VM マシンタイプによる Dataproc 費用の最適化
Google Cloud Japan Team
※この投稿は米国時間 2020 年 4 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
Dataproc は、Apache Spark クラスタ、Apache Presto クラスタ、Apache Hadoop クラスタなどのマネージド オープンソースを簡単かつコスト効率よく実行できるようにする、高速で使いやすいフルマネージド クラウド サービスです。現在、数多くの企業がビッグデータのワークロードをクラウドに移行し、秒単位の料金設定、アイドル状態のクラスタの削除、自動スケーリングなどにより、コスト面で成果を上げていると伺っています。しかし、コンピューティング、ストレージ、ネットワークのコストが、ワークロード全体の処理コストを押し上げてしまう可能性があります。コンピューティング向けに適切なクラウド仮想マシン(VM)を選択することは、予算を効率的に運用するうえで欠かせません。
こうしたビッグデータのクラスタをクラウドに移動すると、コスト効率上のさまざまなメリットがもたらされます。また、各クラスタを Google Cloud にデプロイする際にどのような選択をするかも、コスト節約につながる可能性があります。Dataproc クラスタを構成する際は、そのプロセスの一環として利用可能な Google Cloud VM から VM を選択します。VM タイプを選択する際に考慮すべき要素として、ワークロードとその実行時間があります。Google Cloud で選択できる各種 VM の概要は次のとおりです。
●汎用マシンタイプ(N1)は、幅広いワークロードに対して最高のコスト パフォーマンスを実現します。ワークロードに最適なマシンタイプがわからない場合は、汎用マシンタイプを使用することをおすすめします。
●効率的な汎用マシンタイプ(E2)は、最大 16 個の vCPU を必要とするもののローカル SSD や GPU を必要としない小規模から中規模のワークロードに適しています。E2 マシンタイプでは継続利用割引はご利用いただけませんが、オンデマンド料金と確約利用料金は一貫して低価格です。
●メモリ最適化マシンタイプ(M2)はメモリ対 vCPU 比が高い、メモリを集中的に使用する必要があるタスクに適しています。たとえば、SAP HANA やビジネス ウェアハウジング(BW)のワークロード、ゲノミクス解析、SQL 分析サービスなど、インメモリ データベースやインメモリ アナリティクスに最適です。
●コンピューティング最適化マシンタイプ(C2)は、機械学習アルゴリズムなどの演算中心のワークロードに最適で、Compute Engine 上で 1 コアあたりのパフォーマンスが最も高くなります。
適切な Dataproc ワークロードを実現できるように、費用を低く維持する方法として E2 VM が登場しました。E2 VM は同等の N1 VM と処理特性が似ていますが、最大 31% も低価格なため、Google Cloud の VM で総所有コスト(TCO)が最も低く、信頼性が高く持続的なパフォーマンスと柔軟な構成を実現できます。E2 VM には、継続利用割引が適用されません。また、ローカル SSD、単一テナントノード、ネストされた仮想化、プロセッサ タイプの選択もサポートされていません。
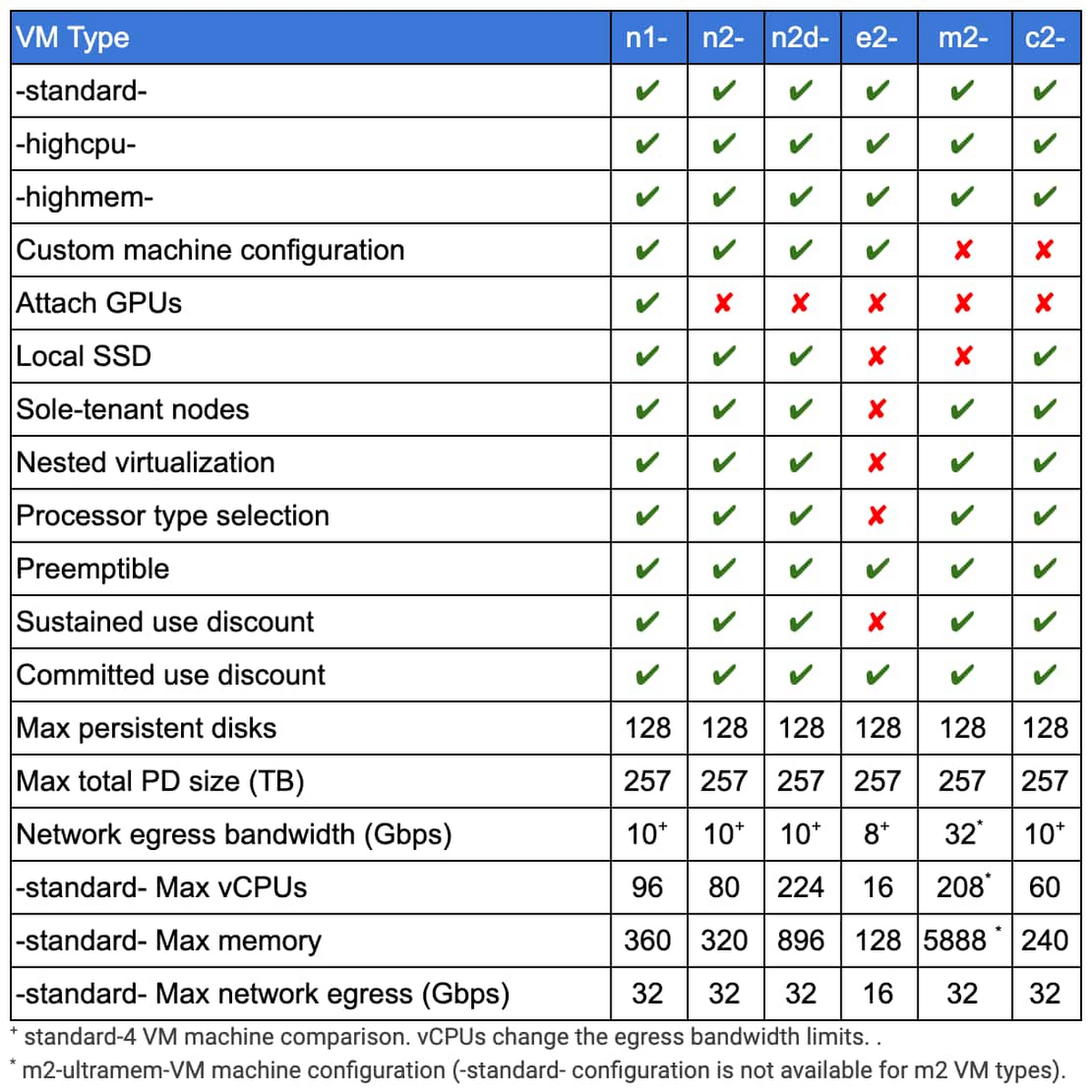
次の表は、Dataproc でサポートされている各種 VM タイプをまとめたものです。
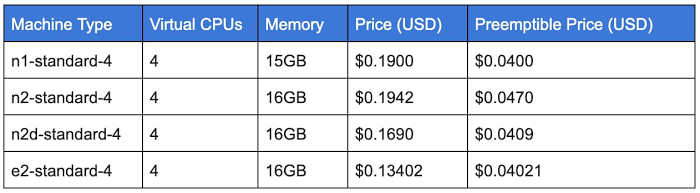
次の表は、この記事の公開時点で入手可能なさまざまな standard-4 構成の費用をまとめたものです。最新の VM 料金情報をご確認ください。e2-standard-4 の料金は n1-standard-4 構成よりも約 30% 安くなっています。
E2 VM により Dataproc クラスタのコンピューティング コストが削減されるため、全体的な TCO も削減されます。確約利用割引もコストの節約になります。E2 VM の利用による Dataproc TCO の節約は、ワークロードとクラスタの使用パターンによって異なります。VM の選択に加えて、ビッグデータの費用を確実に抑える方法が他にもいくつかあります。
クラスタの費用を最適化するためのヒント
クラスタのオペレーション料金を管理するにあたり、よく使われる手法や機能をいくつかご紹介します。
●VM の料金
○確約利用割引: 予測可能なワークロードでは確約利用による価格割引のメリットが得られます。
●コンピューティング費用
○自動スケーリング: 使用率に基づいてスケールアップやスケールダウンが実行されるように Dataproc クラスタを構成できます。
○ジョブ限定クラスタ: Dataproc クラスタは 90 秒で開始できます。SLA クリティカルではないワークロードに対しては、そのワークフローやジョブに固有のクラスタを開始して使用することにより、費用の発生をクラスタが実行されている時間に絞り込み、金額を最小限に抑えることができます。
○プリエンプティブル VM: SLA クリティカルではないワークロードは、プリエンプティブル VM で実行することによって費用をさらに節約できます。
●コンピューティング時間
○データの再編成: クエリのアクセス パターンを把握し、アクセス パターンに合わせてデータストアを最適化すると、クエリ時間が短縮され、コンピューティング コストが削減されます。
○集計されたデータと未加工データの比較: また、頻繁にアクセスされるデータを中間的に集計すると、スキャンされるデータの量が減り、クエリのパフォーマンスとコンピューティング コストが改善されます。
Dataproc クラスタ向けに E2 VM を選択する方法
クラスタ作成時に master-machine-type と worker-machine-type を任意の E2 VM マシン名に更新し、Dataproc クラスタ構成を変更します。E2 VM マシンタイプを選択するには、gcloud コマンド、REST API、Google Console、言語固有の API(Go、Java、Node.js、Python)のいずれかの Dataproc 管理インターフェースを使用します。
具体的な数字はお客様ごとに異なりますが、E2 VM を使用すると、この VM による制限が許容可能である限り、コスト節約を期待できます。本番環境に変更を加える前に、E2 VM を使用して Dataproc クラスタのワークロードを確認し、パフォーマンスとコストの特性について理解を深めることを強くおすすめします。
Google は最高のコスト パフォーマンスをお届けする方法を常に模索しています。これからも、Dataproc クラスタのカスタマイズと最適化を実現する機能を追加してまいります。Dataproc の最新情報について詳しくは、Dataproc のページをご覧ください。
- Google Cloud プロダクト マネージャー Susheel Kaushik
