kafka トピックを読み取ることで、そのトピックから受信するすべての行レベル イベントに反応できます。
コネクタにはフォールト トレランスが組み込まれています。変更を読み取ってイベントを生成する際に、コネクタは、処理された直近の commit タイムスタンプを変更ストリームのパーティションごとに記録します。コネクタがなんらかの理由(通信障害、ネットワークの問題、クラッシュなど)で停止した場合、再起動すると、最後に停止したところからレコードのストリーミングが再開されます。
Kafka の変更ストリーム コネクタについて詳しくは、Kafka への変更ストリームの接続についてのページをご覧ください。Kafka の変更ストリーム コネクタは Debezium からダウンロードできます。
新しい値キャプチャ タイプを使用したイベント メッセージの微調整
上述の例では、変更ストリーム order_items_changed にデフォルトの値キャプチャ タイプ OLD_AND_NEW_VALUES が使用されていました。これは、変更ストリームの変更レコードには、ある行の変更された列の新旧の値と、その行の主キーが含まれることを意味します。しかし、データの変更に関わるすべての要素をキャプチャする必要がない場合もあります。そこで、2 つの新しい値キャプチャ タイプ NEW_VALUES と NEW_ROW を追加しました。具体的には次のとおりです。
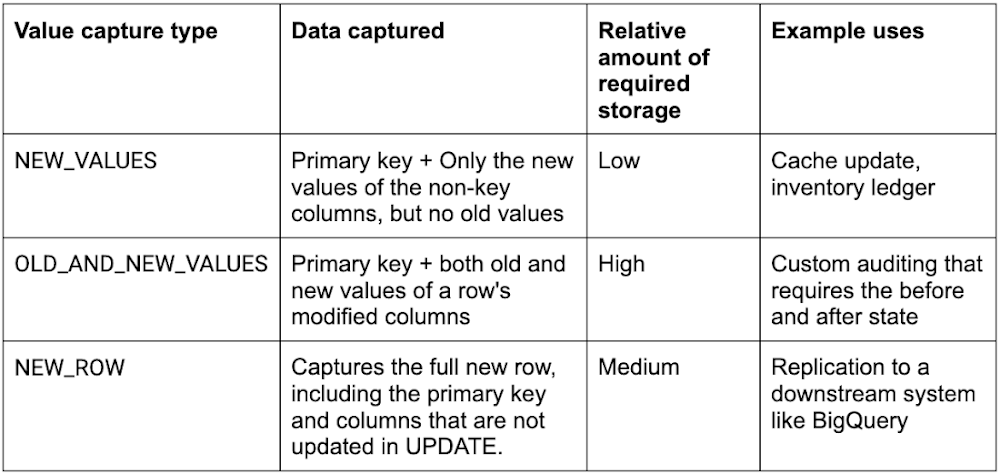
これまでの例で説明を続けられるように、変更後の列の新しい値のみを含む別の変更ストリームを作成します。これは、メモリとストレージのフットプリントが最も小さい値キャプチャ タイプです。
上記の DDL では、PostgreSQL Interface 構文を使用して変更ストリームを作成しています。PostgreSQL と GoogleSQL で Spanner データベースの変更ストリームを作成する DDL について詳しくは、変更ストリームを作成、管理するをご覧ください。
まとめ
変更ストリームを使うと、目的が BigQuery での分析、ダウンストリーム アプリケーションのイベントのトリガー、コンプライアンス、アーカイブのいずれであっても、必要な場所で Spanner のデータを利用できます。また、Spanner に組み込まれている機能であるため、ソフトウェアをインストールせずに外部整合性、高いスケーラビリティ、最大 99.999% の高可用性を得ることができます。
Pub/Sub と Kafka のサポートにより、Spanner の変更ストリームがあれば、お客様のビジネスに必要な柔軟性を備えたイベント ドリブン パイプラインをこれまで以上に簡単に構築できるようになります。
Spanner の利用を始めるには、インスタンスを作成して無料で試用するか、または Spanner の Qwiklabs を受講してください。
Spanner の変更ストリームについて詳しくは、変更ストリームについてをご覧ください。
Pub/Sub の変更ストリーム Dataflow テンプレートについて詳しくは、Cloud Spanner change streams to Pub/Sub テンプレートをご覧ください。
Kafka の変更ストリーム コネクタについて詳しくは、Kafka への変更ストリームの接続についてのページをご覧ください。
- シニア プロダクト マネージャー Mark Donsky