データレイクとウェアハウスの統合を実現する BigLake の一般提供を開始

Google Cloud Japan Team
※この投稿は米国時間 2022 年 7 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
データの量は留まることなく増え続け、レイク、ウェアハウス、クラウド、ファイル形式にわたる分散化もますます進んでいます。より多くのユーザーが多様なユースケースを求める中、データ移動のインフラストラクチャを構築する従来型のアプローチではスケーリングが難しくなってきています。データの可能性を最大限に引き出すためにはこうしたサイロの解消が不可欠で、しだいにそれが企業にとっての最重要課題になってきています。
今年の初めに Google は、BigLake のプレビュー版を公開しました。これは、BigQuery ストレージでのイノベーションをさらに拡充したストレージ エンジンで、パブリック クラウドのオブジェクト ストア上で実行されているオープン ファイル形式にも対応したものです。これによりお客様は、オープン ファイル形式で安全にマルチクラウド データレイクを構築できるようになります。BigLake は、Google Cloud とオープンソースのクエリエンジン向けに、一貫性があり、きめの細かいセキュリティ管理を提供しながらデータを扱います。このたび、BigLake が一般提供されたことに加え、差別化されたデータ プラットフォームの構築をサポートする一連の新しい機能の提供が開始されたことをお知らせいたします。
「Deutsche Bank では、GCP を使用してウォール ストリートで最大級のリスクシステムを構築し、拡大しています。何度かテストを行う中で、BigLake の素晴らしい可能性とスケールを目の当たりにしました。ですから、BigLake こそが、クラウドへの移行やアプリケーションのさらなる効率化をサポートしてくれるプロダクトだと思っています」 - Deutsche Bank、ディレクター兼リスク CTO、Scott Condit 氏
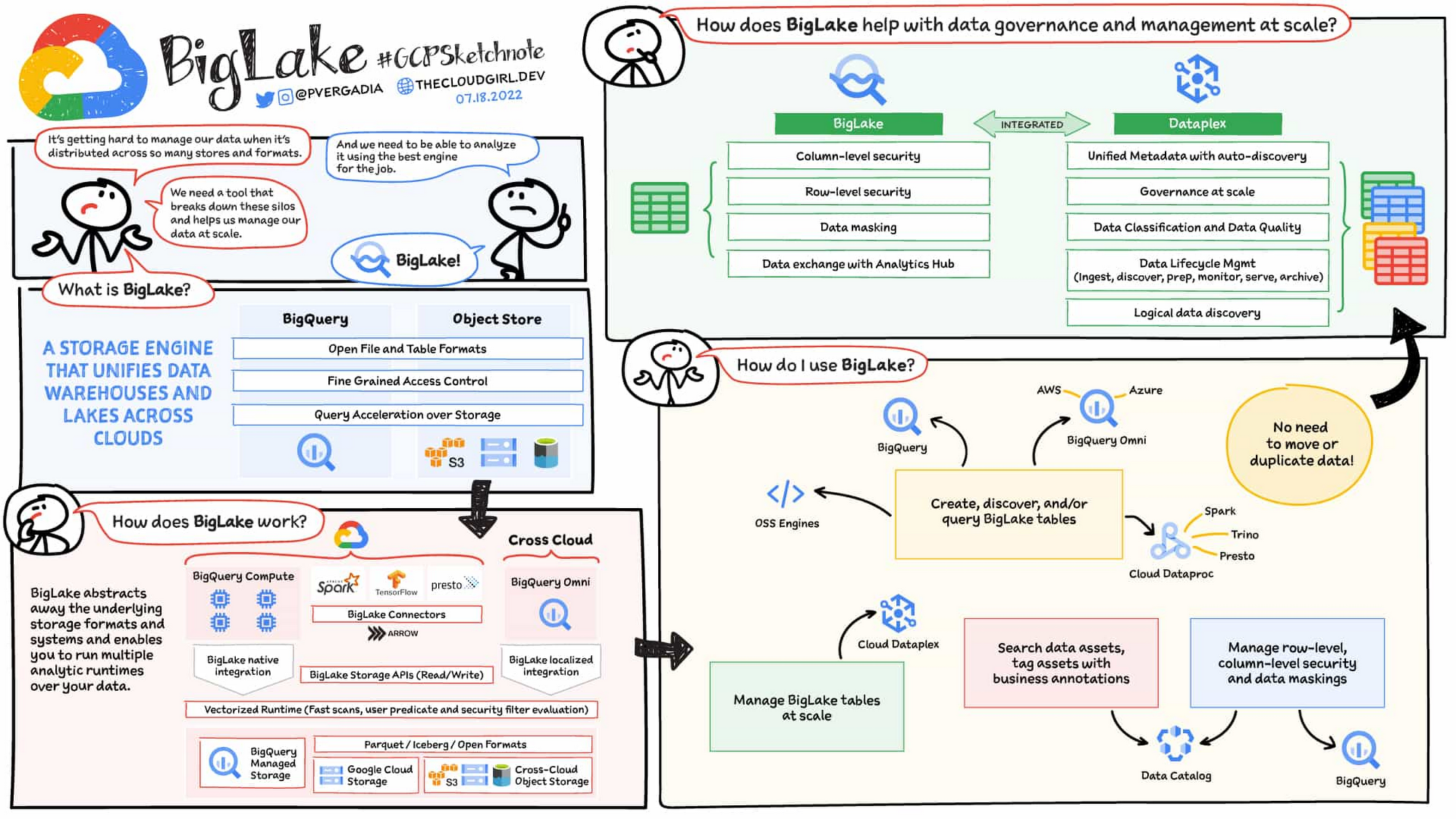
ウェアハウス、オブジェクト ストア、クラウドにわたる分散型データレイクを BigLake で構築
お客様は、Parquet、ORC、Avro などのサポートされたオープン ファイル形式を使用して Google Cloud Storage(GCS)、Amazon S3、ADLS Gen 2 上で BigLake のテーブルを作成することが可能です。BigLake テーブルは、データ ウェアハウスのテーブルと似た方法で管理できる新しいタイプの外部テーブルです。管理者は、エンドユーザーにオブジェクト ストア内のファイルへのアクセス権を付与する必要はありませんが、その代わりにテーブル、行、列レベルでアクセスを管理する必要があります。こうしたテーブルは、BigLake のコネクタを使用して、BigQuery やオープンソース エンジンといった任意のクエリエンジンから作成することができます。テーブルが作成された後は、BigLake や BigQuery のテーブルは、Data Catalog からの一元的な確認が可能となり、Dataplex を使用して大規模に管理できるようになります。
BigLake は、BigQuery Storage API をオブジェクト ストアに拡張することで、マルチコンピュータ アーキテクチャの構築を助けます。BigQuery Storage API 上に構築された BigLake のコネクタでは、セキュリティを提供することで Google Cloud DataFlow とオープンソース クエリ エンジン(Spark、Trino、Presto、Hive など)による BigLake テーブルへのクエリが可能となります。これにより、クエリエンジン特有のユースケースにデータを移行する必要がなくなり、1 か所で構成したセキュリティのためだけのニーズがあらゆる箇所で有効になります。
「Synapse LLC では、お客様のために GCP を使用してデータレイクのソリューションをデザインし、データドリブンな企業を生み出すためにお客様のデジタル戦略を転換しています。ELT パイプライン構築の必要性をなくし、製品化までの時間を削減することで、お客様にいち早く分析ソリューションの価値に気が付いてもらうためには、BigLake が必要不可欠です。BigLake のパフォーマンスとガバナンス機能が、お客様のさまざまなデータレイクのユースケースを実現してきました」 - Synapse LLC、創設役員、Sureet Bhurat 氏
Google Cloud と OSS クエリエンジンを使用して新たなユースケースの扉を開く BigLake
プレビュー版の際に、Google は数多くのお客様が BigLake をさまざまな方法で使用しているところを目の当たりにしました。ここで、よくあるユースケースの一部を紹介します。
オープンソース ワークロード向けの安全で管理されたデータレイクの構築 - Hadoop、Spark を初めて使用するお客様、または Presto / Trino を使用しているお客様のワークロードの移行には、BigLake を使用して GCS 上に、安全で、管理された、優れたパフォーマンスのデータレイクを構築することが可能です。GCS 上の BigLake テーブルでは、きめ細かなセキュリティ、(ファイルへのアクセス権を付与しない)テーブル管理、優れたクエリ パフォーマンス、Dataplex との統合されたガバナンスを提供しています。こうした機能は、BigLake のコネクタを使用することで、複数の OSS クエリエンジンからアクセスが可能となります。
「データドリブンな組織をサポートするために、Wizard はオープン ファイル形式を活用し、自社のニーズに合わせて成長できるデータレイクのソリューションを必要としていました。BigLake であれば、オープン ファイル形式での構築やクエリ、ニーズに合わせたスケーリング、分析情報の検出の促進が実現します。Wizard は、これから出てくるであろう BigLake の機能で、ユースケースをさらに拡大できると期待しています。」 - Wizard、シニア データ エンジニア、Rich Archer 氏
データ ウェアハウスやデータレイクにわたってデータの重複を排除または削減 - GCS や BigQuery マネージド ストレージを使用するお客様は、これまでは、BigQuery と OSS エンジンを使用するユーザーのデータをサポートするために、2 つのコピーを作成する必要がありました。BigLake では、GCS テーブルと BigQuery テーブルとの整合性をさらに強めることで、データ複製の手間を削減しています。それによりお客様は、今では BigQuery のストレージと GCS にわたって 1 つのコピーを所持できるようになり、さらに、一貫性のある安全な方法で、いずれか一方から BigQuery または OSS のエンジンにアクセスできるようになっています。
マルチクラウド ユースケースのためのきめ細かなセキュリティ - BigQuery Omni のお客様は、Amazon S3 および ADLS Gen 2 上で BigLake を使用して、きめ細かなセキュリティのアクセス制御を構成し、ローカルでのデータ処理や、マルチクラウド分析を行うためのクロスクラウド転送機能を活用できるようになりました。他のクラウドで作成されたテーブルは、管理やガバナンスの簡略化のために Data Catalog で一元的に検出可能となります。
分析ワークロードとデータ サイエンス ワークロード間の相互運用 - Spark または Vertex AI Notebooks のいずれかを使用したデータ サイエンス ワークロードでは、セキュリティを適用し、トレーニング モデル向けのデータをインポートする手間を削減することで、API コネクタを通じて BigQuery 内または GCS 内のデータに直接アクセスすることが可能となります。BigQuery のお客様は、これらのモデルを BigQuery ML に再度、インポートして推論を立てることができます。
BigLake の新しい機能で、差別化されたデータ プラットフォームを構築
今回の一般提供のリリースでは、新しい機能についても発表いたします。たとえば次のようなものです。
Analytics Hub のサポート: お客様は GCS 上の BigLake テーブルを、リンク済みデータセットという形でパートナー、ベンダー、サプライヤーと共有できるようになりました。お客様はお好きなクエリエンジン(BigQuery、Spark、Presto、Trino、TensorFlow)を通じてこのデータにアクセスできます。
BigLake テーブルは現在、BigQuery Omni をデフォルトのテーブルタイプとして設定しており、以前までデフォルトであった外部テーブルからアップグレードしています。
BigQuery ML のサポート: BigQuery のお客様は、データをインポートする必要なしに BigQuery ML を使用して GCS BigLake テーブル上でモデルをトレーニングすることができ、テーブルのアクセス ポリシーに沿ってデータにアクセスすることが可能です。
パフォーマンスの促進(プレビュー版): 基盤となる BigQuery インフラストラクチャを使用することで、GCS BigLake テーブル向けのクエリを促進できるようになります。こちらの機能の使用をご希望の場合は、Google のアカウント担当者にご連絡いただくか、こちらのフォームにご記入ください。
Cloud Data Loss Prevention(DLP)プロファイリング サポート(準備中): Cloud DLP では、間もなく BigLake テーブルのスキャンが可能となり、センシティブ データの特定や保護を大規模に行うことができるようになります。こちらの機能の使用をご希望の場合は、Google のアカウント担当者にご連絡ください。
データ マスキングと監査ロギング(準備中): BigLake テーブルでは、現在、動的なデータ マスキングをサポートしています。それにより、センシティブ データ要素のマスキングや、コンプライアンスのニーズへの対応が可能となります。BigLake テーブル向けのエンドユーザーからの GCS へのクエリ リクエストは、監査ログに記録され、ログからのクエリが可能となります。
次のステップ
BigLake のドキュメントを参照して詳細をご確認いただくか、こちらのクイック スタート チュートリアルを今すぐ開始してください。すでに外部テーブルを使用している場合は、前述の新しい機能を活用できるように、BigLake テーブルへのアップグレードをご検討ください。BigLake がどのようにお客様のデータ プラットフォームに価値をもたらすかについての詳細は、Google Cloud のアカウント担当者にお問い合わせください。このリリースを実現してくれた、Anoop Johnson、Thibaud Hottelier、Yuri Volobuev、その他の BigLake エンジニア チームに感謝します。
- Google Cloud シニア プロダクト マネージャー Gaurav Saxena
- Google Cloud ソフトウェア エンジニアリング マネージャー Justin Levandoski

