Dataproc の Presto オプション コンポーネントを提供開始
Google Cloud Japan Team
※この投稿は米国時間 2020 年 7 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
Presto はオープンソースの分散 SQL クエリエンジンで、さまざまなタイプのデータソースに対するインタラクティブ分析クエリの実行に使用できます。このたび、Dataproc の Presto オプション コンポーネントの一般提供を開始しました。Dataproc は、オープンソース エコシステムからデータ処理ソフトウェアを実行するための Google のフルマネージド クラウド サービスです。この新しいオプション コンポーネントでは、短時間でのクラスタ起動や、他の Dataproc コンポーネントとの統合テストを含む、Google Cloud が提供するサポートをすべてご利用いただけます。
Dataproc の Presto コンポーネントのリリースには、Presto をより使いやすくするための新機能がいくつか含まれています。これには、設定不要の BigQuery 統合のサポート、コンポーネント ゲートウェイでの Presto UI のサポート、Cloud Monitoring と JMX およびロギングとの統合、Presto ジョブ送信による SQL コマンドの自動化、Presto JVM 構成の改善などがあります。
Dataproc で Presto を使用する理由
Presto を使用すると、オンプレミス システムや他のクラウドにある複数のソースからのデータに対し、アドホック分析を高速かつ簡単に処理、実施できます。大規模な Dataproc インスタンスと、BigQuery、HDFS、Cloud Storage、MySQL、Cassandra、Kafka などの他のソースに対し、フェデレーション型のクエリをシームレスに実行可能です。また、Presto を使用して BigQuery の次回の抽出、変換、読み込み(ETL)ジョブを計画することもできます。Presto クエリを使用すると、データセットをリンクする方法の理解、必要なデータの判別、複数の基盤となるソースシステムから情報をカプセル化する横長の非正規化された BigQuery テーブルの設計を適切に行うことができます。この処理についての詳しいチュートリアルをご覧ください。
Dataproc で Presto を使用する場合、Presto オプション コンポーネントによって Presto の開始に必要な多くのオーバーヘッドが処理されるため、データ分析にかかる時間を短縮できます。Presto のコーディネーターや作業者は自動的に管理されます。Hive などの外部メタストアを使用して Presto カタログを管理することも可能です。初期化アクションやコンポーネント ゲートウェイなど、Presto UI を表示できる Dataproc 機能を利用することもできます。
以下では、Dataproc で Presto を使用するメリットをさらに詳しくご紹介していきます。
JVM チューニングの強化
Presto コンポーネントでは、Presto コミュニティで確立されている推奨事項に基づいて、ガーベッジ コレクションとメモリ割り当てのプロパティが適切に指定されるよう構成されています。クラスタの構成の詳細については、Presto のドキュメントをご覧ください。
BigQuery との統合
BigQuery は、サーバーレスでスケーラビリティと費用対効果の高い Google Cloud のクラウドデータ ウェアハウス サービスです。Presto オプション コンポーネントとともに使用すると、BigQuery コネクタがデフォルトで使用可能になり、BigQuery Storage API を利用して BigQuery でデータに Presto クエリを実行できます。設定なしで使用を開始できるように、Presto オプション コンポーネントには、デフォルトでインストールされる次の 2 つの BigQuery カタログも付属しています。Dataproc クラスタと同じプロジェクト内のデータにアクセスできるようにするbigquery と、BigQuery の一般公開データセット プロジェクトにアクセスできるようにするための bigquery_public_data です。クラスタ プロパティを使用すれば、クラスタの作成時に独自のカタログを追加することもできます。クラスタ作成コマンドに以下のプロパティを追加すると、bigquery_my_other_project という名前の別のプロジェクトにアクセスするための my-other-project というカタログが作成されます。注: この機能は現在 Dataproc イメージ バージョン 1.5 またはプレビュー イメージ バージョン 2.0 でのみサポートされています。BigQuery コネクタには Presto バージョン 331 以降が必要なためです。
外部メタストアを使用してカタログを管理
Presto クラスタでは、クラスタの作成時にカタログを追加できますが、Hive などの外部メタストアを使用し、それをクラスタ構成に追加することで、Presto カタログの管理も行えます。クラスタの作成時に以下のプロパティを追加します。
Dataproc Metastore はアルファ版のお客様にもご利用いただけるようになりました。これにより、Presto メタデータ情報に複数の Dataproc クラスタからアクセスできるようにする包括的に管理されたサーバーレス オプションが使用可能になり、Apache Spark や Apache Hive などの他の処理エンジン間でテーブルを共有可能になります。
Presto オプション コンポーネントを使用して Dataproc クラスタを作成する
以下のコマンドを使用して、Presto、Anaconda、Jupyter オプション コンポーネントおよびコンポーネント ゲートウェイを有効にしたリージョンを選択することで Dataproc クラスタを作成できます。Jupyter ノートブックから Presto コマンドを実行できるよう、Jupyter オプション コマンドと必要な Python 依存関係を追加することもできます。
gcloud コマンドを使用して Presto ジョブを送信する
Dataproc の Presto Jobs API を使用して、Presto コマンドを Dataproc クラスタに送信できます。以下の例では、Presto コマンド「SHOW CATALOGS;」を実行して、利用可能なカタログのリストが返されるようにします。
出力は次のようになります。
BigQuery 一般公開データセットに対してクエリを実行する
Presto では BigQuery データセットはスキーマと呼ばれます。データセットの詳細リストを表示するには、SHOW SCHEMAS コマンドを使用します。
次に、SHOW TABLES コマンドを実行して、データセット内のテーブルを確認します。この例では、chicago_taxi_trips データセットを使用します。
次に以下のコードを使用して、taxi_trips テーブルに対し Presto SQL クエリを送信します。
ファイルに保存されている Presto SQL クエリを使用してジョブを送信することもできます。taxi_trips.sql という名前のファイルを作成して、そのファイルに以下のコードを追加します。
次に、このクエリをクラスタに送信するために、以下のクエリを実行します。
Jupyter ノートブックを使用して Presto SQL クエリを送信する
Dataproc Hub または Jupyter オプション コンポーネントを ipython-sql とともに使用すると、Presto SQL クエリを Jupyter ノートブックから実行できます。ノートブックの最初のセルで、以下のコマンドを実行します。
次に、ノートブックからアドホック Presto SQL クエリを実行します。
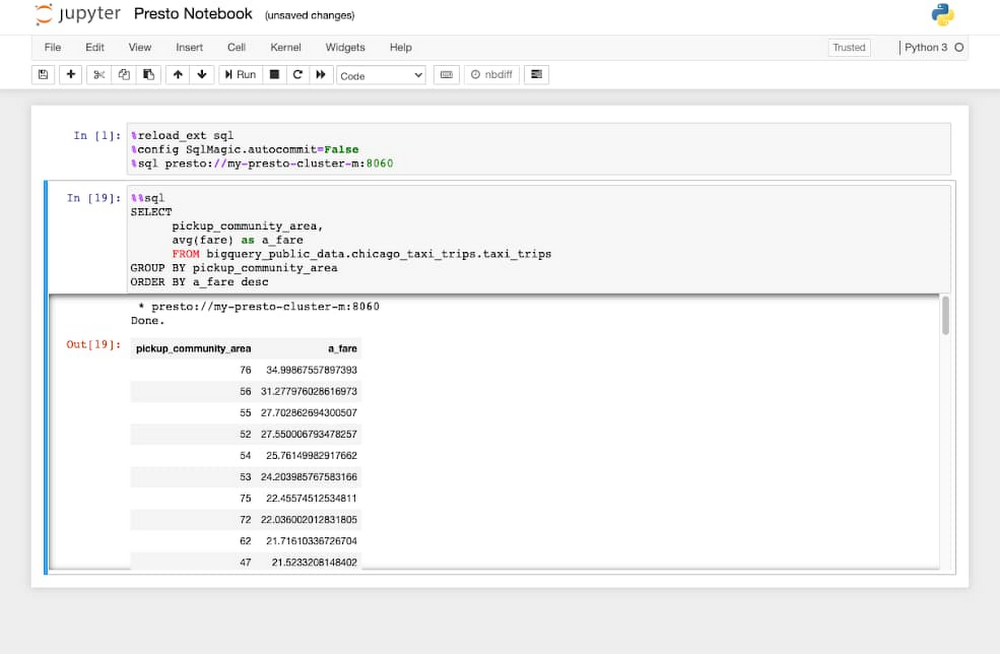
Cloud Console から Presto UI に直接アクセスする
Cloud Console のクラスタページからアクセス可能なリンクを作成するコンポーネント ゲートウェイにより、クラスタに SSH アクセスを行うことなく Presto UI にアクセスできるようになりました。Presto UI を使用すると、共同編集者や作業者の状態をモニタリングできます。
ロギング、モニタリング、診断 tar アーカイブの統合
Presto ジョブが Cloud Monitoring と Cloud Logging に統合されたので、これらのサービスの状態を詳細に管理できるようになりました。
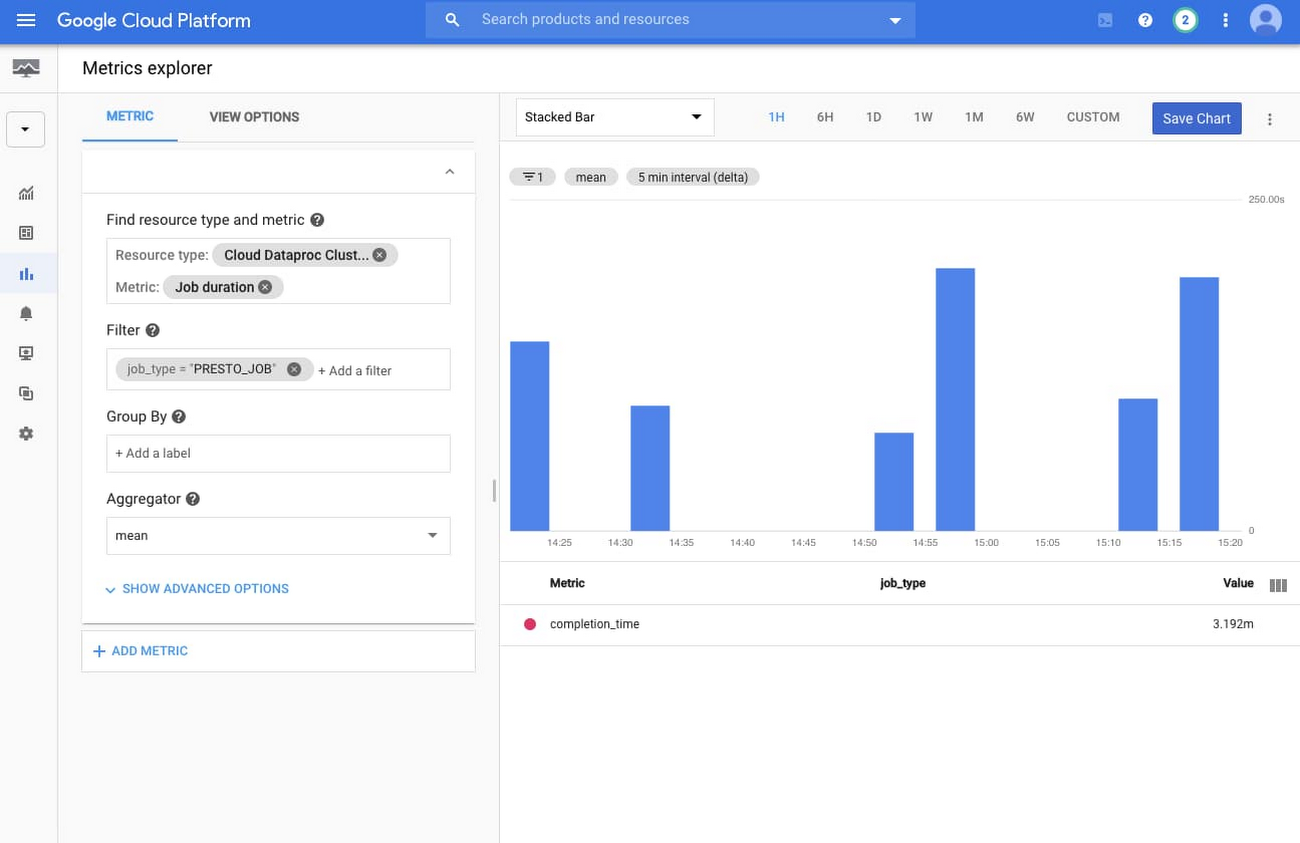
デフォルトで、Presto ジョブの情報は Dataproc クラスタのメインクラスタ モニタリング ページには表示されません。ただし、Cloud Monitoring と Metrics Explorer を使用すれば簡単にダッシュボードを新規作成できます。
クラスタ上のすべての Presto ジョブのグラフを作成するには、[Resource type] として [Cloud Dataproc Cluster]、[Metric] として [Job duration] を選択します。次に、job_type = PRESTO_JOB のみが表示されるようにフィルタを適用し、[Aggregator] を [mean] に指定します。
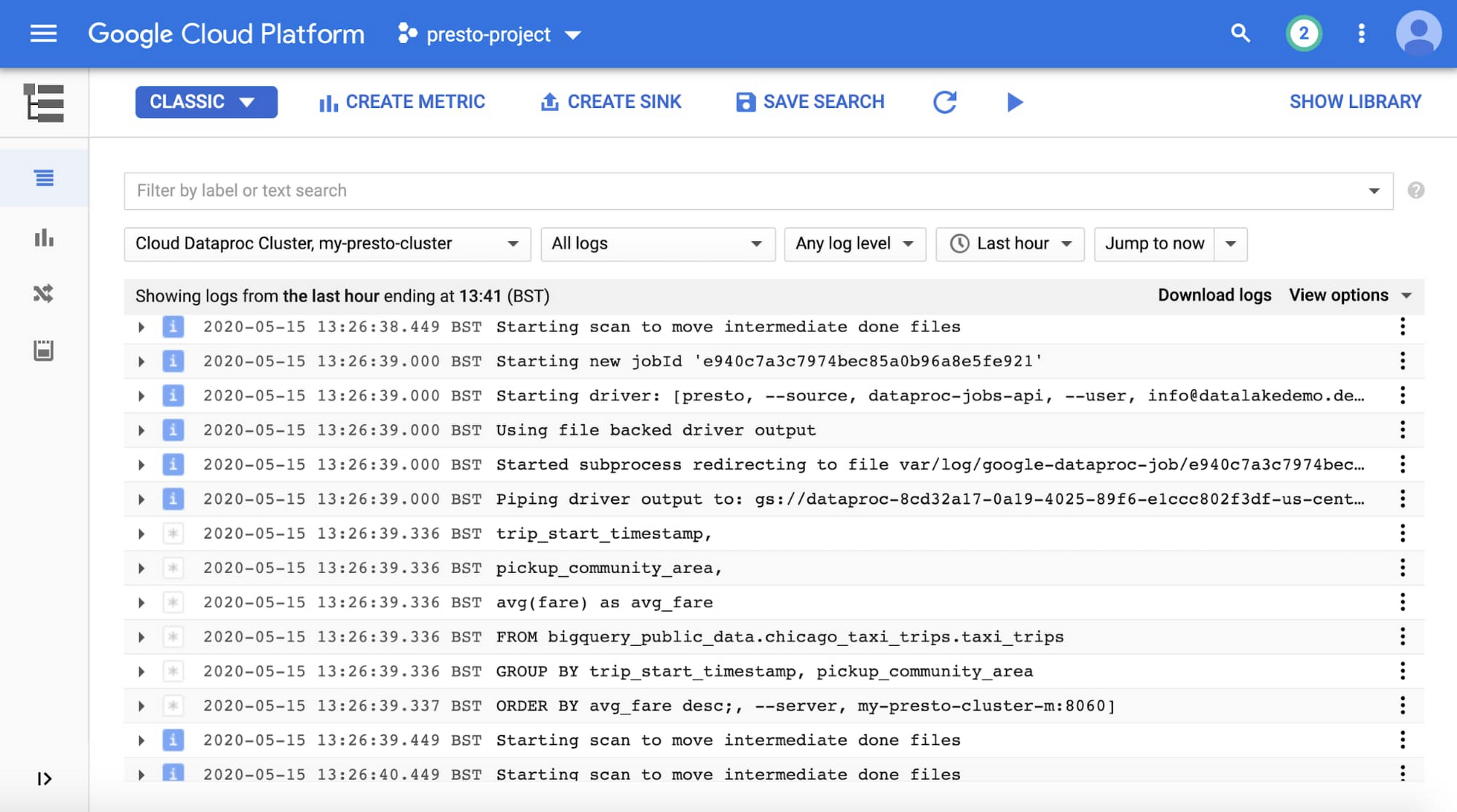
次に示すように、Cloud Monitoring のほかに、Cloud Logging でも Presto サーバーとジョブのログを確認できます。
最後に、Presto の構成とログの情報に、Dataproc 診断 tar アーカイブが追加されたことをお知らせします。これをダウンロードするには、以下のコマンドを実行します。
Cloud Dataproc で Presto の使用を開始するには、Cloud Dataproc での Presto の使用に関するチュートリアルをご覧ください。そして、Presto オプション コンポーネントを使用して、Dataproc クラスタに初めての Presto を作成してください。
- サイト リライアビリティ マネージャー Tahir Fayyaz、デベロッパー プログラム エンジニア Brad Miro

