Database Migration Service による接続 - 技術的考察

Google Cloud Japan Team
※この投稿は米国時間 2020 年 11 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
新しくリリースされたプロダクト、Database Migration Service(DMS)についてはすでにご存じかと思います。まだご存じない場合は、発表のブログ記事をご覧ください。要約: このサービスは、データベースをフルマネージドの Cloud SQL インスタンスに可能な限り簡単かつ安全に移行することを目的としたサービスです。
この投稿では、MySQL(プレビューで利用可能)と PostgreSQL(リクエストによりプレビューで利用可能、このリンクからご登録ください)について詳しく説明します。SQL Server をわざと無視しているわけではありません。このブログの執筆時点で、DMS がまだ SQL Server をサポートしていなかったためですが、今後サポートされる予定です。サポート開始のアナウンスがあるまで、少しお待ちください。
さて、クラウドに移動するデータベースがあるとします。あるいは、クラウドにあるものの、Cloud SQL による管理はされていないデータベースがあるとします。ここで少し雑談しましょう。
データストアの移行を決定し、そのためにアプリケーションを準備するのには多くの作業が必要になります。この投稿は、移行をすでに決定していること、DMS を評価している(または評価を完了して実行する準備ができている)こと、アプリケーションのカットオーバー移行を行ってデータベースの移行が完了した暁には、アプリケーションを新しい Cloud SQL インスタンスに適用する準備ができていることを前提にしています。
今日は接続についてお話しします。わかります。問題はいつも DNS ですよね。でも、万が一 DNS が問題ではなかったらどうですか?話を続けましょう。DMS は、組織のセキュリティ ポリシーを満たしつつ、ソースとマネージド Cloud SQL データベース間の接続を管理する方法について、固有のニーズに対応するための「ドアノブ」をいくつか設けてプロセスをガイドするものです。
ところで、接続について深入りする前に、するべきこと、考えるべきことがある、と声を大にして言わせてください。移行に向けてデータベースとアプリケーションの準備内容を検討し、また DMS による移行が完了した後の次のステップを理解しておく必要があるのです。これらのトピックについて詳細に説明する、他のいくつかのブログをよく探してみてください。特に、同種移行に関するベスト プラクティスのブログに目を通しておけば、次のセクションにうまくつながります。
先制トラブルシューティング
準備に関する非常に重要な要素について、いくつか強調させてください。それらを見逃すと失敗するからです。それらの項目は、上にリンクを示したブログに詳細な説明があります。また、移行に必要な構成として DMS の UI にも含まれています。とても重要なので繰り返しチェックしてください。
server_id の構成
MySQL を移行する場合、ソース データベースの server_id の設定を変更することを忘れないでください(私は数回、というより何度もこの失敗をした記憶があります)。要約: レプリカを設定するときは、データベースごとに異なる server_id が必要になります。server_id は、いくつかの異なる方法で変更できます。mysqld プロセスを手動またはスクリプトを介して開始する場合、--server-id=# フラグを使用して開始します。クライアントとして db に接続し SET GLOBAL server_id=# を実行する方法もありますが、この方法では、サーバーのリセットごとにこれを繰り返す必要があります。そして最後に、my.cnf ファイルに設定する方法もあります。
bind-address 構成
私が何回か経験した中でのもう一つの重要な点は、データベースの bind-address です。こちらについても他の投稿でより詳しく説明していますが、これを修正するには(セキュリティ リスクの原因になる可能性があるため、注意が必要)、デフォルトの構成である(少なくとも MySQL の場合)127.0.0.1 から 0.0.0.0 に変更する必要があります。これにより、ローカル接続だけでなく、どこからでも接続できるようになります。よりターゲットを絞ったやり方で、作成した Cloud SQL データベースの IP アドレスを入力することもできますが、正確な IP アドレスを特定するのは少し難しい場合があります。Cloud SQL は送信 IP アドレスを保証しないため、現在の IP アドレスを指定しても機能しないことがあるのです。
構成ファイルを変更する場合、server_id と bind-address の両方について、変更を有効にするためにデータベース サービスを再起動する必要があります。
接続オプションと設定
DMS には、移行のセットアップ時に作成した新しい Cloud SQL インスタンスにソース データベースを接続する方法を示したマトリックスがあります。ソース データベースがある場所、組織のセキュリティ ポリシー、移行要件に最も適合する方法を選択してください。
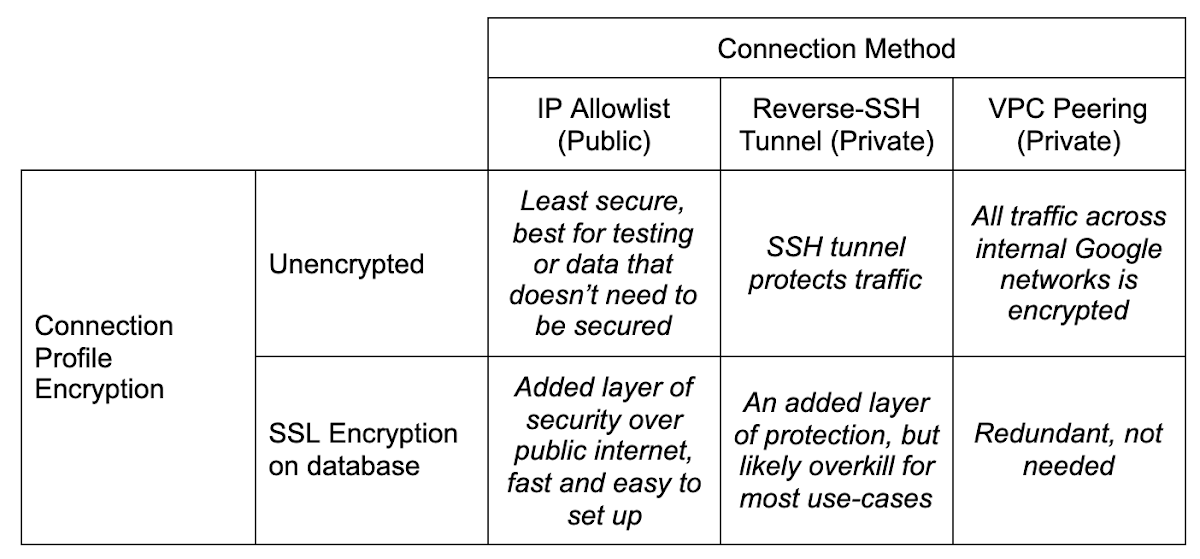
ご覧のとおり、使用する方法は、ほぼ安全性がどの程度求められるかに応じて決定されます。たとえば、IP 許可リスト方式を使用する場合、ネットワークのファイアウォールに受信トラフィック用の穴を開けることになります。企業のセキュリティ ポリシーによっては、これが不可能な場合があります。
では始めてみましょう。
DMS 接続プロファイル
ソースを定義するときは、移行元のソース データベースへの接続情報を定義する接続プロファイルを作成します。
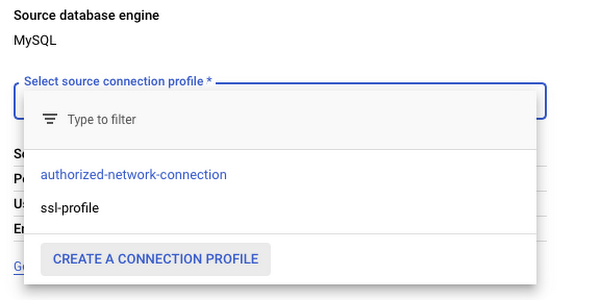
これらの接続プロファイルはスタンドアロン リソースのため、一度作成すれば将来の移行作業で再利用できます。再利用のユースケースとしてたとえば、データベース シャーディングの 1 ステップとして、ある種のプロキシまたはロードバランサの背後に存在する複数の Cloud SQL インスタンスをターゲットに、同じデータベースを移行するとよいでしょう。その後、個々のインスタンスの中のデータをシャーディングされた必要なもののみに削減することで、メイン インスタンスからシャーディングされたデータのみを取り出すよう注意する必要がなくなります。
接続プロファイルは、ソース データベース エンジン、名前と ID、データベース自体の接続情報(ホスト、ポート、ユーザー名、パスワード)、接続時の SSL 暗号化適用有無のコンポーネントで構成されます。項目はすべて単純明快なものですが、SSL 接続は例外で SSL 構成に精通していないと混乱する可能性があります。DMS は、暗号化なし、サーバーのみ暗号化、サーバー クライアント暗号化のいずれもサポートします。関連ドキュメントには、この点についてのわかりやすい説明が載っています。
要約: 「サーバーのみ」は Cloud にソース データベースを検証するように指示し、「サーバー クライアント」はサーバーとクライアントの両方に対して相互に検証するように指示します。もちろん、暗号化と検証を常に行うことがベスト プラクティスです。行う処理が重要なものではなく、SSL 鍵生成の処理をしたくない場合、たしかに暗号化をする必要はありません。ただし、これがまさしく本番環境のデータやなんらかの機密データである場合、特にパブリック接続で接続しているときは、必ず暗号化して検証を行ってください。
ただし、暗号化と検証が本当に必要な場合、最も難しいのは適切な鍵を生成し使用することです。DMS は x509 形式の SSL 鍵を使用します。SSL を使用したインスタンスの生成と保護をこれまでに行ったことがない場合、MySQL の場合はこちら、PostgreSQL の場合はこちらから関連情報をご覧ください。いずれにしても、移行準備の一環として、必ず鍵を準備する必要があります。たとえば、MySQL では、mysql_ssl_rsa_setup を実行するとインスタンスの鍵を取得できます。以下のように多数の鍵が生成されます。
私のように、サーバーに対して SSL を設定する経験が比較的浅い場合は、クライアントを使用して SSL 経由で接続することにより、SSL を正しく設定できたかどうかをテストすることができます。たとえば、MySQL の場合、mysql -u root -h localhost --ssl-ca=ca.pem --ssl-cert=client-cert.pem --ssl-key=client-key.pem --ssl-mode=REQUIRED -p を実行すると、鍵が正しいかどうかを強制的にテストできます。
私自身はアップロード フィールドを使用して正しい形式の鍵をアップロードするのに少し苦労しました。正しくラップした(少なくともそうしたと思ったのは確かで、結果自分はお世辞にも SSL の専門家とはいえないと確信しました)ことを確認したのに、x509 鍵のフォーマットが不適切であるとの指摘を受けたのです。同じエラーが発生した場合の私の解決策は、鍵ファイルのアップロードから手動での入力に切り替え、鍵の内容をコピーしてフィールドに貼り付けることでした。これには魔除けのような効果がありました。
さて、ソース側については説明したので、今度はソースと完成間近の Cloud SQL インスタンスとを接続するさまざまな方法を説明します。
移行先の作成は、Cloud SQL インスタンスを指定するだけなので簡単です。DMS は、レプリケーションの設定やデータの受信の準備に必要なすべての構成要素を用意しています。気をつける必要があるのは接続の方法です。Cloud SQL インスタンスの接続に対して、IP 許可リストを使用する場合はパブリック IP を、またリバース SSH および VPC ピアリングの場合はプライベート IP をそれぞれ設定する必要があります。また、VPC ピアリングを使用している場合、ソース データベースが存在する GCE インスタンスと同じ VPC に、Cloud SQL インスタンスを配置してください。正しい設定を選択するのを忘れたり気が変わったりしても、接続設定を選択すれば、DMS が Cloud SQL インスタンスの設定を更新するのでご心配は無用です。
上で概説したように、ギャップを埋める方法として、IP 許可リスト、リバース SSH トンネル、VPC ピアリングの 3 つの方法があります。実際上、この決定は 1 つの考慮事項に帰着します。つまり、安全性をどの程度求めるかという点です。業界の規制や内部ポリシーへの対応、またはデータベースに含まれたデータ自体の安全性確保が問題になっているかなど、求められる安全性を決定する要素はさまざまです。
詳細に入る前に、ここで注意点があります。データベースが自宅のマシン上にあって管理の緩い状態にあるのか、オフィスのサーバールーム内のオンプレミス サーバー上にあるのか、その他のクラウド内にあるのかにかかわらず、データベースを移行するうえで特に難しい部分(私にとって)の一つは、さまざまなファイアウォール、ルーター、マシン、インターネットの間にネットワーク パスを構築するという点でした。私はこの部分でかなりの時間立ち往生してしまいました。1 つ目の原因は、私のローカル データベースを見つけられるようポートを転送しておく必要があるルーターがあるのにポートを転送していなかったこと、2 つ目の原因はインターネットと私の内部スイッチをつなぐモデムとルーターのファイアウォールを通過させて転送することに失敗していたからです。そこで、アドバイスをさせてください。ネットワーク上の各ホップをトリプル チェックして、そのホップが外部から正しく転送しているかどうか確認するのです。近くに助けてくれるネットワークの専門家がいる場合、後で使用できるよう接続プロファイルを作成することまで手助けしてくれるでしょう。
IP 許可リスト
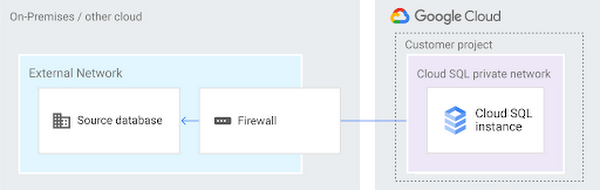
IP 許可リストは 2 つのポイントを接続するうえで、桁違いに簡単な方法です。移行セットアップの一部として Cloud SQL インスタンスを作成するときは、ソース データベースの IP アドレスを指す承認済みネットワークを追加します。逆に、Cloud SQL がソースデータベースと通信できるよう自分のファイアウォールに穴を開ける必要があります。私の場合、ローカル データベース側の作業は、whatsmyip を検索して Cloud SQL の作成時に IP を承認済みネットワークにコピーすることでした。もう一つの方向として、接続ステップで DMS から提供された Cloud SQL の送信 IP アドレス(ただし、Cloud SQL インスタンスの詳細ページからコピーすることも可能でした)から自分のローカル データベース マシンへのトラフィック向けに、ファイアウォール上でポート転送を作成しました。上記で述べた、ルートがデータベースに到達するのを妨げるものがないかネットワーク トポロジを確認すべきことを除けば、この方法で特に問題に遭遇したことはありません。
IP 許可リストは、3 つの接続方法の中で最も安全性が低いものです。ですが、本質的に安全性に欠けるというわけではありません。SSL 暗号化を使用している限り、通常のユースケースでは十分に安全性を確保できることが理解できるでしょう。ただし、リバース SSH トンネルや VPC ピアリングを使用する場合と比較すると安全性は劣ります。すべて、相対的なものです。
クラウドでホストされている VM を経由したリバース SSH トンネル
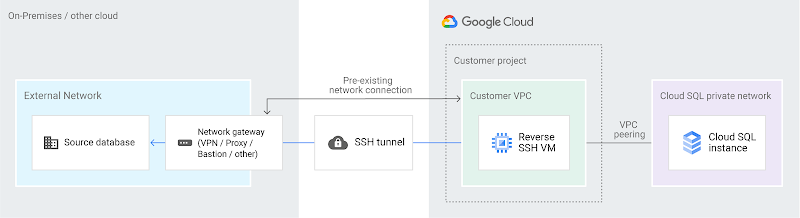
安全性でワンランク上の方法は、リバース SSH トンネリングです。今までこれを使用したことがない、これが何であるかわからないという方には、Stack Exchange でのこの方の回答(私のお気に入りの回答)が参考になります。何が起きているのかを簡単に理解できるようにしてくれる詳細かつ優れた説明です。要約: ソース データベース ネットワーク、Google Compute Engine による仮想マシン インスタンス、移行先の Cloud SQL インスタンスの間に構築される文字どおりのトンネルと考えてください。このトンネルは、インターネットを通過するトラフィックを保護します。
さて、この方法ではコンポーネントが追加されます。SSH トンネルのコネクタ部分に使用する仮想マシンです。これは、その複雑さで仕事を一層楽しくしてくれる追加のレイヤーとなります。ほとんどの場合、このコンポーネントの作成は DMS がやってくれます。UI の接続方法としてリバース SSH を選択すると、既存の VM を使用するか、VM を作成するかを選択できます。いずれにせよ、ソース データベースにアクセスできるマシンから実行すると、SSH トンネルのターゲットとして正常に使用できるよう VM をセットアップするスクリプトが生成されます。
自動化されたもののすべてにいえることですが、この場合にもいくつかの潜在的問題が発生して、診断がかなり困難な障害になることがあります。私の経験から注意が必要なことは次のとおりです。
VM_ZONE
関連する UI はかなり優秀ですが、Cloud SQL インスタンスが最初のセットアップを完了する前に(Cloud SQL インスタンスの作成には最大で約 5 分かかることがあります)、VM のセットアップ スクリプトを表示してしまったときは、スクリプト内の変数 VM_ZONE が正しく設定できなくなるという点に気を付けてください。
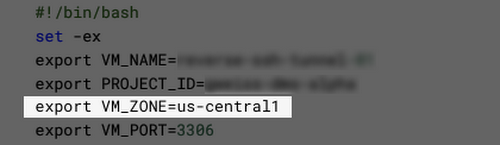
適切なゾーンが設定されないため、ご自身で入力するか、Cloud SQL インスタンスの作成が完了して入力可能になったら [スクリプトを表示] ボタンをもう一度押して値が設定されるようにする必要があります。
マシンタイプ
このブログの執筆時点ではまだ修正されていない内容として、マシンタイプのプルダウンをデフォルトのままにした場合、VM_MACHINE_TYPE に対しても間違った変数がセットされます。スクリプトで変数が db-n1-standard-1 と設定されますが、正しい変数は n1-standard-1 です。このため VM の作成が失敗します。
server_id
MySQL を移行する場合、server_id をゼロ以外に設定したことをトリプル チェックしてください。これは前にも言ったことの繰り返しです。このステップでそれを忘れていたか、いなかったか。とにかく、これで時間を失ったのです。言わずにはいられません。
また、スクリプトの次の行ではバックグラウンドでリバース トンネルをすぐに確立しています。
このスクリプトは、実行するマシンのバックグラウンドで何かを実行している点に着目してください。上記コマンドの -f が、バックグラウンドでの処理になっている原因です。私はバックグラウンドでプログラムを実行するのがあまり好きではありません。プログラムが常時実行しておきたいものでない場合、忘れずに後で停止しなければならないからです。この場合では、複数の移行を行うときにどのトンネルを使用するか混乱が生じる原因に、またその他のエッジケースで混乱の原因になる可能性があります。そのため私は、このコマンドを削除したスクリプトを実行して VM を生成してから、ターミナルでスクリプト変数の値を置き換えたうえで -f を指定せずにこのコマンドを実行しました。
というわけで、スクリプトを実行してください(私の場合、バックグラウンド コマンドを削除しましたが、残しておいても特に問題を感じなければそれで良いのです。ただ、残してあるという事実だけは忘れないでください)。これを行うと、スクリプトからの出力に echo "VM instance '${VM_NAME} created with private ip ${private_ip}" という行が表示されます。 DMS 移行ステップ 4 で、[VM サーバーの IP] フィールドに入力する必要のある、あの IP アドレスです。
さて、ネットワークへの接続が大きな障害なる可能性があると言ったときのことを覚えていますか?あのコメントは事実なのです。仮想マシンで複雑さのレイヤーがもう 1 つ追加になりました。デフォルトでは、Google Compute Engine 仮想マシンはファイアウォールでとても頑丈にロックダウンされています(セキュリティ確保が至上命令)。それで私たちの生活がより一層複雑になったとしても、ファイアウォールが頑丈なのは良いことです。リバース SSH を機能させるには VM にピンホールを開けて、作成した Cloud SQL インスタンスと通信する、それも内部ネットワークを超えて通信する必要があります。このため、新しいファイアウォール ルールを作成する必要があります。
重要なことから始めよ、ということでいろいろなものを可能な限りロックダウンされたままにします。そのためにまず、作成したばかりの仮想マシンの詳細ページに移動します。VM のリストはこちらにあります。VM を編集し、下にスクロールしてネットワーク タグのセクションを見つけます。
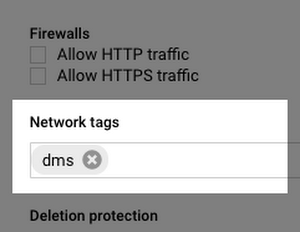
これにより、ファイアウォール ルールの適用先をこのインスタンスのみに限定できます。タグは何でも構いませんが、次のステップで使用するタグを覚えておいてください。
コンソールのファイアウォール領域に移動します。[ネットワーキング] > [VPC ネットワーク] > [ファイアウォール] と移動します。または、単にこちらをクリックします。新しいファイアウォール ルールを作成します。名前を付けます。移行にデフォルトの VPC とは異なる VPC を使用している場合は、[ネットワーク] プルダウン メニューで正しい VPC を選択してください。次に、[ターゲット] フィールドを [指定されたターゲットタグ] とし、下のフィールドに、VM に追加したのと同じタグを入力します。ところで、ソースフィルタには少し異質なところがあります。
説明しましょう。トラフィックは Cloud SQL からトンネルを経由してソースに戻り、接続を確保します。このセクションの冒頭にある図を見ると、どのように見えるか確認できます。
これは、Cloud SQL がファイアウォールを通過して VM に達しようとすることを意味します。そのため、以下を行う必要があります。これには裏があるのです。Cloud SQL に表示される IP アドレスは、ファイアウォールの IP 範囲フィルタに入力するものと考えがちですが、Cloud SQL が実際に送信トラフィックに使用する IP アドレスとは異なります。このため、ここでフィルタリングする必要のある IP アドレスが何かわからないことになります。Cloud SQL は、送信 Cloud SQL トラフィックの静的アドレスを保証していません。
これを解決するには、Cloud SQL が使用する IP アドレスのブロック全体を許可する必要があります。これは、10.121.1.0/24 を [ソース IP の範囲] フィールドに入力することで行います。これは、残念ながら必要悪です。これを行うのは心配だと思われる場合(内部 IP であるため、それほど悪くはありませんが)、ファイアウォールの [プロトコルとポート] セクションで、ご使用の db エンジンのデフォルトポート(MySQL では 3306、PostgreSQL では 5432)での tcp のみを許可することでロックダウンをより一層強化できます。以上によりファイアウォールは、その内部 IP 範囲から発信され、使用 db エンジンのポートを経由し、かつ作成した 1 つの VM に対するトラフィックのみを許可するようになります。
ファイアウォールについては以上です。それでは [作成] をクリックしましょう。理論的には、これで成功するはずです。
スクリプトでトンネルを設定するための実際のコマンドを実行していなかった場合、今すぐ実行してください。コマンドは以下のとおりです。
終了したら次は、[構成して続行] をクリックして、ジョブのテストに進みます。すべての星が揃いネットワークの神々があなたを支持しているならば、[ジョブをテスト] の一押しでテストが成功するはずです。もう移行しても問題ありません。
VPC ピアリング
ふう、まだあるのか。さて、方法は 2 つ、そのうちの 1 つをやります。
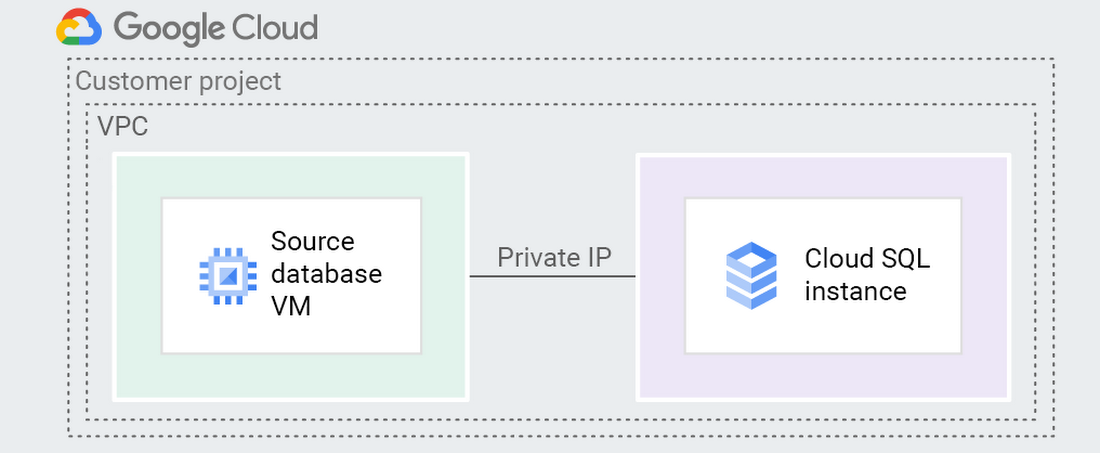
VPC ピアリングは、IP 許可リストと同様、上記の基本事項を忘れていなければ非常に簡単です。基本事項には、server_id やターゲットからの接続を許可するようソース データベースに bind-address が設定されていることの確認などが含まれます。
VPC ピアリングの使用については 2 つのシナリオがあります(おそらくもっとありますが、主要なシナリオは 2 つです)。
ソース データベースが、Compute Engine インスタンスなどの形で、すでに Google Cloud で実行されている。
Cloud VPN や Cloud Interconnect などを使用して、ソース データベースのネットワークを Google Cloud ネットワークにピアリングするネットワーキングを設定済みである。
外部ネットワークの GCP へのピアリングには、極めて奥の深い一面もあります。場合により、リージョンでのルーティング関連ハードウェア、コストとスループットに関する考慮事項などが関係してきます。そのため、いろいろな組み合せが可能で、非常に特有な要件を伴うことが多く、このブログ投稿で扱える範囲を超えています。最終的には中編小説ぐらいの長さになってしまうでしょう。ともあれ、ご自分の外部ネットワークを Google Cloud の内部ネットワークに参加させ、移行に際して VPC ピアリングを使用することは間違いなく可能であると私は確信しています。もう少しこのテーマを掘り下げる場合は、ドキュメントに例を挙げて説明しているページがあります。こちらをご覧ください。
なお、VPC ピアリングの伝統的な使用法として、Compute Engine でデータベースを実行していて、Cloud SQL のより管理されたソリューションに切り替える場合があります。過去において Compute Engine でデータベースを実行するのが良いと考えられていた理由はいくつかあります。依存していた特定のフラグが Cloud SQL では変更できない、必要な MySQL や PostgreSQL のバージョンが使用できないなどを含め、多くの問題があったのです。
GCE で使用していた理由が何であれ、今ではデータベースは Cloud SQL での管理が望ましく、VPC ピアリングが進むべき方向と考えるはずです。ここで、データベース構成の設定をダブルチェックして、前述のような準備ができているかどうか確認する必要があります。ソース接続プロファイルを作成する場合、IP アドレスは外部 IP ではなく GCE VM の内部 IP になります(情報はプライベート ネットワーク内に保管してください)。ファイアウォールの設定は、リバース SSH トンネルで説明したものと同じにする必要があります。VPC を使用している場合、GCE インスタンスに許可する Cloud SQL インスタンスの IP アドレスは、標準の Cloud SQL の範囲(10.121.1.0/24)内にはありません。というのも、その IP アドレスは VPC の IP 範囲内から割り振られているはずだからです。そのため、Cloud SQL インスタンス ページに移動して、そこにあるリードレプリカの内部 IP アドレスを取得する必要があります。DMS の移行先ステップで作成したインスタンスが表示されない場合、または内部 IP アドレスが指定されない場合は、まだインスタンスが作成されていない可能性があります。これには数分かかります。
パズル完成への最後のピースは、目的の VPC がどこであれ、すべての要素を同じネットワーク内に置くことです。すなわち作成した Cloud SQL 移行先、およびソース データベースを保持する GCE インスタンスです。目的に応じて、最初にそれらの両方を新しい VPC に移動する必要があるかもしれません。デフォルトの VPC を利用するのは問題ではありませんが、プロジェクトが非常に古いものである場合、レガシーのデフォルト VPC を使用している可能性があります。レガシーの VPC の場合、移行は機能せず、移行を行うためには新しい VPC を作成する必要があります。
1)Logging。ここで役立つ 2 つの場所があります。1 つ目はデータベースをホストしている GCE インスタンスの詳細の中、またはリバース SSH トンネルのホスティング マシンの詳細の中です。Cloud Logging へのリンクがあります。
それをクリックすると、その GCE のエントリでフィルタリングされたログに直接移動します。2 つ目の場所は、使用している VPC ネットワークのサブネットにあります。こちらに移動し、GCE インスタンスが存在するゾーンをクリックして編集し、フローログをオンにします。それが完了したら、移行テストを再試行してログをチェックし、疑わしいものがないか確認します。
2)接続テスト。DMS を使用するまで、接続テストについては知りませんでした。非常に便利です。2 つの異なる IP アドレス(ソースと移行先)の特定と確認するポート(MySQL 3306、PostgreSQL 5432)を指定できます。また、ポイント a からポイント b への移動に使用したホップを示すトポロジやトラフィックの許可や拒否に適用されたファイアウォール ルールを表示してくれます。これはすごく楽しい経験でした。コンソールのこちらから直接アクセスして、試すことができます。ただし、ネットワーク管理 API を有効にする必要があります。
まとめ
以上で、データベースを Cloud SQL に移行することを目的に、ソース データベースを DMS に接続する際の基本的方法について説明できたものと願っています。移行の完了後に処理が必要なピースがいくつか残っています。これらのやり残した部分について説明するブログも投稿する予定です。
ご質問、ご提案、ご意見などがありましたら、Twitter で私にご連絡ください。DM は開いています。最後までお読みいただきありがとうございました。
-デベロッパー アドボケイト Gabe Weiss



