BigQuery スロットの使用状況を分析する実践的な手法
Google Cloud Japan Team
※この投稿は米国時間 2020 年 2 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
Google BigQuery は、エンタープライズ データ ウェアハウスのワークロード向けのフルマネージド サーバーレス ソリューションです。操作はとても簡単で、バッチまたはストリーミングでデータをアップロードし、クエリの実行を開始するだけです。基盤となるシステムがシームレスに機能し、多様なジョブの完了に必要なインフラストラクチャ リソースを提供します。
まるでマジックのようですね。特に、バックグラウンドには大規模な分散システムがあり、多数の並列タスクが、選択した Google Cloud リージョンの複数の可用性ゾーンに分散されて、さまざまなマイクロサービスによって実行されていることを考えるとそう思います(BigQuery のテクノロジーについて詳しくはこちらをご覧ください)。
しかし、内部の演算能力をもっと可視化したい場合はどうすればよいでしょうか。このブログ投稿では、リソースの使用状況をモニタリングし、分析するために現在ご利用いただけるすべてのオプションについて詳しく説明します。また、新たに利用可能になった、INFORMATION_SCHEMA ビューの拡張機能についてもご紹介します。これは基盤となるデータに実際にアクセスできるようにするもので、現在ベータ版です。まず、システムの負荷を把握するために使用する演算能力の単位について見てみましょう。
BigQuery の演算能力の単位: スロット
クエリの実行ごとに、複数のバックエンド タスクを完了する必要があります(テーブルからのデータの読み取り、不要になったデータの整理、結果集計の実行など)。各タスクはアドホックのマイクロサービスで実行され、完了するためには適切な演算能力が必要です。スロットは、その能力を測定するための演算能力の単位です。BigQuery エンジンで単一のクエリを実行するために必要なスロット量が動的に特定され、タスクを実行するために必要とされる適切な演算能力がバックグラウンド プロセスで透過的に割り当てられます。
そのため、スロット使用状況をモニタリングして分析する方法を理解しておくことが重要になります。そうすることで、技術チームはボトルネックがあるかどうかを把握し、ビジネスに最適な料金モデル(オンデマンドまたは定額)を選択できるようになります。
ここでは、スロット使用状況を可視化するための 3 通りの方法を詳しく説明し、それらを使い始める方法を見ていきます。
システム テーブルを使用したスロット使用状況の分析
Stackdriver を使用したリアルタイムの使用状況モニタリング
BigQuery 監査ログを使用したスロット使用状況の分析
システム テーブルを使用したスロット使用状況の分析
Google は、INFORMATION_SCHEMA ビューの拡張バージョンを発表しました。これには BigQuery ジョブに関するリアルタイムの情報が含まれます。
これは INFORMATION_SCHEMA と呼ばれる一連の内部ビューの一部で、データセット、ルーティン、テーブル、ビューに関連する有用な情報の抽出に活用できます。単純なクエリで一連のメタデータにアクセスできるため、現在のデータ ウェアハウス定義(テーブルリスト、フィールドの説明など)を簡単に分析できます。
この新しい拡張バージョンでは、必要なすべてのジョブ情報がクエリだけで得られるため、スロット使用状況(および他のリソース)を分析しやすくなります。
次に例を示します。単一のプロジェクト内での、ユーザーによって分割されたスロットの先月の日々の消費状況を(他の情報とともに)把握したいとします。これを記述するクエリは本当に簡単です。
ここで重要な要素は total_slot_ms フィールドで、クエリで使用されたスロットの合計量がミリ秒単位で含まれています。これはクエリの実行時間全体でクエリによって消費されたスロットの合計量を、ミリ秒単位で考慮したものです。クエリの平均スロット使用量を計算する場合は、この値をクエリの実行時間(ミリ秒)で割ります。方法としては、creationTime フィールドからendTime フィールドの値を減算します。たとえば、20,000 の totalSlotM を使用した 10 秒のクエリがある場合、平均スロット使用量は 2(20.000/10*1000)になります。
ビューの列定義を掘り下げていくと、多くの情報が見つかり、さまざまな種類の分析を実装する際に活用できます。たとえば、組織内で最も費用のかかるクエリを簡単に計算する、クエリを大量に発行しているユーザーを見つける、どのプロジェクトが最も費用がかかっているかを把握する、単一のクエリのクエリステージを調査して詳細な分析を実行する、などが可能です。詳細はジョブの完了から 1 秒以内に確認できるため、その情報を使用して独自のトリガーを実装できます(たとえば、読み込みジョブが正常に完了したら、本番用にデータのクリーニングと変換を行うクエリを開始するなど)。
通常、データは数秒で利用可能になり、ジョブデータは 180 日間保持されます。履歴を残すため、または後で分析を実行するためにデータのバックアップを保持する場合は、スケジュールされたクエリを使用すると、データがアドホック(パーティション分割)テーブルに自動的にエクスポートされます。また、リアルタイムのスロット使用状況は、クエリの実行に伴って変動することに注意してください。さらに詳しく調べるには、スロット消費量を可視化するオープンソース ソリューションをお試しください。
Stackdriver を使用したリアルタイムのスロット使用状況のモニタリング
別の方法として、プロジェクトのスロット使用状況をリアルタイムでモニタリングする場合は、Stackdriver が最適です。
ネイティブのスロット使用状況グラフにより、プロジェクトのスロット使用状況の概要を即座に把握
複数の利用可能な指標(割り当てられたスロット、ジョブタイプごとに割り当てられたスロットなど)を使用したアドホック グラフの作成
特定のイベント発生時(使用可能なスロット数が特定のしきい値を下回った状態が 5 分以上続いた場合など)に通知を受け取るアドホック アラートの作成
BigQuery のモニタリングの実装に関するこちらのガイドをご確認ください
https://cloud.google.com/bigquery/docs/monitoring
BigQuery 監査ログを使用したスロット使用状況の分析
基盤となる情報にアクセスするもう 1 つの方法は、BigQuery 監査ログを調べることです。このログには、スロット使用状況などの多数の情報が含まれています。
ログのデータをクエリするには次の 2 つの方法があります。
Stackdriver Logging: 関心のある正確な値をすばやく検索したい場合
BigQuery: より詳細な分析を実行したい場合
Stackdriver Logging
Stackdriver Logging のページから、以下の操作を行います。
BigQuery をリソースとして選択: resource_type=”bigquery_project”
必要な期間を選択(過去 1 時間や上限なしなど)
以下を含むものを検索
protoPayload.metadata.jobChange.job.jobConfig.type=”QUERY”
protoPayload.metadata.jobChange.job.jobStatus.jobState=”DONE”
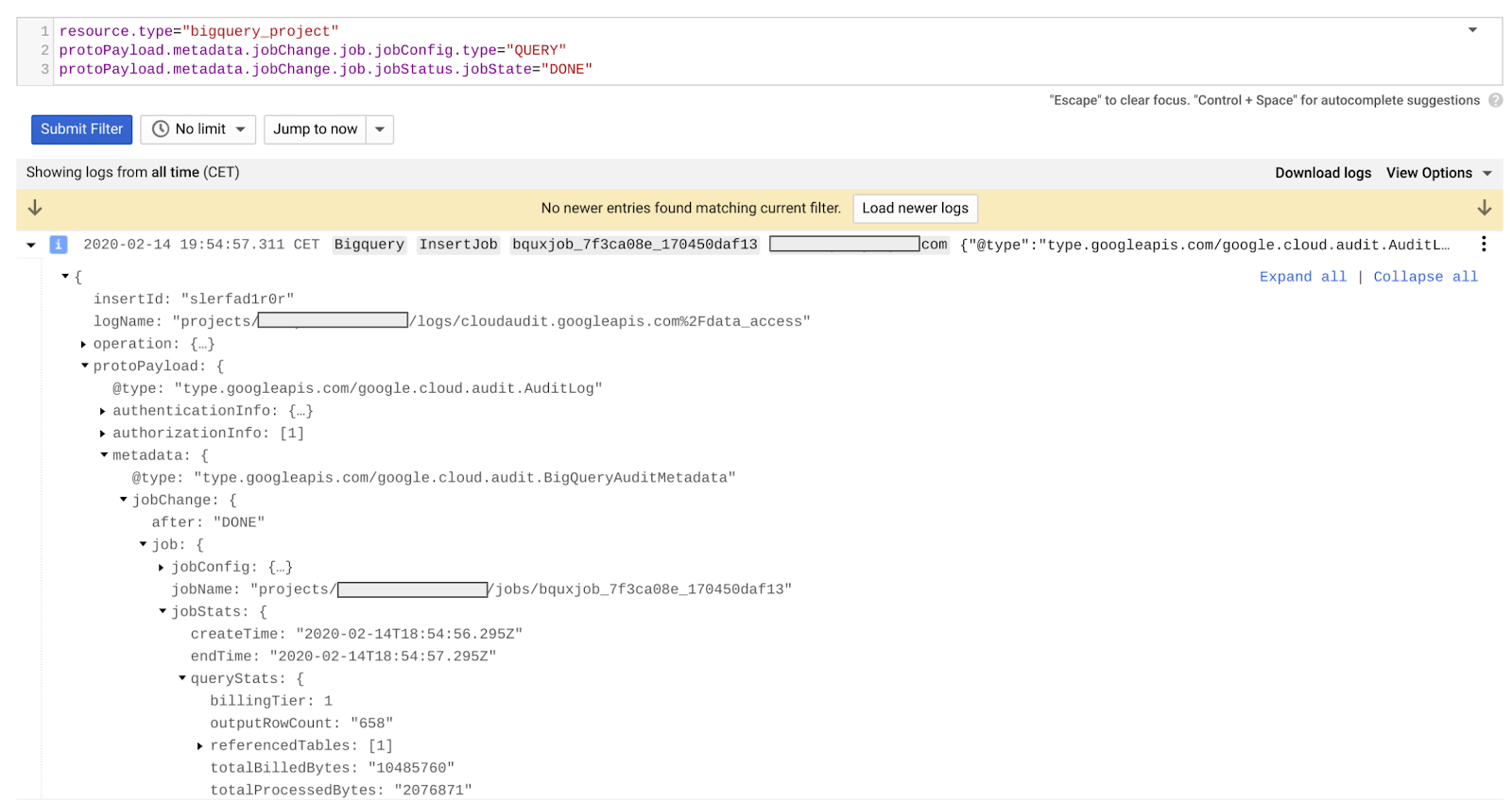
目的のクエリが見つかったら、そのペイロードを展開して、関心のあるエントリを探します。たとえば、$.jobChange.job.jobStats.totalSlotMs は、前述したスロットの合計量(ミリ秒)を表します。
より詳細な分析を実行するには、BigQuery を使用します。まず、シンクを作成して Stackdriver Logging から BigQuery にデータを転送します。これで、より複雑なクエリを実行してプロジェクトのスロット使用状況を分析できるようになります。たとえば、上記と同じクエリを使用した場合、結果は次のようになります。
ぜひこれらのツールを活用して、カスタマイズしたソリューションを構築してみてください。スロットの編成について詳しくはこちらをご覧ください。次のステップでは、データポータルを使用してカスタム ダッシュボードを生成し、組織内で共有する方法について説明します。
- By データ分析担当カスタマー エンジニアリング マネージャー Marco Tranquillin



