リアルタイムの変更データ キャプチャを使用した BigQuery へのデータ レプリケーション
Google Cloud Japan Team
※この投稿は米国時間 2021 年 5 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
データドリブンの意思決定をタイムリーに実現したいと考えている企業は、データの価値が時間の経過とともに低下し、鮮度が落ちる可能性を理解しています。データの入手とほぼ同時にリアルタイムでデータを分析して、分析情報を構築できるシステムの需要が高まったのは、そのためです。多くの場合、ビジネスの糧となる運用データやトランザクション データは、リレーショナル データベースに格納されます。しかしこれは、トランザクションの処理には向いていても、大規模なリアルタイム解析には適していません。
この問題を解決するための従来のアプローチとして、大規模になりがちなデータセット全体を決められた時間に一括して読み込むことで、あるソースから別のソースにデータを複製する方法があります。しかし、これは往々にして費用がかさみ、本番環境システムにかかる負荷も大きいうえに、タイムリーで正確な意思決定のボトルネックにもなります。
運用データやトランザクション データを活用してリアルタイム解析を実行する方法
これを実現するのが、変更データ キャプチャ(CDC)として知られるデータ統合の手法です。CDC は、ソース データベース内の変更(更新、挿入、削除)を識別してキャプチャします。つまり、変更が発生した時点で、変更されたデータのみを処理できます。CDC は、データの取得、レプリケーション、保存、分析において、低レイテンシで、ほぼリアルタイム、かつ費用対効果の高いソリューションを提供します。
CDC により、データ ウェアハウスへのトランザクション データのレプリケーションが可能になり、最新のデータを分析し、オペレーション レポート、ストリーミング分析、キャッシュ無効化、イベント ドリブン アーキテクチャなどに活用できます。しかし、CDC ソリューションの導入は複雑なうえ、高価なライセンスが必要となり、特殊な技術的専門知識に大きく依存することになります。このブログでは、完全にクラウドネイティブなエンドツーエンドのソリューションを活用してこの問題を解決する方法をご紹介します。
リアルタイム CDC を使用して運用データを BigQuery に複製する方法
BigQuery は Google Cloud のデータ ウェアハウスです。サーバーレスかつ費用対効果の高い方法で大量のデータを格納でき、大規模な分析用に最適化されています。BigQuery は運用分析に最適なソリューションですが、最大の課題の一つは、信頼性が高く、タイムリーかつ使いやすい方法でデータを取り込むことです。この分野でのソリューションはこれまでにも散在していましたが、統合についての多くを顧客が負担しなければなりませんでした。
Google Cloud の新しいサーバーレス CDC およびレプリケーション サービスである Datastream のリリースによって、このような課題の多くが解決されます。Datastream は、異種のデータベース、アプリケーション、ストレージ システム間で、最小限のレイテンシでデータを同期します。また、リアルタイム解析を含む多様なユースケースにおいて、データ レプリケーションをサポートします。Datastream は Google Cloud のデータおよび分析サービスと統合して、変更データを BigQuery に複製するためのシンプルなエンドツーエンドのクラウドネイティブ ソリューションを作成できるようにします。
Cloud Data Fusion は、ETL および ELT データ パイプラインを構築するための Google Cloud の統合サービスです。Data Fusion では、使いやすいウィザード形式の操作により、SQL Server や MySQL から BigQuery へのデータのレプリケーションをすでにサポートしています。Data Fusion と Datastream の今回の統合により、Oracle がデータソースとしてサポートされるようになり、高価なライセンスやエージェントは不要になりました。
Dataflow は、統合ストリームおよびバッチデータ処理用フルマネージド サービスです。Dataflow と Datastream の統合では、データを BigQuery、Cloud Spanner、Cloud SQL for PostgreSQL に複製するための 3 つの新しいテンプレートが導入されました。Dataflow テンプレートを拡張またはカスタマイズして、変更データを Datastream のソースから取り込んで処理することもできます。これは、他のソースからのデータを変換または拡張してから Google Cloud に保存する必要がある場合に重要です。
では、これらの統合機能の使い方について、例を見ながら説明していきましょう。
ロンドン市内の家庭に生鮮食品を当日配達する FastFresh というビジネスの経営者であるとします。すべての生鮮食品を売り切って食品の廃棄を最小限に抑えるために、余っている生鮮食品を把握して、当日の販売終了前に割引を行う必要があるかどうかを判断できるリアルタイム レポートを構築したいと考えています。生鮮食品の在庫などの運用データは Oracle に保存されており、顧客が商品を購入すると随時更新されます。このデータを BigQuery に複製して、分析を行い、リアルタイム レポートを生成できるようにします。
Data Fusion と Datastream を使用して Oracle から BigQuery にデータを複製する方法 [デモ]
コーディングが一切不要な Data Fusion は、1 つのサービスを利用してシンプルなエンドツーエンドのレプリケーション パイプラインを構築したいと考えているユーザーに最適なソリューションです。Data Fusion はデータの民主化を念頭に構築されています。ガイド付きレプリケーション ウィザードにより、データ サイエンティストやアナリストだけでなく、ビジネス ユーザーやデータベース管理者もデータ パイプラインの作成や情報管理のオーナー権限を得られるようになります。

Oracle から BigQuery へ在庫データを同期するには、ウィザードに沿ってデータソースと宛先を設定するだけです。ユーザーは、同期するテーブル、列、変更操作(更新、挿入、削除)を選択できます。このようにきめ細かくコントロールすることで、実際に複製する必要のあるデータのみをキャプチャして、冗長性、レイテンシ、費用を最小限に抑えることができます。
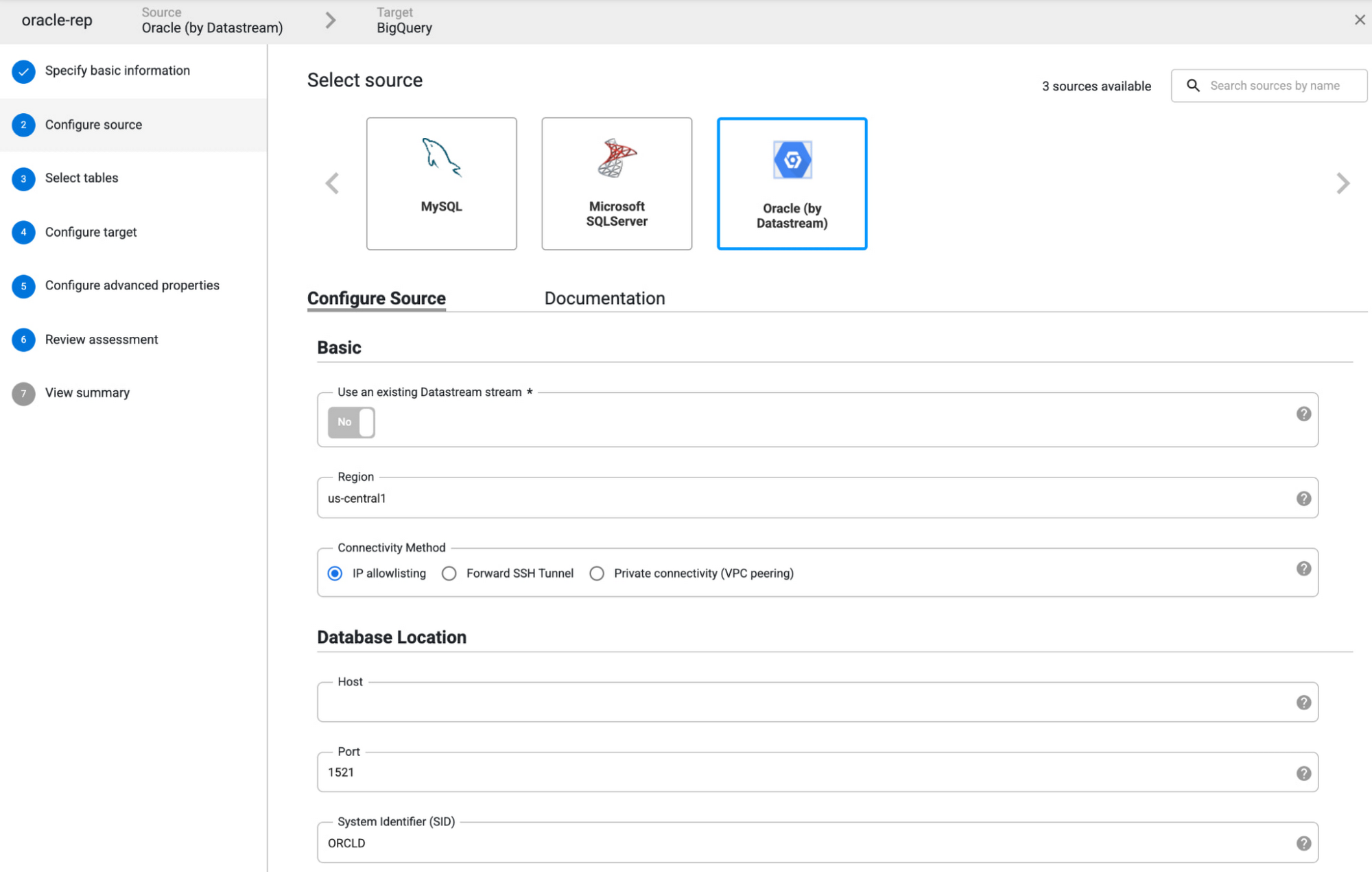
Data Fusion では、レプリケーション プロセスの開始前に実現可能性評価が行われます。そのため、レプリケーションを開始する前に問題を修正でき、本番環境に対応したパイプラインの構築プロセスを早めることができます。
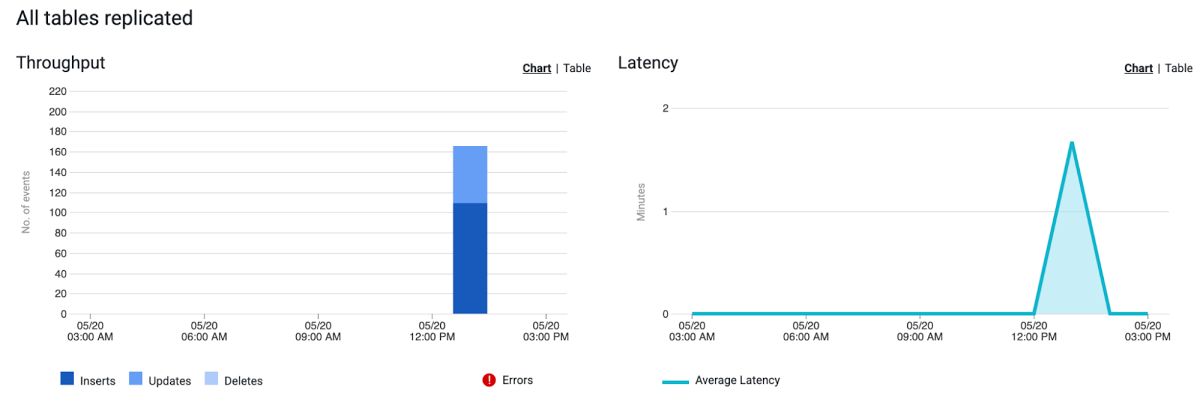
最後に、モニタリング ダッシュボードを使用してストリーミングのパフォーマンスとイベントを可視化することで、パイプラインを全体的に監視して、ボトルネックや予期せぬ動作をリアルタイムで発見できるようになります。
Dataflow のテンプレートを使用して運用データを BigQuery、Spanner、Cloud SQL に複製する方法[デモ]
BigQuery 以外のターゲットにデータを複製する必要がある場合や、独自の変更データ キャプチャ ジョブを作成して管理したいと考えているデータ エンジニアの場合は、Datastream と Dataflow を組み合わせてレプリケーションを行います。この統合を合理的に行えるよう、新しい 3 つの事前構築されたストリーミング テンプレートが Dataflow のインターフェースに導入されました。
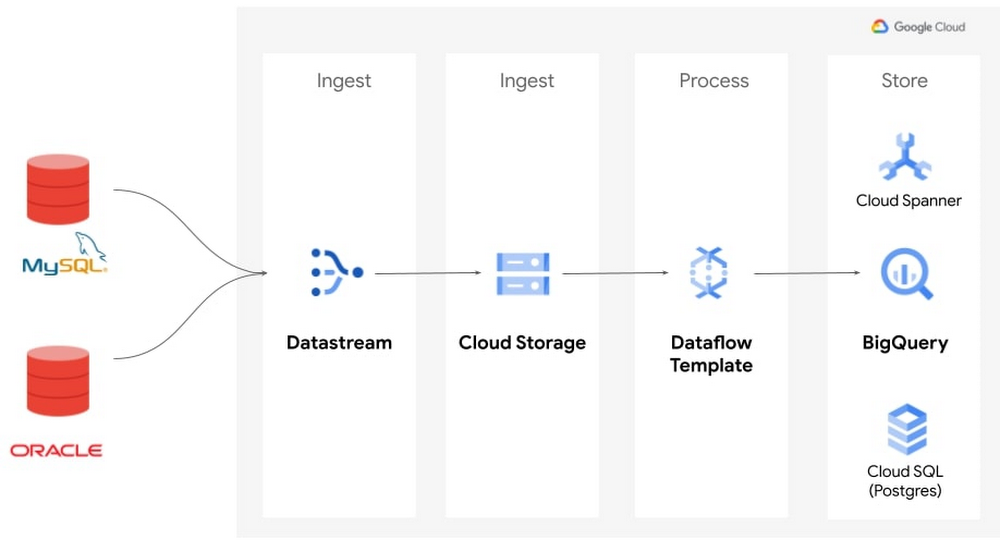
これらのテンプレートにより、Java や Python の専門知識を必要としない、軽量でシンプルなレプリケーション ソリューションが実現します。
まず、変更データを Cloud Storage バケットに同期するための Datastream ストリームを作成します。同じバケットを複製先とする複数のソースについて、複数のストリームを作成できます。つまり、複数のソースからの変更データを 1 つの Dataflow ジョブで BigQuery にストリーミングでき、管理が必要なパイプラインの数を減らすことができます。Datastream は、さまざまなソースにおけるデータ型を正規化します。これにより、ソースに依存しないダウンストリーム処理を Dataflow で容易に行えるようになります。
次に、新しいストリーミング テンプレートの一つである「Datastream to BigQuery」を使用して、今回のユースケース用に Dataflow ジョブを作成します。必要な操作は、ストリーミングのソースバケット、ステージング データセットとレプリケーション データセットを BigQuery で指定するだけです。
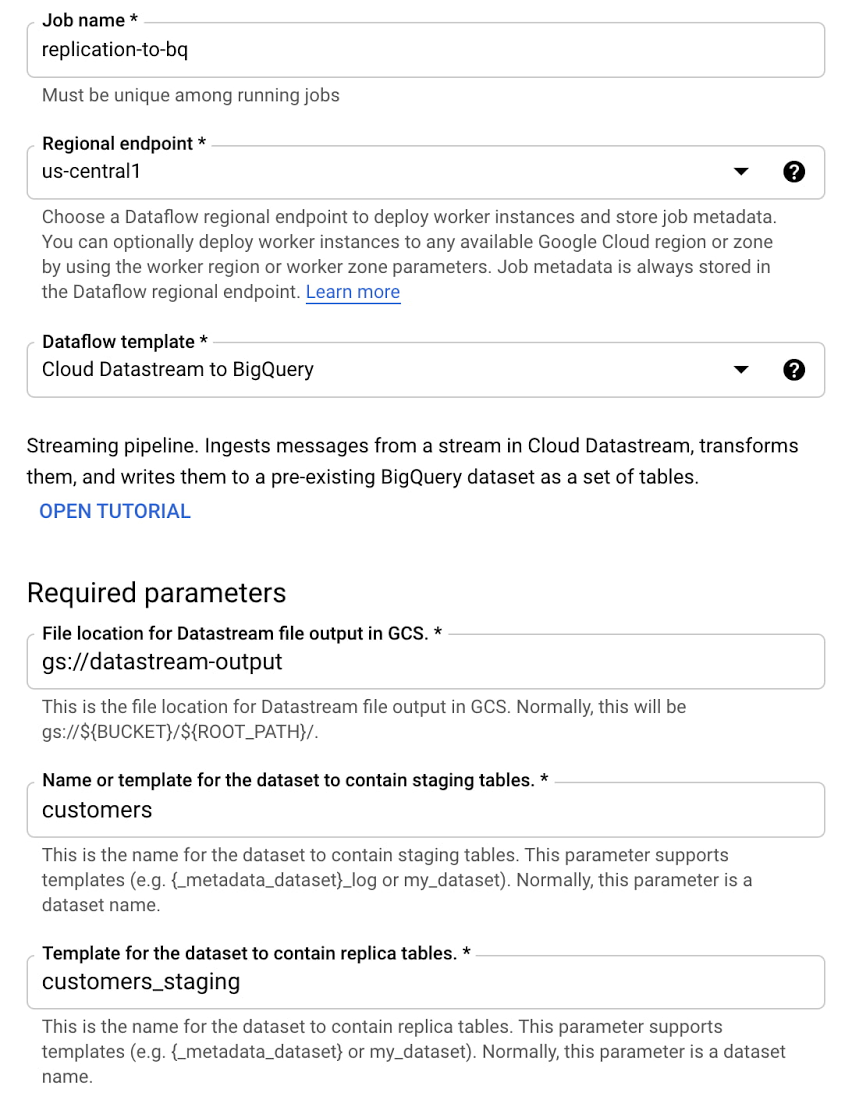
これで完了です。ジョブが最短の起動時間で開始されて、変更データが BigQuery に複製されます。次回のブログ投稿では、Dataflow CDC のジョブを動作中に改善する方法のヒントをご紹介します。
メリットの活用: 運用データを BigQuery で分析する方法
運用データが BigQuery に複製されて、費用対効果の高いストレージと分析能力を最大限に活用できるようになりました。BigQuery はサーバーレスでスケールでき、ペタバイトのデータに対して数秒でクエリを実行して、リアルタイムの分析情報を構築できます。複製されたテーブルに関するマテリアライズド ビューを作成してパフォーマンスと効率性を上げたり、BQML を活用して需要予測やレコメンデーションなどの ML モデルを作成、実行したりできます。

今回のユースケースでは、在庫をリアルタイムでモニタリングするダッシュボードを作成しようと考えました。BigQuery のデータを Looker のようなビジネス インテリジェンス サービスに接続することで、高機能なリアルタイム レポートのプラットフォームを構築できます。
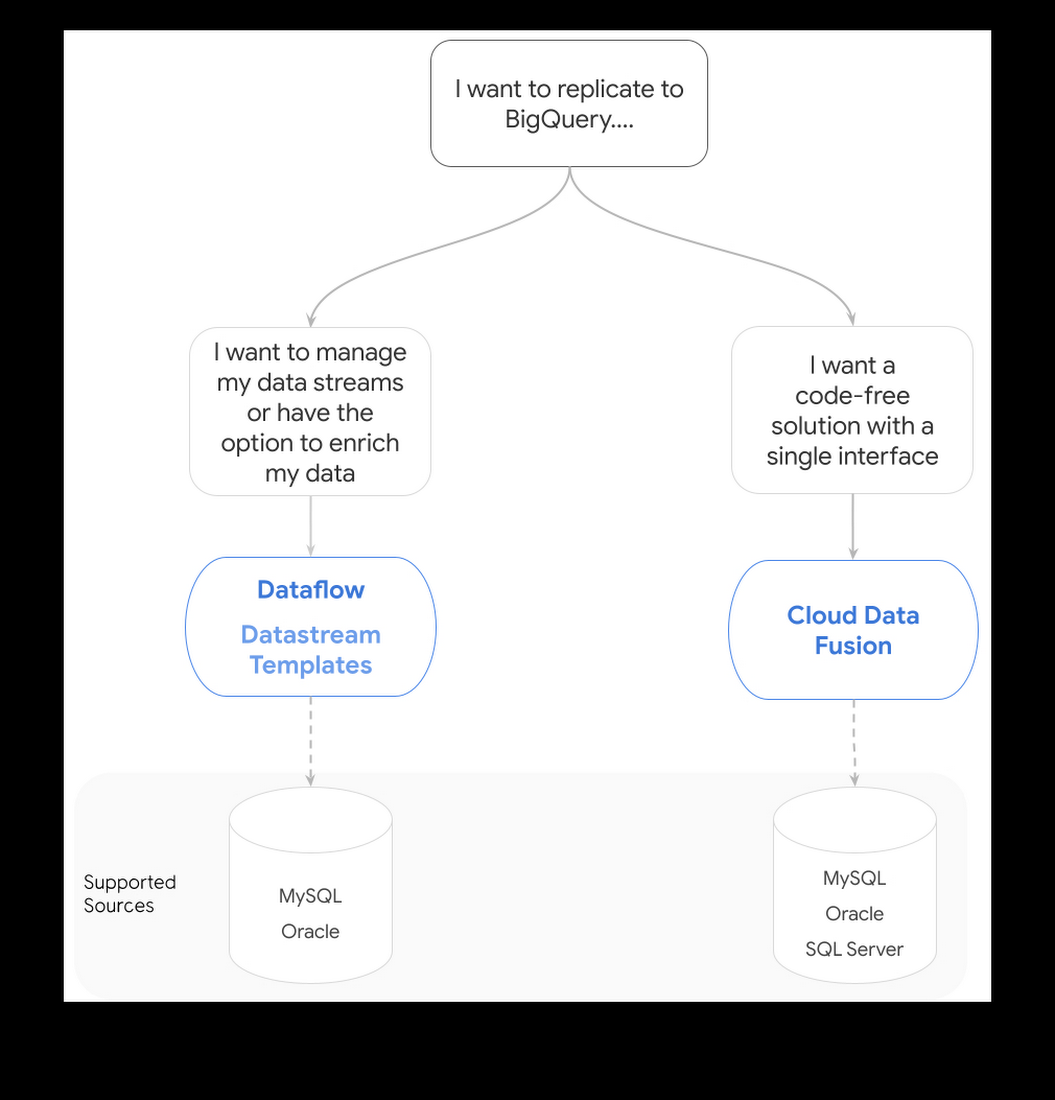
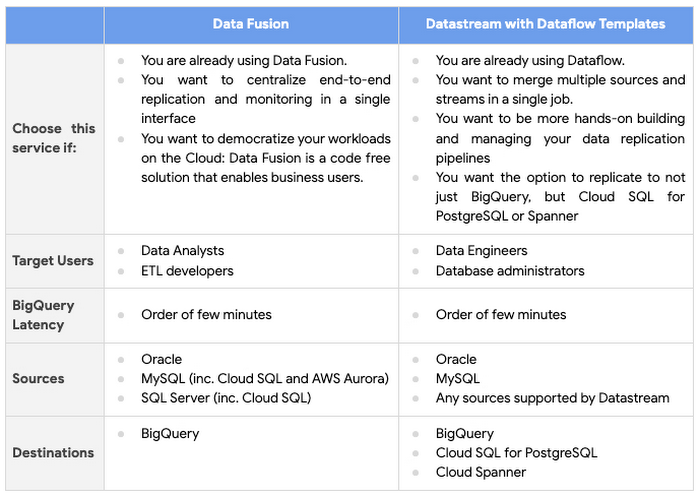
Data Fusion と Dataflow(Datastream 固有のテンプレートを使用)のどちらも、Google Cloud のストレージ ソリューションにデータを複製します。以下の表は、ユースケースや組織にとって正しい判断を下す際に役立ちます。
Cloud Data Fusion を使用すべき場合と Dataflow テンプレートを使用すべき場合
Data Fusion と Dataflow(Datastream 固有のテンプレートを使用)のどちらも、Google Cloud のストレージ ソリューションにデータを複製します。以下の表は、ユースケースや組織にとって正しい判断を下す際に役立ちます。Data Fusion と Dataflow(Datastream 固有のテンプレートを使用)のどちらも、Google Cloud のストレージ ソリューションにデータを複製します。以下の表は、ユースケースや組織にとって正しい判断を下す際に役立ちます。Data Fusion と Dataflow(Datastream 固有のテンプレートを使用)のどちらも、Google Cloud のストレージ ソリューションにデータを複製します。以下の表は、ユースケースや組織にとって正しい判断を下す際に役立ちます。
レプリケーション後の作業: 変更データを処理または拡張してから目的の宛先と同期する方法
テンプレートやコード不要のソリューションは、データをそのまま複製するには最適です。ただし、データを受信と同時に拡張または処理してから BigQuery に格納する場合はどうでしょうか。たとえば、購入前に顧客が会員カードをスキャンしたら、外部サービスから会員の詳細情報を検索して変更データを拡張してから、データを BigQuery に保存したい場合があります。
Dataflow は、まさにこのようなビジネスケースを解決するために構築されました。Dataflow のテンプレートを拡張またはカスタマイズして、変更データを Datastream のソースから取り込んで処理することができます。このシリーズの次回のブログでは、変更データの拡張方法についてさらに詳しくご紹介します。
それまでの間に、Google の Datastream に関するブログ投稿をお読みになり、Dataflow や Data Fusion を利用して運用データを BigQuery に複製してみましょう。
Google は複数のパートナーと協力して、共通のお客様が抱えるオペレーション レポートの重要なニーズへの対応に取り組んでいます。このソリューションに関するパートナーの体験や観点については、Cognizant のブログをご参照ください。
-Google Cloud デベロッパー アドボケイト Rachael Deacon-Smith
-Google Cloud プロダクト マネージャー Griselda Cuevas

