Dataflow ジョブの費用の予測
Google Cloud Japan Team
※この投稿は米国時間 2020 年 5 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
ストリーミング分析では、データを瞬時に処理して分析情報を引き出し、その分析情報を製品やサービスにタイムリーに反映してカスタマー エクスペリエンスの向上に役立たせることができます。ただし、「瞬時のデータ分析情報」という概念はユースケースごとに異なります。データ分析をスピード重視で最適化する企業もあれば、実行コスト重視で最適化する企業もあります。
この投稿では、Google Cloud のフルマネージド ストリーミングおよびバッチ分析サービス Dataflow でジョブの費用を見積もる際のヒントをいくつかご紹介します。Dataflow を使用すると、リソースのプロビジョニングと管理をサーバーレスで行うアプローチにより、ストリーミング分析ジョブを最適化できます。Dataflow はデータ分割を自動的に行い、ワーカーコードを複数の Compute Engine インスタンスに分散してそれを並列処理します。また、高額になりうるデータ集約などのオペレーションを最適化し、自動スケーリングや動的作業再調整機能などにより即座に調整します。
Dataflow の適応型リソースの割り当てがもたらす柔軟性は強力です。ワークロードの見積もりのオーバーヘッドが不要になり、利用していないリソースに対する料金や処理能力の不足による障害の発生を回避します。適応型リソースの割り当てに関しては、費用の見積もりも予測不可能だという印象を持たれがちです。しかし、Dataflow はそうではありません。予測可能性を高めるために、Dataflow チームはシミュレーションを実施し、Dataflow ジョブの費用を見積もる際に使える便利なメカニズムを提供しました。
このシミュレーションでは、リソースが十分に最適化されると、Dataflow ジョブの費用が直線的に増大することがわかりました。このことを前提とし、小規模な負荷テストでジョブの最適なパフォーマンスが判明すれば、得られるスループット係数によりジョブの総費用を推定できます。一般に、Dataflow ジョブの費用は、次の手順に沿って見積もることをおすすめします。
- 80~90% のリソース使用率を容易に到達できそうな小規模な負荷テストを設計します
- このパイプラインのスループットをスループット係数として使用します
- スループット係数により本番環境のデータサイズを予測し、すべてのデータを処理するために必要なワーカー数を算出します
- Google Cloud 料金計算ツールを使用して、ジョブの費用を見積もります
このメカニズムは、Pub/Sub から BigQuery にデータを移動するストリーミング ジョブや、Cloud Storage から BigQuery にテキストを移動するバッチジョブなど、シンプルなジョブに適しています。この投稿では、スループット係数を直線的に適用して、Dataflow ジョブの総費用の見積りが可能であることを証明するプロセスについてご説明します。
ストリーミング Dataflow ジョブのスループット係数を見つける
ストリーミング Dataflow ジョブのスループット係数を計算するために、Google は最も一般的なユースケースの 1 つを選択しました。このユースケースでは、Google の Pub/Sub からデータを取り込み、Dataflow の Streaming Engine を使用してデータを変換したうえで、新しいデータを BigQuery テーブルに push します。Google は最近のクライアントのユースケースを反映して、シミュレートされた Dataflow ジョブを作成しました。これは、Pub/Sub から 10 のサブスクリプションを JSON ペイロードとして読み取るジョブでした。次に、下の画像で示すように、10 のパイプラインをフラット化し、DynamicDestinations と BigQueryIO を使用して、10 の異なる BigQuery テーブルに push しました。
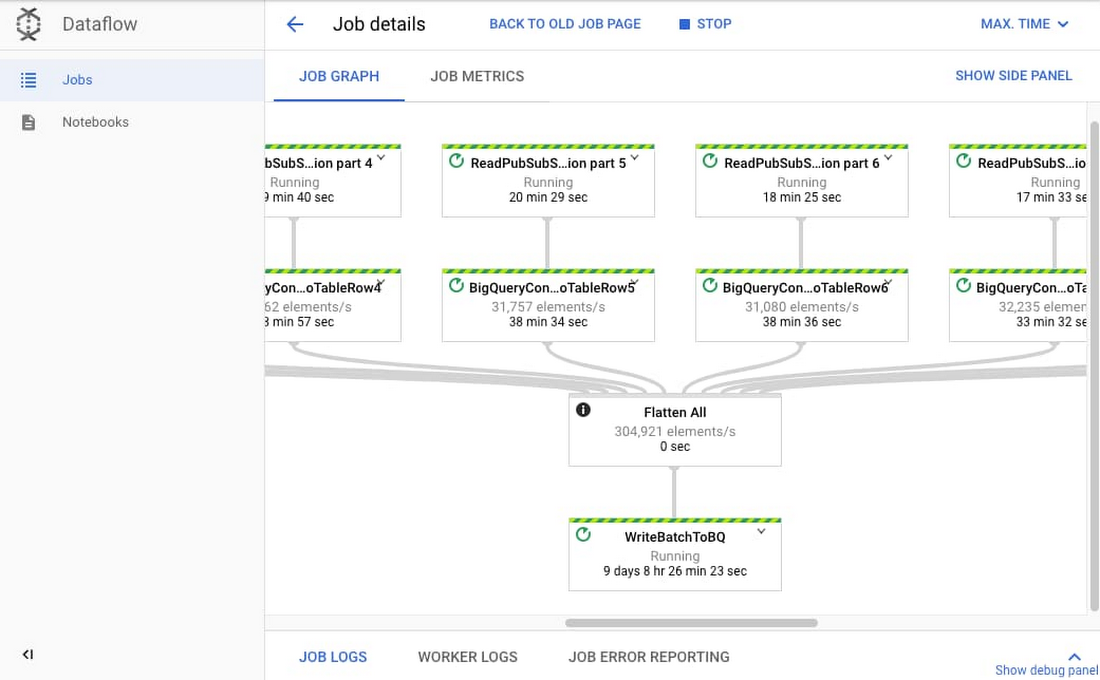
チームはこのジョブに対して 11 の小規模な負荷テストを実施しました。最初のいくつかのテストは、ジョブのスループット係数を計算するために、ジョブの最適なスループットとリソースの割り当てを見つけることに重点を置いていました。
テストでは、Pub/Sub で平均 500 KB のメッセージを生成し、トピックごとにメッセージ数を調整して、各テストで与える総負荷を求めました。3 MB/秒 から 250 MB/秒 までの範囲の負荷をテストしました。下の表は、代表的な 5 つジョブを調整したパラメータとともに示しています。
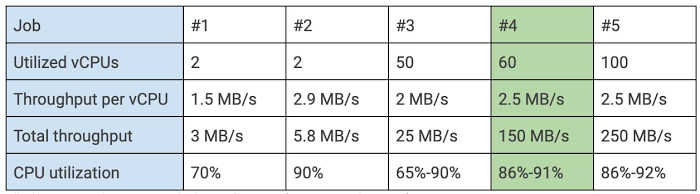
最大のリソース使用率を確保するために、Dataflow インターフェースでバックログ グラフを使用して各テストのバックログをモニタリングしました。パイプラインで小規模な負荷の増加に対応できる十分な容量を確保するために、使用率を 80%~90% の範囲にすることをおすすめします。Google は CPU 使用率 86%~91% を最適な使用率と見なしました。このケースでは、1 つの仮想 CPU(vCPU)につき負荷は 2.5 MB/秒でした。これは上の表のジョブ #4 です。すべてのテストで n1-standard-2 マシンを使用しました。これはストリーミング ジョブに推奨されるタイプのマシンで、2 つの vCPU を搭載しています。残りのテストでは、最適なスループットを使用してリソースが直線的にスケールすることを証明することに重点を置き、それが確認されました。
スループット係数を使用して、ストリーミング ジョブのおおよその総費用を見積もる
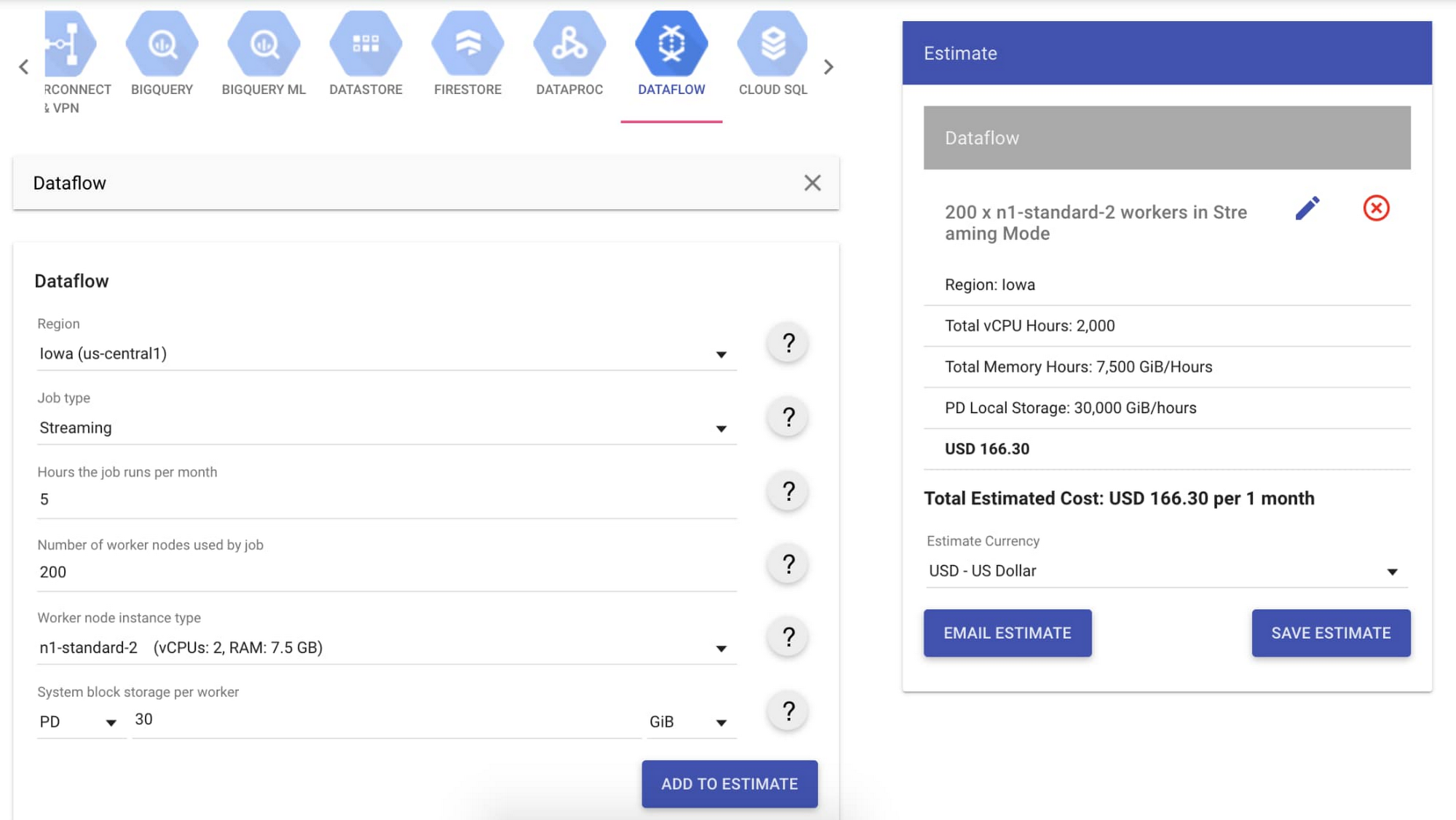
大規模なジョブが 1GB/秒のスループットで、月に 5 時間実行されるとします。スループット係数によって、n1-standard-2 マシンを使用する 1 ワーカーあたりの理想的なスループットは 2.5 MB/秒 であると推定しています。1 GB/秒のスループットをサポートするには、約 400 のワーカー、すなわち 200 台の n1-standard-2 マシンが必要です。
このデータを Google Cloud 料金計算ツールに入力したところ、大規模なジョブの総費用は月額 $166.30 と見積もられました。ワーカー費用に加えて、Streaming Engine を使用する際に処理されるストリーミング データの費用もあります。このデータはギガバイト単位で測定されたボリュームによって料金が設定され、一般的にはワーカー費用の 30%~50% です。今回のユースケースでは多めに 50% と見積もったところ、月額 $83.15 でした。このユースケースの総費用は、月額 $249.45 です。
シンプルな Dataflow のバッチジョブのスループット係数を見つける
Dataflow を使用した最も一般的なバッチ分析のユースケースは、Cloud Storage から BigQuery へのテキストの転送です。小規模な負荷テストでは、Cloud Storage から CSV ファイルを読み込みんで TableRow に変換し、バッチモードで BigQuery に push しました。ソースは 1 GB のファイルに分割されました。10 GB から 1 TB のファイルサイズでテストを実施し、最適なリソース割り当てが直線的にスケールすることを実証することにしました。これらのテストの結果は次のとおりです。
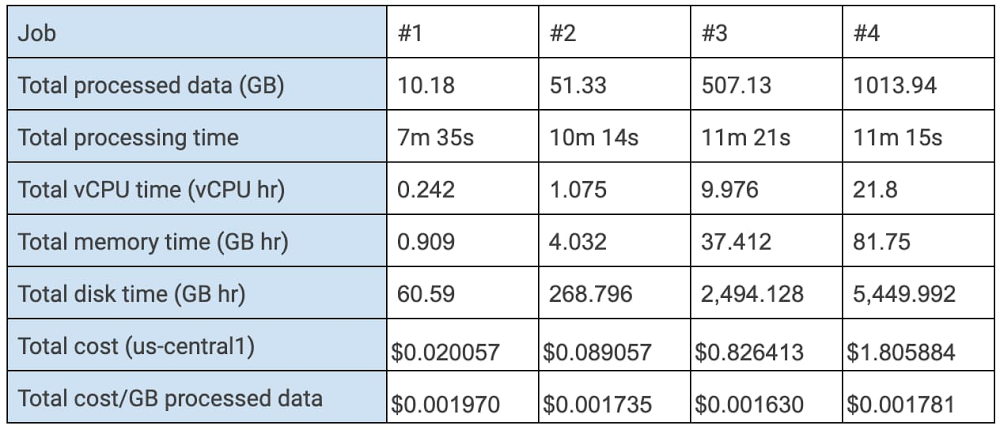
これらのテストにより、バッチ分析が自動スケーリングを効率的に適用することが実証されました。ジョブで最適なリソース使用率が見つかると、同様の処理時間で処理されるデータと同じ単価を使って、そのジョブを完了するために必要なリソースがスケールして割り当てられます。
たとえば、実規模のジョブが 10 TB のデータを処理するとします。ここで、us-central1 のリソースを使用する費用の見積りは、処理されたデータ 1 GB あたり約 $0.0017 です。この場合、実規模のジョブの総費用は約 $18.06 になります。この見積もりは cost(y) = cost(x) × Y ÷ X という公式で求められます。ここで、cost(x) は最適化された小規模な負荷テストの費用、X は小規模な負荷テストで処理されたデータの量、Y は実規模のジョブで処理されるデータの量です。
この例と前の例で鍵を握るのは、小負荷のテストを設計して、最適化されたパイプラインの設定を見つけることです。この設定により、スケールして実規模のジョブで必要となるリソースを見積もる際に使用するスループット係数のパラメータが提供されます。さらに、これらのリソースの見積もりを料金計算ツールに入力して、ジョブの総費用を計算できます。
詳しくは、クラウドの費用を最適化するためのベスト プラクティスを掲載したブログ投稿をご覧ください。
- By Google Cloud Dataflow プロダクト マネージャー Griselda Cuevas、カスタマー エンジニア兼アナリティクス スペシャリスト Wei Hsia



