Dataproc の自動スケーリング機能強化により、費用を削減しジョブ実行時間を短縮
Google Cloud Japan Team
※この投稿は米国時間 2023 年 10 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
Dataproc は、Apache Hadoop、Apache Spark および 30 以上のオープンソースのツールとフレームワークを実行するための、スケーラビリティに優れたフルマネージド サービスです。Google Cloud のお客様は、Dataproc の自動スケーリングを使用して、ワークロードの要件に応じてクラスタを動的にスケールし、費用を節約できます。2023 年 7 月、Dataproc の自動スケーリングが以下のように改善および機能強化されました。
- 応答性 - 自動スケーリングの処理速度が向上
- パフォーマンス - 自動スケーリングの処理の所要時間が短縮
- 信頼性 - クラスタの自動スケーリング エラーが減少
- オブザーバビリティ - オートスケーラーの推奨事項をログに記録
これらの機能強化によってどのような効果が得られるかを確認するために、自動スケーリングの機能強化前と後のクラスタで、同じ Spark ジョブセットを実行するテストを実施しました。このテストによって、機能強化された新しい Dataproc の自動スケーリングではクラスタの VM の費用が最大 40%*、ジョブの実行時間の合計が 10% 減少することがわかりました。
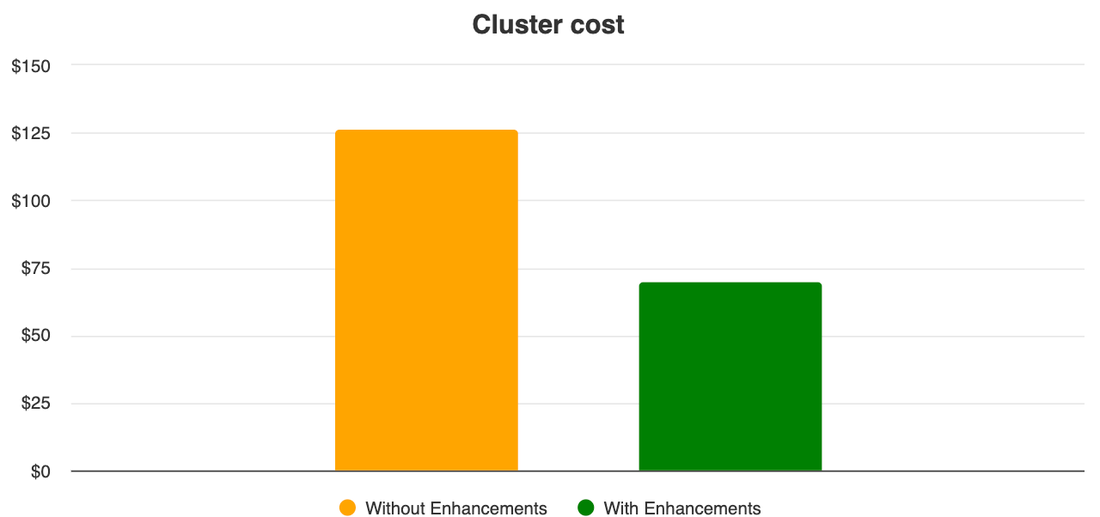
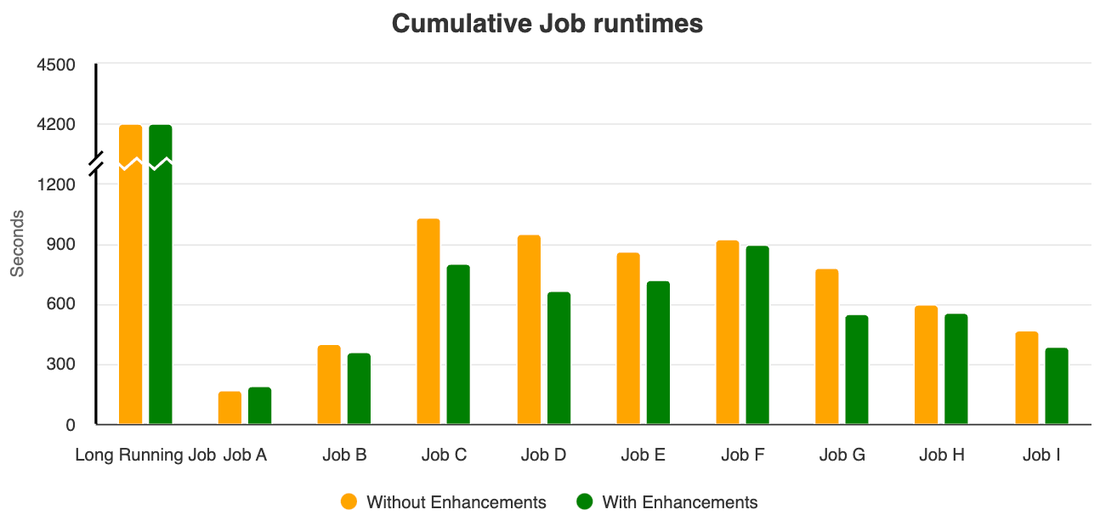
機能強化の大部分は、2.0.66 および 2.1.18 よりも新しいイメージ バージョンで利用できます。
では、機能強化の項目ごとに、費用や実行時間への影響を見ていきましょう。
スケールアップの応答性改善によるジョブ パフォーマンスの向上
Dataproc のオートスケーラーは、YARN のメモリおよび CPU 指標を継続的にモニタリングし、スケールアップまたはスケールダウンの判断を行っています。正常なデコミッションでスケールダウンを実行している間も、クラスタ指標を継続的にモニタリングし、自動スケーリングのポリシーに基づき、ジョブの要件を満たすためにスケールアップが必要であるかどうかを評価しています。たとえば、ジョブが完了したタイミングでクラスタのスケールダウンがトリガーされた後、新しいジョブの送信が急増した場合、オートスケーラーはスケールダウンをキャンセルして、スケールアップをトリガーします。スケールアップの仕組みがこのように改善されたことで、正常なデコミッションによってスケールアップの処理が阻まれることがなくなり、ワークロードの要件に対するクラスタの応答性が向上しました。
Cloud Monitoring の以下のグラフでは、テスト対象のクラスタにおいてスケールアップ時の応答性が改善していることがわかります。機能強化前のクラスタでは、オートスケーラーは YARN 保留中メモリの変化に応答していません。一方、機能強化後のクラスタでは、オートスケーラーは YARN 保留中メモリの折れ線グラフで示されている需要に応じて、クラスタのスケールダウンをキャンセルし、スケールアップを実行していることがわかります。縦の破線は、スケールアップがトリガーされたタイミングを示しています。
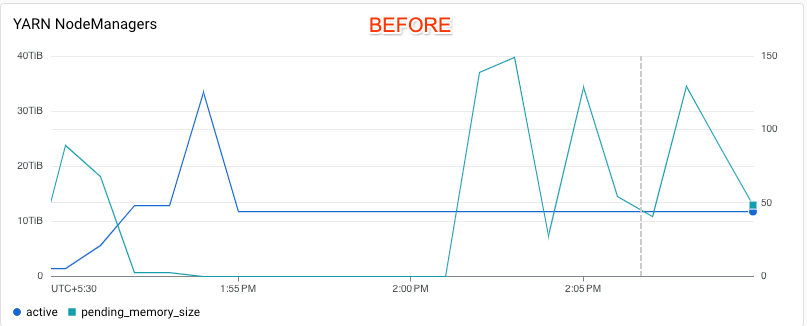
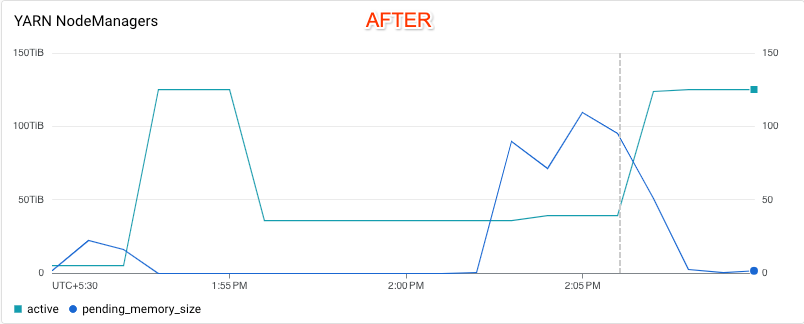
詳しくは、自動スケーリングによってスケールダウン オペレーションがキャンセルされるタイミングをご覧ください。
オートスケーラーの処理の可視性向上
この機能強化では、オートスケーラーのログが改善されました。このログでも、スケールダウンをキャンセルしてスケールアップに切り替えるという判断が行われたことがわかります。
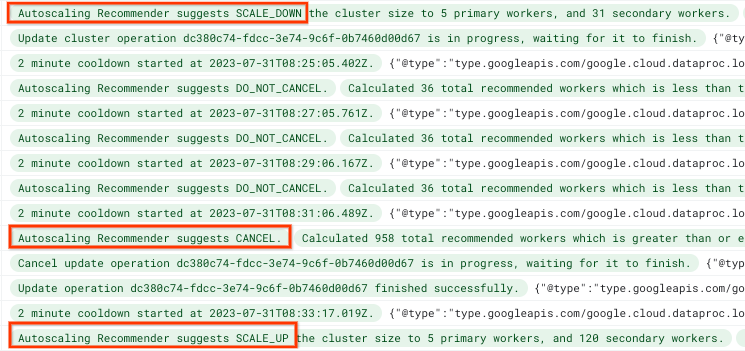
Dataproc のクラスタ費用の削減とスケールダウン時間の短縮
ワーカーを的確に選択し、高速スケールダウンを実現
新しい Dataproc では、複数の指標をモニタリングして、スケールダウン対象のワーカーを選択するようになりました。具体的には、クラスタに含まれる各ワーカーについて、以下の指標を評価します。
- 実行中の YARN コンテナの数
- 実行中の YARN アプリケーション マスターの数
- Spark シャッフル データの合計量
これらの指標に基づき、アイドル状態のワーカーを選択することで、スケールダウンの時間を短縮しています。
シャッフル データの移行およびシャッフル状況を踏まえたデコミッションにより、高速かつ信頼性の高いスケールダウンを実現
デコミッション対象のワーカー上に、実行中のエグゼキュータやシャッフル データがある場合、スケールダウンの処理が遅くなります。デコミッションを高速化するため、以下のような変更を加えました。
- デコミッション予定のワーカー上のアクティブなエグゼキュータが、新しいタスクを受け付けないようにする。これにより、エグゼキュータが早く完了するようになり、ワーカーのデコミッションがより早く開始されます。
- 実行中のエグゼキュータやシャッフル データがないワーカーを直ちにデコミッションする
- デコミッション予定のワーカー上のシャッフル データを移行して、ワーカーを直ちにデコミッションする
テストを実施した 2 つのクラスタのうち、機能強化前のほうでは、トリガーされた正常なデコミッションに丸 1 時間(自動スケーリング ポリシーの gracefulDecommissionTimeout の長さ)がかかっています。一方、機能強化後のほうでは、クラスタ上でジョブがまだ実行されているにもかかわらず、デコミッションが早く終了しています。
機能強化前のクラスタでは、大規模なスケールダウンがすべて完了するまでに 61 分かかっていました(以下を参照)。
機能強化後のほうでは、大規模なクラスタのスケールダウンがキャンセルされ、スケールアップが行われています。ただし、その後に実行されたスケールダウンが完了するのに 34 分しかかかっていません(以下を参照)。
YARN リソース マネージャーのログによると、シャッフル データの移行完了と同時に、ワーカーが DECOMMISSIONED の状態になっていることがわかります(以下を参照)。
この機能強化は、Dataproc のイメージ バージョン 2.1.18+ でのみサポートされます。
デコミッションが完了したワーカーを直ちに削除
Dataproc では、スケールダウンの最中に、各ワーカーのデコミッション ステータスをモニタリングし、デコミッションが完了したワーカーをすぐに削除するようになりました。以前は、すべてのワーカーがデコミッションされるまで待機してから、VM を削除していました。この機能強化によって、クラスタ内の正常なデコミッションに長い時間を要するワーカーのデコミッションに、他よりも極端に時間がかかるケースで費用を節約できます。
テストのセットアップ
自動スケーリングの機能強化の効果を確認するために、以下の同じ構成で 2 つのクラスタを作成しました。
- マスターとワーカーのマシンタイプ n2d-standard-16、2 つのローカル SSD をアタッチ、5 個のプライマリ ワーカー、0~120 個で自動スケーリングされるセカンダリ ワーカー。
- デフォルトのクラスタ構成を統一
- 以下の同じ自動スケーリング ポリシーを適用:
両方のクラスタで以下の同じジョブを実行しました。
- 一定のリソースセットを使用する、実行時間の長いカスタム Spark ジョブ。以下のジョブと平行して実行。
- 多数の短い Spark ジョブ。1 TB データセットに対して、変更を加えた TPC-DS ベンチマークのクエリをいくつか同時実行する。ジョブの急増およびアイドル状態をシミュレートするために実行間にアイドル時間を設けた。
Dataproc のイメージ バージョン 2.1.3-debian11(自動スケーリングの機能強化前)と、新しいイメージ バージョン 2.1.19-debian11(機能強化後)で、クラスタを 1 つずつ作成しました。
自動スケーリングの機能強化は、イメージ バージョン 2.0.66+ と 2.1.18+ でデフォルトで利用できます。これらの機能強化を活用するために、クラスタの構成や自動スケーリング ポリシーを変更する必要はありません。Spark のシャッフル データの移行は、イメージ バージョン 2.1 でのみ利用できます。
まとめ
このブログ投稿では、Dataproc の自動スケーリングの機能強化によってもたらされる費用削減およびジョブ パフォーマンスの改善について紹介しました。これらの機能強化点を活用するために、管理者がクラスタ構成や自動スケーリング ポリシーを変更する必要はありません。Dataproc を使ってみるには、Dataproc クイックスタートをご覧ください。Dataproc の自動スケーリングに関するドキュメントもあわせてお読みください。
* 2023 年 8 月時点、正規料金、このブログ投稿に記載したテストのセットアップを使用
-Sagar Narla
-Deependra Patel

