Real-time Change Data Capture for data replication into BigQuery
Rachael Deacon-Smith
Developer Advocate, Google
Griselda Cuevas
Product Manager
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialEditor’s note: Seamless, direct replication into BigQuery, is now available with Datastream for BigQuery. For the most up to date information, please read our Datastream for BigQuery launch blog here.
Businesses hoping to make timely, data-driven decisions know that the value of their data may degrade over time and can be perishable. This has created a growing demand to analyze and build insights from data the moment it becomes available, in real-time. Many will find that the operational and transactional data fuelling their business is often stored in relational databases, which work well for processing transactions, but aren’t designed or optimized for running real-time analytics at scale.
Traditional approaches to solving this challenge include replicating data from one source to another in scheduled bulk loads of entire, frequently large, datasets. This is often costly, strenuous on production systems, and can become a bottleneck to making timely and accurate decisions.
So, how can you run real-time analytics against operational and transactional data?
You can achieve this with a technique for data integration known as Change Data Capture (CDC). CDC identifies and captures changes in source databases (updates, inserts and deletes). This allows you to process only the data that has changed, at the moment it changes. CDC delivers a low-latency, near real-time, and cost-effective solution for data acquisition, replication, storage and analysis.
CDC can replicate transactional data into data warehouses, unlocking the potential to analyze the freshest data for operational reporting, streaming analytics, cache invalidation, event-driven architectures, and more. However, implementing CDC solutions can be complex, require expensive licenses, and be heavily reliant on niche technical expertise. In this blog, we’ll explore how you can take advantage of a completely cloud-native, end-to-end solution to this problem.
Replicating operational data into BigQuery with real-time CDC
BigQuery is Google Cloud’s data warehouse which offers a serverless and cost-effective way to store large amounts of data, it is uniquely optimized for large-scale analytics. While BigQuery is a great solution for operational analytics, one of the biggest challenges is bringing in data in a reliable, timely, and easy-to-use manner. There have been scattered solutions in this area, but they have largely placed the burden of integration on customers.
The launch of Datastream, our new, serverless CDC and replication service, solves many of these challenges. Datastream synchronizes data across heterogeneous databases, applications, and storage systems with minimal latency. It supports data replication for a variety of use cases, including real-time analytics. Datastream integrates with our Data and Analytics services allowing you to create simple, end-to-end, cloud-native solutions that replicate your changed data into BigQuery:
Cloud Data Fusion is Google Cloud’s integration service for building ETL and ELT data pipelines. Data Fusion already supports the replication of data from SQL Server and MySQL to BigQuery through an easy-to-use, wizard-driven experience. Data Fusion now integrates with Datastream to support Oracle as a data source, without the need for expensive licenses or agents.
Dataflow is our fully managed service for unified stream and batch data processing. Dataflow’s integration with Datastream includes the launch of three new templates that replicate data to BigQuery, Cloud Spanner and Cloud SQL for PostgreSQL. You can also extend and customize the Dataflow templates that ingest and process changed data from Datastream sources. This is key if you need to do transformations or enrichments with data from another source before storing it in Google Cloud.
Let’s dive into an example and explore how you can use these integrations:
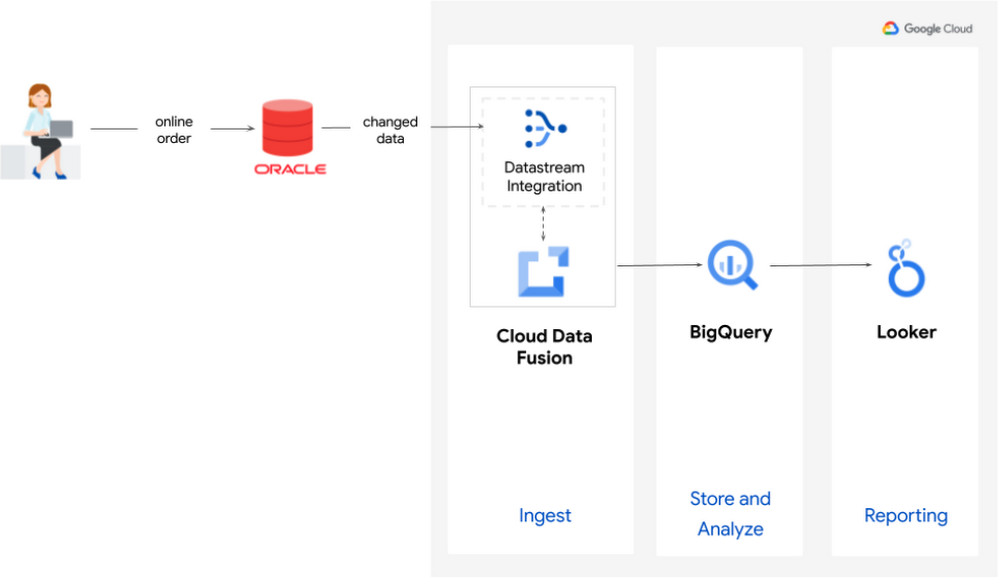
Imagine that you are running a business, FastFresh, that offers same day delivery of fresh food to homes across London. To sell all your produce and minimize food waste, you want to build real-time reports to understand whether you have a surplus of produce and should apply discounts before the end of the day. Your operational data, such as produce inventory, is stored in Oracle and is being continuously updated as customers purchase goods. You want to replicate this data into BigQuery so you can run analysis and generate these real-time reports.
Replicating data from Oracle to BigQuery with Data Fusion and Datastream [Demo]
Data Fusion is completely code-free and is the perfect solution for those wanting to build a simple, end-to-end replication pipeline using one service. Data Fusion is built with data democratization in mind - a guided replication wizard invites not just data scientists and analysts, but also business users and database administrators to take ownership of their data pipeline creation and information management.
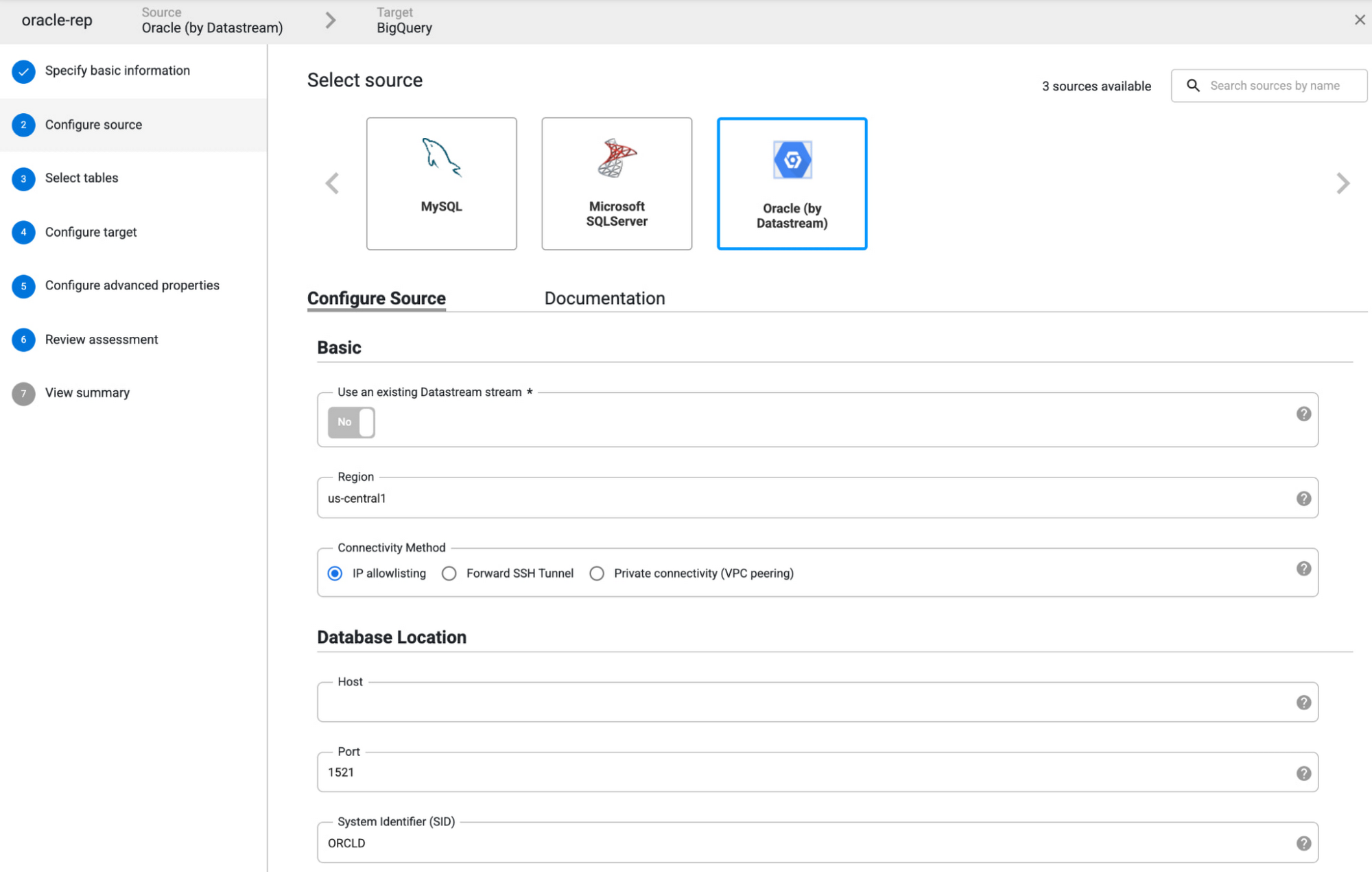
To synchronize your inventory data from Oracle to BigQuery you just need to follow the wizard to set up your data sources and destinations. You can select the tables, columns and change operations (update, inserts or deletes) that you want to synchronize. This granular level of control allows you to capture only the data that you actually need replicated, minimizing redundancy, latency and cost:
Data Fusion will generate a feasibility assessment before beginning the replication process, giving you the opportunity to fix any problems before starting replication, fast-tracking your journey to building a production-ready pipeline.
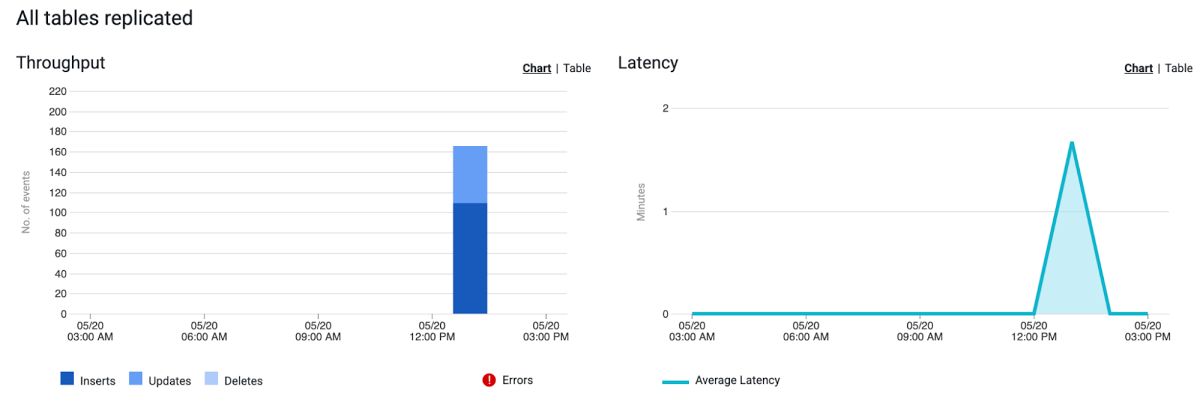
Finally, you can use the monitoring dashboard to visualize your streams performance and events, enabling you to build a holistic oversight of your pipeline and spot any bottlenecks or unexpected behavior in real time:
Replicating your operational data into BigQuery, Spanner or Cloud SQL with Dataflow Templates
If you need to replicate data to targets other than BigQuery, or you are a data engineer wanting to build and manage your own change data capture jobs, you’ll want to use a combination of Datastream and Dataflow for replication. To streamline this integration, we’ve launched three new pre-built streaming templates in Dataflow’s interface:
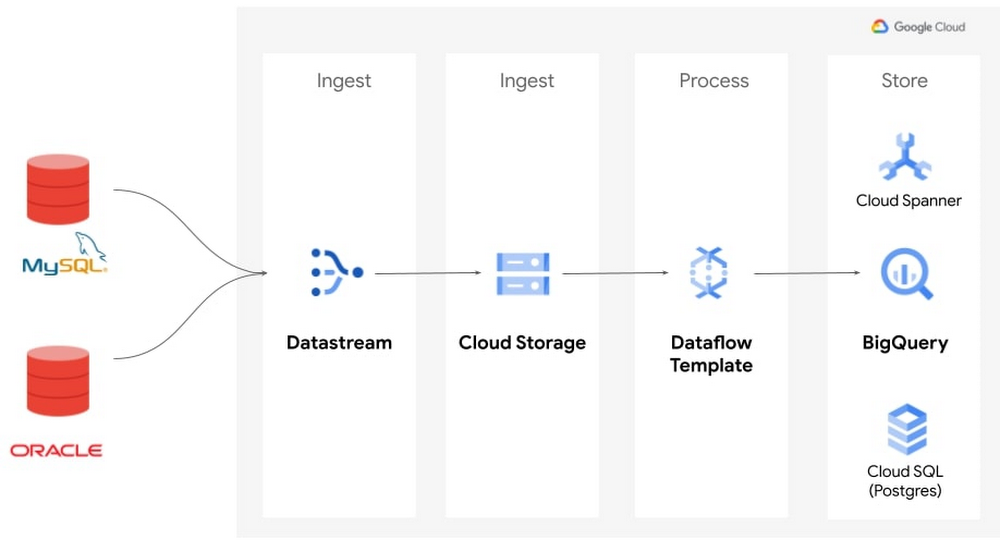
These templates offer a lightweight and simple replication solution that doesn't require expertise in Java or Python.
You first create a Datastream stream to synchronize your changed data to a Cloud Storage bucket. You can create multiple streams across multiple sources that replicate into the same bucket. This means you can stream change data from multiple sources into BigQuery with a single Dataflow job, reducing the number of pipelines you need to manage. Datastream normalizes data types across sources, allowing for easy, source-agnostic downstream processing in Dataflow.
Next, you create a Dataflow job from one of our new streaming templates - Datastream to BigQuery, for our use case. All you have to do is specify the streaming source bucket and the staging and replication datasets in BigQuery.
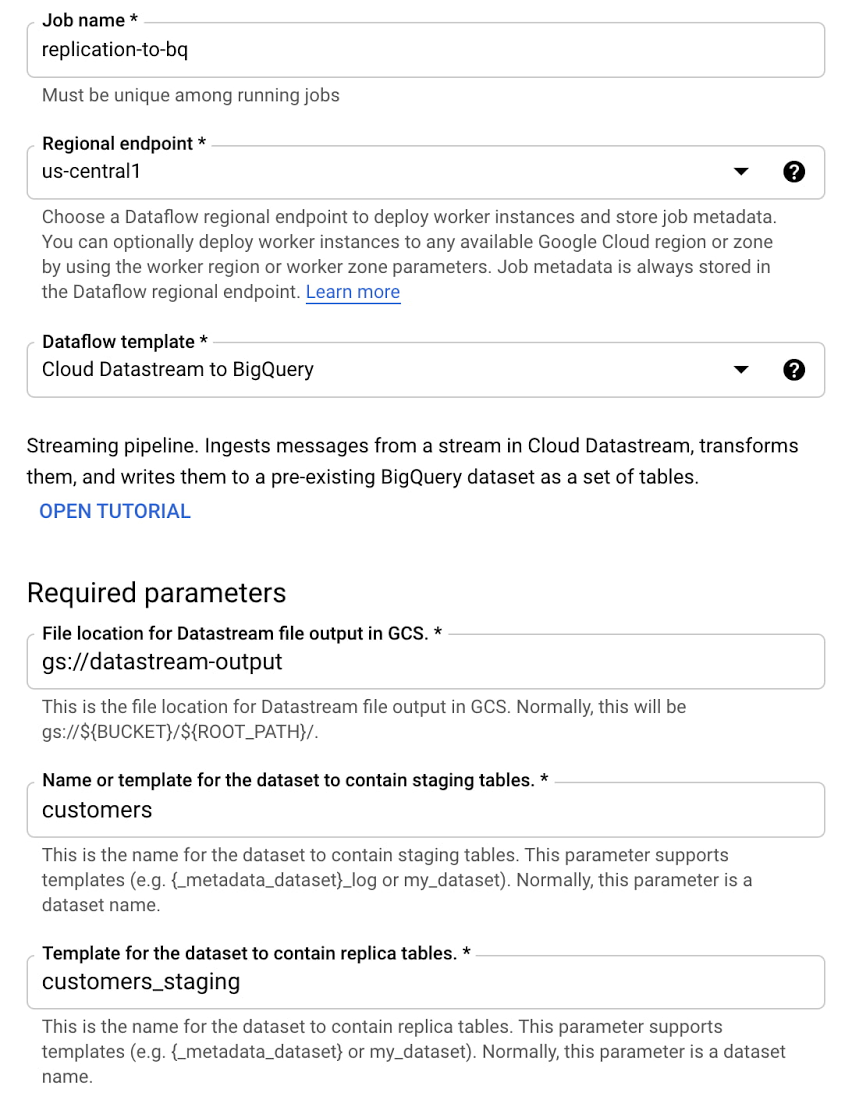
And that’s it! Your job will begin with minimal start up time and changed data will be replicated to BigQuery. In a subsequent blog post, we’ll share tips on how to enrich your Dataflow CDC jobs on the fly.
Reap the rewards: Analyzing your operational data in BigQuery
Now that your operational data is being replicated to BigQuery, you can take full advantage of its cost-effective storage and analytical prowess. BigQuery scales serverlessly and allows you to run queries over petabytes of data in a matter of seconds to build the real time insights. You can create materialized views over your replicated tables to boost performance and efficiency or take advantage of BQML to create and execute ML models for say, demand forecasting or recommendations.

In our use case, we wanted to create dashboards to monitor stock inventory in real-time. Connecting your BigQuery data to business intelligence services like Looker allows you to build sophisticated, real-time reporting platforms.
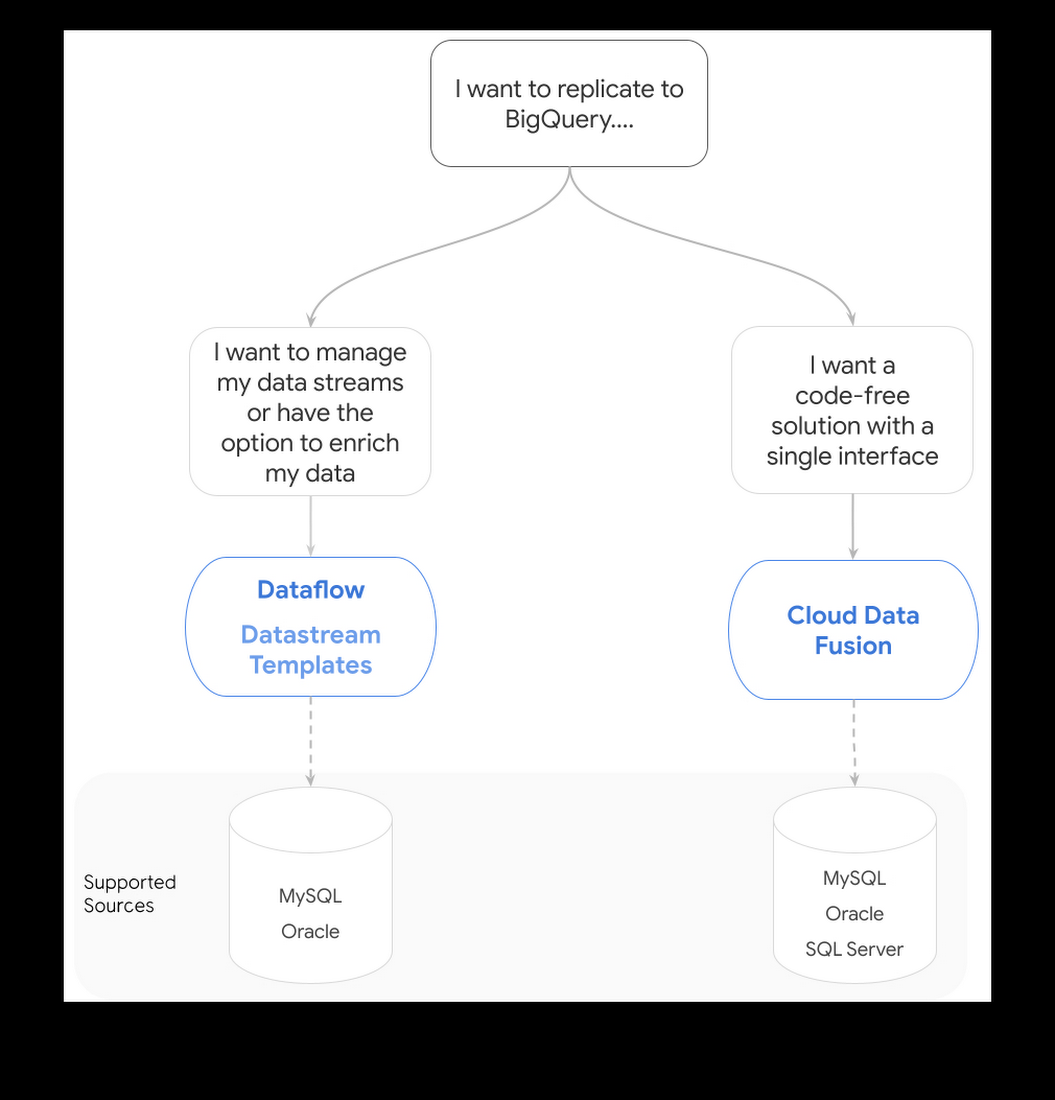
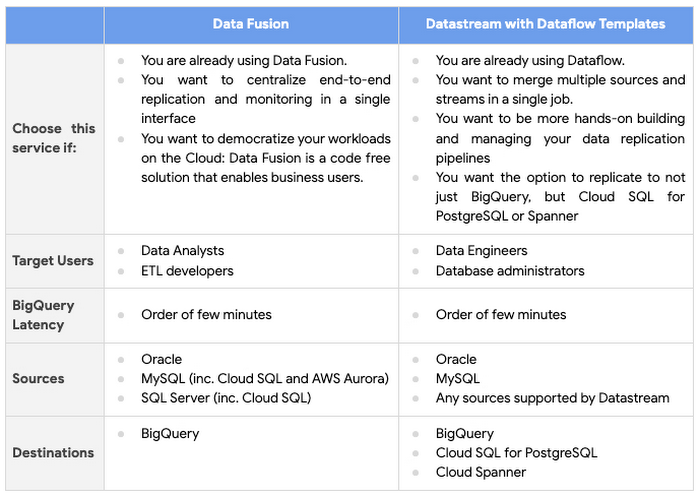
When should I use Cloud Data Fusion or Dataflow templates?
Both Data Fusion and Dataflow (using Datastream-specific templates) replicate data to storage solutions in Google Cloud. Here’s a table that can help you make the right decision for your use case and organization:
Beyond replication: Processing and enriching your changed data before synchronizing to your target destination
Templates and code-free solutions are great for replicating your data as it is. But what if you wanted to enrich or process your data as it arrives, before storing it in BigQuery? For example, when a customer scans their membership card before making a purchase, we may want to enrich the changed data by looking up their membership details from an external service before storing this into BigQuery.
This is exactly the type of business case Dataflow is built to solve! You can extend and customize the Dataflow templates that ingest and process changed data from Datastream sources. Stay tuned for our next blog in this series as we explore enriching your changed data in more detail!
In the meantime, check out our Datastream announcement blog post and start replicating your operational data into BigQuery with Dataflow or Data Fusion.
We’ve also collaborated with multiple partners who have seen this critical need for operational reporting at our joint customers. Check out the blog posts from Cognizant and TCS.


