Optimizing your BigQuery incremental data ingestion pipelines
Anna Epishova
Strategic Cloud Engineer
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialWhen you build a data warehouse, the important question is how to ingest data from the source system to the data warehouse. If the table is small you can fully reload a table on a regular basis, however, if the table is large a common technique is to perform incremental table updates. This post demonstrates how you can enhance incremental pipeline performance when you ingest data into BigQuery.
Setting up a standard incremental data ingestion pipeline
We will use the below example to illustrate a common ingestion pipeline that incrementally updates a data warehouse table. Let’s say that you ingest data into BigQuery from a large and frequently updated table in the source system, and you have Staging and Reporting areas (datasets) in BigQuery.

The Reporting area in BigQuery stores the most recent, full data that has been ingested from the source system tables. Usually you create the base table as a full snapshot of the source system table. In our running example, we use BigQuery public data as the source system and create reporting.base_table as shown below. In our example each row is identified by a unique key which consists of two columns: block_hash and log_index.
In data warehouses it is common to partition a large base table by a datetime column that has a business meaning. For example, it may be a transaction timestamp, or datetime when some business event happened, etc. The idea is that data analysts who use the data warehouse usually need to analyze only some range of dates and rarely need the full data. In our example, we partition the base table by block_timestamp which comes from the source system.
After ingesting the initial snapshot you need to capture changes that happen in the source system table and update the reporting base table accordingly. This is when the Staging area comes into the picture. The staging table will contain captured data changes that you will merge into the base table. Let’s say that in our source system on a regular basis we have a set of new rows and also some updated records. In our example we mock the staging data as follows: first, we create new data, than we mock the updated records:
Next, the pipeline merges the staging data into the base table. It joins two tables by unique key and than updates the changed value or inserts a new row
It is often the case that the staging table contains keys from various partitions but the number of those partitions are relatively small. It holds, for instance, because in the source system the recently added data may get changed due to some initial errors or ongoing processes but older records are rarely updated. However, when the above MERGE gets executed, BigQuery scans all partitions in the base table and processes 161 GB of data. You might add additional join condition on block_timestamp:
But BigQuery would still scan all partitions in the base table because condition T.block_timestamp = S.block_timestamp is a dynamic predicate and BigQuery doesn’t automatically push such predicates down from one table to another in MERGE.
Can you improve the MERGE efficiency by making it scan less data? The answer is Yes.
As described in the MERGE documentation, pruning conditions may be located in a subquery filter, a merge_condition filter, or a search_condition filter. In this post we show how you can leverage the first two. The main idea is to turn a dynamic predicate into a static predicate.
Steps to enhance your ingestion pipeline
The initial step is to compute the range of partitions that will be updated during the MERGE and store it in a variable. As was mentioned above, in data ingestion pipelines, staging tables are usually small so the cost of the computation is relatively low.
Based on your existing ETL/ELT pipeline, you can add the above code as-is to your pipeline or you can compute date_min, data_max as part of some already existing transformation step. Alternatively, date_min, data_max can be computed on the Source System side while capturing the next ingestion data batch.
After computing date_min, date_max you pass those values to the MERGE statement as static predicates. There are several ways to enhance the MERGE and prune partitions in the base table based on precomputed date_min, data_max.
If your initial MERGE statement uses a subquery, you can incorporate a new filter into it:
Note that you add the static filter to the staging table and keep T.block_timestamp = S.block_timestamp to convey to BigQuery that it can push that filter to the base table. This MERGE processes 41 GB of data in contrast to the initial 161 GB. You can see in the query plan that BigQuery pushes the partition filter from the staging table to the base table:
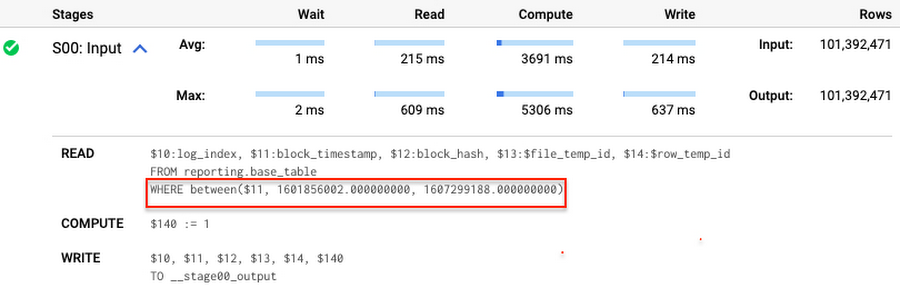
This type of optimization, when a pruning condition is pushed from a subquery to a large partitioned or clustered table, is not unique for MERGE. It also works for other types of queries. For instance:
And you can check the query plan to verify that BigQuery pushed down the partition filter from one table to another.
Moreover, for SELECT statements, BigQuery can automatically infer a filter predicate on a join column and push it down from one table to another if your query meets the following criteria:
- The target table must be clustered or partitioned.
- The result size of the other table, i.e. after applying all filters, must qualify for broadcast join. Namly, the result set must be relatively small, less than ~100MB.
In our running example, reporting.base_table is partitioned by block_timestamp. If you define a selective filter on staging.load_delta and join two tables, you can see an inferred filter on the join key pushed to the target table
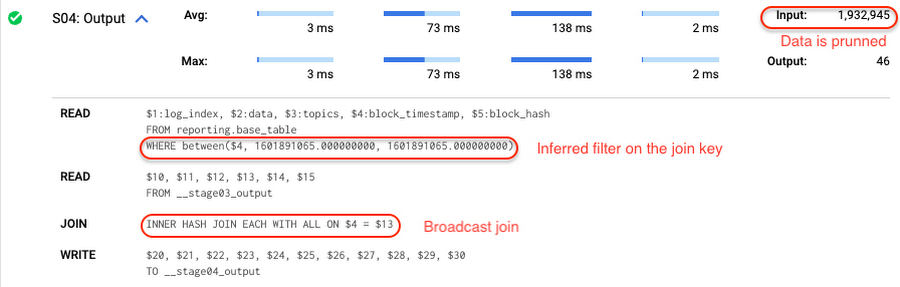
There is no requirement to join tables by partitioning or clustering key to kick off this type of optimization. However, in this case the pruning effect on the target table would be less significant.
But let us get back to the pipeline optimizations. Another way to enhance MERGE is to modify the merge_condition filter by adding static predicate on the base table:
To summarize, here are the steps that you can perform to enhance incremental ingestion pipelines in BigQuery. First you compute the range of updated partitions based on the small staging table. Next, you tweak the MERGE statement a bit to let BigQuery know to prune data in the base table.
All the enhanced MERGE statements scanned 41 GB of data, and setting up the src_range variable took 115 MB. Compare it with the initial 161 GB scan. Moreover, given that computing src_range may be incorporated into some existing transformation in your ETL/ELT, it results in a good performance improvement which you can leverage in your pipelines.
In this post we described how to enhance data ingestion pipelines by turning dynamic filter predicates into static predicates and letting BiQuery prune data for us. You can find more tips on BigQuery DML tuning here.
Special thanks to Daniel De Leo, who helped with examples and provided valuable feedback on this content.


