BigQuery 増分データの取り込みパイプラインを最適化する
Google Cloud Japan Team
※この投稿は米国時間 2021 年 9 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
データ ウェアハウスを構築する際は、ソースシステムからデータ ウェアハウスに対するデータ取り込み方法を検討することが重要です。テーブルが小さければ通常の方法で完全に再読み込みできます。しかし、テーブルが大きい場合にはテーブルを増分更新する手法が一般的です。この投稿では、データを BigQuery に取り込む際に増分パイプラインの性能を強化する方法について紹介します。
標準の増分データ取り込みパイプラインを設定する
以下の例を使用して一般的な取り込みパイプラインを説明します。このパイプラインでは、データ ウェアハウス テーブルを段階的に更新します。たとえば、ソースシステム内で頻繁に更新されている大きなテーブルから取得したデータを BigQuery に取り込むとして、BigQuery にはステージング エリアとレポートエリア(データセット)があるとします。

BigQuery のレポートエリアは、ソースシステムのテーブルから取り込んだ最新の完全データを格納します。通常は、ソースシステムのテーブルに関する完全スナップショットとしてベーステーブルを作成します。運用例では、BigQuery の一般公開データをソースシステムとして使用し、以下に示すような reporting.base_table を作成しています。事例では、各行は一意のキーによって識別されています。このキーは block_hash と log_index という 2 つの列で構成されます。
一般的にデータ ウェアハウスでは、ビジネス上の意味を持つ datetime 列によって大きなベーステーブルを分割します。たとえば、この列はトランザクション タイムスタンプまたはなんらかのビジネス イベントの発生日時などの意味を持ちます。考え方としては、データ アナリストは一般的にある一定の期間のみ分析する必要があり、完全なデータはたいてい不要であるというものです。事例では、ソースシステムから取得した block_timestamp でベーステーブルを分割しています。
最初のスナップショットを取り込んだら、ソースシステムのテーブルで発生した変更をキャプチャし、その内容に応じてレポート ベース テーブルを更新する必要があります。ここでステージング エリアが登場します。ベーステーブルに統合することになるキャプチャしたデータ変更は、ステージング テーブルが格納しています。たとえば、通常のソースシステムには一連の新しい行と更新済レコードが存在しています。事例では、ステージング データを次のようにシミュレートしています。最初に、新規データを作成してから更新済レコードをシミュレートします。
次に、パイプラインがステージング データをベーステーブルに統合します。2 つのテーブルは一意のキーによって結び付けられ、変更した値を更新もしくは新しい行を挿入します。
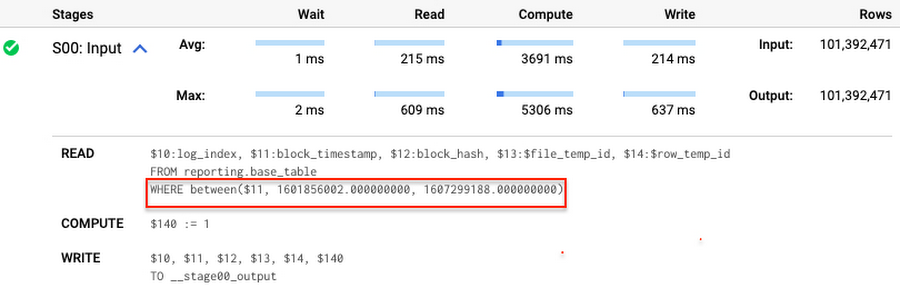
ステージング テーブルが各種パーティションからのキーを格納していることは珍しくありませんが、そのパーティションの数は比較的少なめです。たとえば、ソースシステムでは、ある初期エラーまたは進行中プロセスによって最近追加されたデータが変更されることがありますが、古いレコードが更新されることはまれなため、保留されます。ただし、前述の MERGE 実行時には、BigQuery はベーステーブルに存在するすべてのパーティションをスキャンして 161 GB 分のデータを処理します。block_timestamp に追加の結合条件を入力する場合があります。
ですが、条件 T.block_timestamp = S.block_timestamp は動的述語であり、BigQuery はそのような述語を、あるテーブルから別の MERGE に自動で push することはありません。そのため、BigQuery は引き続きベーステーブルのすべてのパーティションをスキャンします。
スキャンするデータを減らすことで MERGE の効率を上げることはできるでしょうか?答えはイエスです。
MERGE に関するドキュメントで説明されているように、プルーニング条件はサブクエリ フィルタまたは merge_condition フィルタや search_condition フィルタ内に存在する場合があります。この投稿では、最初の 2 つについて活用方法を紹介します。動的述語を静的述語に変換するというのが基本となる考え方です。
取り込みパイプラインの強化方法
最初の手順では、MERGE 実行中に更新される一連のパーティションを計算してから変数に格納します。前述したとおり、データ取り込みパイプラインでは、ステージング テーブルは一般的に小さく、そのため計算コストも比較的低く抑えられます。
既存の ETL/ELT パイプラインを基に、上に記載したコードをそのままパイプラインに追加するか、もしくは date_min と data_max を既存の変換手順の一部として計算することができます。別の方法としては、次の取り込みデータバッチのキャプチャ中に date_min と data_max をソースシステム側で計算することもできます。
date_min と date_max の計算後、それらの値を静的述語として MERGE ステートメントに渡します。事前に計算された date_min と data_max を基に MERGE を強化してベーステーブルのパーティションをプルーニングする方法は複数存在しています。
最初の MERGE ステートメントがサブクエリを使用している場合、そのクエリに対して新しいフィルタを組み込めます。
静的フィルタをステージング テーブルに追加して T.block_timestamp = S.block_timestamp を維持し、BigQuery に渡すと、BigQuery はそのフィルタをベーステーブルに push できます。この MERGE では、最初の 161 GB と異なり、41 GB 分のデータを処理します。クエリプランでは、BigQuery がパーティション フィルタをステージング テーブルからベーステーブルに push していることが確認できます。
プルーニング条件がサブクエリから大きなパーティション分割テーブルもしくはクラスタ化テーブルに push された場合、この種の最適化は MERGE に特有のものではなく、他の種類のクエリに対しても動作します。次に例を示します。
また、クエリプランを確認して、BigQuery がパーティション フィルタをあるテーブルから他のテーブルに push したかを検証できます。
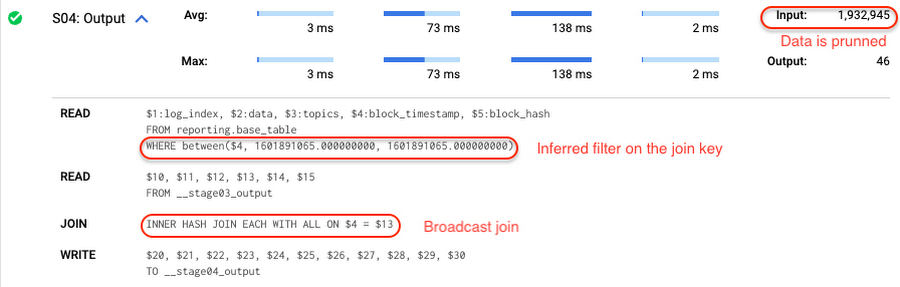
さらに、SELECT ステートメントに関して、BigQuery は結合列のフィルタ述語を自動で推測し、クエリが次の基準を満たす場合には、あるテーブルから別のテーブルへ push します。
対象テーブルはクラスタ化またはパーティション分割されている必要があります。
別のテーブルは、ブロードキャスト結合に適切なサイズになる必要があります(例: 全フィルタ適用後のサイズ)。言い換えると、結果セットは 100 MB 以下の比較的小さいものでなければいけません。
運用例では、reporting.base_table が block_timestamp によって分割されています。staging.load_delta で選択型フィルタを定義して 2 つのテーブルを結合した場合、結合キー上の推測したフィルタが、対象テーブルに push されたことを確認できます。
この種の最適化を開始する際に、キーのパーティション分割またはクラスタ化によってテーブルを結合する必要はありません。ですが、その場合の対象テーブルに対するプルーニング効果は小さくなります。
さて、話をパイプラインの最適化に戻しましょう。別の MERGE 強化方法としては、ベーステーブルの静的述語を追加して merge_condition フィルタを変更する方法があります。
ここでは、BigQuery で増分取り込みパイプラインを強化する手順についてまとめています。始めに、小さなステージング テーブルを基に一連の更新済パーティションを計算します。次に、BigQuery がベーステーブルのデータをプルーニングするように、MERGE ステートメントを少しだけ修正します。
すべての強化された MERGE ステートメントが 41 GB 分のデータをスキャンします。src_range 変数の設定に 115 MB が使用されます。スキャンしたデータを最初の 161 GB 分のスキャンと比較します。なお、src_range が ETL/ELT 内で行われる既存の変換に組み込まれていると仮定した場合、パイプラインで活用してパフォーマンスを効率よく向上できます。
この投稿では、動的述語を静的述語に変換して BigQuery にデータをプルーニングさせることで、データ取り込みパイプラインを強化する方法について説明しました。BigQuery DML 調整について、こちらから詳細をご確認ください。
本コンテンツに関する事例作成の支援および貴重なフィードバックを提供してくれた Daniel De Leo の協力に感謝します。
-戦略クラウド エンジニア Anna Epishova


