Aiven for Apache Kafka と Google BigQuery で分析情報をすばやく獲得
Google Cloud Japan Team
※この投稿は米国時間 2023 年 3 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
昨今はあらゆる企業がデータドリブンになることを目指していますが、正確なデータを適切な関係者にタイムリーに提供するプロセスは複雑になりがちです。ソースデータを複数の異なる技術で管理していて、アクセス インターフェースやデータ形式が一定でない場合、一層困難さが増します。
このような場合は、Aiven for Apache Kafka® と Google BigQuery の連携が威力を発揮します。これらを組み合わせると、幅広いツール エコシステムからデータを取得してストリーミング モードで BigQuery に push し、BigQuery でデータセットを整理、操作してクエリを実行することができます。
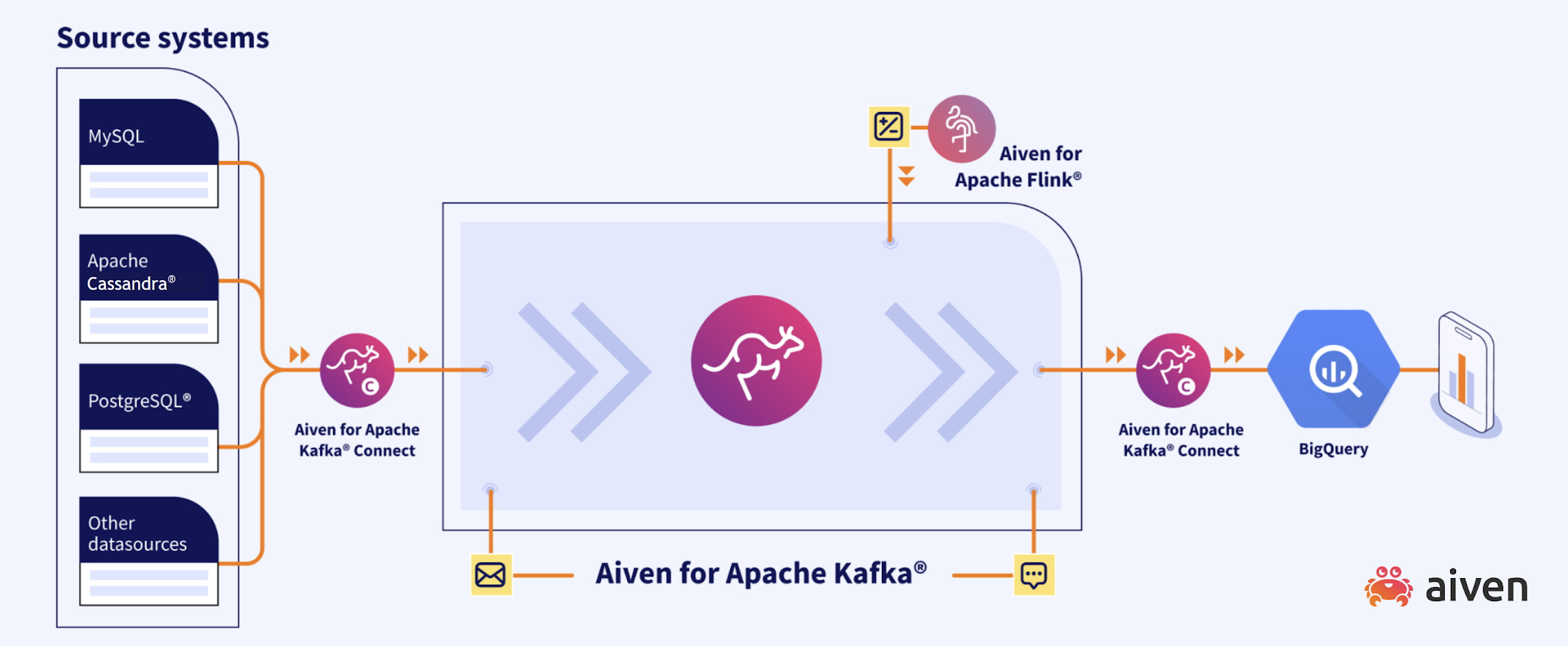
データソースから Apache Kafka with Kafka Connect へ
Aiven は、Apache Kafka とともに、マネージド Kafka Connect クラスタを作成する機能を提供します。Aiven には 30 以上のコネクタが用意されており、JSON 構成ファイルを使用してさまざまなソースおよびシンク技術に Kafka を統合できます。さらに、必要な特定の技術に対応するコネクタがリストにない場合は、セルフマネージド型の Kafka Connect クラスタを統合することで、フルマネージドの Apache Kafka クラスタの利点を維持したまま、自由にコネクタを選択できます。
データソースがデータベースの場合は、PostgreSQL 用 Debezium ソースコネクタのようなコネクタを使用することで、ネイティブのデータベース レプリケーション機能を利用した信頼性の高い高速な変更データ キャプチャ メカニズムを実現でき、ソースシステムに対する負荷の増加を最小限に抑えられます。
Apache Kafka 内のデータ
取り込みフェーズでは、コネクタはスループットを最適化するために Avro データ形式を使用し、Karapace(スキーマ レジストリと REST API エンドポイントを提供する Aiven のオープンソース ツール)にデータのスキーマを保存できます。
Apache Kafka 内のデータはトピック形式で保存され、データを保持する期間または容量を定義する保持期間をトピックに関連付けることができます。トピックは、1 つ以上のコンシューマがそれぞれ独立して読み取ることも、同じアプリケーション内のコンシューマ同士(Apache Kafka の用語で「コンシューマ グループ」)が競合して読み取ることもできます。
ターゲット データストアに格納する前にデータの再構築が必要な場合は、Aiven for Apache Flink により、SQL ステートメントを使用してストリーミング モードで変換を行うことができます。一般的な例としては、データのクレンジングや、異なる技術に由来するデータを組み合わせた内容の拡充が挙げられます。
Google BigQuery へのデータの push
データが分析に適した形に変換されたら、専用のシンクコネクタを使用して Apache Kafka トピックをストリーミング モードで BigQuery に push できます。コネクタには幅広い構成オプションがあり、パーティショニングに使用するタイムスタンプや、同時書き込みスレッドの数を定義するスレッドプール サイズなどを指定できます。
Apache Kafka を介してストリーミング モードで取り込まれたデータは 1 つ以上の BigQuery テーブルに格納され、分析や処理にすぐに使用できます。BigQuery には豊富な SQL 関数が用意されており、ネストされたデータセットの解析、複雑な地理的変換、ML モデルのトレーニングとその利用などを SQL 関数で行えます。BigQuery の SQL 関数は応用範囲が広く、アナリスト、データ エンジニア、データ サイエンティストは、一般的な SQL 言語を使用して他に類を見ないプラットフォームで仕事をすることができます。
迅速な分析を可能にするストリーミング ソリューション
幅広いソースコネクタとストリーミング機能を備えた Aiven for Apache Kafka は、多種多様なデータソースから BigQuery にデータを送り込んで分析するのに最適です。
このパターンを使用しているお客様の一例として、Wunderman Thompson 傘下のリテール メディア プラットフォームである Streaem が挙げられます。Streaem は、小売業者やそのブランドにセルフサービス型のリテール メディア プラットフォームを提供しています。このプラットフォームでは、商品に関するインテリジェンスや顧客からのシグナルを、広告主から提供されたキャンペーン情報と組み合わせることで、小売業者のサイトや店舗内のデジタル アセットの一部を収益化できます。たとえば、ユーザーが検索ボックスに「Coke」と入力すると、通常の検索結果に加えてスポンサーがついている商品のリストも表示されます。さらに、ユーザーがサイトを閲覧しているときに、それまでのインタラクションに基づいて商品をプロモーションすることもできます。
Streaem はプラットフォームとして Google Cloud を選択し、今後も使用していくつもりですが、同社の技術はイベント ドリブンであり、その中核となるメッセージ ブローカーの Kafka は Google Cloud からネイティブに使用できません。そこで Streaem は、Google Cloud と Aiven の Apache Kafka を連携させ、両方の長所を取り入れることに成功しました。つまり、自社に最適なクラウド プラットフォーム上で業界標準のイベント ストリーミングを行いつつも、Kafka を自ら管理する手間から解放されました。複数のマイクロサービスがデプロイされ、それらすべてのサービスが一貫した最新のビューを必要としている場合、Kafka は疑いなくその中心に位置すべきサービスです。Kafka が中心にあることで、すべてのサービスが最新の情報を取得でき、組織が成長してデータ量が増えたときにも容易にスケーリングできます。
「当社がお客様に提供するサービスでは、イベントベースのデータが重要な要素であり、Kafka はそのプラットフォームの中核にあります。」Streaem の CTO である Garry Turkington 氏はこのように語ります。「GCP 上でホストされたデータサービスを利用することで、私たちはコアとなるビジネス ロジックに集中できます。また、Aiven のおかげで、高性能で信頼性の高いプラットフォームを自信を持ってお届けすることができます。」
Kafka のみの環境では、分析は依然として難題です。そのため、Streaem は Aiven プラットフォーム上でマネージド型のオープンソース Kafka コネクタを使用して、マイクロサービスのデータを Google BigQuery にストリーミングしています。つまり、ライブ プラットフォームにある顧客アクティビティやキーワード オークションなどのデータを低レイテンシで BigQuery に取り込み、それを元にレポート ダッシュボードの情報を充実させたり、最新の集計結果をリアルタイムの意志決定に活用したりすることができます。Google Cloud Platform、Aiven for Apache Kafka、BigQuery を使用することで、Streaem は本番環境システムのスムーズな運用を確保し、社員がビジネスを成長させる仕事に全力で取り組める環境を作り上げています。
その他のユースケース
Aiven for Apache Kafka と Google Cloud BigQuery の組み合わせは、幅広い業種やユースケースにわたって、ビジネスに不可欠な分析情報をもたらしています。以下はその例です。
小売: BigQuery ML による需要計画、レコメンデーション エンジン、商品検索
Aiven は、ヨーロッパのある大規模な小売チェーンで、オープンソース データベースとイベント ストリーミングのインフラストラクチャに利用されています(Aiven for Apache Kafka、Aiven for OpenSearch、Aiven for Postgres、Aiven for Redis)。取得したデータは、おすすめの商品を提案するために BigQuery ML のトレーニング済みモデルに取り込まれています。これらのモデルは、Vertex AI で管理された API として、本番環境アプリケーションに公開できます。
e コマース: リアルタイムの動的な料金設定
あるグローバルな旅行予約サイトでは、Aiven のプロダクトをデータ ストリーミング インフラストラクチャ(Aiven for Apache Kafka)、グローバルな料金設定と需要データのほぼリアルタイムでの処理、および SIEM とアプリケーション検索のユースケース(Aiven for OpenSearch)に使用しています。取得したデータは分析のために BigQuery に送り込まれ、業界最高クラスのエンタープライズ データ ウェアハウスを実現しています。
ゲーム: プレーヤー分析
ある Fortune 500 のゲーム会社は、Aiven for Apache Kafka を介したデータ ストリーミングで、複数のゲームタイトルと世界中の 1 億人を超えるプレーヤーを支えています。この会社は、BigQuery によるプレーヤー メタデータの分析によって有益な情報を得ています。
まとめ / 次のステップ
Aiven for Apache Kafka と Google BigQuery を組み合わせると、最新データをほぼリアルタイムで分析し、短時間で有益な情報を引き出して最大限の効果を得ることができます。Aiven と Google のお客様は、すでにこの強力な組み合わせを活用して成果を上げています。ご興味をお持ちの場合は、Aiven に登録し、以下のリンクから詳細をご確認ください。
Aiven for Apache Kafka で、マネージド Apache Kafka サービスで提供されている機能、プラン、オプションをご覧ください。
Apache Kafka BigQuery シンクコネクタで、Apache Kafka から BigQuery にデータを push するための設定とその例をご覧ください。
Google Cloud BigQuery の詳細については、こちらをご覧ください。
実際にお試しになりたい場合は、こちらをクリックして Google Cloud Marketplace に掲載された Aiven のリスティングを確認し、ご希望を Google にお知らせください。
- Aiven、ソリューション アーキテクト Kevin Bowman 氏
- Google Cloud、テクノロジー パートナーシップ ディレクター Ritika Suri
