BigQuery DataFrames、Gemini、CARTO を使用してクラウド上で地図を作成する

Giulia Carella
Senior Data Scientist, CARTO
Alicia Williams
Developer Advocate
※この投稿は米国時間 2024 年 6 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
昨今のデータドリブンな世界において、きめ細かい分析情報を取得して情報に基づいた意思決定を行うには、位置情報を最大限に活用することが不可欠です。大規模な地理空間データセットに対応可能な BigQuery のスケーラビリティと効率性、そして CARTO の可視化機能を活用することで、Jupyter ノートブックを離れることなく、インタラクティブで優れた可視化を作成し、高度な空間分析を実行できるようになりました。
この投稿では、BigQuery DataFrames と CARTO の可視化ツールを組み合わせて使用して、Python ユーザーがクラウドネイティブ分析を利用できるようにする方法をご紹介します。
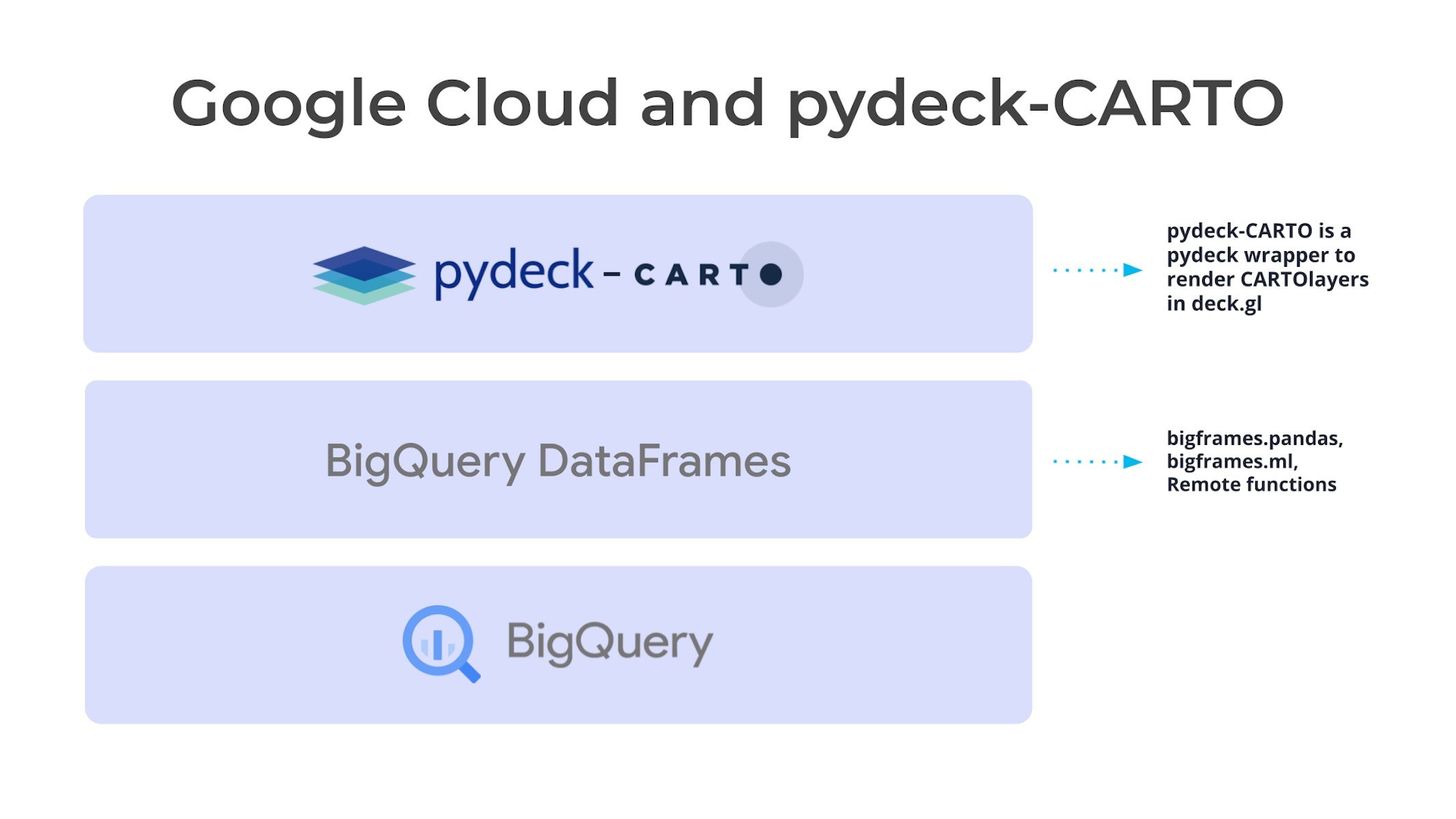
BigQuery DataFrames:「Pythonic」な DataFrame
BigQuery DataFrames は、pandas と scikit-learn の共通 API を提供するオープンソース ライブラリ群です。これらの API は、SQL 変換を通じて処理を BigQuery にプッシュダウンすることで実装されます。
Python 環境で作業しているデータ サイエンティストは、使い慣れた Python 構文を使用しながら、BigQuery DataFrames がもたらす BigQuery エンジンのスケーラビリティを活用できます。つまり、Python 環境とデータベース間でデータを転送する必要がないため、Jupyter ノートブックなどの単一プラットフォーム内でシームレスに作業できます。BigQuery DataFrames では、Python の効率を活かしてデータの操作と分析を行うことができます。ユーザーの意図はライブラリによって SQL に変換され、BigQuery にプッシュダウンされます。
大規模なデータセットの面倒な処理は BigQuery DataFrames がクラウド上で行うため、データ サイエンティストは得意分野に集中できます。つまり、任意のコーディング環境で、データのラングリング、分析、モデリングを大規模に実行できるのです。
pydeck-CARTO
pydeck-CARTO という Python ライブラリを使用すると、Jupyter ノートブックで CARTO を使って deck.gl 地図をレンダリングできます。このライブラリは CARTO と pydeck のインテグレーションとして機能し、さらなる橋渡しを実現します。ユーザーは Python ノートブック内で直接、地図のインタラクティブかつスケーラブルな可視化を作成できます。
この合理的なアプローチにより、さまざまなツール間でのコンテキストの切り替えが最小限で済むため、データ サイエンティストはノートブック内でデータと可視化を同時に繰り返し探索できます。そのため、地理空間データから分析情報を引き出すまでの時間を短縮できます。
BigQuery DataFrames と CARTO を組み合わせて地理空間分析を効率化
BigQuery DataFrames と CARTO の組み合わせの強みを示すために、実際の例を見てみましょう。このシナリオでは、米国における異常気象、大気汚染、医療へのアクセスの悪さによるリスクを表す複合インジケーターを作成し、Gemini 1.0 Pro モデルを使用してさまざまなリスクカテゴリを人間が読める形式で説明します。医療保険会社はこうした異なるリスク階層を使用することで、次のようなさまざまな意思決定プロセスにデータを活用できます。
-
保険料の設定: スコアが低い地域は保険料の引き下げに関連している可能性があります。これは、環境リスク要因の少なさとケアへのアクセスのしやすさによって医療の利用率が低くなっている可能性を示しています。
-
対象を絞った支援プログラム: 医療機関は、リスクスコアが高い地域への支援活動とリソース提供を優先して、予防医療対策と病気の早期発見を促すことができます。
-
リスク軽減戦略: 地理的な格差を埋めるために、保険会社はリスクが高い地域の現地の医療施設と連携して、ケアへのアクセスを改善したり、遠隔医療などの取り組みに投資したりできます。
この分析を確認して再現するには、CARTO の 14 日間の無料トライアルに登録し、CARTO チームが提供するこの Colab ノートブック テンプレートを実行してください。
ステップ 1: 設定
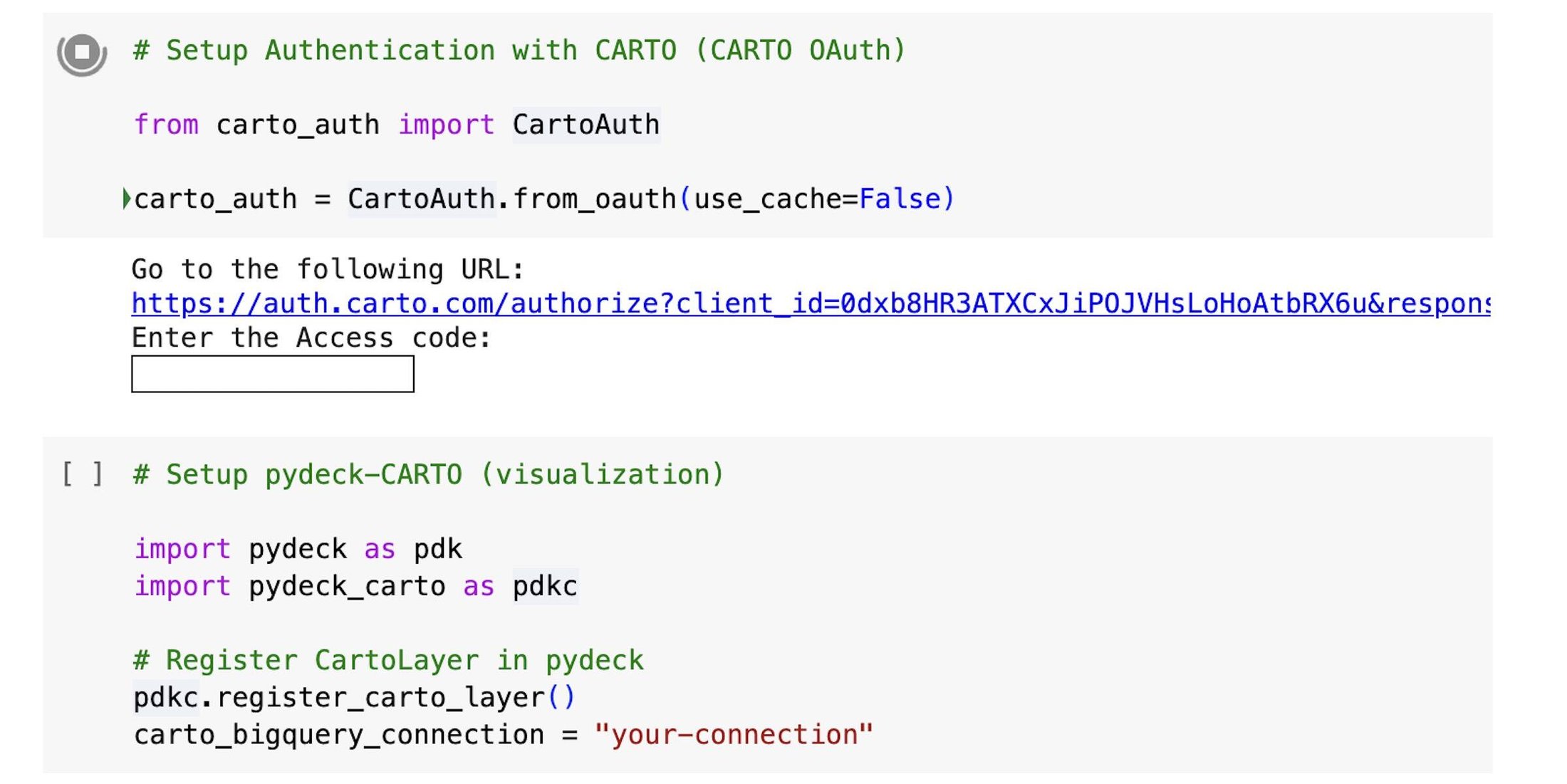
まず、BigQuery DataFrames ライブラリをインポートします。

次に、carto-auth の Python ライブラリを使用して CARTO への接続を設定し、CARTO アカウントにログインします。そして、pydeck に CartoLayer を登録します。これにより、CARTO プラットフォームで確立した任意のデータ ウェアハウス(BigQuery など)への接続からデータを可視化して、CARTO アカウントに関連付けられた CARTO Data Warehouse 内のデータ オブジェクトにアクセスできるようになります。
ステップ 2 - データを入力する
次に、データを BigQuery DataFrames にインポートします。
この例では、CARTO が管理する一般公開データセットとして BigQuery で提供されている以下のデータセットを使用します。すべてのデータセットは、Quadbin インデックスに基づいて階層型グリッドに変換されています。このインデックスは、高パフォーマンスな空間オペレーションを実現するために、解像度の異なるグリッドセル間の直接的な関係を示します。
-
ERA5 温度データ (
cartobq.docs.ERA5_t2m_1940_2023_glo_q10): ERA5 天候再解析によって得られた、1940 年から 2023 年までの月別の地表面温度データ。Quadbin の解像度 10 に変換されています。 -
医療サービスへの徒歩でのアクセスに関するデータ (
cartobq.docs.walking_only_travel_time_to_healthcare_usa_q15): 最寄りの医療センターまでの歩行時間(分数)。このデータはこの調査で取得されたもので、Quadbin の解像度 15 に変換されています。 -
PM2.5 濃度データ (
cartobq.docs.pm25_2012_2016_usa_q15): CIESIN が提供する、2012 年から 2015 年までの PM2.5 濃度の年間平均値。Quadbin の解像度 15 に変換されています。 -
空間的特徴 (
carto-data.<your-carto-data-warehouse>.sub_carto_derived_spatialfeatures_usa_quadgrid15_v1_yearly_v2): CARTO 空間的特徴の人口統計データ。CARTO によってキュレートされたグローバル データセットで、Quadbin の解像度 15 で一般公開されています。このデータにアクセスするには、この手順に沿って CARTO Workspace から一般公開データセットに登録してください。
read_gbq 関数を使用すると、上述のデータを読み取ることができます。この関数は、テーブルまたはクエリから取得したデータを使って BigQuery DataFrame を定義します。たとえば、次のコードを実行すると、24 GB の ERA5 温度データテーブルにアクセスできます。

次に、dt クラスを使用して、2018 年から 2022 年のデータのみを選択し、Quadbin ごとの最大値と最小値を計算します。
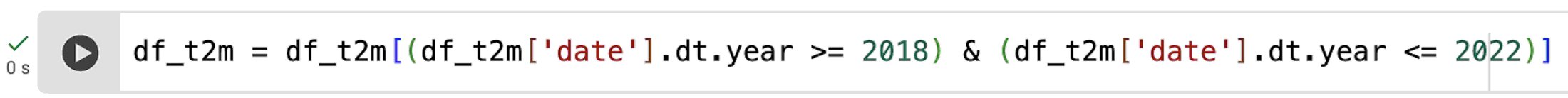

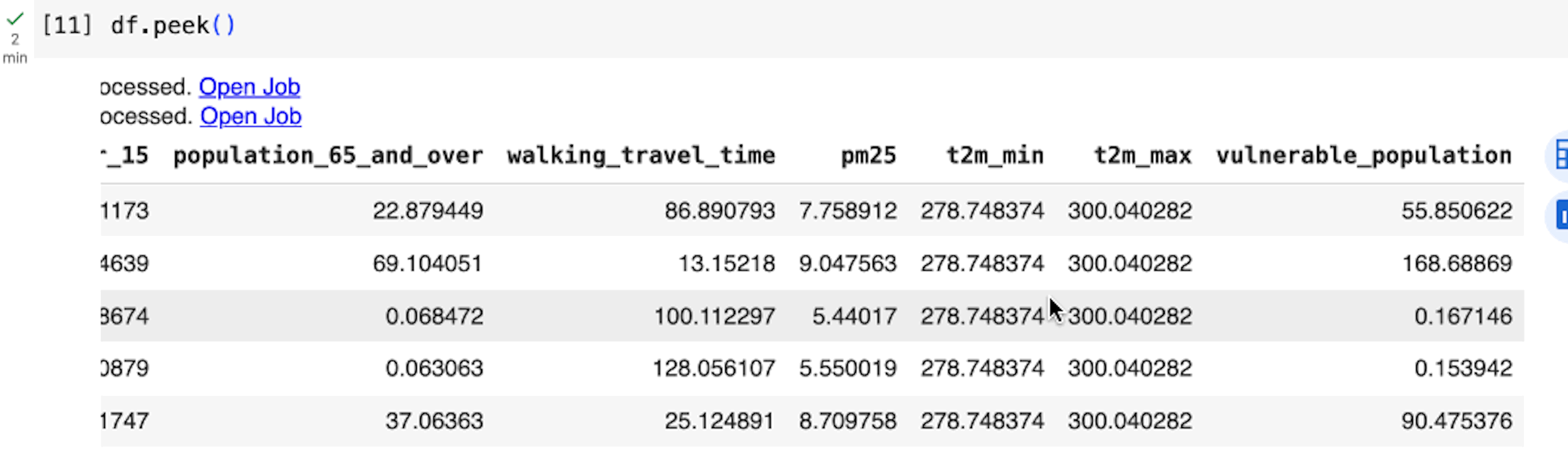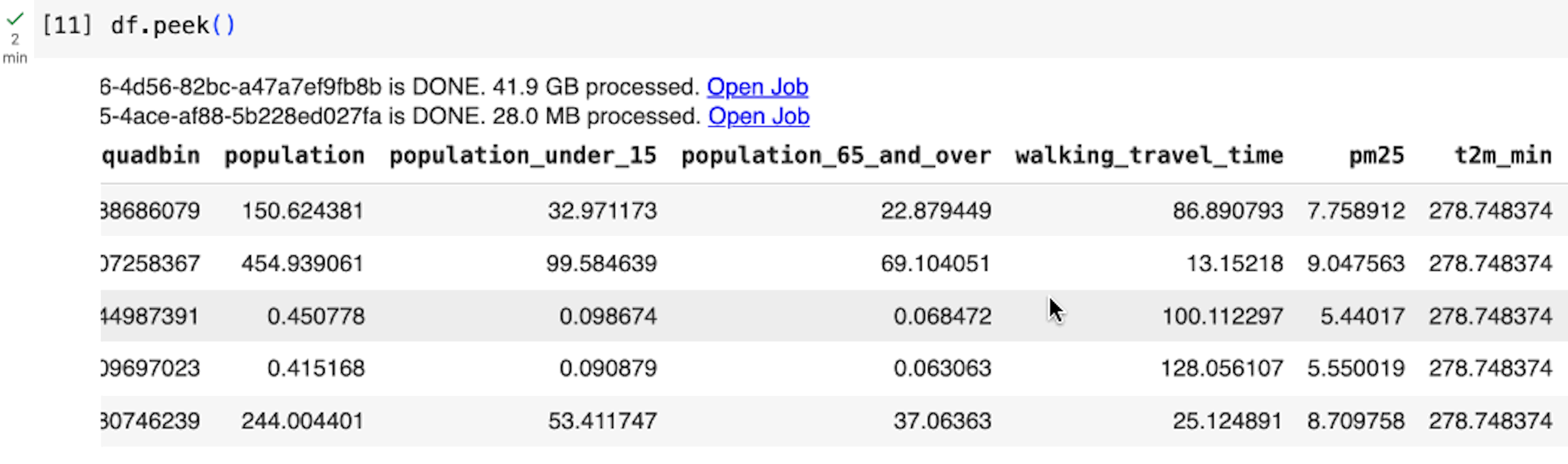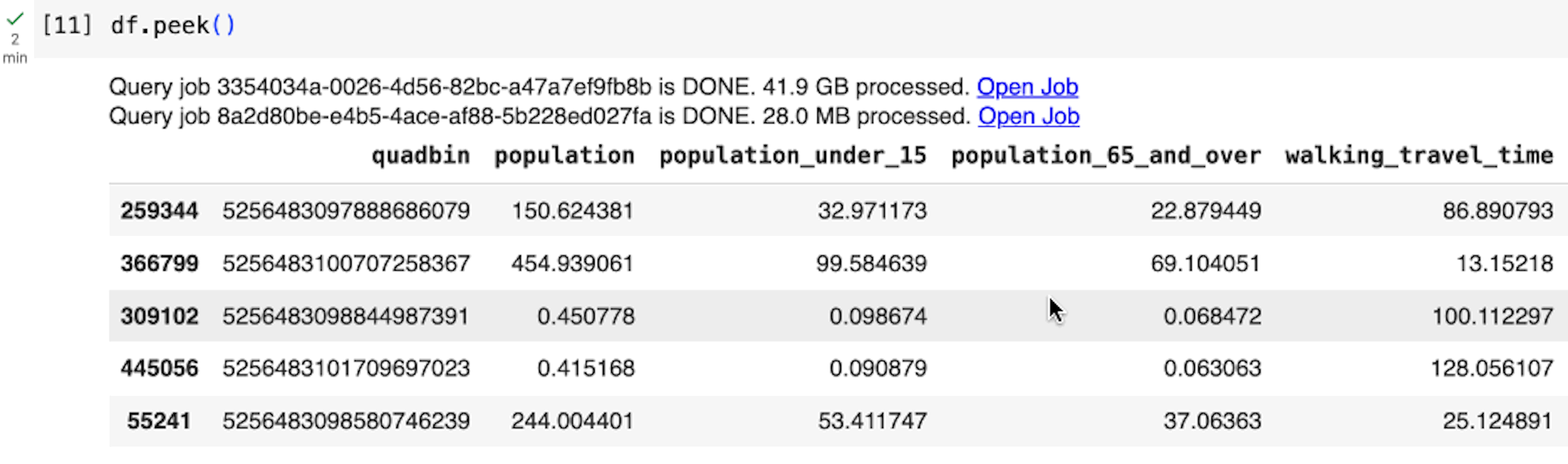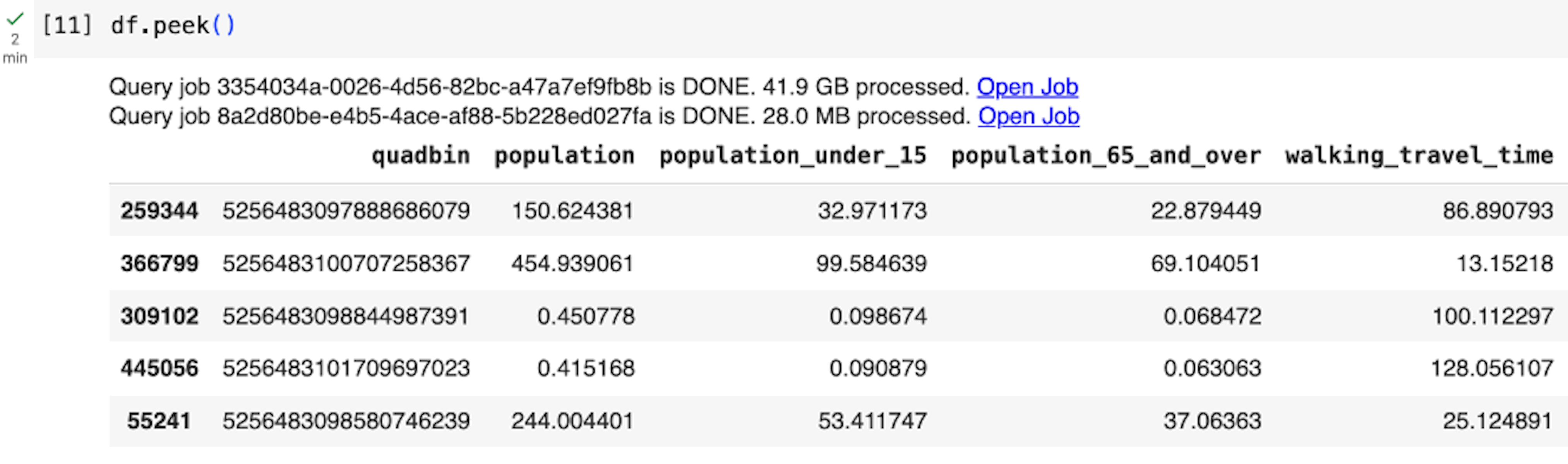
BigQuery DataFrames では、遅延実行のアプローチが採用されています。このアプローチでは、データがリクエストされるか読み取られるまで、クライアント側で徐々にクエリが構築されます(df.peek() を実行した場合など)。そのため、BigQuery は Python ステートメントごとにクエリを実行するのではなく、大規模なクエリ全体で最適化を行うことができます。
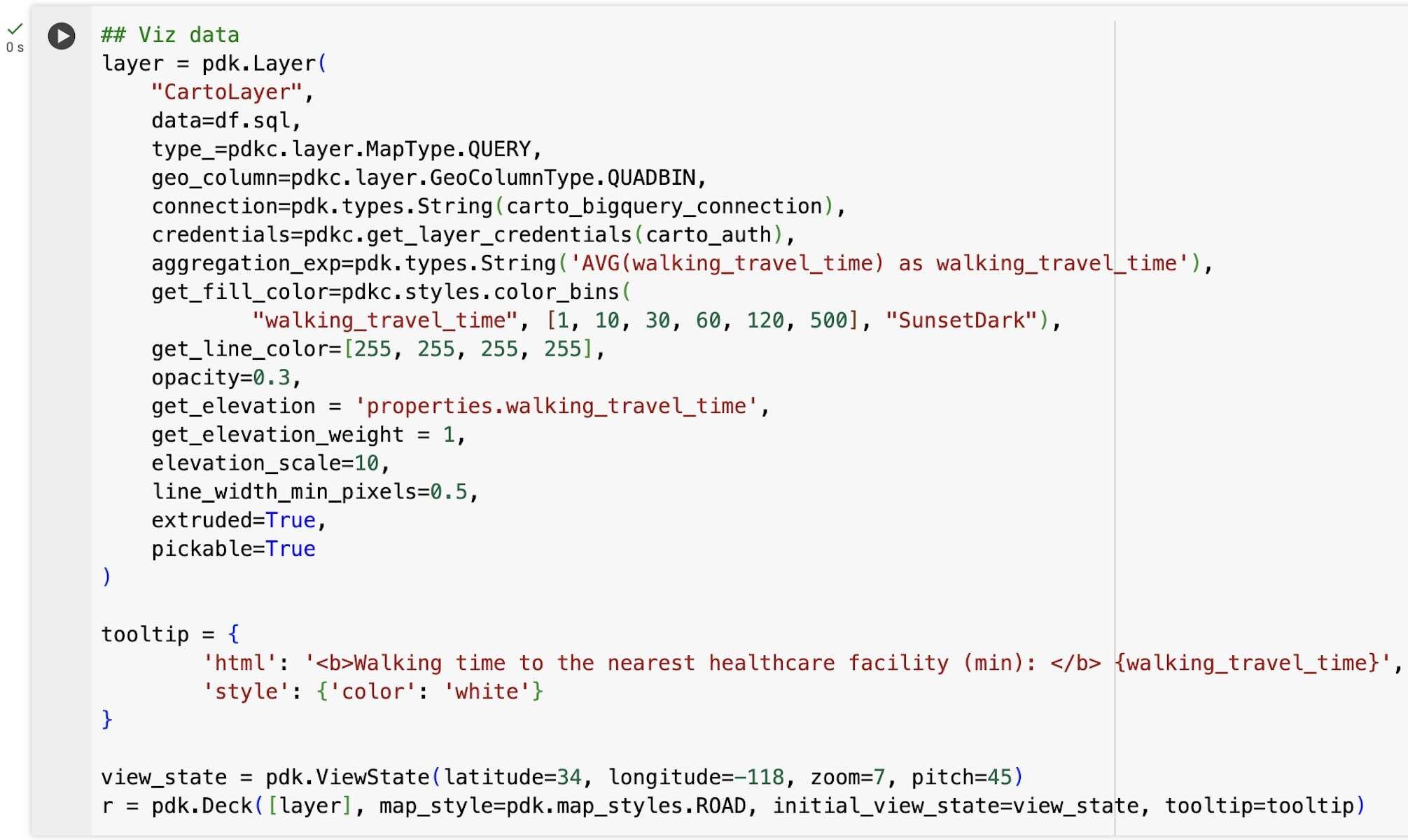
次に、最寄りの医療施設までの歩行時間を可視化するとします。生成する SQL クエリでは、BigQuery DataFrames の sql メソッドを pydeck-CARTO への入力として使用し、カラービン スタイルを適用した 3D 可視化を使って、医療へのアクセスに関する各種カテゴリで地域をわかりやすくハイライト表示します。

ステップ 3 - 複合インジケーターを作成する
次のステップでは、選択した外部要因による地域の複合的な健康リスクを表す複合インジケーターを定義します。ここで使用する外部要因は、最高温度と最低温度、PM2.5 濃度、全人口と要援護者人口(子どもと高齢者)、最寄りの医療施設までの歩行時間です。
インジケーターを計算する前に、すべての入力変数で、高い値がインジケーターの高い値に対応するようにします。ほとんどの変数ではそのように対応していますが、最低温度については、反転した値(値に -1 を掛ける)を使用することを検討します。

インジケーターは、選択した環境変数を使って主成分分析(PCA)の主成分スコアを算出することで導き出します。これには、次の PCA クラスを使用します。

主成分(PC)を出力することで、その記号(任意)が意図したとおりに最初の PC スコアと相関していることも確認できます。この場合、年間最高温度と PM2.5 濃度については PC との正の相関関係が必要であり、年間最低温度については記号を反転させた負の相関関係が必要です。この場合、算出された最初の PC スコアの記号を反転させる必要があります。
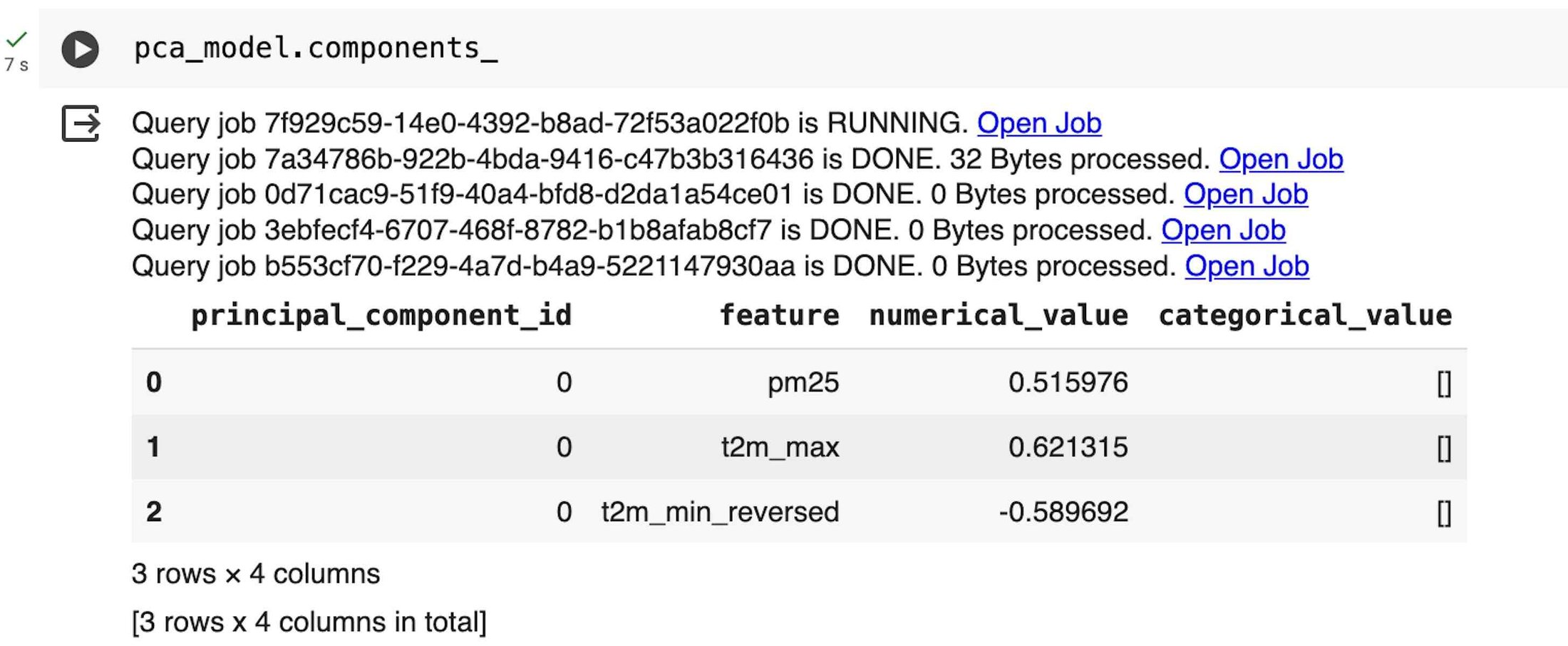
最初に算出された PC(データ内で分散が最大となる方向を示す)は、要援護者人口および最寄りの医療施設までの歩行時間と線形結合され、次元を比較できるように MinMaxScaler クラスを使って 0~1 の範囲にスケールされます。

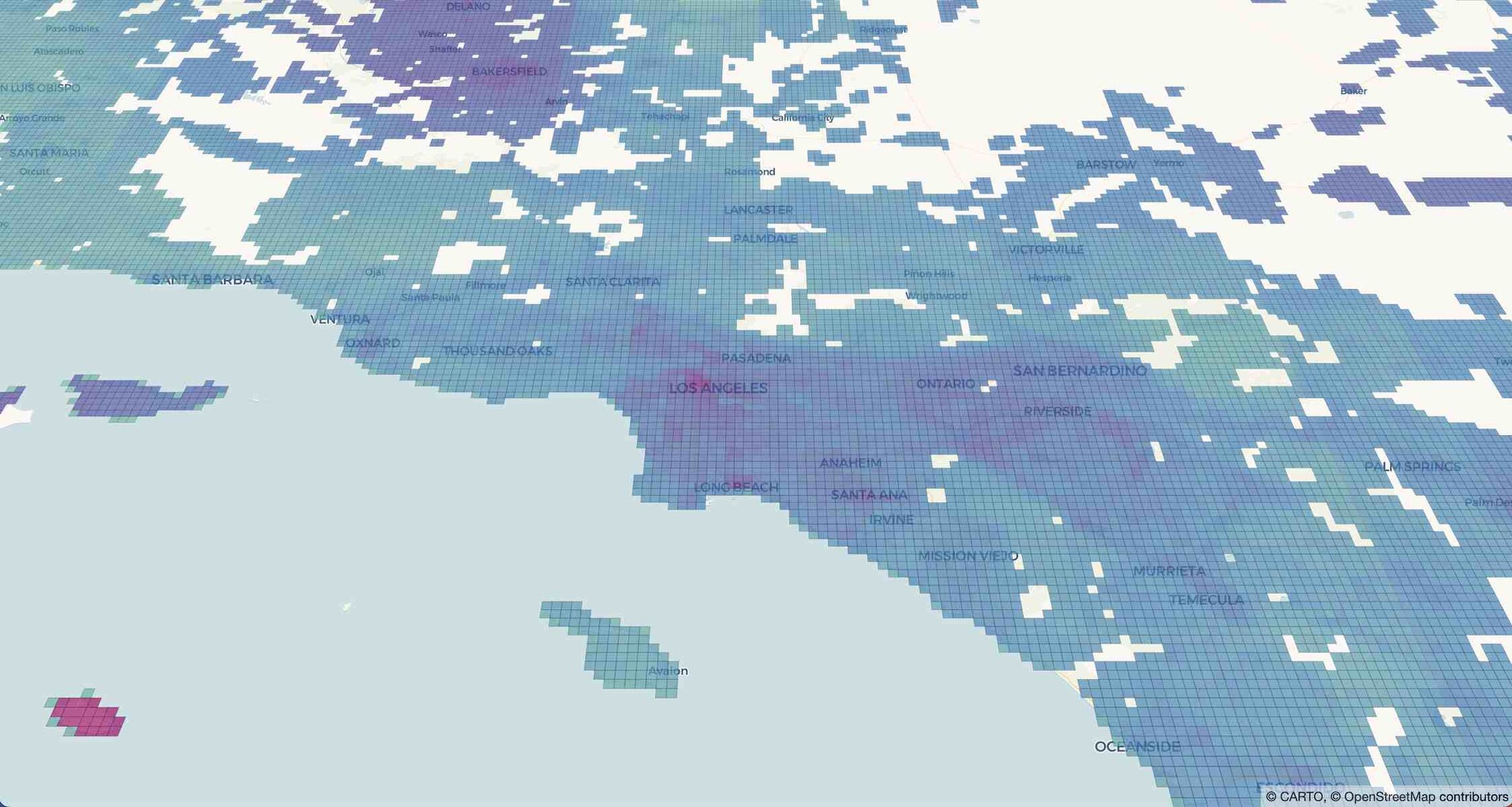
最後に、pydeck-CARTO で連続したカラーレイヤを使用して結果を地図上に可視化し、算出されたインジケーターを平滑化します。
ステップ 4 - 生成 AI を使用してインジケーターを説明する
最後のステップとして、さまざまなクラスのリスクスコア値を説明するプロンプトを使って、BigQuery DataFrames でデータセットを作成します。また、Gemini 1.0 Pro モデルを使用して、インジケーター値とその算出に使用された変数値に基づいて各クラスを説明します。
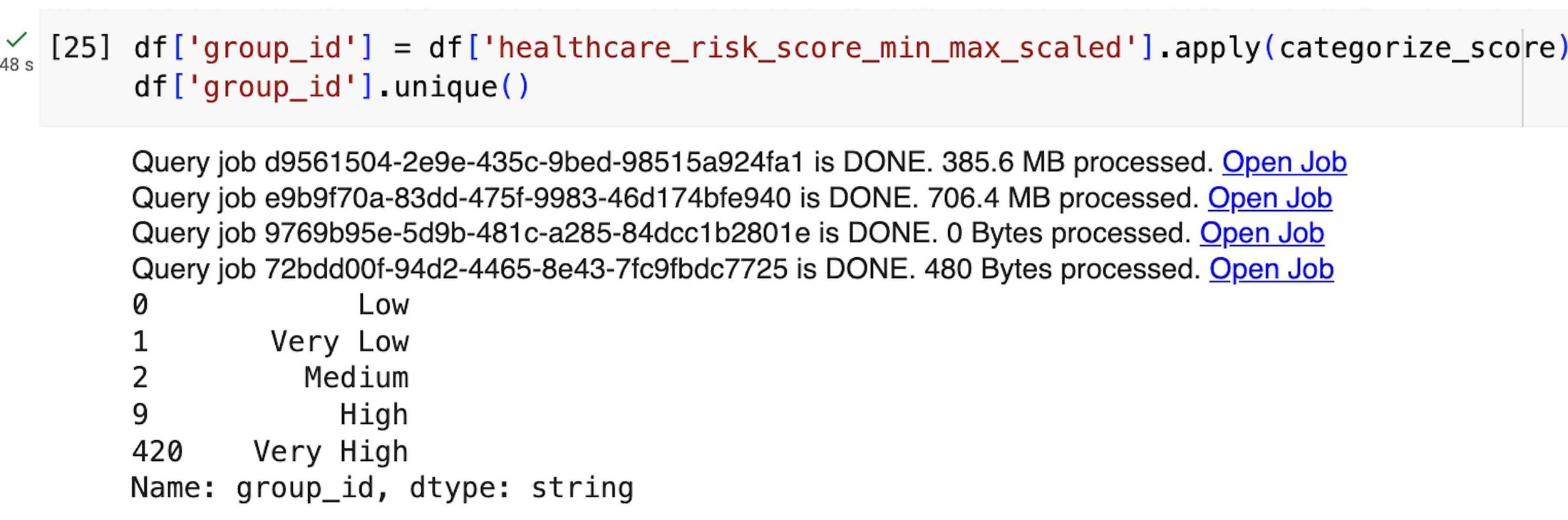
まず、リモート関数を作成して、スコアを 5 つの異なるリスクカテゴリ(非常に低い、低、中、高、非常に高い)に分類します。リモート関数を作成すると、カスタムのスカラー関数を BigQuery リモート関数に変換して、BigQuery DataFrames データセットに適用できます。

次に、インジケーターの算出に使用したすべての変数の平均値をカテゴリごとに算出し、それを全スコアカテゴリの平均値と比較します。そして、グループと母集団の平均値の関係を、その相対的な違いから導き出します。


採用したロジックによると、グループの平均値が母集団の平均値の ±10% の範囲にある場合、グループと母集団の平均値は類似しているとみなされます。グループ平均の絶対値と母集団の平均値に最大で 10 倍の差がある場合、グループの平均値は母集団の平均値より大きい(小さい)か、はるかに大きい(はるかに小さい)とみなされます。
次に、プロンプトを使って単一行の DataFrame を作成します。プロンプトの前には、タスクのコンテキストを定義する簡単な英語のリクエストを追加します。そして、GeminiTextGenerator モデルをインポートします。

最後に、Gemini にリクエストを送信して、プロンプトに対する回答を生成します。

これで、結果を地図上で可視化して、この分析結果について人が読める説明を追加できます。
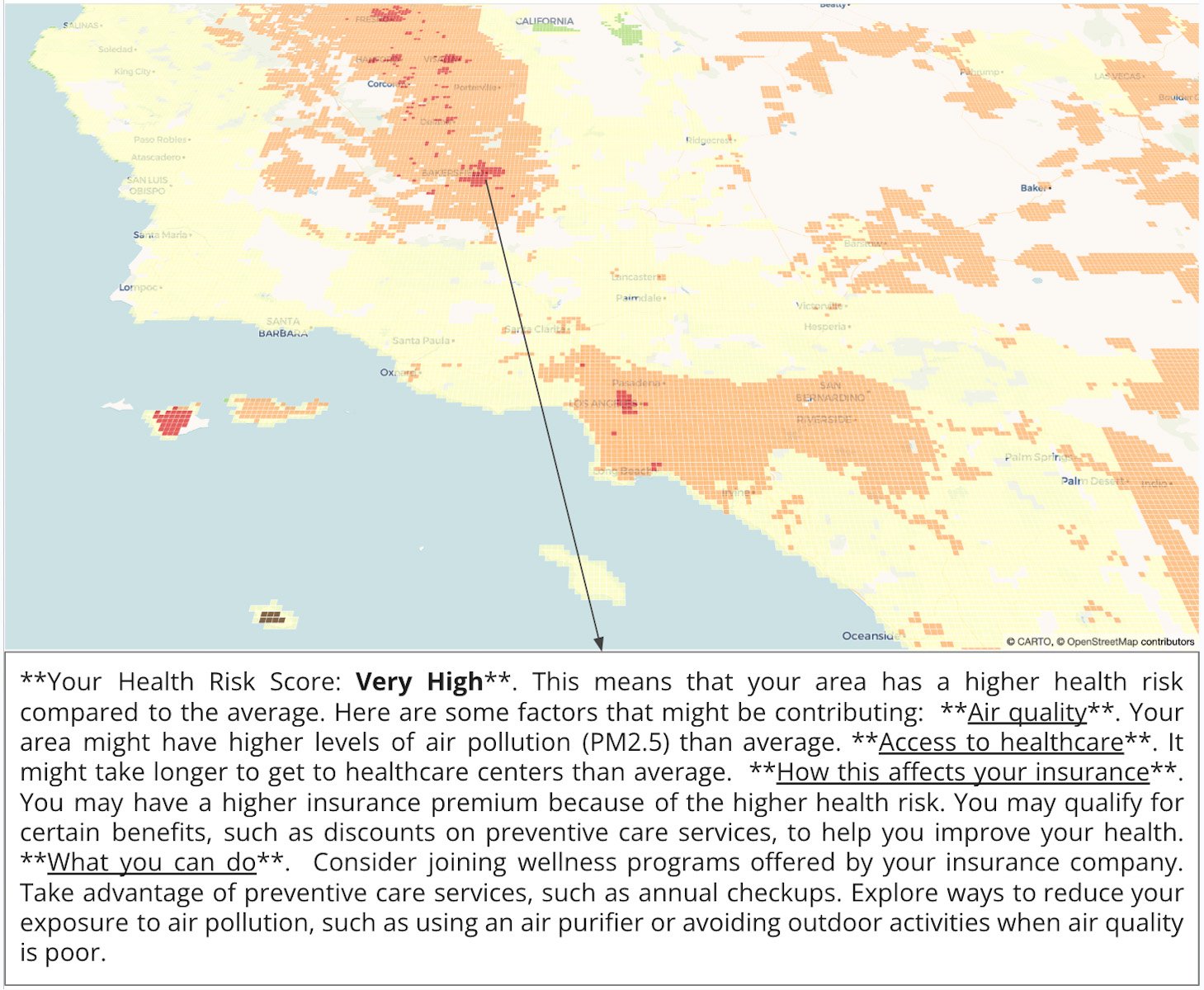
人が読める説明の一つが例としてハイライト表示された地図
位置情報を最大限に活用
このブログ投稿では、BigQuery DataFrames がどのように多様なユーザー(データ アナリスト、データ エンジニア、データ サイエンティストなど)を一つにまとめるツールとして機能するのか、そして、使い慣れた優れたインターフェースで大規模なデータセットを処理できる仕組みをご紹介しました。pydeck-CARTO とのスムーズなインテグレーションにより、ユーザーはノートブック環境内で直接インタラクティブな地図を作成できます。そのため、BigQuery DataFrames API は、データの探索、クリーニング、集約、ML 用のデータ準備などのタスクの簡素化をサポートするだけでなく、それらの能力を強化して、ユーザーが簡単に地理空間データから貴重な分析情報を抽出できるようにします。
CARTO と Google Cloud の無料トライアルに登録して、クラウド上のロケーション インテリジェンスをぜひお試しください。また、このブログ投稿で紹介されている例もご覧ください。BigQuery DataFrames の詳細については、サンプル ノートブックと概要ドキュメントをご覧ください。
-CARTO、シニア データ サイエンティスト Giulia Carella 氏
-Google Cloud、デベロッパー アドボケイト Alicia Williams



