BigQuery のスーパーパワーを引き出す 10 個の重要なヒント
Google Cloud Japan Team
※この投稿は米国時間 2020 年 1 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
私たち開発者の多くは、日中仕事をしているときはテクノロジーのヒーローといえます。たとえば SQL について知っているなら、あなたはデータをインサイトに変換できる能力を持ったヒーローです。困っている人が助けを求めてきたら、ビジネス提案書に載せるべき魔法の数字を教えて窮地から救ってあげることができます。データレイクを調べて見つけたパターンで同僚を驚かせることも。
Google Cloud のエンタープライズ データ ウェアハウスである BigQuery を使用すれば、すぐにスーパーヒーローになれます。他の誰よりも速くクエリを実行でき、テーブル全体のスキャンだって恐くありません。データセットを高度に利用可能な状態にできるので、メンテナンスの時間枠におびえる必要もなくなります。データのインデックス登録もバキュームも必要ありません。
BigQuery ユーザーであれば、あなたはすでにスーパーヒーローです。しかし、スーパーヒーローが自身のスーパーパワーやその使い方を知っているとは限りません。まだご存知ないかもしれない BigQuery のスーパーパワー トップ 10 をご紹介します。

1. データの力
大切な友達が邪悪な勢力に捕らわれ、助け出すには次のシンプルななぞなぞを解かなければならないとしましょう。「2018 年 2 月の第 1 週に Wikipedia で最も閲覧されたスーパーヒーローは誰だったでしょう?」
どうすればよいでしょうか?Wikipedia の全ページビューのログはどこから入手しますか?どれがスーパーヒーローのページかどうやって判断しますか?このデータをすべて収集し、くまなくチェックするのにどのくらいの時間がかかるでしょうか?私ならこのなぞなぞを解くことができます(こちらからソースデータをご覧ください)。データが読み込まれたら、クエリ結果を得るまで 10 秒しかかかりません。やり方は次のとおりです。英語版 Wikipedia のすべてのスーパーヒーローのページと、所定の期間のページビューの数は、次のような結果になりました。2018 年 2 月の第 1 週のトップ 10 は次のとおりです。
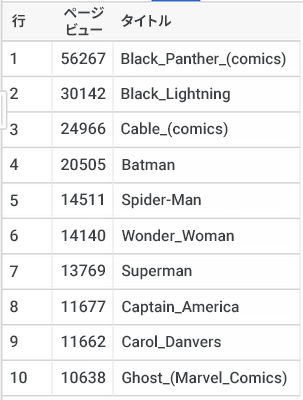
これで友達を救うことができます!しかし邪悪な勢力は、まずデータの詳細を渡せと言います。それには、こちらのクエリを使用できます。
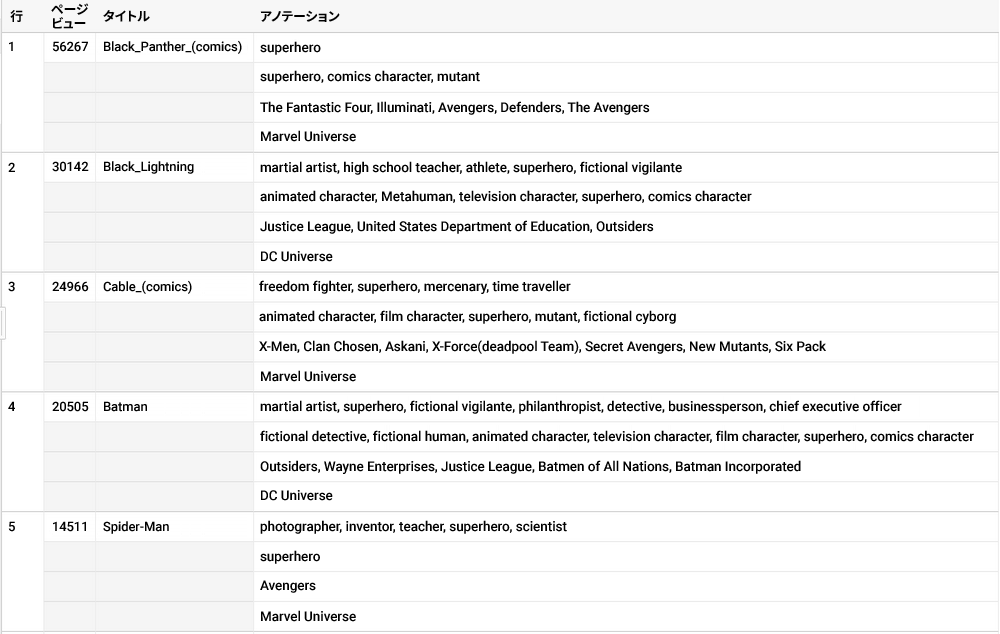
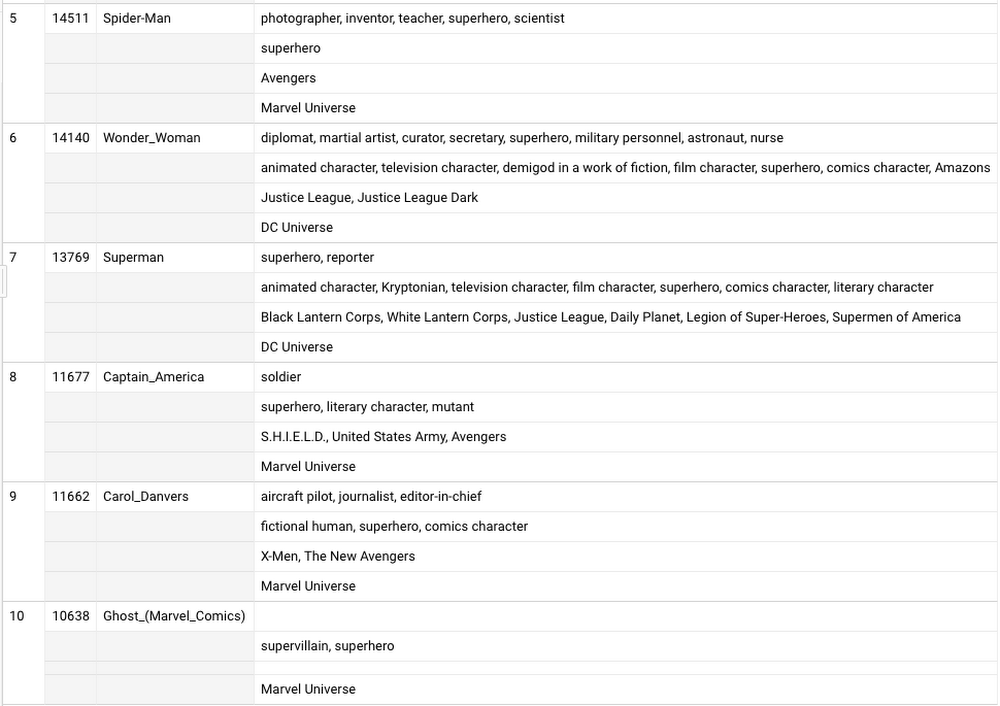
あなたもデータの力を手にすることができます。Wikipedia のページビューに関するデータと、私が実施したウィキデータに関する最新のテスト(および BigQuery のすべての一般公開データ)を参考にしてください。テストで使用したクエリをコピーして貼り付け、修正を加えて友達を救いましょう。
2. テレポーテーションの力
Wikipedia ページビューとウィキデータのテーブルを見てみたいですか?BigQuery ウェブ UI に移動しましょう。クエリの入力中にオートコンプリート機能を使用できるのをご存知ですか?クエリを記述しているときに Tab キーを押すだけでできます。サブクエリを選択して Ctrl+E キーを押せば、サブクエリを実行することもできます。テレポーテーションの力を使いたい場合は、Ctrl キーを押しながらクリックすればテーブルに直接移動できます。たとえば、先ほどクエリを実行した Wikipedia 2018 ページビュー テーブルには 2 TB 以上のデータがあり、ウィキデータのテーブルには 4,600 万 エンティティのファクトがあります。これらを結合してなぞなぞの答えを出しました。
また、スキーマを見ているときにフィールドをクリックすれば、クエリが自動入力されます。これらがテレポーテーションの力です。
3. ミニチュアリゼーションの力
ページビュー テーブルのデータは 2 TB 以上ありました。これは膨大な量です。BigQuery では毎月 1 TB のクエリを無料で実行できます。2 TB のクエリだと、無料の割り当てをすぐに超えてしまうことになります。実際に消費した割り当てはどのくらいだったでしょうか?最初のクエリを、今後はキャッシュにヒットさせないでもう一度実行してみましょう。
結果はどうなったでしょう?処理されたのは 4.6 秒間で 9.8 GB でした。
これはどうして可能なのでしょうか?このクエリでは 2 TB と 750 GB のテーブルを結合しました。パーティショニングを使用すれば、1 週間の Wikipedia ページビューは、2 TB を 52 週で割った 38.5 GB になります。日単位でパーティショニングすれば、クエリを実行するデータはさらに少なくなります。
テーブル内のデータは Wikipedia の言語とタイトルでクラスタ化されているので、Wikipedia ログを調べるときはそれらのフィルタをいつでも使用できます。
このクエリの処理には、より時間がかかりました。それはなぜでしょうか?透視能力を使えば、BigQuery がバックグラウンドで行っている処理を確認できます。クエリ履歴と実行に関する詳細のタブを見てみましょう。
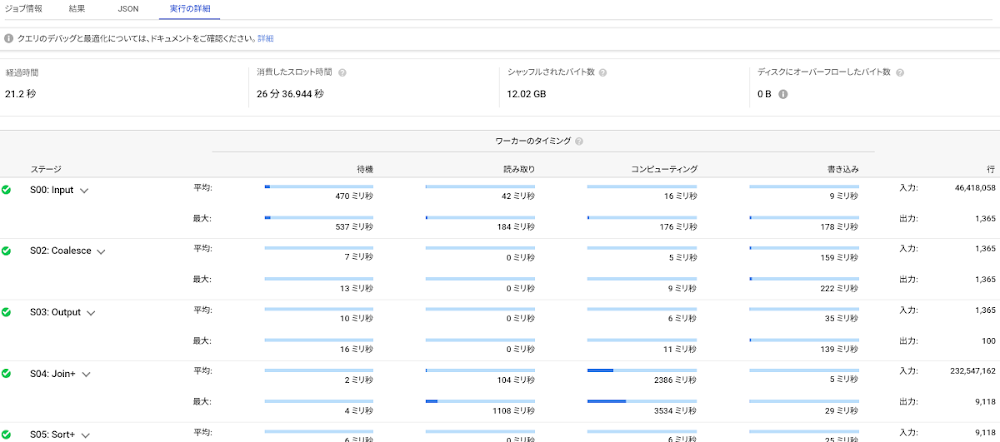
これらはすべて、クエリを実行するために BigQuery が行う必要のあったステップです。これではわかりにくい場合は、別の方法で見ることもできます。たとえば、以前の BigQuery ウェブ UI では、よりコンパクトに結果が表示されます。
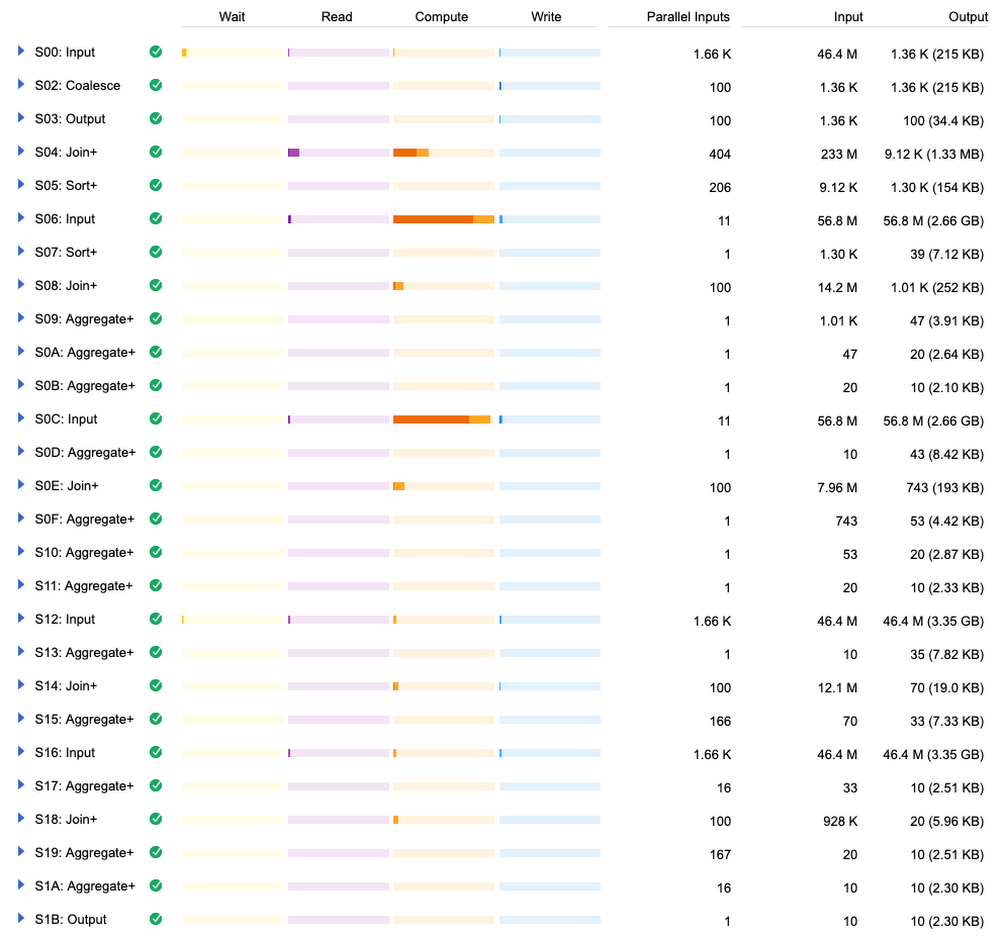
最も遅いオペレーションは、5,600 万行のテーブルを 2 回読み取るコンピューティングでした。
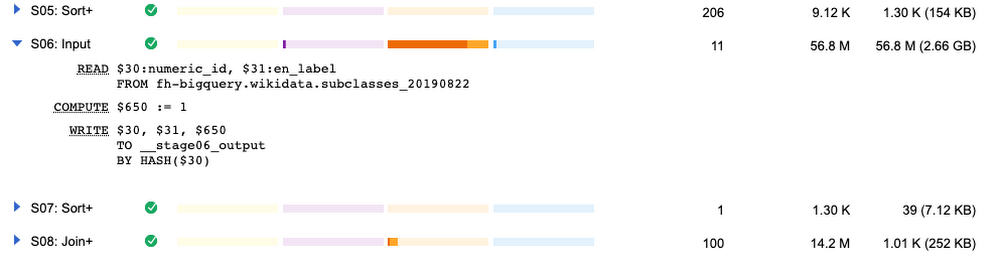
パフォーマンスを向上させるために、この 2 つのオペレーションに注目します。これらのオペレーションを次のように変更してみます。
クエリが半分の時間で実行できるようになりました。次に示すように、最も遅いオペレーションは別の箇所に変わりました。
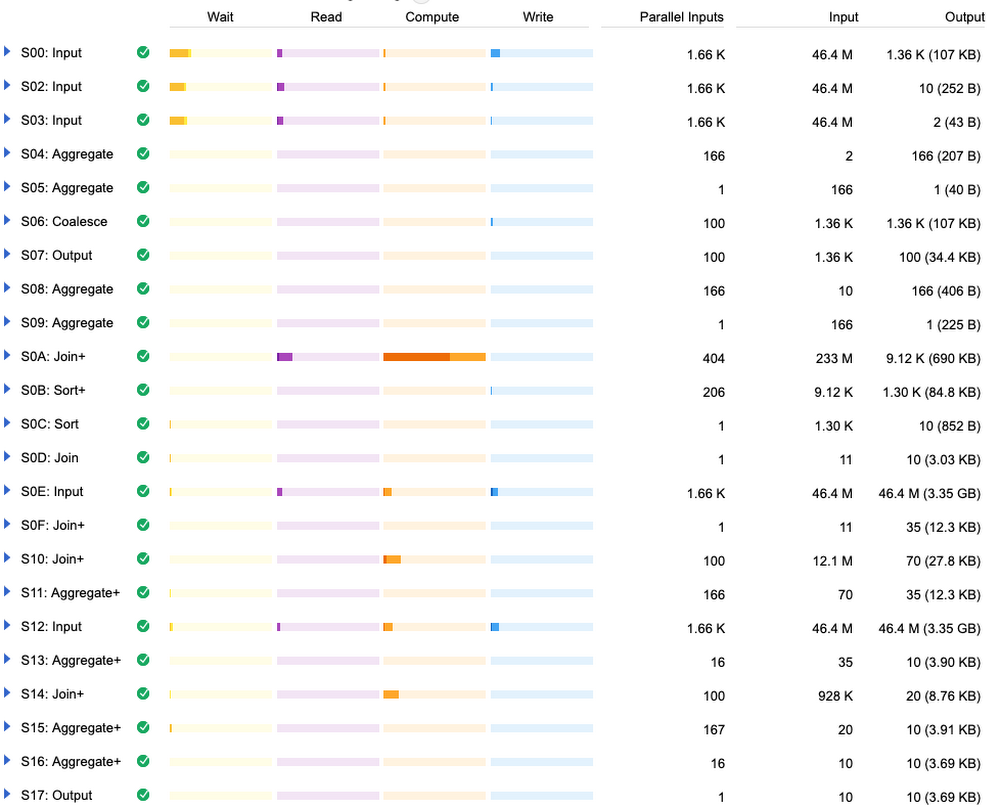
それがこの JOIN です。

このオペレーションでは、「3-D Man」から「Zor-El」のすべてのスーパーヒーローをアルファベット順に調べています。BigQuery クエリ プラン ビジュアライザのより詳細な説明をご覧ください。
5. 実体化の力
BigQuery でテーブルを使えるのは非常に便利です。では、どのようにしてデータをテーブルに読み込むのでしょうか?私は定期的に未加工のファイルを Cloud Storage に保存してから、生データのまま BigQuery に読み込んでいます。Wikipedia ページビューの場合は、多くのエッジケースが含まれているので BigQuery 内ですべての CSV 解析を行い、ケースバイケースで解決する必要があります。
次に、パーティション分割とクラスタ化を行ったテーブルに、これらのテーブルを定期的に反映させます。ウィキデータの場合は JSON が複雑なので、各 JSON 行を生データのまま BigQuery に読み込みます。それを SQL で解析することもできますが、十分ではありません。そこで、次のスーパーパワーの出番となります。
6. 多元的宇宙の移動
現在いる場所は、SQL だけが移動できる SQL の宇宙です。この宇宙は、データを操作して解析できるすばらしい場所です。しかし、それぞれの宇宙には独自の制限とルールがあります。別のルールがあって別の力を使える別の宇宙に移動して、2 つの宇宙をつなぐことができるとしたらどうでしょうか?つまり、JavaScript の宇宙に移動できるとしたら?ユーザー定義の関数(UDF)を使えば、それが可能です。UDF を使うと、BigQuery の標準 SQL を簡単に拡張できます。たとえば、JavaScript ライブラリをダウンロードして BigQuery 内で使用することで、自然言語処理などを行うことができます。
UDF を使うということは、ウィキデータの JSON の各行を取得して BigQuery 内で解析できることを意味します。そのため、好きな JavaScript ロジックを使用してから BigQuery で実体化できます。
7. タイムトラベル
ここにテーブルが 1 つあります。数千行ある美しい宇宙です。しかし、強大な敵がこれらの行の半分をランダムに削除しようとしています。敵は次のコードを実行しました。
平和な宇宙にある行の半分がランダムに削除されてしまいました。まったくひどい悪行です。元に戻すにはいったいどうすればよいでしょうか?
5 日後
半分の行を失ったまま前に進むことにしましたが、行を取り戻したい気持ちは捨てられません。時間を元に戻して、失った行を取り戻すことができればよいのですが。
それは可能です。
次のコードの代わりに
次のように記述します。
警告: テーブル履歴は CREATE OR REPLACE TABLE によって削除されてしまうため、結果は別の場所に書き込んでください。
8. 超高速の力
BigQuery はどのくらい速いでしょうか?その速さは次のとおりです。
簡単にまとめると、BigQuery は HyperLogLog++ を実行できます。これは、Google の社内向けに実装された、カーディナリティ推定用の HyperLogLog アルゴリズムです。HyperLogLog++ を使用すると、BigQuery で他のデータベースよりも速く固有値をカウントできます。また、BigQuery のパフォーマンスが大幅に改善する便利な機能も用意されています。
9. 不死身
最も厄介な敵は誰でしょうか?それは、ゼロで割ろうとしたときに発生する、データのブラックホールです。ただし、SAFE. 接頭辞といった BigQuery の式を使うことで回避できます。
SAFE. 接頭辞
構文:
SAFE.function_name()
説明
関数の先頭に SAFE. 接頭辞を付けると、エラーではなく NULL が返されます。
+ や = などの演算子は SAFE. 接頭辞をサポートしません。除算演算のエラーを防ぐには、SAFE_DIVIDE を使用します。ただし、IN、ARRAY、UNNEST、およびこれに類似する関数などの演算子は、SAFE. 接頭辞をサポートしていません。CAST 関数や EXTRACT 関数も SAFE. 接頭辞をサポートしていません。エラーのキャストを防ぐには、SAFE_CAST を使用します。詳細については BigQuery のドキュメントをご覧ください。
10. 自制心の力
どのスーパーヒーローも、自分にスーパーパワーがあることが初めてわかったときに苦悩します。
超怪力はかっこいい能力ですが、注意しなければ触れたものをいろいろ壊してしまいます。同様に、超高速移動も、止まる方法を知ってこそ楽しめる能力です。5 PB のデータのクエリを 3 分間で実行できますが、1 PB のクエリにかかる料金は 1 TB のクエリの 1,000 倍です。毎月の無料枠は 1 TB だけです。毎月 1 TB の無料枠の使用についてはクレジット カードの登録は不要ですが、1 TB を超えて使用する場合は、予算に注意してコスト管理を行う必要があります。
こちらのカスタムコスト管理の作成に関するドキュメントと、簡単に定額料金モデルを利用できる BigQuery Reservations の仕組みをご確認ください。スーパーパワーには大きな責任が伴います。
コスト管理を行いましょう。
BigQuery で使えるスーパーパワーは、ほかにもたくさんあります。未来を予知する力はいかがですか?ML の世界や、BigQuery で利用可能な GIS の機能も揃っています。Google Cloud で使える便利なリソースについて、Lak Lakshmanan が説明しているのでご覧ください。それこそが、Google Cloud が持つもう一つのスーパーパワーです。
11. コミュニティの力
どのスーパーヒーローにも仲間が必要です。Google Cloud の Reddit コミュニティにぜひご参加ください。ここでは、ヒントや最新情報をご覧いただけます。また、Stack Overflow で質問に回答して、新しいスーパーヒーローが力を使いこなせるようサポートしてください。お互いに学び合いましょう。Twitter で私と友人をフォローするのもお忘れなく。
スーパーパワーを試す準備ができたら、毎週実施される BigQuery データ チャレンジに挑戦してみてください。無料で参加できる楽しいチャレンジで、$500 の Google Cloud クレジットを獲得できるチャンスもあります。
- By Google Cloud Platform 担当デベロッパー アドボケイト Felipe Hoffa

