使用すべきデータ パイプライン アーキテクチャとは
Google Cloud Japan Team
クラウドでデータを処理する際に実装できる設計パターンは数多くあります。ここでは、現在使用できるデータ パイプライン アーキテクチャの概要を説明します。
※この投稿は米国時間 2023 年 2 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
データはあらゆるアプリケーションに不可欠であり、組織全体における情報の配信および管理のための効率的なパイプラインを設計する際に使用されます。通常、データ パイプラインは、データのライフサイクルの中でデータを処理する必要がある場合に定義します。パイプラインは、データの生成と任意の形式での保存から開始します。そして、データの分析、ビジネス情報としての利用、データ ウェアハウスへの保存、ML モデルでの処理で終了します。
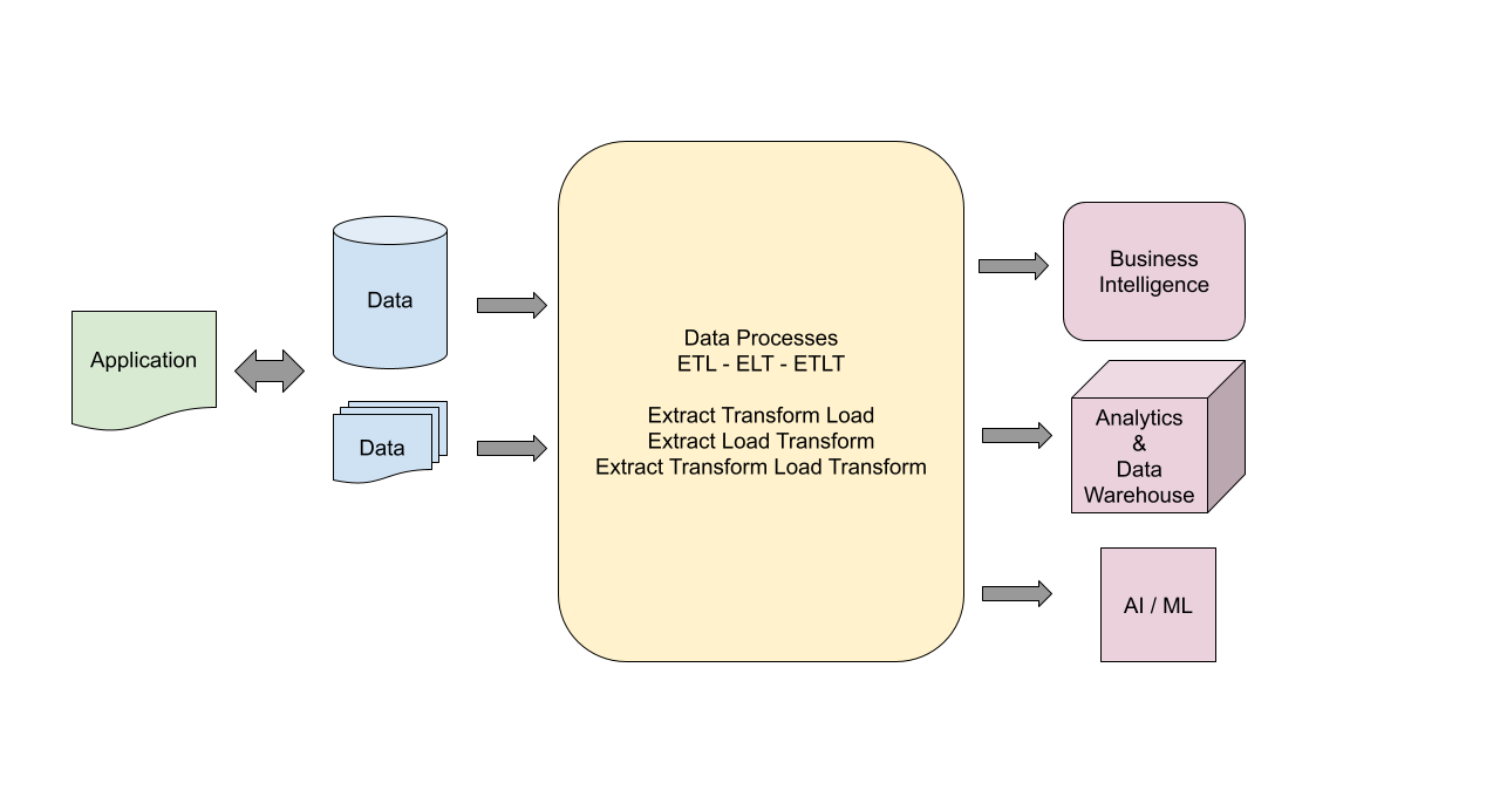
データの抽出、処理、変換は、ダウンストリームのシステム要件に応じて、複数のステップで行われます。あらゆる処理と変換のステップが、データ パイプラインで定義されます。要件に応じて、パイプラインは 1 ステップのような単純なものだけでなく、複数の変換・処理ステップに及ぶ複雑なものになる場合もあります。
設計パターンの選び方
データ パイプラインの設計パターンを選択する際、考慮する必要があるさまざまな設計要素があります。その要素には次のようなものが含まれます。
データソースの形式を選択する。
使用するスタックを選択する。
データ変換ツールを選択する。
Extract Transform Load(ETL)、Extract Load Transform(ELT)、Extract Transform Load Transform(ETLT)のいずれかを選択する。
変更されたデータの管理方法を決定する。
変更を取り込む方法を決定する。
データソースにはさまざまなデータ型があります。Google が使用している技術スタックとツールセットを把握することも、パイプライン構築プロセスの重要な要素です。エンタープライズ環境では、変更されたデータを取り込んでターゲット データと結合するために、複数の複雑な手法を使用する必要があるという課題が伴います。
ほとんどの場合、パイプラインの要件とこれらのプロセスを相互接続する方法は、下流のシステムによって定義されると先ほど説明しました。データフローの処理手順とシーケンスは、パイプラインの設計に影響を与える主な要因です。各ステップには 1 つ以上のデータ入力が含まれる場合があり、出力には 1 つ以上のステージが含まれる場合があります。入力から出力までの間の処理は、単純な変換ステップの場合もあれば、複雑な変換ステップになる場合もあります。進行中のステップと変換を明確に理解できるように、設計をシンプルかつモジュール化することを強くおすすめします。また、パイプラインの設計をシンプルかつモジュール化することで、開発者チームは開発とデプロイのサイクルを実行しやすくなります。また、パイプラインに問題が発生した場合のデバッグやトラブルシューティングも容易になります。
パイプラインの主要なコンポーネントには次のものがあります。
ソースデータ
処理
ターゲット ストレージ
ソースデータには、トランザクション アプリケーション、ユーザーから収集したファイル、外部 API から抽出したデータなどがあります。ソースデータの処理は、1 ステップのコピーのような単純なものから、複数の変換や他のデータソースとの結合といった複雑なものまで、さまざまなものがあります。ターゲットのデータ ウェアハウジング システムでは、変換(データ型の変更やデータ抽出など)の結果である処理済みデータや、他のシステムからのルックアップと更新が必要になる場合があります。データを変更せずにソースからターゲットにコピーすることで、単純なデータ パイプラインを作成できる場合があります。また、複雑なデータ パイプラインには、さまざまな理由により複数の変換ステップ、ルックアップ、更新、KPI 計算、複数のターゲットへのデータ保存が含まれる場合があります。

ソースデータは複数の形式で提示できます。それぞれの形式に、処理と変換のための適切なアーキテクチャとツールが必要になります。一般的なデータ パイプラインでは、複数のデータ型が必要になる場合があり、次のいずれかの形式になります。
バッチデータ: 表形式の情報ファイル(CSV、JSON、AVRO、PARQUET など)で、定義済みのしきい値や頻度に従って、従来のバッチ処理またはマイクロバッチ処理によりデータが収集されます。最近のアプリケーションは、連続するデータを生成する傾向があります。このため、ソースからデータを収集するには、マイクロバッチ処理が推奨されます。
トランザクション データ: RDBMS(リレーショナル データ)、NoSQL、ビッグデータなどのアプリケーション データ。
ストリーミング データ: Kafka、Google Pub/Sub、Azure Stream Analytics、Amazon Stream Data を使用するリアルタイム アプリケーション。ストリーミング データ アプリケーションは、要件を満たすためにリアルタイムで通信し、メッセージを交換できます。エンタープライズ アーキテクチャの設計では、リアルタイム処理とストリーム処理は非常に重要な設計要素です。
フラット ファイル - 処理用のデータを含む PDF やその他の非表形式のファイル。たとえば、医療文書や法律文書など、情報を抽出するために使用できるものがこれにあたります。
ターゲット データは、要件と下流の処理ニーズに基づいて定義されます。複数のシステムのニーズを満たすために、ターゲット データを構築するのが一般的です。データレイクのコンセプトでは、分析システムが分析情報を得られるようにデータを処理・保存しつつ、AI / ML プロセスでそのデータを使用して予測モデルを構築できるようにします。
アーキテクチャと例
ソースデータがどのように抽出され、ターゲットに変換されるかを示す複数のアーキテクチャ設計について説明します。目標は、一般的なアプローチを巧みに使いこなすことです。それぞれのユースケースは非常に異なっていて、お客様に固有のものであり、特別な配慮が必要な場合もあることを覚えておいてください。
データ パイプライン アーキテクチャは、論理レベルとプラットフォーム レベルに分解できます。論理設計では、データがどのように処理され、ソースからターゲットに変換されるかを記述します。プラットフォーム設計では、各環境に必要な実装やツールに焦点を当てますが、プラットフォームで利用可能なプロバイダやツールに依存することになります。Google Cloud、Azure、Amazon のいずれも、変換のためのツールセットは異なりますが、論理設計のゴール(データ変換)はどのプロバイダを使用しても変わりません。
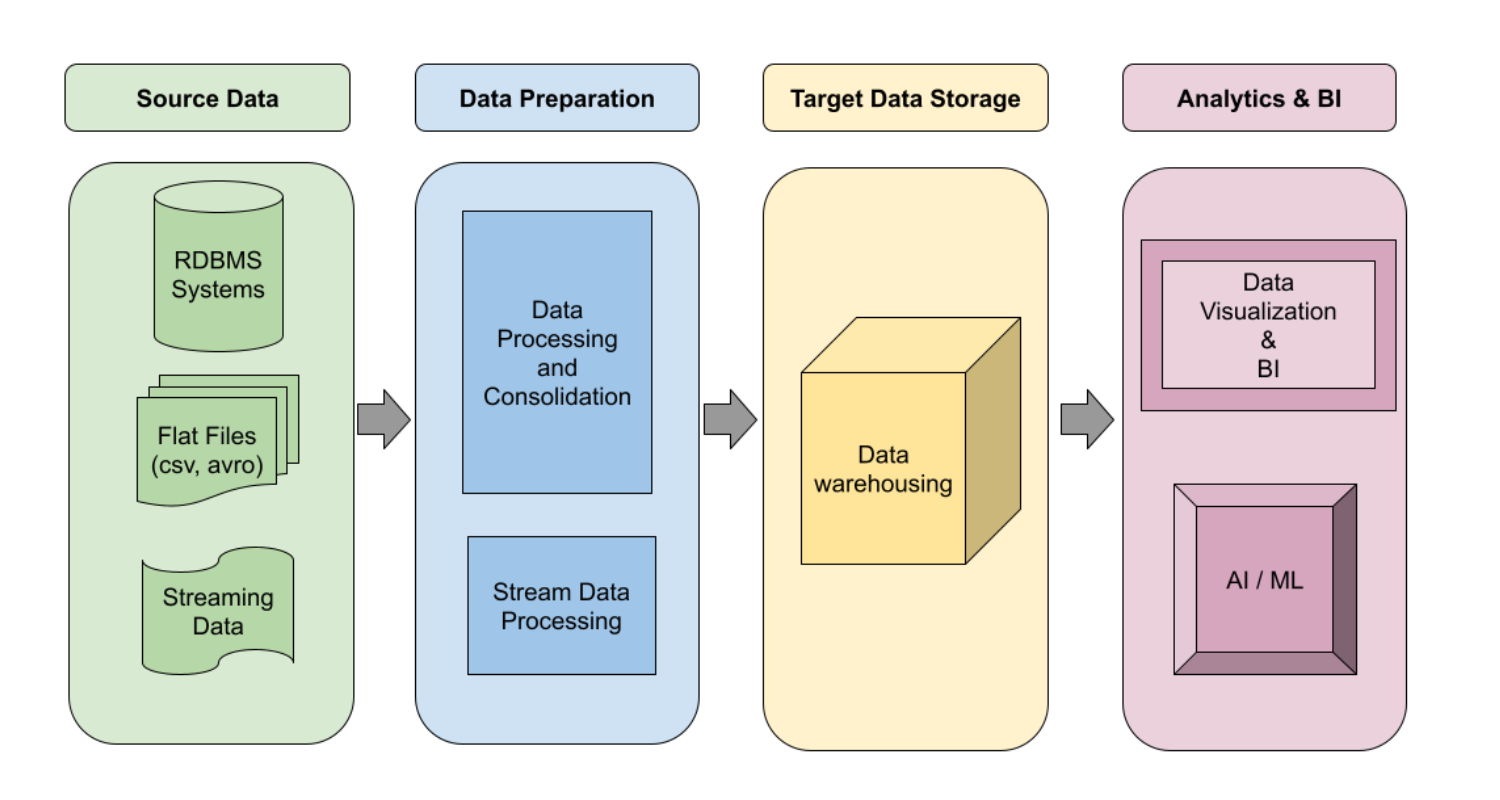
以下は、データ ウェアハウジング パイプラインの論理設計です。
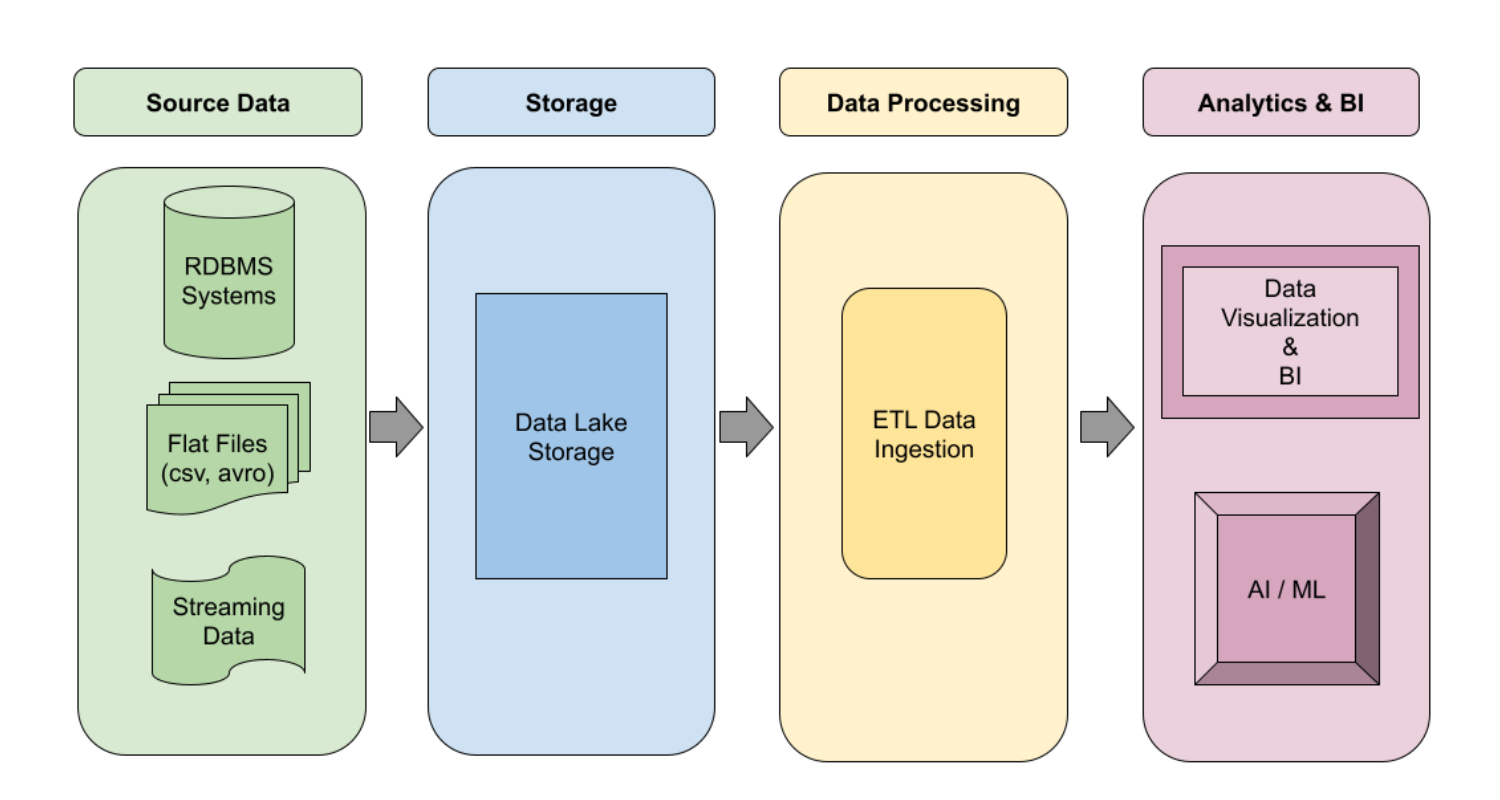
以下は、データレイク パイプラインの論理設計です。
ダウンストリームの要件に応じて、一般的なアーキテクチャ設計をより詳細に実装して、いくつかのユースケースに対応することが可能です。
プラットフォームの実装は、ツールセットの選択と開発スキルによって異なる場合があります。以下は、一般的なデータ パイプライン アーキテクチャの Google Cloud での実装例です。
Google Cloud のバッチ ETL パイプライン - ソースは、分析ビジネス インテリジェンス(BI)エンジンに取り込む必要があるファイルの場合があります。Google Cloud 内のデータ転送メディアとして Cloud Storage を利用し、Dataflow でターゲットの BigQuery ストレージにデータを読み込みます。このアプローチはシンプルなため、この設計パターンを単純な変換プロセスにおいて再利用可能かつ効果的なものにします。他方で、複雑なパイプラインを構築する必要がある場合は、このアプローチでは効率的、効果的とは言えません。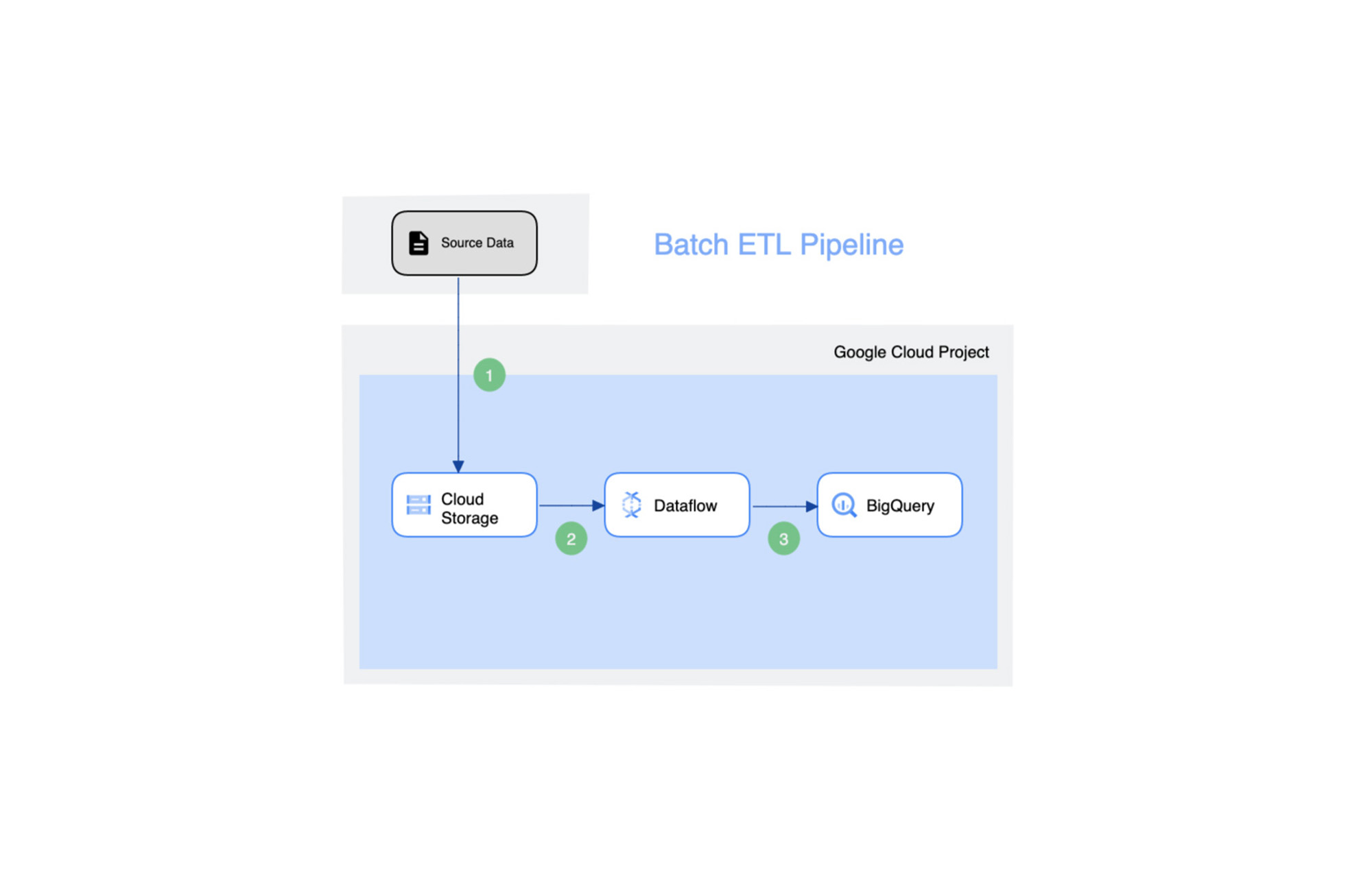
データ分析パイプラインは、バッチデータとストリーム データの両方の取り込みパイプラインを含む、複雑なプロセスです。処理は複雑で、複数のツールとサービスを使用してデータをウェアハウスに変換し、さらに処理するために AL / ML アクセス ポイントに変換します。データ分析のためのエンタープライズ ソリューションは複雑で、データを処理するために複数のステップを要します。設計が複雑になると、プロジェクトのスケジュールや費用がかさむ可能性がありますが、ビジネスの目標を達成するために、各コンポーネントを慎重に検討して構築してください。

Google Cloud の ML データ パイプラインは、お客様がすべての Google Cloud ネイティブ サービスを利用して ML プロセスを構築し、処理できるようにする包括的な設計となっています。詳細については、ML パイプラインの作成をご覧ください。
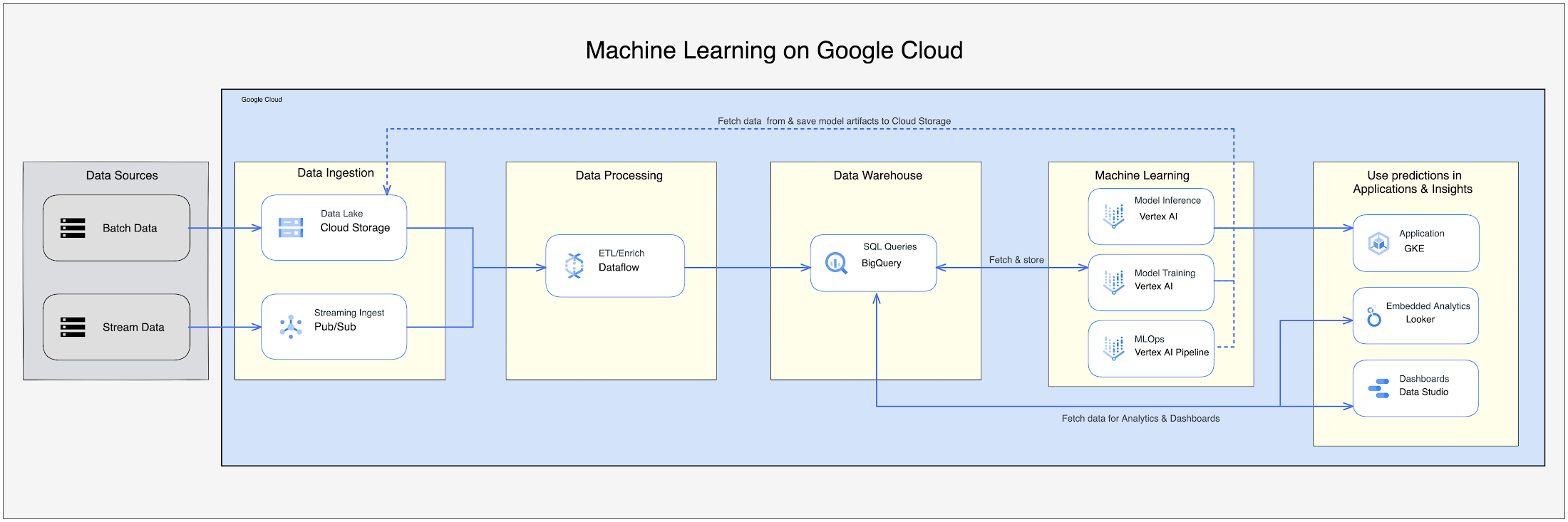
Google Cloud プラットフォームの図は、Google Cloud デベロッパー アーキテクチャによって作成されています。
データ パイプライン アーキテクチャの選択方法
データ パイプラインの設計と実装には、複数のアプローチがあります。重要なのは、要件を満たす設計を選択することです。より堅牢で高速なデータ パイプラインの実装を実現する新しいテクノロジーが登場しています。Google BigLake は、データの取り込みに関する新しいアプローチを導入した新サービスです。BigLake は、BigQuery やオープンソース フレームワーク(Spark など)が、きめ細かいアクセス制御によりデータにアクセスできるようにすることで、データ ウェアハウスを統合するストレージ エンジンです。BigLake は、マルチクラウド ストレージやオープン フォーマット(Apache Iceberg など)においてクエリ パフォーマンスを向上させます。
適切なデータ パイプライン アーキテクチャを決定する際のもう一つの大きな要因は、費用です。費用対効果の高いソリューションを構築することが、設計を決定する大きなポイントになります。通常、ストリーミング パイプラインやリアルタイムのデータ処理パイプラインは、バッチモデルを使用する場合と比べて構築や実行にかかる費用が高くなります。どの設計を選択するか、どのようにプラットフォームを構築するかは、予算によって決まる場合もあります。各コンポーネントの詳細を把握し、事前にソリューションの費用分析ができることは、ソリューションに適したアーキテクチャ設計を選択するうえで重要です。Google Cloud は、このような場合に利用できる料金計算ツールを提供しています。
本当にリアルタイム分析が必要なのか、それともほぼリアルタイムのシステムで十分なのか。これにより、ストリーミング パイプラインの設計が決まります。クラウド ネイティブのソリューションを構築するのか、それとも既存のソリューションをオンプレミスから移行するのか。これらの問題はすべて、データ パイプラインの適切なアーキテクチャを設計するうえで重要です。
データ パイプラインを設計する際は、データ量も無視できません。ソリューションの設計と実装においては、プラットフォームで使用される設計とサービスのスケーラビリティも非常に重要な要素になります。ビッグデータはますます拡大し、処理能力を高めています。データの保存はデータ パイプライン アーキテクチャの重要な要素です。実際には、適切なプラットフォーム設計に役立つ多くの変数があります。データの量や速度、あるいはデータの流量は、非常に重要な要素になる場合があります。
データ サイエンス プロジェクト用のデータ パイプラインの構築を計画している場合は、将来のエンジニアリングのために ML モデルが必要とするすべてのデータソースを検討することをおすすめします。データ エンジニアリング チームは、データ クレンジング プロセスに関わることが多く、適切かつ十分な変換ツールセットを備えている必要があります。また、データ サイエンス プロジェクトは大規模なデータセットを扱うため、ストレージの計画が必要になります。ML モデルの利用方法に応じて、リアルタイム処理またはバッチ処理のいずれかをユーザーに提供する必要があります。
次のステップ
ビッグデータや一般的なデータの増加は、データ アーキテクトに新たな課題をもたらし、常にデータ アーキテクチャの要件に戦いを挑んでいます。また、データの種類、データ形式、データソースの絶え間ない増加も課題となっています。企業はデータの価値を認識し、より多くのプロセスを自動化しており、分析や意思決定情報へのリアルタイムなアクセスを求めています。このため、スケーラブルなパフォーマンスを備えたシステムのすべての変数を考慮することが課題になりつつあります。データ パイプラインは、強力で柔軟、かつ信頼性の高いものでなければなりません。データの品質は、すべてのユーザーから信頼される必要があります。データのプライバシーは、あらゆる設計上の考慮事項においても最も重要な要素の一つです。これらのコンセプトについては、次回の記事で取り上げることにします。
次のステップとして、Google Cloud のクイックスタートとチュートリアルに沿って Google Cloud の詳細を学び、実践演習を体験することを強くおすすめします。
今後の情報にご注目ください。ご精読ありがとうございました。質問やチャットをご希望の場合は、Twitter または LinkedIn でご連絡ください。



