Splunk Dataflow のストリーミング パイプラン向けの新しいオブザーバビリティ機能

Google Cloud Japan Team
※この投稿は米国時間 2022 年 5 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
Google は、Pub/Sub to Splunk Dataflow テンプレートの新しいオブザーバビリティ機能を発表いたします。これにより、オペレーターがストリーミング パイプラインのパフォーマンスを監視することが可能になります。Splunk Enterprise と Splunk Cloud のユーザーは、Splunk Dataflow テンプレートを使用してGoogle Cloud のログを確実にエクスポートし、セキュリティ、IT、ビジネス ユースケースの詳細な分析に使用していますが、Splunk IO シンクの新しく追加された指標や改善されたロギング機能により、次のような運用上の疑問に対する答えを簡単に得ることができるようになりました。
Dataflow パイプラインは作成されたログの量に対応しているか
Splunk に書き込むとき、レイテンシとスループットはどうなっているか(1 秒あたりのイベント数、EPS)
ダウンストリーム Splunk HTTP Event Collector(HEC)のレスポンスのステータスの内訳とエラー メッセージの内容
このような重要な情報を可視化することにより、ログのエクスポートのサービスレベル指標(SLI)を取得し、パイプラインのパフォーマンス低下をモニタリングできます。また、Splunk HEC ネットワーク接続やサーバーの問題などの Dataflow と Splunk の間で発生する可能性のあるダウンストリームの障害の原因を簡単に究明し、連鎖的な障害が発生する前に問題を修正できます。
このような指標を迅速に可視化するために、Splunk Dataflow 向けの Terraform モジュールのアップデートでカスタム ダッシュボードにそれらの指標が追加されました。これらの Terraform テンプレートを使用して、Splunk にログをエクスポートするインフラストラクチャ全体、または、モニタリング ダッシュボード単独でデプロイできます。
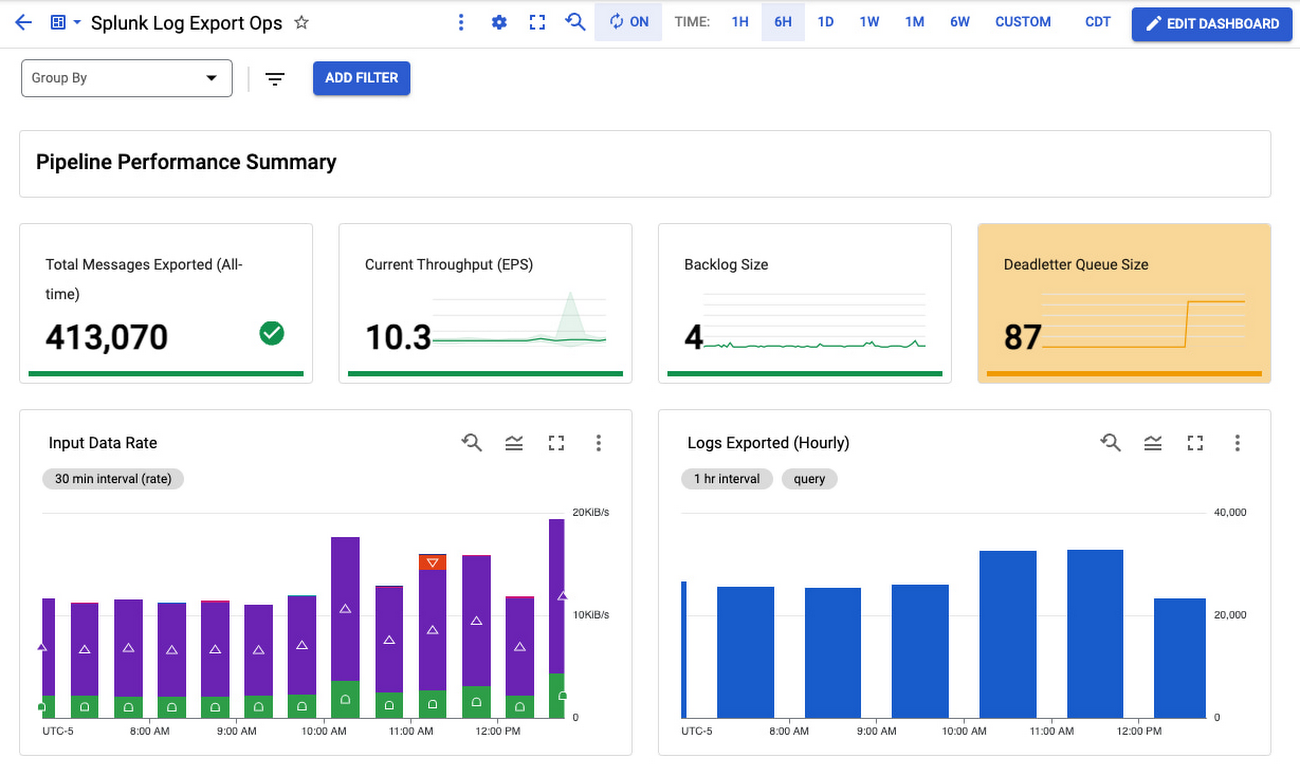
Splunk Dataflow 向けのログ エクスポート ダッシュボード
その他の統計情報
Dataflow コンソールに新しいカスタム指標が追加されました(下図でハイライト表示)。テンプレートのバージョン 2022-03-21-00_RC01(gs://dataflow-templates/2022-03-21-00_RC01/Cloud_PubSub_to_Splunk)以降で起動されたジョブが対象となります。
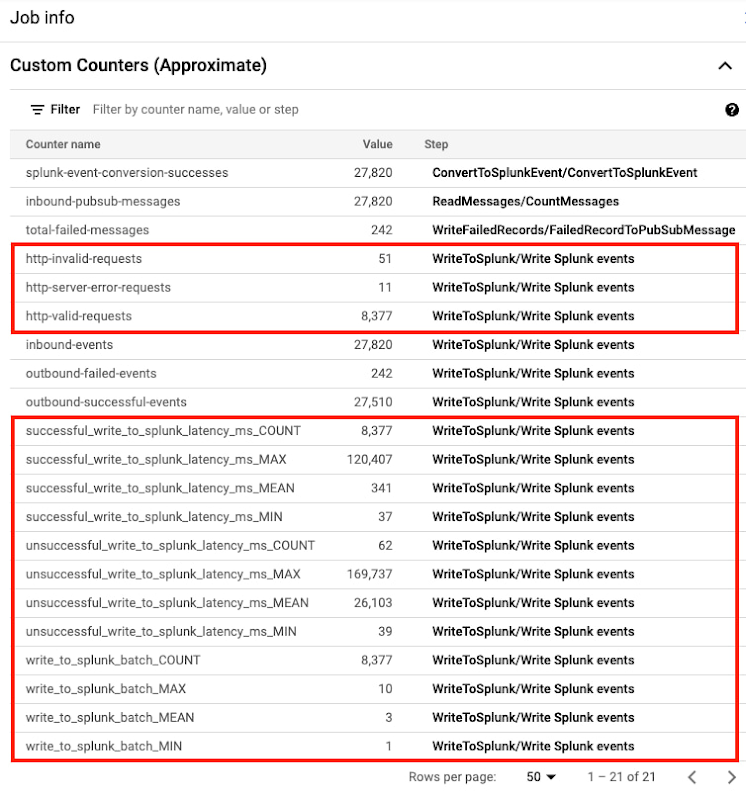
パイプラインの計測手法
新しい指標について詳しく説明する前に、一歩戻って Splunk Dataflow ジョブステップについて説明します。次の図に Splunk Dataflow ジョブのステージを示すフローチャートと、対応するカスタム指標を示します。
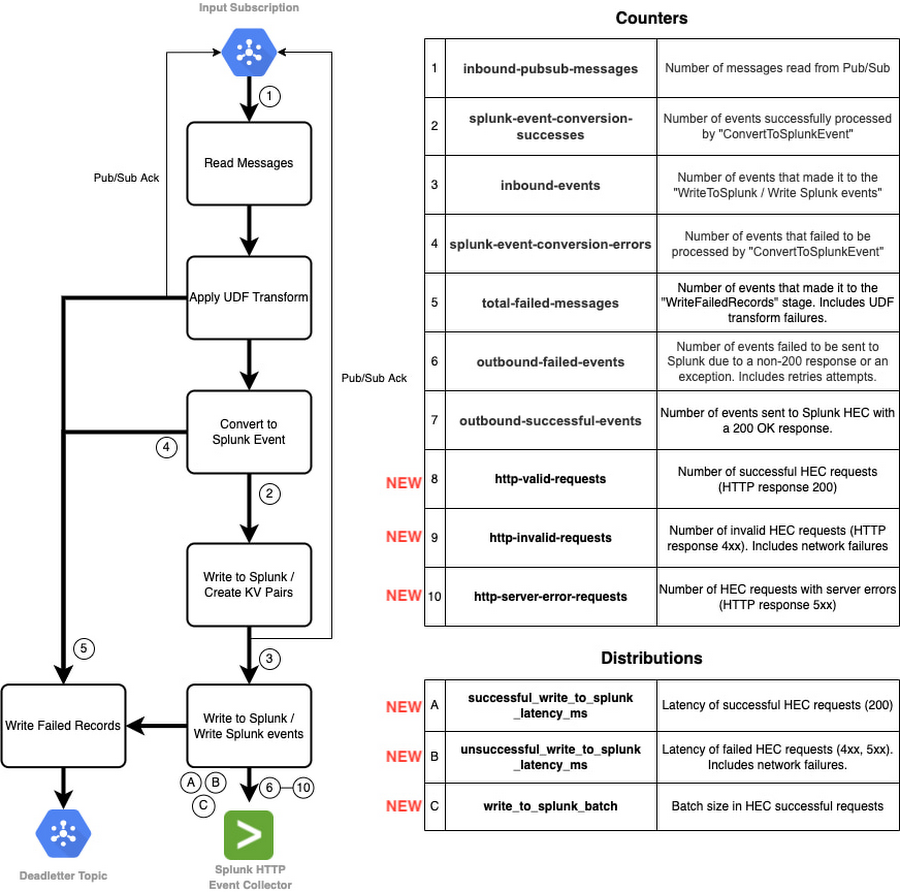
このパイプラインでは、2 種類の Apache Beam カスタム指標を使用しています。
カウンタ指標。上の表の 1~10。メッセージやリクエストの数を確認する(成功および失敗の両方)。
分布指標。上の表の A~C。リクエストのレイテンシ(成功および失敗の両方)とバッチサイズをレポートする。
ダウンストリーム リクエストの可視性
これまで、Splunk Dataflow のオペレーターは、これらの事前構築済みのカスタム指標を適宜使用して、ログメッセージがパイプライン ステージを進む過程をモニタリングしていました。特に、最後のステージである「Splunk に書き込む」では、指標 outbound-successful-events(表の #6 のカウンタ)と outbound-failed-events(表の #7 のカウンタ)を使用して、正常にエクスポートされた(されなかった)メッセージの数を追跡していました。オペレーターは送信メッセージの成功率を確認できますが、HEC リクエスト レベルでの可視性はありませんでした。今回の新機能により、Splunk Dataflow のオペレーターは成功および失敗した HEC リクエストの数だけでなく、レスポンスのステータスの内訳もモニタリングできるようになりました。そのため、リクエストの失敗の理由がクライアント リクエストの問題(例: Splunk インデックスまたは HEC トークンが無効)なのか、一時的なネットワークまたは Splunk の問題(例: サーバーがビジーまたはダウンしている)なのかを、すべて Dataflow コンソールで次の追加されたカウンタ(表の #8~10)を使用して確認できるようになりました。
http-valid-requests
http-invalid-requests
http-server-error-requests
Splunk Dataflow オペレーターは、また、Splunk HEC へのダウンストリーム リクエストの平均レイテンシや平均リクエスト バッチサイズを次の分布指標(表の #A~C)で追跡できるようになりました。
successful_write_to_splunk_latency_ms
unsuccessful_write_to_splunk_latency_ms
write_to_splunk_batch
Beam の分布指標は Dataflow によって接尾辞に _MAX、_MIN、_MEAN、_COUNT が付いた 4 つのサブ指標で報告されます。そのため、3 つの新しい分布指標は Cloud Monitoring で 12 の新しい指標として表示されます。これは、前に示した Dataflow コンソールのジョブ情報のスクリーンショットで確認できます。Dataflow は現在ヒストグラムの作成をサポートしていないため、ヒストグラムでこれらの指標の値の内訳を可視化することはできません。そのため、この目的では _MEAN のサブ指標を使用する方法しかありません。_MEAN は期間全体を通しての平均値なので、任意の間隔(例: 1 時間ごと)での変化を追跡する目的では使用できません。ただし、ベースラインの把握、トレンドの追跡、他のパイプラインとの比較には役立ちます。
Dataflow カスタム指標は、前述の Splunk Dataflow テンプレートで報告される指標も含め、Cloud Monitoring の機能であり、課金対象です。指標の料金については、Cloud Monitoring の料金をご覧ください。
改善されたロギング
HEC エラーのロギング
ダウンストリーム問題の根本原因を解決するため、HEC リクエストのエラーが、レスポンス ステータス コードとメッセージも含め、適切にロギングできるようになりました。
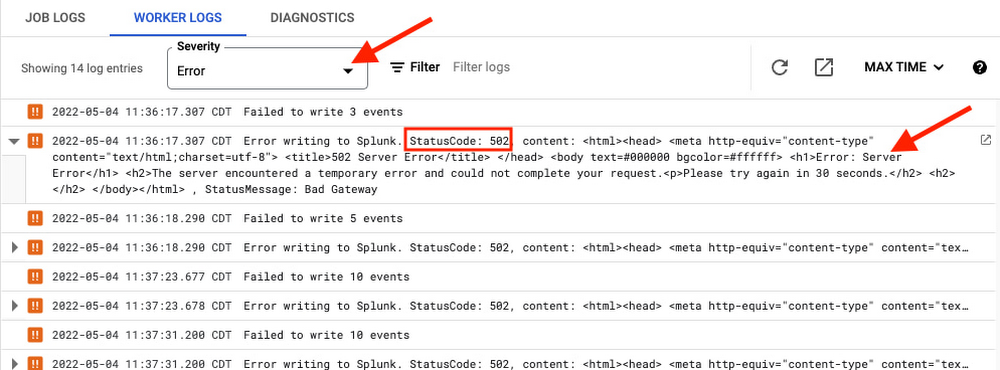
Dataflow コンソールの [ワーカーログ] で、ログの重大度をエラーに設定することで、直接取得できます。
あるいは、ログ エクスプローラを使用する場合は、次のクエリを実行します。バッチのログを無効にする
デフォルトでは、Splunk Dataflow ワーカーは次のように HEC リクエストごとにログを記録します。
これらのリクエストは多くの場合、イベントをバッチ処理するものですが、このような「バッチのログ」は HEC リクエストごとに 2 つのログ メッセージを出力するので、ログの件数が多くなります。リクエスト レベルのカウンタ(http-*-requests)、レイテンシとバッチサイズの分布、前述のHEC エラーのロギングが追加されたことで、これらのバッチのログは一般的には冗長なものです。ワーカーのログの量を制御するため、これらのバッチのログを無効にすることができるようになりました。Splunk Dataflow ジョブをデプロイするときに、新しいオプションのテンプレート パラメータ enableBatchLogs を false に設定します。最新のテンプレート パラメータについて詳しくは、テンプレートのユーザー向けドキュメントをご覧ください。
デバッグレベルのログの有効化
Apache Beam Java SDK を使用して作成された Google 提供テンプレートのロギング レベルは、デフォルトで「INFO」です。これは、「INFO」と、それより重要度が高い「WARN」や「ERROR」のメッセージがすべてロギングされることを示しています。これよりレベルの低い「DEBUG」などのメッセージのロギングを有効にするには、gcloud コマンドライン ツールを使用してパイプラインを開始する際に --defaultWorkerLogLevel フラグを DEBUG に設定します。
--workerLogLevelOverrides フラグを使用して特定のパッケージやクラスに対してログレベルをオーバーライドすることもできます。たとえば、HttpEventPublisher クラスは、Splunk に送信される最終的なのペイロードを DEBUG レベルでロギングします。--workerLogLevelOverrides フラグを {"com.google.cloud.teleport.splunk.HttpEventPublisher":"DEBUG"} に設定すると、Splunk に送信する前に最終的なメッセージをログで確認することができます。このとき、その他のクラスでは INFO レベルのままです。これを使用するときには注意が必要です。Splunk に送信するすべてのメッセージがコンソールの [ワーカーログ] タブにロギングされるため、ログのスロットリングが発生する可能性があり、機密情報の漏洩につながることもあります。
すべてを組み合わせる
これらをすべて 1 つのモニタリング ダッシュボードにまとめて、ログのエクスポートを簡単にモニタリングできるようにしました。
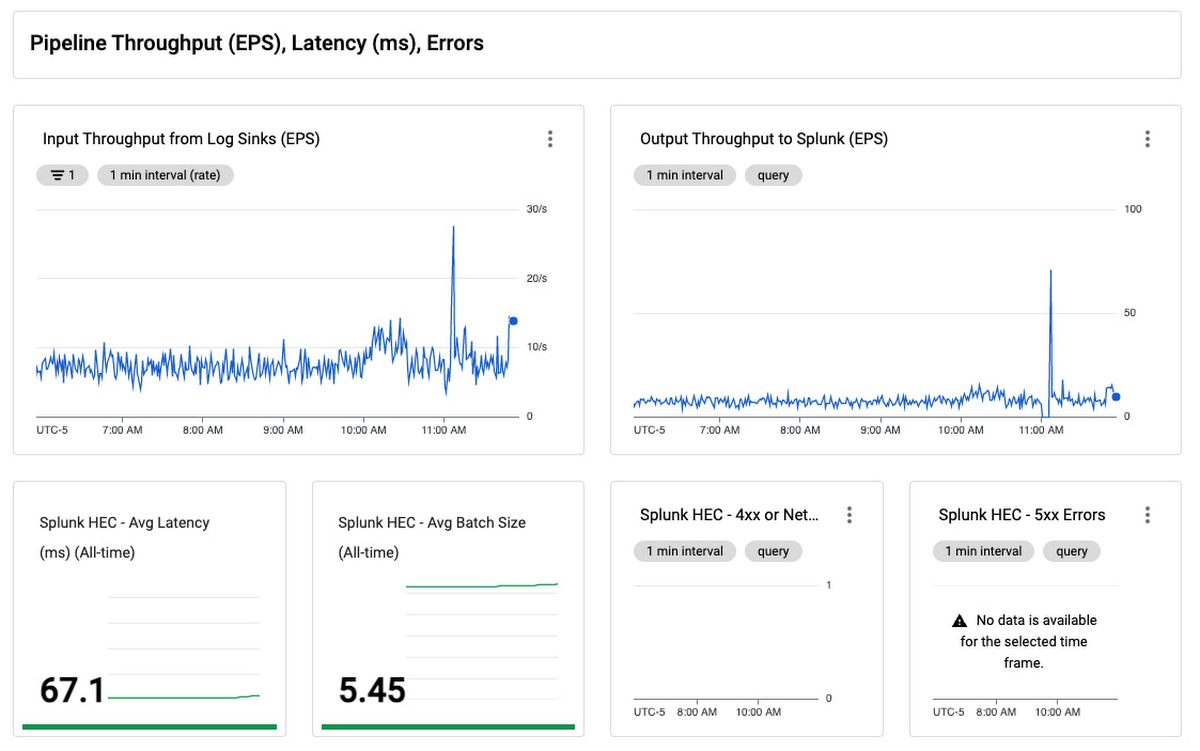
このダッシュボードは、Pub/Sub から Splunk Dataflow へのパイプラインをモニタリングするための一括表示画面です。これを使用してログのエクスポートが動的ログの容量の要件に合致しているかを確認します。レイテンシやバックログを最小限に止めつつ、適切なスループット(EPS)率になるようにスケーリングしてください。パイプラインのリソース使用率と使用量を追跡できるパネルもあります。パイプラインが安定した状態で費用対効果に優れた方法で実行されているかを検証できます。
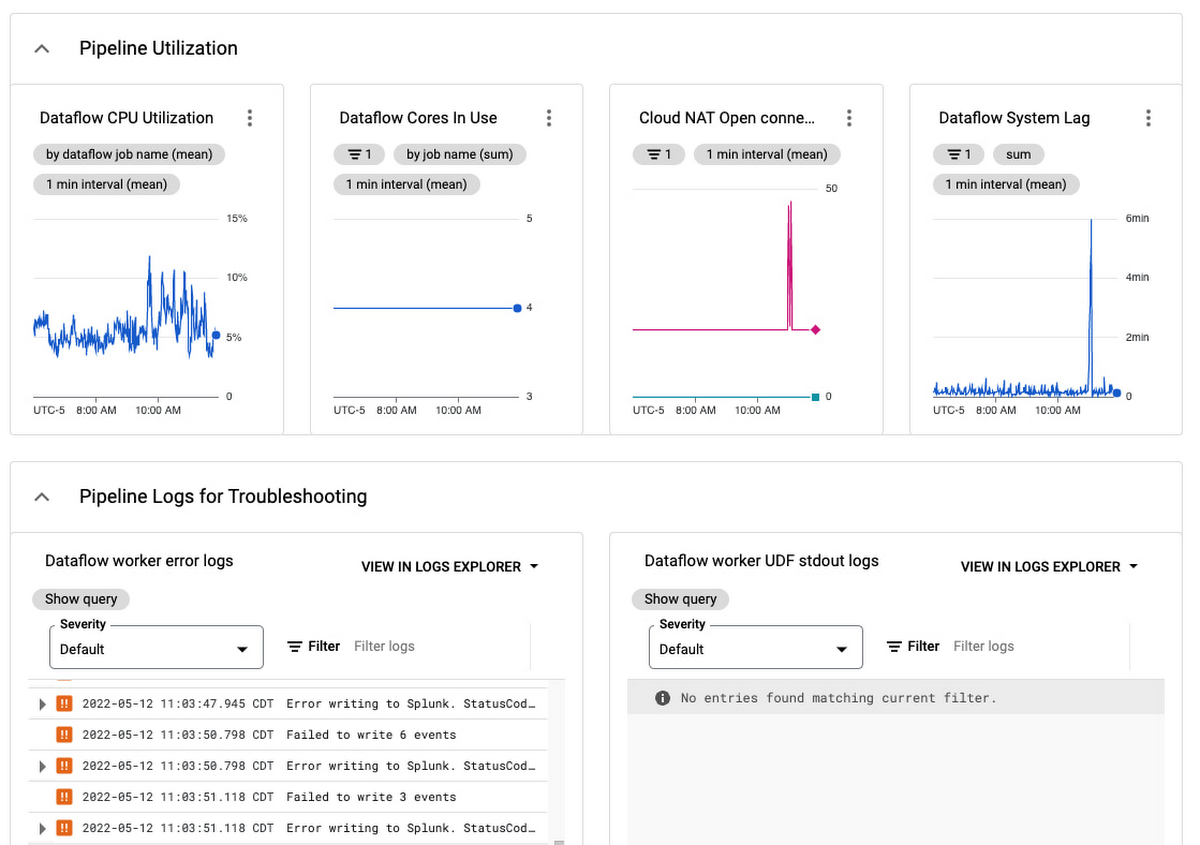
パイプライン使用率とワーカーログ
失敗したメッセージの処理や再生する場合のガイダンスについては、Splunk Dataflow リファレンス ガイドの失敗したメッセージに関するトラブルシューティングをご覧ください。Dataflow パイプラインの一般的なトラブルシューティングの情報については、トラブルシューティングとデバッグのドキュメントを確認してください。一般的なエラーとその解決方法については、一般的なエラーのガイダンスのドキュメントをご覧ください。なんらかの問題が発生した場合は、Dataflow テンプレートの GitHub リポジトリで問題を報告するか、Google Cloud コンソールで直接サポートケースを登録します。
GCP ログを Splunk にエクスポートする手順については、「Dataflow を使用して本番環境対応のログのエクスポートを Splunk にデプロイする」をご覧ください。または、付属の Terraform スクリプトを使用して自動的にログ エクスポートのインフラストラクチャと関連する運用ダッシュボードを設定してください。
- ソリューション アーキテクト Roy Arsan




