Cloud Spanner 向け Query Insights のご紹介: 事前構築されたダッシュボードでパフォーマンス問題のトラブルシューティングを行う
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
今日、アプリケーション開発チームはよりアジャイルになり、以前より速く機能を提供するようになっています。こうした迅速な開発サイクルとマイクロサービス アーキテクチャの台頭に加え、機能開発(およびパフォーマンス モニタリング)のエンドツーエンドのオーナーシップは、上級データベース管理者とフルスタック デベロッパーの責任共有モデルへと移行しています。しかし、ほとんどの開発者は、複雑なクエリのパフォーマンス問題をデバッグするために必要な長年の経験や時間を備えていません。そのため、データベース管理者は、今やほとんどの組織で希少なリソースとなっています。その結果、開発者と DBA の両方がパフォーマンス問題を迅速に診断するためのツールが切実に求められています。
Spanner 向け Query Insights のご紹介
この度リリースされた Spanner 向け Query Insights は、開発者やデータベース管理者が Spanner 上のクエリ パフォーマンスの問題を迅速に診断するための簡単な方法を提供する可視化ツールのセットです。Query Insights を使用することで、ユーザーはセルフサービス方式でクエリのパフォーマンスをトラブルシューティングできるようになりました。Query Insights は、Spanner 上でクエリのパフォーマンスに関する問題をデバッグするすべての人に直感的な体験を提供するために、世界水準の可視化機能と使い慣れたデザイン パターンを使用して設計されています。Query Insights は追加費用なしで利用できます。
すぐに使える視覚的なダッシュボードやグラフを使用することで、開発者は時系列でさまざまなパフォーマンス指標の浮き沈みといった異常な動作を可視化し、問題のあるクエリを迅速に特定できます。時系列データは、重要なリアルタイムおよび過去の指標の分析を可能にするため、組織に大きな価値を提供します。データは、理解しやすいものであってこそ価値があります。直感的なダッシュボードを表示することは、時系列データをチーム全体に公開しようとする企業にとって大きな力となります。
事前構築済みのダッシュボードを使った視覚的な手順
Query Insights を使用することで、開発者はデータベースのパフォーマンスの問題の検出から問題のあるクエリの診断まで、単一のインターフェースでシームレスに行うことができます。Query Insights は、事前構築済みのダッシュボードにより、クエリのパフォーマンスに関する問題を容易に特定できます。
ユーザーは、クエリのパフォーマンスに関する問題をすばやく確認、特定、分析できる簡単な手順を踏むことで、これを実現できます。例を見ていきましょう。
データベースのパフォーマンスを理解する
この手順は、ユーザーが Google Cloud Monitoring で CPU 使用率があるしきい値を超えた場合のアラートを設定するところから始まります。アラートは、このしきい値を超えると、「モニタリング」ダッシュボードへのリンクとともに、メール通知アラートでユーザーに通知されるように構成できます。
このアラートを受け取ったユーザーは、メールに記載されたリンクをクリックし、「モニタリング」ダッシュボードに移動することになります。CPU 使用率が高く、読み込みのレイテンシが高い場合、根本的な原因はコストの高いクエリである可能性があります。CPU 使用率の急増は、非効率的なクエリによって、システムが通常よりも多くのコンピューティングを使用していることを示す強いシグナルである可能性があります。
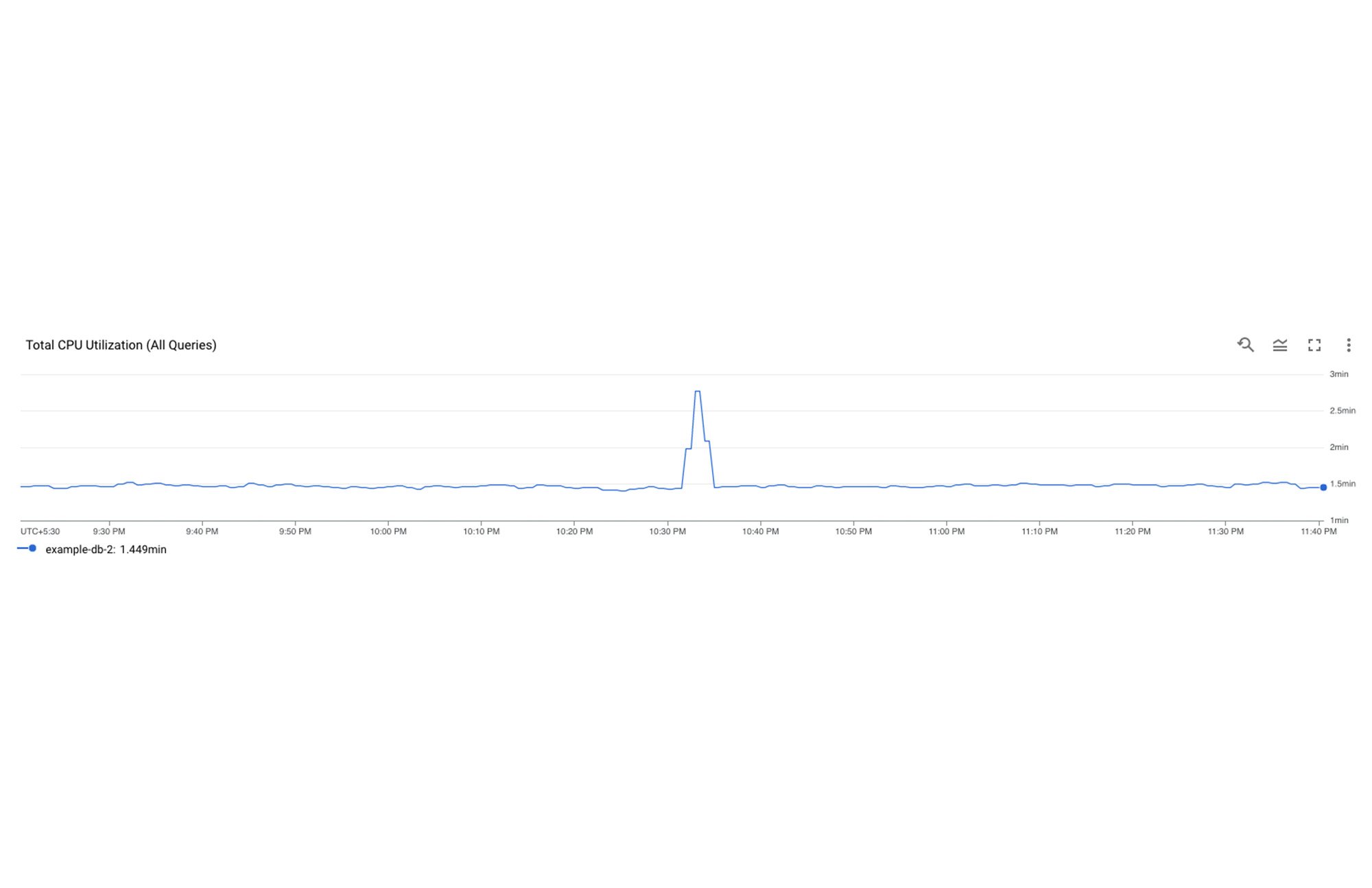
次のステップは、どのクエリに問題があるかを特定することです。ここで、Query Insights の出番です。Spanner インスタンスの左側のナビゲーションにある「Query Insights」をクリックすると、このツールにアクセスできます。ここでは、クエリごとの CPU 使用率を掘り下げて、特定のデータベースで CPU 使用率(すべてのクエリに起因する)が特定の時間枠で急増していることを観察できます。これにより、CPU 使用率の急増が非効率なクエリによるものであることが確認されました。
問題のあるクエリを特定する
ユーザーは、TopN(CPU 使用率上位のクエリ)のクエリグラフを観察して、CPU 使用率別に TopN クエリを確認します。このグラフから、CPU 使用率の急上昇の原因となっている上位のクエリを可視化し、特定することは非常に簡単です。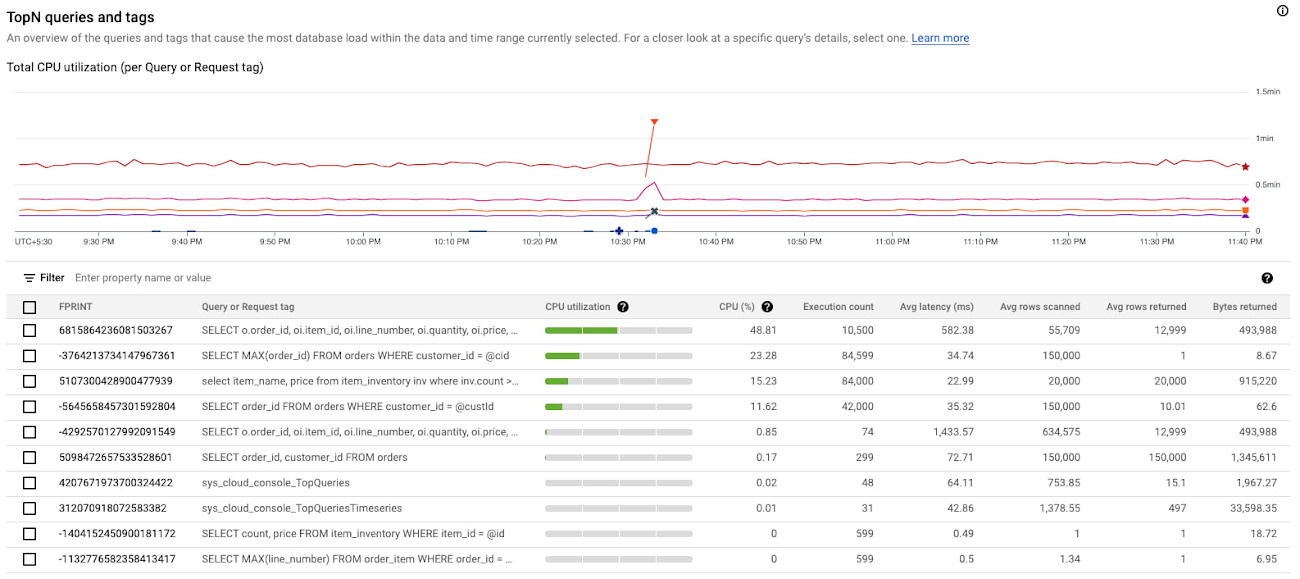
上記のスクリーンショットでは、テーブルの最初のクエリが午後 10 時 33 分に明らかに急増し、CPU 全体の 48.81% を消費していることがわかります。これはクエリに問題がある可能性を示すものであるため、ユーザーはさらに調査する必要があります。
クエリ パフォーマンスの解析
問題のあるクエリを特定したら、今度はこのクエリの形状を掘り下げて確認し、CPU 使用率が高い根本原因を特定できます。
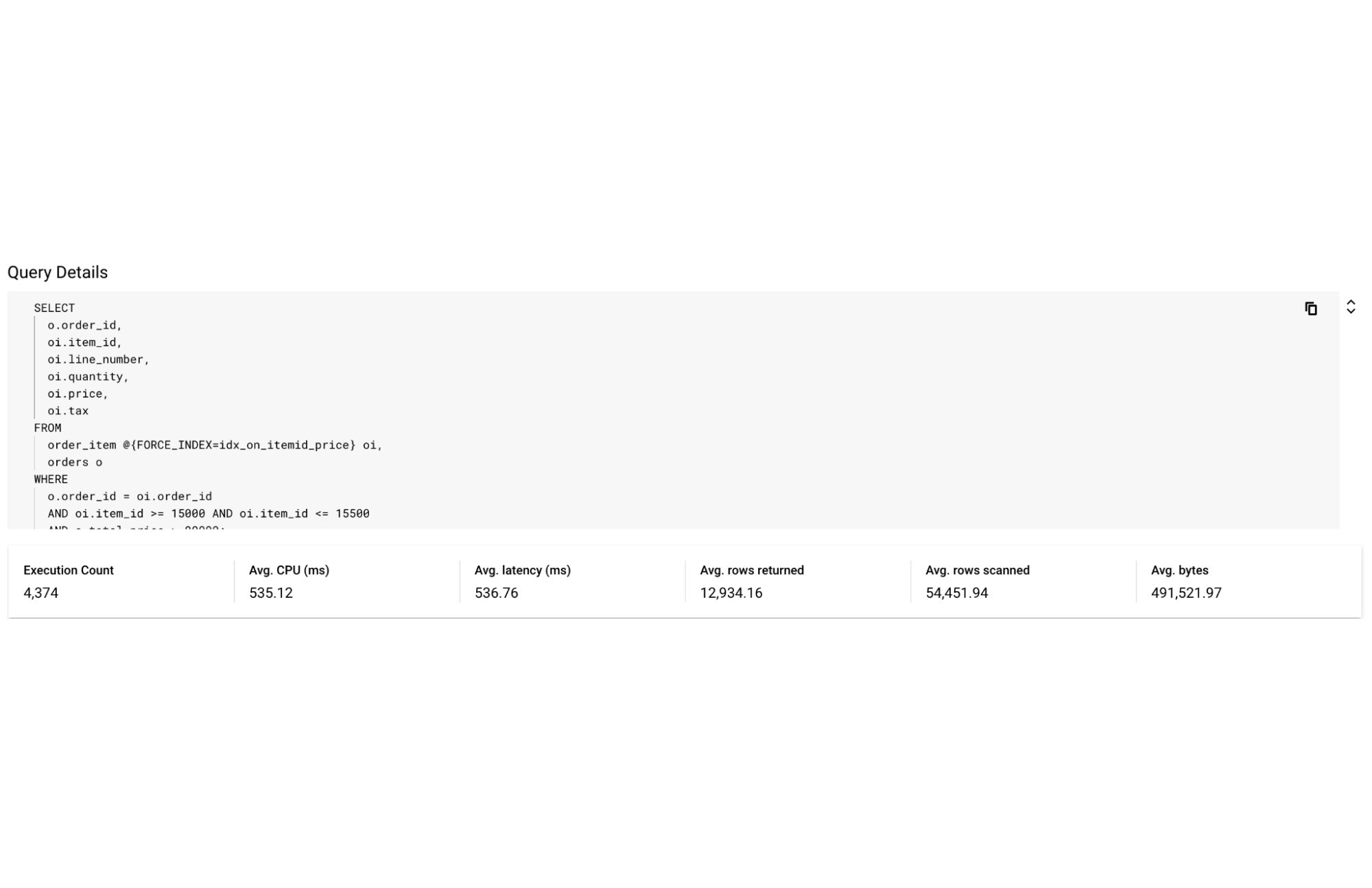
topN テーブルから特定のクエリの Fingerprint ID をクリックし、「クエリの詳細」ページに移動すると、特定のクエリの時系列での指標(レイテンシ、CPU 使用率、実行回数、スキャンされた行数 / 返された行数)のリストが表示されます。
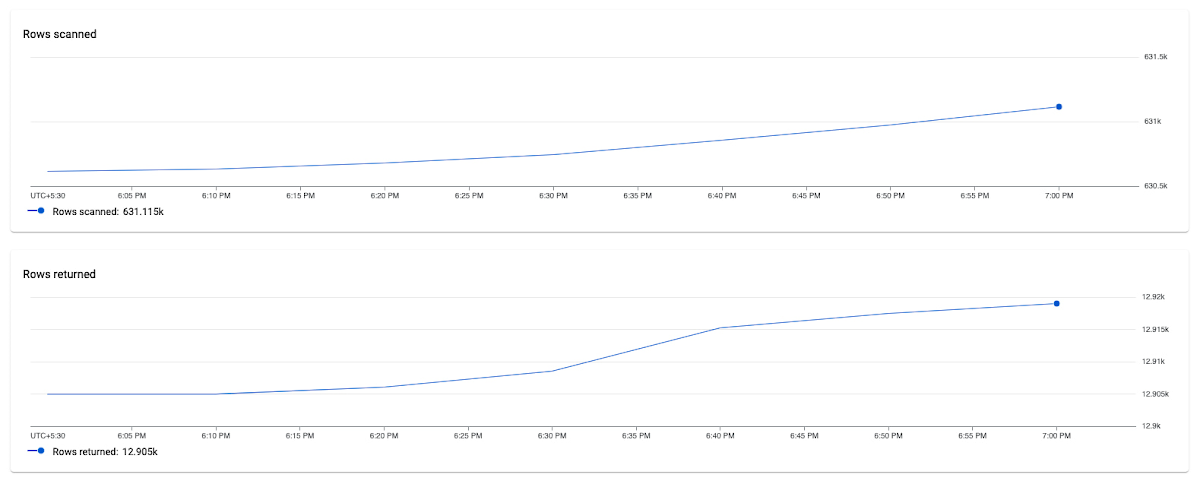
この例では、このクエリでスキャンされた平均行数が非常に高いことがわかります(約 12,000 行を返すのに約 60 万行をスキャン)。これは、クエリの設計が不適切で、非効率なクエリになっている可能性を示しています。また、このクエリではレイテンシが高い(1.4 秒)ことも確認できます。
問題の解決
このシナリオの問題を解決するには、FORCE_INDEX のクエリヒントを使用してクエリで セカンダリ インデックスを指定し、インデックス ディレクティブを提供することでこのクエリを最適化できます。これにより、より安定したパフォーマンスが得られ、クエリの効率が上がり、このクエリの CPU 使用率が下がります。
下のスクリーンショットでは、クエリにインデックスを指定すると、CPU、スキャンした行数(54,000 対 630,000)、クエリのレイテンシ(536 ナノ秒対 1.4 秒)の点でクエリの性能が劇的に向上していることがわかります。
最適化されていないクエリ:

最適化されたクエリ:
このシンプルで視覚的な手順に従うことで、ユーザーは Spanner 上で非効率なクエリを簡単に検出、診断、デバッグできます。
今すぐ Query Insights を使い始める
Query Insights の詳細については、こちらのドキュメントを参照してください。Query Insights はデフォルトで有効になっています。Spanner コンソールでは、左側のナビゲーションにある Query Insights をクリックすると、クエリのパフォーマンス指標の可視化を開始できます。
Spanner 初心者の方へ 新しいデータベースを数分で使い始めることができます。- プロダクト マネージャー Mohit Gulati


