Predicting the cost of a Dataflow job
Griselda Cuevas
Product Manager
Wei Hsia
Developer Advocate
The value of streaming analytics comes from the insights a business draws from instantaneous data processing, and the timely responses it can implement to adapt its product or service for a better customer experience. “Instantaneous data insights,” however, is a concept that varies with each use case. Some businesses optimize their data analysis for speed, while others optimize for execution cost.
In this post, we’ll offer some tips on estimating the cost of a job in Dataflow, Google Cloud’s fully managed streaming and batch analytics service. Dataflow provides the ability to optimize a streaming analytics job through its serverless approach to resource provisioning and management. It automatically partitions your data and distributes your worker code to Compute Engine instances for parallel processing, optimizes potentially costly operations such as data aggregations, and provides on-the-fly adjustments with features like autoscaling and dynamic work rebalancing.
The flexibility that Dataflow’s adaptive resource allocation offers is powerful; it takes away the overhead of estimating workloads to avoid paying for unutilized resources or causing failures due to the lack of processing capacity. Adaptive resource allocation can give the impression that cost estimation is unpredictable too. But it doesn’t have to be. To help you add predictability, our Dataflow team ran some simulations that provide useful mechanisms you can use when estimating the cost of any of your Dataflow jobs.
The main insight we found from the simulations is that the cost of a Dataflow job increases linearly when sufficient resource optimization is achieved. Under this premise, running small load experiments to find your job’s optimal performance provides you with a throughput factor that you can then use to extrapolate your job’s total cost. At a high level, we recommend following these steps to estimate the cost of your Dataflow jobs:
Design small load tests that help you reach 80% to 90% of resource utilization
Use the throughput of this pipeline as your throughput factor
Extrapolate your throughput factor to your production data size and calculate the number of workers you’ll need to process it all
Use the Google Cloud Pricing Calculator to estimate your job cost
This mechanism works well for simple jobs, such as a streaming job that moves data from Pub/Sub to BigQuery or a batch job that moves text from Cloud Storage to BigQuery. In this post, we will walk you through the process we followed to prove that throughput factors can be linearly applied to estimate total job costs for Dataflow.
Finding the throughput factor for a streaming Dataflow job
To calculate the throughput factor of a streaming Dataflow job, we selected one of the most common use cases: ingesting data from Google’s Pub/Sub, transforming it using Dataflow’s streaming engine, then pushing the new data to BigQuery tables. We created a simulated Dataflow job that mirrored a recent client’s use case, which was a job that read 10 subscriptions from Pub/Sub as a JSON payload. Then, the 10 pipelines were flattened and pushed to 10 different BigQuery tables using dynamic destinations and BigQueryIO, as shown in the image below.
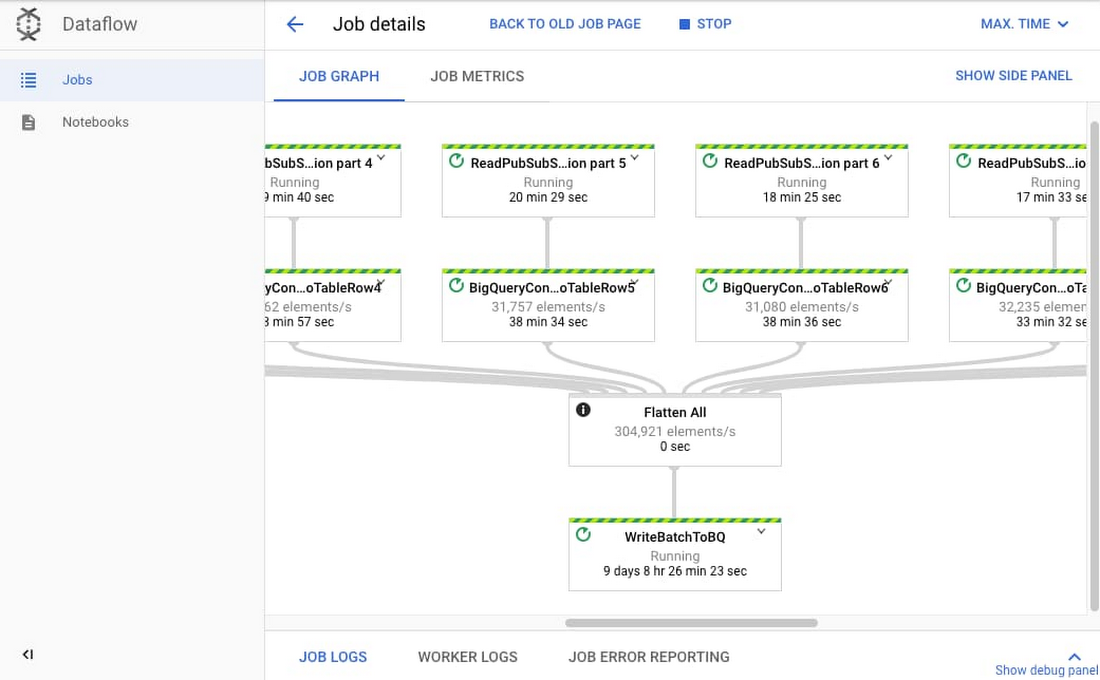
The team ran 11 small load tests for this job. The first few tests were focused on finding the job’s optimal throughput and resource allocation to calculate the job’s throughput factor.
For the tests, we generated messages in Pub/Sub that were 500 KB on average, and we adjusted the number of messages per topic to obtain the total loads to feed each test. We tested a range of loads from 3MB/s to 250MB/s. The table below shows five of the most representative jobs with their adjusted parameters:
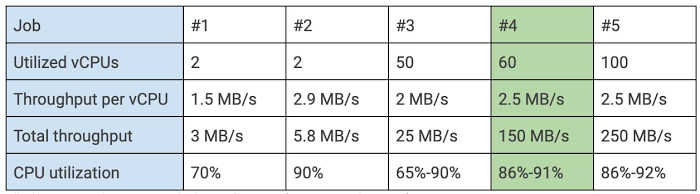
In order to ensure maximum resource utilization, we monitored the backlog of each test using the backlog graph in the Dataflow interface. We recommend targeting an 80% to 90% utilization so that your pipeline has enough capacity to handle small load increases. We considered 86% to 91% of CPU utilization to be our optimal utilization. In this case, it meant a 2.5MB/s per virtual CPU (vCPU) load. This is job #4 on the table above. In all tests, we used n1-standard-2 machines, which are the recommended type for streaming jobs and have two vCPUs. The rest of the tests were focused on proving that resources scale linearly using the optimal throughput, and we confirmed it.
Using the throughput factor to estimate the approximate total cost of a streaming job
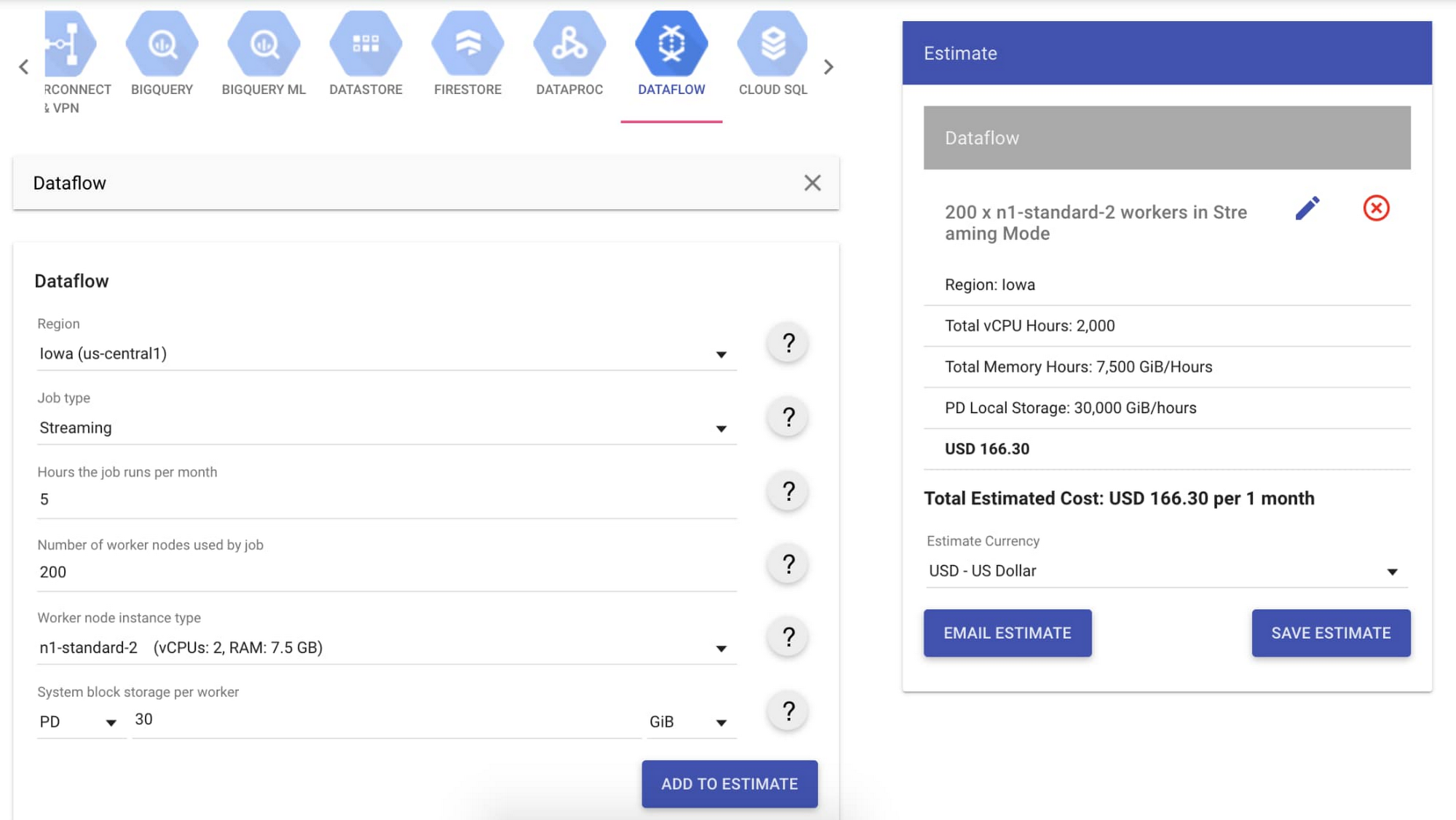
Let’s assume that our full-scale job runs with a throughput of 1GB/s and runs five hours per month. Our throughput factor estimates that 2.5MB/s is the ideal throughput per worker using the n1-standard-2 machines. To support a 1GB/s throughput, we’ll need approximately 400 workers, so 200 n1-standard-2 machines.
We entered this data in the Google Cloud Pricing Calculator and found that the total cost of our full-scale job is estimated at $166.30/month. In addition to worker costs, there is also the cost of streaming data processed when you use the streaming engine. This data is priced by volume measured in gigabytes, and is typically between 30% to 50% of the worker costs. For our use case, we took a conservative approach and estimated 50%, totaling $83.15 per month. The total cost of our use case is $249.45 per month.
Finding the throughput factor for a simple batch Dataflow job
The most common use case in batch analysis using Dataflow is transferring text from Cloud Storage to BigQuery. Our small load experiments read a CSV file from Cloud Storage and transformed it into a TableRow, which was then pushed into BigQuery in batch mode. The source was split into 1 GB files. We ran tests with file sizes from 10GB to 1TB to demonstrate that optimal resource allocation scales linearly. Here are the results of these tests:
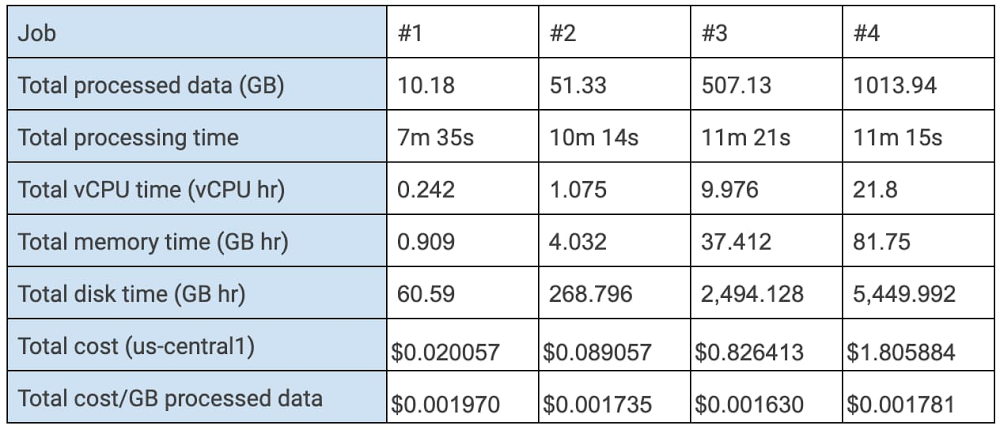
These tests demonstrated that batch analysis applies autoscaling efficiently. Once your job finds an optimized resource utilization, it scales to allocate the resources needed to complete the job with a consistent price per unit of processed data in a similar processing time.
Let’s assume that our real scale job here processes 10TB of data, given that our estimated cost using resources in us-central1 is about $0.0017/GB of processed data. The total cost of our real scale job would be about $18.06. This estimation follows this equation: cost(y) = cost(x) * Y/X, where cost(x) is the cost of your optimized small load test, X is the amount of data processed in your small load test, and Y is the amount of data processed in your real scale job.
The key in this and the previous examples is to design small-load experiments to find your optimized pipeline setup. This setup will give you the parameters for a throughput factor that you can scale to estimate the resources needed to run your real scale job. You can then input these resource estimations in the Pricing Calculator to calculate your total job cost.
Learn more in this blog post with best practices for optimizing your cloud costs.



