AlloyDB for PostgreSQL の仕組み: データベース対応のインテリジェントなストレージ

Google Cloud Japan Team
※この投稿は米国時間 2022 年 5 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
Google は本日、Google I/O にて AlloyDB for PostgreSQL を発表いたしました。これは、要求が厳しいエンタープライズ クラスのトランザクション ワークロードと分析ワークロードに使用できる、PostgreSQL 対応のフルマネージド データベースで、PostgreSQL で弾力性のあるストレージとコンピューティング、インテリジェントなキャッシュ、AI / ML による管理といったクラウドの利点を最大限に活用できるようになります。さらに、AlloyDB は圧倒的なコスト パフォーマンスを実現します。パフォーマンス テストでは、標準の PostgreSQL と比較してトランザクション ワークロードで 4 倍以上、分析クエリで最大 100 倍高速になるという結果が出ています。しかも AlloyDB は、シンプルで予測可能な料金体系となっています。AlloyDB はミッション クリティカルなアプリケーション向けに設計されており、広範なデータ保護と業界をリードする 99.99% の可用性を提供します。
AlloyDB for PostgreSQL のパフォーマンスと可用性の向上は、複数の革新的な技術によって支えられています。ここでは、「AlloyDB for PostgreSQL の仕組み」シリーズの第一弾として、PostgreSQL 用に最適化され、インテリジェント、データベース対応、水平方向にスケーラブルという特徴を持ったストレージ レイヤを取り上げます。
コンピューティングとストレージの分離
AlloyDB for PostgreSQL はコンピューティングとストレージの分離という基本原則に基づいて構築され、スタックの各レイヤで分離を活用するように設計されています。
AlloyDB は、まずストレージからデータベース レイヤを分離して、PostgreSQL 用に最適化された新しいインテリジェント ストレージ サービスを導入します。これにより、I/O ボトルネックが減り、AlloyDB がログ処理システムを使用して多くのデータベース オペレーションをストレージ レイヤにオフロードできるようになります。また、ストレージ サービス自体もコンピューティングとストレージを分離するので、ログ処理とは別にブロック ストレージのスケールが可能になります。
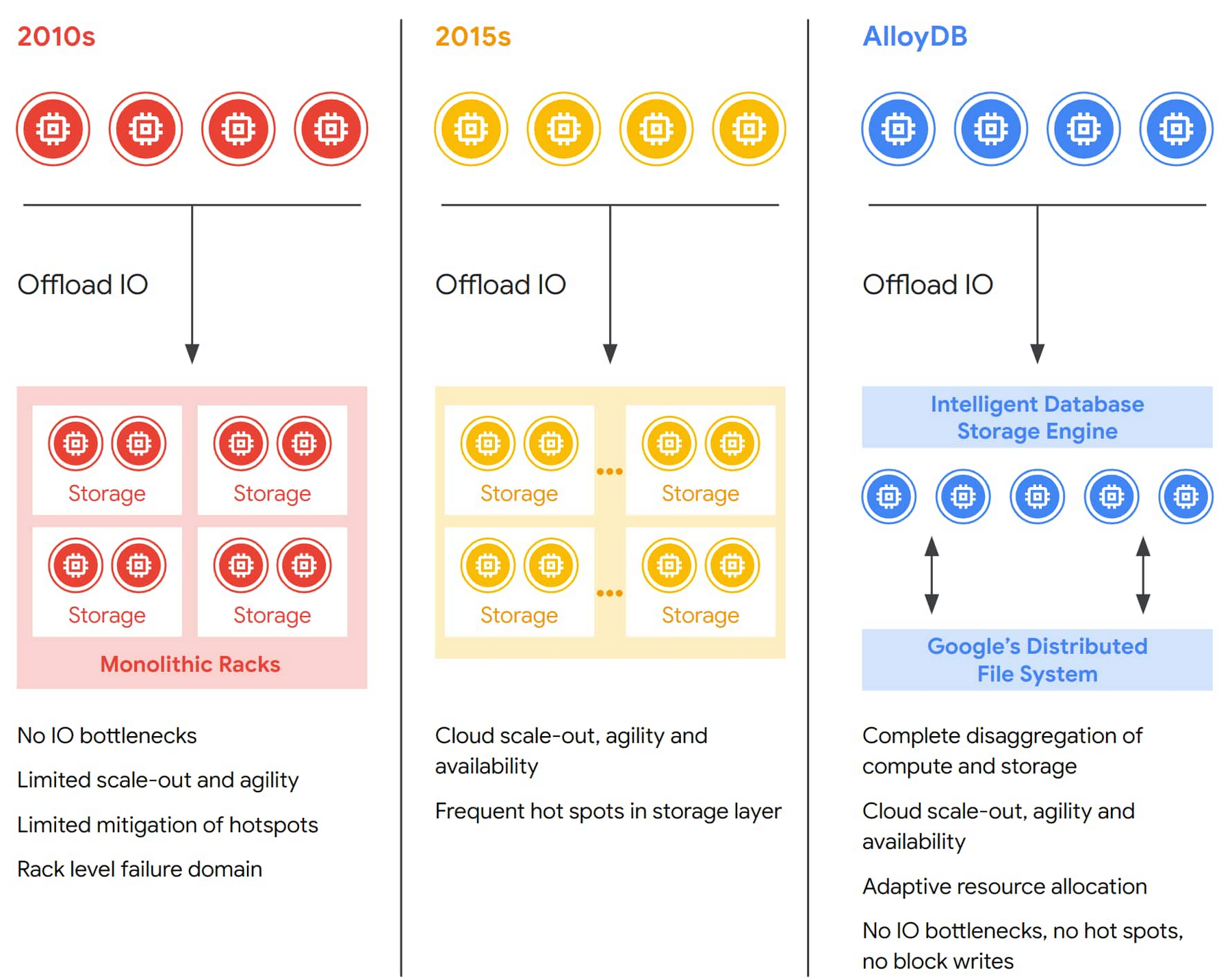
データベース内のコンピューティングとストレージの分離は年々進化しています。初期のアプローチでは、ストレージのサイズ変更をコンピューティング レイヤから独立して行うことができたものの、システム全体はまだかなり固定的で、弾力性に欠けていました。その次の世代のデータベース システムでは、クラウド スケールのストレージ ソリューション上に構築することでストレージの弾力性が改善されましたが、ストレージ クラスタのサイズ過大や、ワークロードの急増(ホットスポット)に対応する IO 容量の不足に依然として悩まされていました。
AlloyDB のストレージ レイヤにまで完全に分離されたアーキテクチャは、変化するワークロードに動的に適応できる弾力性のある分散クラスタとして機能し、耐障害性を強化し、可用性を高め、読み取りスループットを水平スケーリングするコスト効率の高い読み取りプールを実現します。ワークロードのパターンに応じて自動的に階層化される、スタック全体の複数のキャッシュ保存レイヤにより、開発者はクラウドネイティブなストレージの規模、経済性、可用性を維持しながら、パフォーマンスを向上させることができます。AlloyDB アーキテクチャのこれらの側面が加わることで、データベースにおける分離が次のレベルに進化し、AlloyDB の卓越したパフォーマンスと高可用性が実現されます。
モノリシックな設計の問題点
従来の PostgreSQL データベースはモノリシックな設計を採用し、ストレージ リソースとコンピューティング リソースを単一のマシンに配置しています。ストレージ容量の増加やコンピューティング パフォーマンスの向上が必要な場合は、より高性能なサーバーに移行したりディスクを追加したりして、システムをスケールアップします。さらなるスケールアップができなくなった場合や費用対効果が下がる場合は(高性能なサーバーにするとかなりコストがかかります)、レプリケーションを使って、データベースの読み取り専用コピーを複数作成することができます。
このアプローチには限界があります。たとえば、これはデータベースの負荷や構成に依存するので、フェイルオーバーに要する時間が長くなり予測しにくくなります。また、リードレプリカ自体が、高価で遅いデータベースのコピーを使用するため、読み取り容量のスケールやレプリカ ラグの管理がさらに困難になります。結果として、ストレージとコンピューティングが密結合したモノリシックなデータベースの弾力性は制限されることになります。AlloyDB はコンピューティングとストレージを分離することで、これらの制限の多くを解決できます。
AlloyDB では、データベース レイヤのスケーラビリティを単一(仮想)マシンの容量を超えてさらに向上させるために、複数の読み取り専用レプリカ インスタンスを追加することで、データベースのコピーを追加することなくプライマリ データベース インスタンスの読み取り専用クエリ処理をサポートできます。ストレージ レイヤはゾーン間で分散していてどのサーバーからもアクセスできるので、安価(レプリカごとのインスタンスは独自のストレージを必要としないため)で最新のリードレプリカ インスタンスをすばやく構築できます。基本的には、こうした設計原則によって、プライマリ データベース インスタンスのモノリスから機能を移行するプラットフォームを構築し、クラウドネイティブな実装に変換することで、パフォーマンスやスケーラビリティ、可用性、管理機能の向上が見込めます。
AlloyDB 設計の概要
AlloyDB のストレージ レイヤは、大きく分けて 3 つの部分で構成される分散システムです。
高速の先行書き込みログ(WAL)の書き込み用の低レイテンシ、リージョン ログ ストレージ サービス
WAL レコードを処理し「マテリアライズド」データベース ブロックを生成するログ処理サービス(LPS)
ゾーン ストレージ障害が発生した場合でも耐久性を確保する、フォールト トレラントでシャーディング済みのリージョン ブロック ストレージ
下の図 2 は、ログ処理サービスと PostgreSQL データベース レイヤや耐久性の高いストレージとの統合を概要図に示したものです。プライマリ データベース インスタンス(1 つしかありません)は、WAL のログエントリを保持し、データベースの変更オペレーション(INSERT、DELETE、UPDATE など)を低レイテンシのリージョン ログ ストアに反映させます。そこから、ログ処理サービス(LPS)がさらに処理を行うためにこれらの WAL レコードを消費します。ログ処理サービスは、PostgreSQL WAL レコードのセマンティクスと PostgreSQL のストレージ形式を完全に把握しているため、これらの WAL レコードによって記述された変更オペレーションを継続して再生し、最新のデータベース ブロックをシャーディング済みの、リージョン ストレージ システムに具体化することができます。そこから、これらのブロックは、プライマリ データベース インスタンス(再起動の場合やブロックが単にキャッシュから外れた場合)やストレージ サービスを実行しているリージョン内のゾーンにある任意の数のレプリカ インスタンスに戻されます。
また、AlloyDB では、レプリカ インスタンスのローカル キャッシュを最新の状態に保つため、プライマリからレプリカ インスタンスに WAL レコードをストリーミングし、直近の変更を通知します。ブロックの変更に関するこうした情報がないと、レプリカ インスタンスのキャッシュされたブロックを最新に保てなくなります。
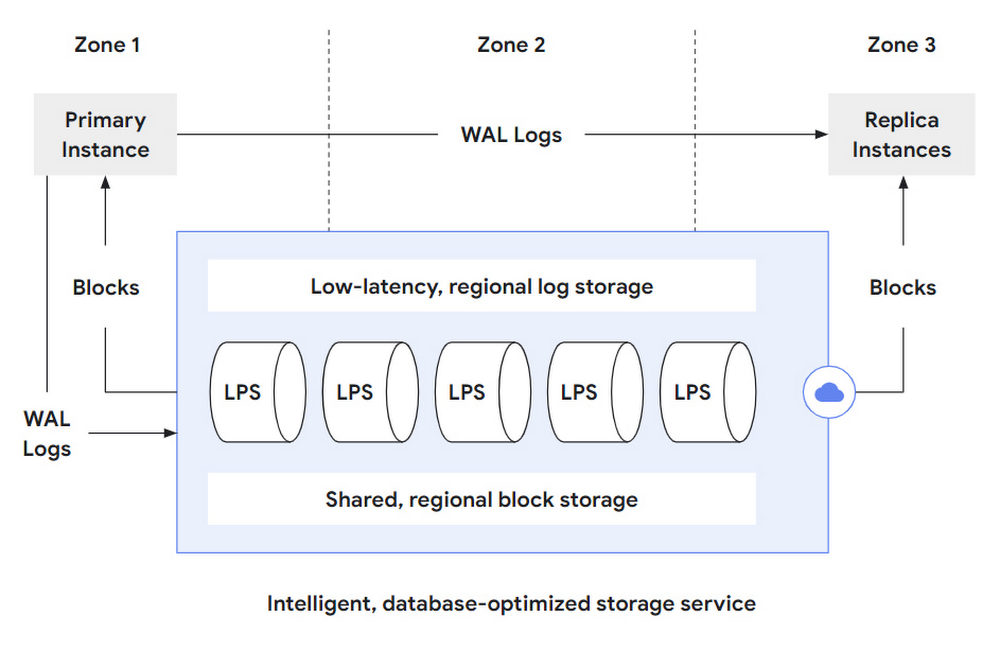
このアプローチのメリットは主にどのようなものでしょうか。この設計による影響について、さらに詳しく見ていきましょう。
ストレージ レイヤ内でもコンピューティングとストレージを完全に分離: LPS はワークロードのパターンに応じてスケールアウトし、ホットスポットを回避する必要があれば、コンピューティング リソースを透過的に追加してログを処理します。ログのプロセッサのコンピューティングは、共有のリージョン ストレージにアタッチされているため、データをコピーすることなく柔軟にスケールアウトまたはスケールインすることができます。
ストレージ レイヤのレプリケーション: 複数のゾーン間のすべてのブロックのレプリカを同期的に作成することで、データベース レイヤに影響を与えたり、変更を加えたりすることなく、ストレージ レイヤがシステムをゾーン障害から自動的に保護します。
効率的な I/O パスで全ページの書き込み不要: 更新オペレーションでは、コンピューティング レイヤは WAL レコードを送信するだけで、ストレージ レイヤはそのレコードを再生し続けます。この設計では、データベース レイヤをチェックポイントにする必要はないうえ、データベース ブロック全体をストレージ レイヤに送信する理由( 欠落したページの問題に対する保護など)もありません。これによって、データベース レイヤはクエリ処理タスクに集中でき、データベース レイヤとストレージ レイヤ間のネットワークを効率的に利用できるようになります。
低レイテンシの WAL の書き込み: 低レイテンシのリージョン ログ ストレージを使用することで、トランザクションの commit オペレーション時にWAL ログレコードをすばやくフラッシュできます。その結果、トランザクションの commit オペレーションが非常に高速になり、ピーク時の負荷でも、高いトランザクション スループットを達成できるようになります。
リードレプリカ インスタンスの高速作成: ストレージ サービスはあらゆるゾーンのあらゆるブロックに対応できるので、データベース レイヤから任意の数のリードレプリカ インスタンスをストレージ サービスにアタッチし、データベースの「非公開」コピーがなくてもクエリを処理することができます。リードレプリカ インスタンスの作成は、データをオンデマンドでストレージ レイヤから増分的に読み込むことが可能で、非常にすばやく実行できます。このため、クエリ処理開始前に、データベースの完全なコピーをレプリカ インスタンスにストリーミングする必要がありません。
高速再起動による復旧: ログ処理サービスでは、オンライン オペレーション中に WAL ログレコードを連続再生するため、再起動による復旧時に処理する必要のある先行書き込みログの量は最小限に抑えられます。結果として、システムの再起動が大幅に高速化されます(WAL 関連の復旧作業を最小限に抑えられるため)。
ストレージ レイヤのバックアップ: バックアップ オペレーションは、ストレージ サービスですべて対応できるので、データベース レイヤのパフォーマンスやリソースに影響を与えることはありません。
書き込み操作のプロセス
データベースに対する変更操作の流れをたどりながら、システムのデザインをさらに見ていくことにしましょう(図 3)。操作はまず、クライアントが、たとえば SQL INSERT ステートメントを、クライアントの TCP 接続を通じてデータベース レイヤのプライマリ インスタンスに向けて発行するところから始まります。プライマリ インスタンスはステートメントを処理(データ構造とインデックス構造をインメモリで更新)し、更新操作のセマンティクスを捕捉する WAL ログレコードを作成します。トランザクションが commit されると、このログレコードがまず低レイテンシのリージョン ログストレージに同期的に保存されます。続いて次のステップで、ログ処理サービスによって非同期的に取り出されます。
なお、ストレージ レイヤは別々のコンポーネントに意図的に分解され、ストレージ レイヤで実行される個別のタスク(ログの保存、ログの処理、ブロック ストレージ)に対する最適化が行われます。トランザクションの commit で生じるレイテンシを低減するうえで重要なことは、ログレコードを可能な限り早く永続的な形で保存し、トランザクションの永続性を確保することです。WAL ログの書き込みは追記専用操作であるため、AlloyDB はこのユースケースに対して、高性能で低レイテンシのストレージ ソリューションにより特に最適化されています。第 2 のフェーズでは、WAL ログレコードを、その参照先になっている以前のバージョンのブロックに適用して処理する必要があります。そのために、ストレージ レイヤの LPS サブシステムでランダムなブロック ルックアップが実行され、PostgreSQL のやり直し処理ロジックが、高い性能と拡張性を確保しながら適用されます。
マテリアライズされたブロックにリージョンで永続性をもたせるために、リージョン内の各ゾーンで複数のログ処理サービス(LPS)が実行されます。各ログレコードがすべて処理され、得られたバッファがシャーディングされたリージョン ブロック ストレージに永続的な形で保存されて(下図参照)、最終的にログレコードがリージョン ログストレージから削除される必要があります。
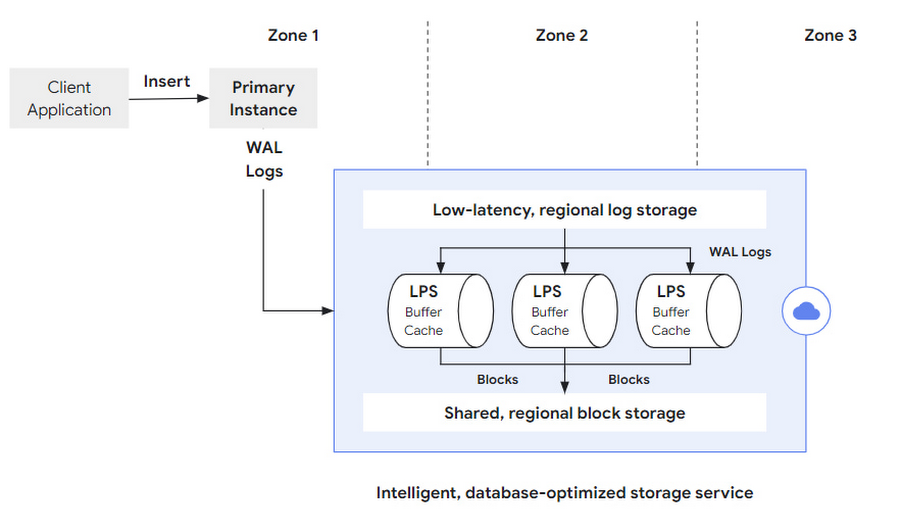
読み取り操作のプロセス
同様に、読み取り操作は、SQL クエリがデータベース サーバーに送られるところから始まります。これはプライマリ インスタンスの場合もあれば、読み取り専用クエリ処理で使用されるレプリカ インスタンスの 1 つ(場合によっては多数)の場合もあります(図 4 にはどちらの場合も示されています)。データベース サーバーでは、クエリに対して従来の PostgreSQL システムと同じ解析、計画、処理が行われます。必要とされるブロックがすべてメモリ常駐バッファ キャッシュに存在する場合、データベースがストレージ レイヤとやりとりする必要はありません。ワーキング セットがバッファ キャッシュに入りきらない場合でも非常に高速なクエリ処理が行えるように、AlloyDB では超高速ブロック キャッシュがデータベース レイヤに直接統合されています。このキャッシュによってバッファ キャッシュの容量が大幅に拡大し、そうした場合のシステム実行速度がさらに向上しました。
ただし、ブロックがどちらのキャッシュにもない場合は、対応するブロック フェッチ リクエストがストレージ レイヤに送られます。取り出すべきブロック番号のほか、このリクエストではデータの読み込みを行うログシーケンス番号(LSN)も指定されます。ここで特定の LSN を使用することにより、クエリ処理の間、データベース サーバーで整合状態を維持できるようになります。これが特に重要になるのは、ブロックを PostgreSQL のバッファ キャッシュから排除し、続けて再度読み込む場合や、同時実行で(構造的な)変更が行われることのある B ツリーのような、複雑なマルチブロックのインデックス構造を走査する場合です。
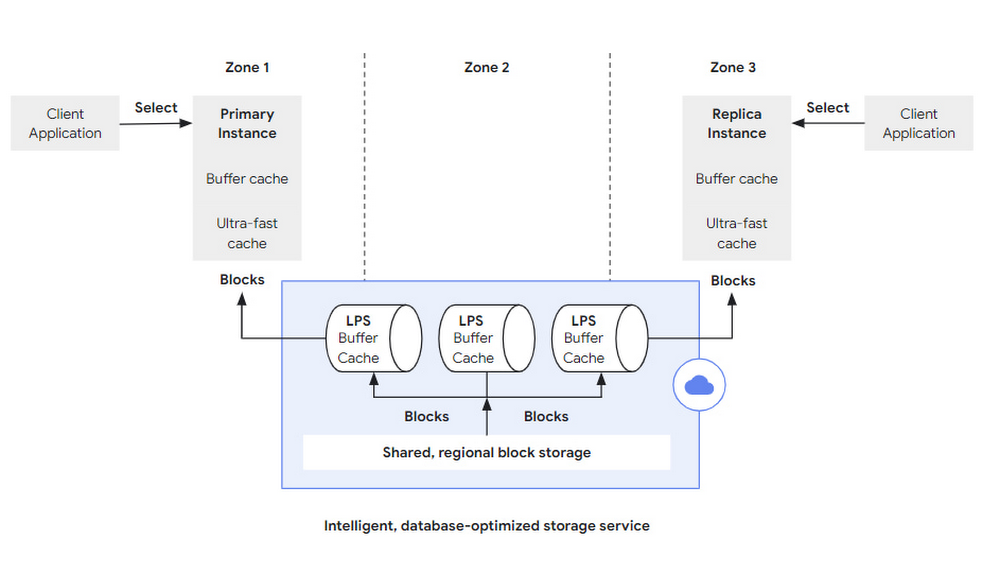
ストレージ レイヤでは、ログ処理サービスもブロック フェッチ リクエストの処理を担っています。LPS にはそれぞれ、PostgreSQL バッファ キャッシュのインスタンスがあります。リクエストされたブロックがすでに LPS のバッファ キャッシュに存在する場合、何の I/O 操作をすることもなく、ブロックを直ちにデータベース レイヤに戻すことができます。リクエストされたブロックがキャッシュに存在しない場合、LPS はそのブロックをシャーディングされたリージョナル ストレージから取り出し、データベース レイヤに送り返します。ログ処理サービスは、ある種の記帳処理を行って、未処理のログレコードが存在するブロックがどれなのかを追跡する必要もあります。そうしたブロックに対するリクエストが届いたら(これはめったに起こらないとされるイベントです。データベース レイヤからはキャッシュから追い出されて参照されることになったブロックのリクエストのみが送られるためです)、読み取りリクエストは、そのログレコードに対するやり直し処理が終了するまで停止する必要があります。したがって、そうした停止状態を避けるために、LPS レイヤの WAL 処理が効率的でスケーラブルに行われ、最も要求の厳しいエンタープライズ ワークロードにも対処できるようになっていることが非常に重要です。これについては、次のセクションで詳しく説明します。
ストレージ レイヤの弾力性
ここまで、ログ処理サービスを(各ゾーンの)単一のプロセスとして説明してきました。しかしながら、LPS プロセスが 1 つしかない場合、要求の厳しいエンタープライズ ワークロードではスケーラビリティの問題が発生する可能性があります。LPS は WAL レコードを継続的に適用すると同時に、プライマリ インスタンスと複数のレプリカ インスタンスの両方からの読み取りリクエストに対応する必要があるためです。
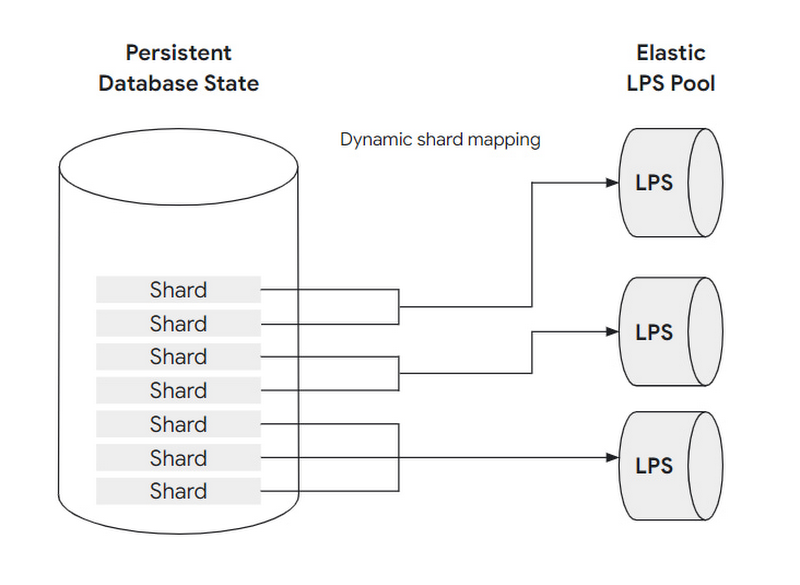
この問題に対処するために、データベースはシャードと呼ばれるブロックのグループに水平分割されて、永続性を確保します。シャードと LPS リソースの両方が水平方向に独立してスケールされます。
それぞれのシャードは常に 1 つの LPS に割り当てられますが、各 LPS は複数のシャードを処理できます。シャードから LPS へのマッピングは動的で、LPS リソースの数をスケーリングしてシャードを再割り当てすることで、ストレージ レイヤはアクセス パターンの増加に柔軟に対応できます。これにより、ストレージ レイヤはスループットをスケールできるだけでなく、ホットスポットを回避できます。
ここで 2 つの例について考えてみましょう。最初の例は、システム全体の負荷が増加して、ほぼすべてのシャードが以前より多くのリクエストを受け取る場合です。この場合、ストレージ レイヤは LPS インスタンスの数を増やす(たとえば、2 倍にする)ことができます。その後、新しく作成されたログ処理サーバー インスタンスがシャードの一部を引き継いで、既存のインスタンスの負荷を軽減します。このシャードの再割り当てにはデータのコピーやその他のコストのかかる操作は含まれないため、非常に高速でデータベース レイヤからは見えません。
シャードの再割り当てが非常に有効であるもう 1 つの例は、小さなシャード セットへのアクセスが急激に増加した場合です(たとえば、データベースに保存されている特定の製品ファミリーに関する情報が、スーパーボウルのコマーシャル後に頻繁にリクエストされるようになった場合など)。この場合も、ストレージ レイヤは動的に対応できます。極端な例では、ワークロードの急激な増加を監視する各シャードを、シャードの負荷を排他的に処理する専用の LPS インスタンスに割り当てることで対応することが可能です。その結果、適切な再シャーディングと LPS の弾力性により、システムはワークロードが急増した場合でも高いパフォーマンスとスループットを提供でき、ワークロードが再び減少した場合にはリソースのフットプリントを削減することもできます。この動的なサイズ変更とストレージ レイヤの弾力性は、データベース レイヤとエンドユーザーのどちら側でも完全に自動化されており、ユーザーが操作する必要はありません。
ストレージ レイヤのレプリケーションと復元
AlloyDB の目標は、データセンターで停電や火災などのゾーン障害が発生した場合でも、データの耐久性とシステムの高可用性を提供することです。このため、すべての AlloyDB インスタンスのストレージ レイヤは 3 つのゾーンに分散されています。各ゾーンにはデータベース状態の完全なコピーがあり、前述した低レイテンシであるリージョンのログストレージ システムから WAL レコードを適用することで継続的に更新されます。
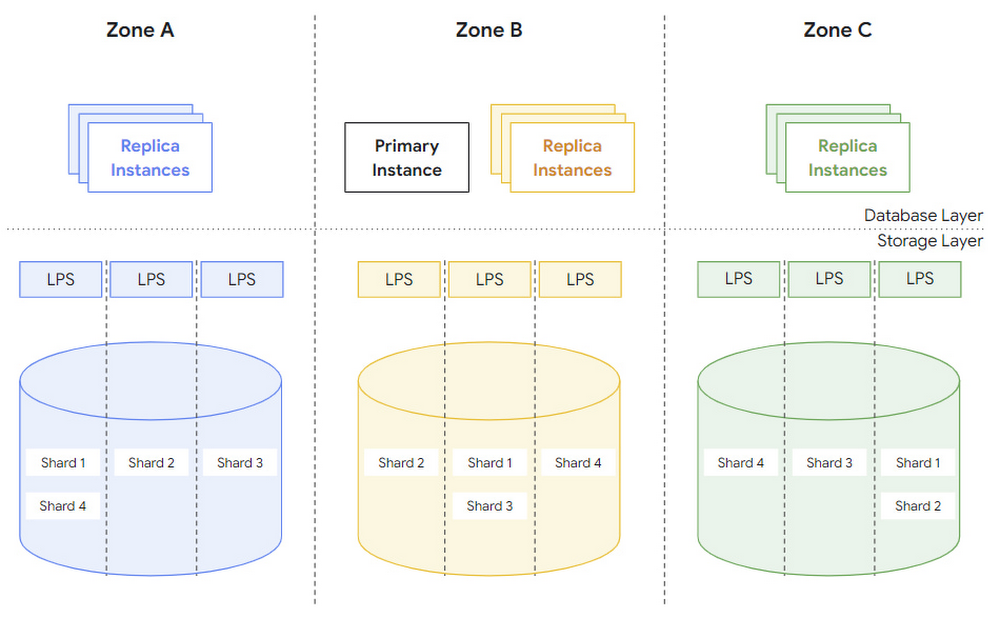
図 6 は、3 つのゾーンにまたがるシステム全体を示しています。各ゾーンには複数のログ処理サーバー(LPS)と、サーバーごとに 1 つまたは複数のシャードがあります。どのゾーンでも各シャードのコピーが使用可能であることに注目してください。
このアーキテクチャでは、最小限のオーバーヘッドでブロック ルックアップ操作を実行できます。各ゾーンには完全なデータベース状態の独自のコピーがあるため、データベース レイヤはゾーンの境界をまたいでブロック ルックアップ操作を行う必要はありません。さらに、ストレージ レイヤはすべてのゾーンに WAL レコードを継続的に適用し、データベース レイヤはリクエストするブロックごとにターゲット バージョン LSN を提供するため(上記を参照)、ルックアップ操作中に読み取りクォーラムを確立する必要もありません。
ゾーン全体が使用できなくなった場合、ストレージ レイヤは、同じリージョンの新しいゾーンを統合し、完全なデータベース状態のコピーをそのゾーンに追加することで、障害が発生したゾーンを置き換えることができます。図 6 に示すように、これを行うには、各シャードのコピーが新しいゾーンで使用可能であることを確認し、ログ処理サービスを実行してシャードを最新の WAL レコードで継続的に更新します。このようにして、ストレージ レイヤは、データベース レイヤのオーケストレーションや補助的なアクティビティを行わずに、すべてのゾーン フェイルオーバーを内部的に処理します。
これらの組み込みのストレージ レイヤ機能に加えて、AlloyDB は手動と自動の両方のバックアップ操作を統合して、アプリケーション レベルの障害やオペレーターの操作ミス(誤ってテーブルを削除するなど)への対策を講じます。
AlloyDB のインテリジェント ストレージでできること
要約すると、AlloyDB for PostgreSQL は、データベースのコンピューティング レイヤとストレージ レイヤを分離し、ログ処理システムを使用することで多くのデータベース操作をストレージ レイヤにオフロードします。ストレージ レイヤまで完全に分離されたアーキテクチャにより、AlloyDB for PostgreSQL は変化するワークロードに動的に適応できる弾力性のある分散クラスタとして機能し、耐障害性を強化し、可用性を高め、読み取りスループットを直線的にスケールするコスト効率の高い読み取りプールを実現します。オフロードすることで、プライマリ インスタンスの書き込みスループットも大幅に向上します。これは、プライマリ インスタンスがクエリ処理に専念して、メンテナンス タスクはストレージ レイヤに任せることができるからです。AlloyDB のインテリジェントなデータベース対応のストレージ レイヤとしての側面がこれに加わることで、AlloyDB の卓越したパフォーマンスと高可用性が実現されます。
cloud.google.com/alloydb にアクセスして、ぜひ AlloyDB をお試しください。AlloyDB の Columnar Engine に関する次の投稿もお楽しみに。
この投稿と今後の投稿で紹介する AlloyDB の技術革新は、Google のエンジニアリング チームの多大なる貢献により実現されました。
- AlloyDB for PostgreSQL エンジニアリング ディレクター Ravi Murthy
- プロダクト マネジメント担当ディレクター Gurmeet(GG)Goindi


