Unify data lakes and warehouses with BigLake, now generally available

Gaurav Saxena
Group Product Manager
Justin Levandoski
Director, Engineering
Data continues to grow in volume and is increasingly distributed across lakes, warehouses, clouds, and file formats. As more users demand more use cases, the traditional approach to build data movement infrastructure is proving difficult to scale. Unlocking the full potential of data requires breaking down these silos, and is increasingly a top priority for enterprises.
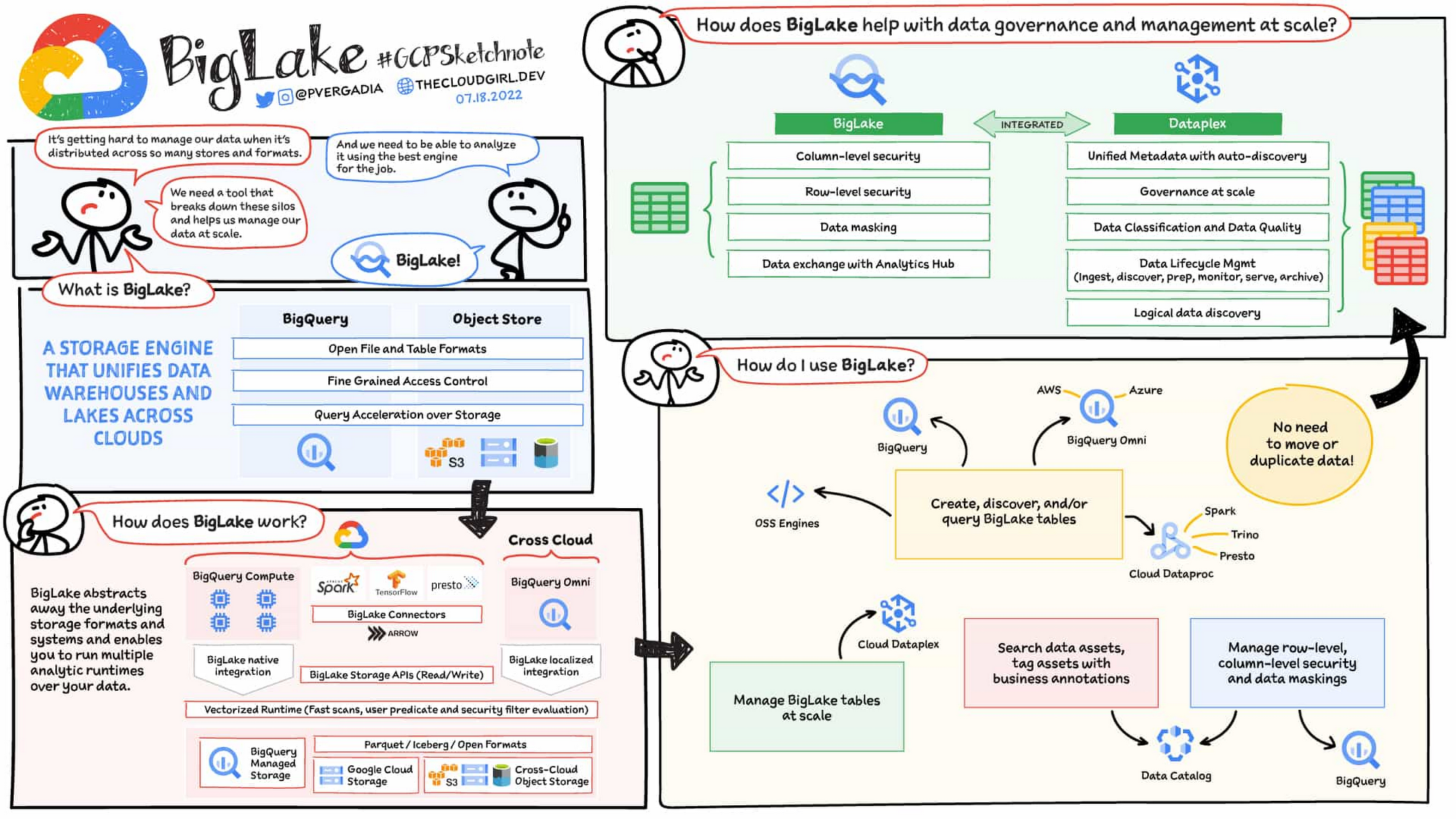
Earlier this year, we previewed BigLake, a storage engine that extends innovations in BigQuery storage to open file formats running on public cloud object stores. This allows customers to build secure multi-cloud data lakes over open file formats. BigLake provides consistent, fine-grained security controls for Google Cloud and open-source query engines to interact with data. Today, we are excited to announce General Availability for BigLake, and a set of new capabilities to help you build a differentiated data platform.
"We are using GCP to build and extend one of the street’s largest risk systems. During several tests we have seen the great potential and scale of BigLake. It is one of the products that could support our cloud journey and drive application’s future efficiency" - Scott Condit, Director, Risk CTO Deutsche Bank.
Build a distributed data lake that spans across warehouses, object stores & clouds with BigLake
Customers can create BigLake tables on Google Cloud Storage (GCS), Amazon S3 and ADLS Gen 2 over supported open file formats, such as Parquet, ORC and Avro. BigLake tables are a new type of external table that can be managed similar to data warehouse tables. Administrators do not need to grant end users access to files in object stores, but instead manage access at a table, row or a column level. These tables can be created from a query engine of your choice, such as BigQuery or open-source engines using the BigLake connector. Once these tables are created, BigLake and BigQuery tables can be centrally discovered in the data catalog and managed at scale using Dataplex.
BigLake extends the BigQuery storage API to object stores to help you build a multi-compute architecture. BigLake connectors are built on the BigQuery storage API and enable Google Cloud DataFlow and open-source query engines (such as Spark, Trino, Presto, Hive) to query BigLake tables by enforcing security. This eliminates the need to move the data to a query engine specific use case and security only needs to be configured at one place and is enforced everywhere.
"We are using GCP to design datalake solutions for our customers and transform their digital strategy to create a data-driven enterprise. Biglake has been critical for our customers to quickly realize the value of analytical solutions by reducing the need to build ETL pipelines and cutting-down time-to-market. The performance & governance features of BigLake enabled a variety of data lake use cases for our customers." - Sureet Bhurat, Founding Board member - Synapse LLC
BigLake unlocks new use cases using Google Cloud and OSS Query engines
During the preview, we saw a large number of customers use BigLake in various ways. Some of the top use cases include:
Building secure and governed data lakes for open-source workloads - Workloads migrating from Hadoop, Spark first customers, or those using Presto/Trino, can now use BigLake to build secure, governed and performant data lakes on GCS. BigLake tables on GCS provide fine-grained security, table management (vs giving access to files), better query performance and integrated governance with Dataplex. These characteristics are accessible across multiple OSS query engines when using the BigLake connectors.
"To support our data driven organization, Wizard needs a data lake solution that leverages open file formats and can grow to meet our needs. BigLake allows us to build and query on open file formats, scales to meet our needs, and accelerates our insight discovery. We look forward to expanding our use cases with future BigLake features" - Rich Archer, Senior Data Engineer - Wizard
Eliminate or reduce data duplication across data warehouses and lakes - Customers who use GCS, and BigQuery managed storage had to previously create two copies of data to support users using BigQuery and OSS engines. BigLake makes the GCS tables more consistent with BigQuery tables, reducing the need to duplicate data. Instead, customers can now keep a single copy of data split across BigQuery storage and GCS, and data can be accessed by BigQuery or OSS engines in either places in a consistent, secure manner.
Fine-grained security for multi-cloud use cases - BigQuery Omni customers can now use BigLake tables on Amazon S3, and ADLS Gen 2 to configure fine grained security access control, and take advantage of localized data processing, and cross cloud transfer capabilities to do multi-cloud analytics. Tables created on other clouds are centrally discoverable on Data catalog for ease of management & governance
Interoperability between analytics and data science workloads - Data science workloads, using either Spark or Vertex AI notebooks can now directly access data in BigQuery or GCS through the API connector, enforcing security & eliminating the need to import data for training models. For BigQuery customers, these models can be imported back into BigQuery ML to produce inferences.
Build a differentiated data platform with new BigLake capabilities
We are also excited to announce new capabilities as part of this General Availability launch. These include:
- Analytics Hub support: Customers can now share BigLake tables on GCS with partners, vendors or suppliers as linked data sets. Consumers can access this data in place through the preferred query engine of their choice (BigQuery, Spark, Presto, Trino, Tensorflow).
- BigLake tables is now the default table type BigQuery Omni, and has been upgraded from the previous default of external tables.
- BigQuery ML support: BigQuery customers can now train their models on GCS BigLake tables using BigQuery ML, without needing to import data, and accessing the data in accordance to the access policies on the table.
- Performance acceleration (preview): Queries for GCS BigLake tables can now be accelerated using the underlying BigQuery infrastructure. If you would like to use this feature please get in touch with your account team or fill out this form.
- Cloud Data Loss Prevention (DLP) profiling support: Cloud DLP can scan BigLake tables to identify and protect sensitive data at scale. You can get started here.
- Data masking and audit logging (Coming soon): BigLake tables now support dynamic data masking, enabling you to mask sensitive data elements to meet compliance needs. End user query requests to GCS for BigLake tables are now audit logged and are available to query via logs.
Next steps
Refer to BigLake documentation to learn more, or get started with this quick start tutorial. If you are already using external tables today, consider upgrading them to BigLake tables to take advantage of above mentioned new features. For more information, reach out to the Google cloud account team to see how BigLake can add value to your data platform.
Special mention to Anoop Johnson, Thibaud Hottelier, Yuri Volobuev and rest of the BigLake engineering team to make this launch possible.