Cloud Data Fusion を使用して、安全でコーディングが不要なデータ パイプラインを数分で作成
Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
最新のクラウド ウェアハウスとデータレイク ソリューションへの投資を拡大して、分析環境を強化し、ビジネス上の意思決定を改善しようとする組織が増えています。データが増大するほど、このようなリポジトリのビジネス価値は高まります。すべてが接続された現代では多くの企業がマルチクラウド戦略を採用しているため、ソースデータが最終的なデータレイクやデータ ウェアハウスがデプロイされる場所ではなく、クラウド プロバイダに保存されるというシナリオはきわめて一般的です。
たとえば、データ ウェアハウス ソリューションが Google Cloud にデプロイされていても、ソースデータが Azure や Amazon Web Services(AWS)内に存在する場合もあります。また、多くの場合、データをデータレイクに読み込み、データ サイエンティストや分析ツールが使用できるようにする前に、コンテンツの各要素を匿名化することが法令遵守によって求められます。最後に、さまざまなデータソースからのデータに対して STRAIGHT JOIN を実行し、データ ウェアハウスにそのデータが格納された後、データセット全体に機械学習予測を適用することが、お客様にとって重要となる場合もあります。
本投稿では、安全なノーコード データ パイプラインの設定方法を説明し、Google Cloud を使用してデータを簡単に移動させて、ターゲット ウェアハウス内でそのデータを匿名化する方法を示します。この直感的なドラッグ&ドロップ ソリューションは事前構築済みコネクタに基づいており、セルフサービス モデルでコードを意識せずにデータ統合を実現できます。そのため、技術的な専門知識がない場合でも、迅速に分析情報を取得できます。また、Google サービスのスケーラビリティと信頼性を活用するこのサーバーレスのアプローチにより、総所有コストを低減しながら最高水準のデータ統合機能を利用できます。
アーキテクチャを以下に示します。
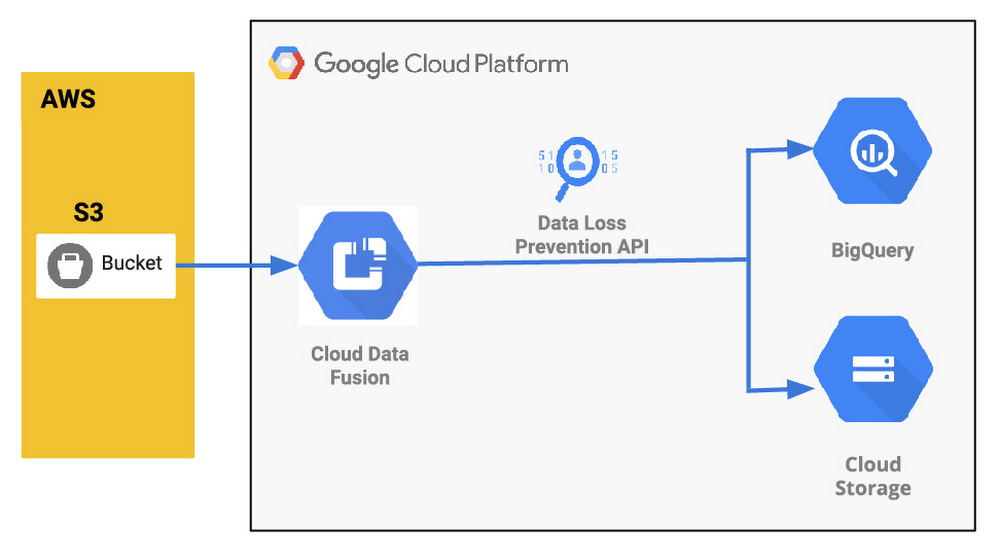
一般的なデータ パイプラインのユースケースについて
もう少し詳しくコンテキストを説明するために、具体的(かつ一般的)なユースケースを次に示します。
アプリケーションが AWS でホストされ、ログファイルが再帰的に生成される。ファイルは gzip を使用して圧縮され、S3 バケットに保存される。
組織が Google Cloud サービスを使用して最新のデータレイクやクラウド データ ウェアハウスを構築しており、AWS に保存されたログデータを取り込む必要がある。
取り込んだデータを SQL ベースの分析ツールで分析し、バックアップと保持のために未加工のファイルとしても取得する必要がある。
ソースファイルに個人情報(PII)が含まれており、コンテンツの一部を使用する前にマスキングする必要がある。
翌日に分析を行うために、新しいログデータを 1 日の終わりに読み込む必要がある。
お客様は、さまざまなデータソースからのデータに対して STRAIGHT JOIN を実行し、データ ウェアハウスにそのデータが格納された後、データセット全体に機械学習予測を適用する必要がある。
Google Cloud でできること
上述の ETL(抽出、変換、読み込み)シナリオに対処するため、4 つの Google Cloud サービス、Cloud Data Fusion、Cloud Data Loss Prevention(DLP)、Google Cloud Storage、BigQuery の使用方法を示します。
Data Fusion は、データ パイプラインを素早く構築、管理できる、クラウドネイティブのフルマネージド エンタープライズ データ統合サービスです。Data Fusion ウェブ UI を使用すると、基盤となるインフラストラクチャを管理することなく、データのクリーニング、準備、ブレンド、転送、変換を行うスケーラブルなデータ統合ソリューションを構築できます。Data Fusion を Google Cloud と統合することで、データ セキュリティを簡単に確保でき、データをすぐに分析できるようになります。この演習では、Data Fusion を使用して、データ取り込みパイプライン全体をオーケストレートします。
Cloud DLP は、Data Fusion パイプライン内の API によってネイティブに呼び出すことができます。フルマネージド サービスである Cloud DLP は、特に機密性の高いデータを自動的に検出、分類、保護できるように設計されています。Cloud DLP には InfoType が 120 種類以上組み込まれており、Cloud Storage と BigQuery 内の機密性の高いデータをスキャン、分類する機能をネイティブにサポートしています。また、他のデータソース、カスタム ワークロード、アプリケーションをサポートするためのストリーミング コンテンツ API も備えています。この演習では、Cloud DLP を使用して、レコードに記載されている電話番号などの個人を特定できる機密情報(PII)をマスクします。
データを匿名化したら、Google Cloud に保存して分析のために使用できるようにする必要があります。上述の特定の要件について説明するために、Cloud Storage(耐久性が高く、地理的に冗長な Google のオブジェクト ストレージ)および BigQuery(サーバーレスで、スケーラビリティと費用対効果に優れた Google のマルチクラウド データ ウェアハウス ソリューション)の使用方法を示します。
データ パイプラインの概要
作成するデータ パイプラインを次に示します。AWS の S3 インスタンスを出発点とし、Wrangler と Redact API を使用して匿名化して、データを Cloud Storage と BigQuery に移動させます。
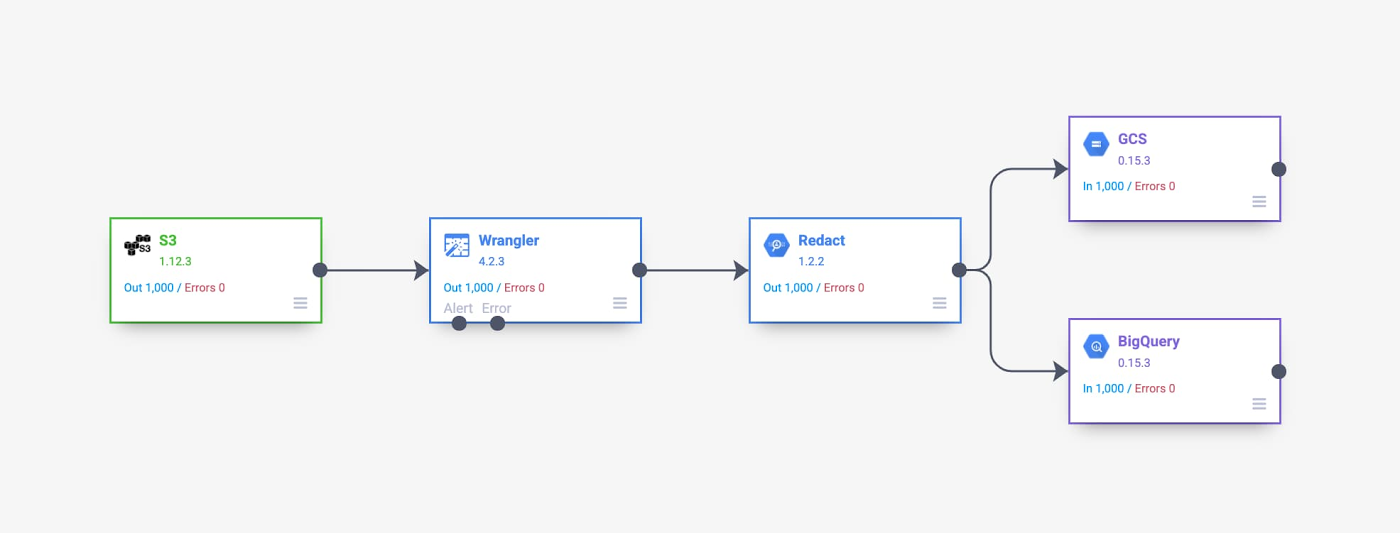
データ パイプラインの開発とデプロイのプロセスの説明
データ パイプラインの開発とデプロイのプロセス全体を説明するため、7 つのシリーズ動画を作成しました。それぞれのステップに関する動画をご覧いただけます。
ステップ 1(省略可): ユースケースについてまだ理解していないか、再確認する場合は、こちらの動画が最適です。ユースケースの概要を示し、対処すべき特定の要件を説明しています。必要に応じてご覧ください。

ステップ 2: この次の動画では、ソースデータを編成する方法を説明しています。AWS でデータを保存する方法を理解し、取り込みパイプラインで使用されるサンプル ファイルの構造を詳しく見ることができます。

ステップ 3: ユースケースの目的とソースデータの構造を理解した後は、こちらの動画を視聴してパイプラインの作成を開始します。この動画では、Cloud Data Fusion の概要を簡単に確認できます。また、Data Fusion の Wrangler 機能を使用してノーコード データ変換を実施する方法を理解して、Wrangler 画面から取り込みパイプライン作成を開始できます。

ステップ 4: 前述のとおり、このサンプルのユースケースにおける重要な要件は、データを使用する前に匿名化することです。パイプラインを作成しながら、Data Fusion 内から Cloud DLP API 呼び出しを開始する方法を理解することで、データを永続的に保存する前にオンザフライで匿名化できます。詳細なステップについては、こちらの動画をご覧ください。

ステップ 5: データを匿名化したので、次に Google Cloud に保存します。このユースケースでは構造化されたファイルのバックアップと SQL ベースの分析の両方を行う必要があるため、Cloud Storage と BigQuery の両方にデータを保存します。Cloud Storage のシンクと BigQuery のシンクの両方を既存のパイプラインに追加する方法については、こちらの動画をご覧ください。

ステップ 6: もう少しで完了です。ここで今までの作業を検証します。パイプラインを完全にデプロイする前に、「試してみる」ことをおすすめします。試してみるには、パイプラインのプレビュー機能を使用します。この短い動画を視聴して、データ取り込みパイプラインをプレビューしてからデプロイする方法を理解し、少し時間を取ってスケジューリングとデプロイ プロファイルのオプションを確認しましょう。

ステップ 7: 最後のステップです。こちらの動画を視聴して、パイプライン全体の実行を分析する機能を確認します。また、この動画では、Cloud Storage と BigQuery の両方で概括的なデータ検証を実施する方法が説明されています。

次のステップ:
同じような課題をお持ちでしたら、次に Google Cloud でこちらの Cloud Data Fusion のクイックスタートをお試しください。ご健闘をお祈りいたします。
-Google カスタマー エンジニア(大のデータ好き)Carlos Augusto
