生成 AI や Dataflow とともにストリーミング分析を活用して実用的な分析情報を得る
Google Cloud Japan Team
※この投稿は米国時間 2024 年 2 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
近年、運用上の異常を特定するための予測メンテナンスや、リアルタイムでエクスペリエンスを最適化してプレーヤー主体のゲームを作成するオンライン ゲームなど、さまざまなユースケースでストリーミング分析の導入が急増しています。同時に、テキストを生成して理解できる生成 AI と大規模言語モデル(LLM)の台頭により、それら両方を組み合わせて革新的なソリューションを作成する新たな方法が模索されるようになりました。
このブログ投稿では、Dataflow を使用して簡単かつスケーラブルにリアルタイムの LLM の分析情報を取得する方法を紹介します。このソリューションはゲームルームのチャットに適用されますが、リアルタイム コミュニケーションが普及している他のあらゆる分野において、カスタマー サポートのチャット ログ、ソーシャル メディアの投稿、商品レビューなど、さまざまな種類のデータに関する分析情報を得るために使用することもできます。
ゲームチャットは情報の宝庫
チャット メッセージからリアルタイムの分析情報を得ようとする企業を考えてみましょう。多くの企業にとって重要な課題は、ユーザーが使う専門用語や略語の進化を把握することです。これはゲーム業界では特に重要となります。たとえば、「gg」は「いい試合だった」、「g2g」は「そろそろ行かなくちゃ」を意味します。こうした言葉の変化に対し、キーワードを事前に定義することなく柔軟に対応できるのが理想的なソリューションと言えるでしょう。
このソリューションの開発にあたっては、Kaggle が提供する、Dota 2 をプレイしながらチャットしているゲーマー同士の短いテキスト メッセージでの自由な会話の匿名データを調べました。ゲーマー間の会話は、Google にとって情報の宝庫にほかなりませんでした。ゲーマー同士のチャットから、接続や遅延に関する問題が発生していることを迅速に検出することで、優れた Quality of Service(QoS)を確保する機会を見いだしました。同様に、ゲーマーの間でよく話題になるトークンやゲーム内武器などの不足アイテムについての情報も、ゲーム体験とその費用対効果を向上させるために活用できます。
さらに、構築したソリューションは、それがそのようなものであっても素早く簡単に実装できる必要がありました。
ソリューション コンポーネント
Google が構築したソリューションには、業界トップレベルの Google Cloud データ分析とストリーミング ツールに加え、オープンソースのゲームデータと LLM が使用されています。
- BigQuery は元データを保存し、検出アラートを保持します。
- Pub/Sub(Google Cloud サーバーレス メッセージバス)は、ストリーミング チャット メッセージと Dataflow パイプラインを分離するために使用します。
- Dataflow(分散データ処理パイプラインを構築して実行するための Google Cloud マネージド サービス)は、シンプルで使いやすいインターフェースの Beam RunInference 変換を利用して、ローカルおよびリモートの推論を行います。
- Dota 2 ゲームチャット データセットは、Kaggle -G ゲームチャットの元データから取得します。
- Google / Flan-T5 は、プロンプトに基づく検出に使用される LLM モデルで、Hugging Face でホストされます。
ソリューション コンポーネントを決めたら、特定のビジネス ユースケースに適したプロンプトを選ぶ必要がありました。今回は、ゲームチャットのレイテンシ検出に決めました。
接続、遅延、レイテンシ、ラグなどのキーワードを検索し、ゲームデータを分析しました。
例:
以下のゲーム ID が表示されました。
ここでは、ラグやサーバーに関するさまざまな問題が発見されました。
SQL クエリの反復処理を数回行ったあと、真陽性が検出アラートを生成するくらいの高さにしながら、特定のキーワードを指定せずに遅延の問題を十分に特定できるように、プロンプトをどうにか調整しました。
"Answer by [Yes|No] : does the following text, extracted from gaming chat room, can indicate a connection or delay issue : "
次の課題は、2 つの主要機能をシームレスに統合する Dataflow パイプラインを作成することでした。
-
動的な検出プロンプト: パイプラインが稼働している間、ユーザーがコードを記述することなくさまざまなユースケースに合わせて検出プロンプトを調整できるようにする必要があります。
-
シームレスなモデル更新: コードを記述しなくても、継続的な稼働時間を確保しながら、パイプラインのオペレーションを中断することなく、より適切にトレーニングされたモデルに切り替えられる方法が必要でした。
これを実現するため、Beam RunInference 変換を使用することにしました。
RunInference には多くのメリットがあります。
-
データの前処理と後処理は RunInference 関数内にカプセル化され、プロセスの別個の段階として扱われます。このことが重要な理由は、RunInference が各段階に関連するエラーを効果的に管理し、個別の PCollection に自動的に抽出することで、以下のコードサンプルのようにシームレスな処理が実現するからです。
-
RunInference の自動モデル更新メカニズムは、ウォッチ ファイル パターンです。これにより、パイプラインを停止したり再起動したりしなくても、モデルを更新して新しいバージョンを読み込むことができます。
必要なのは数行のコードのみです。
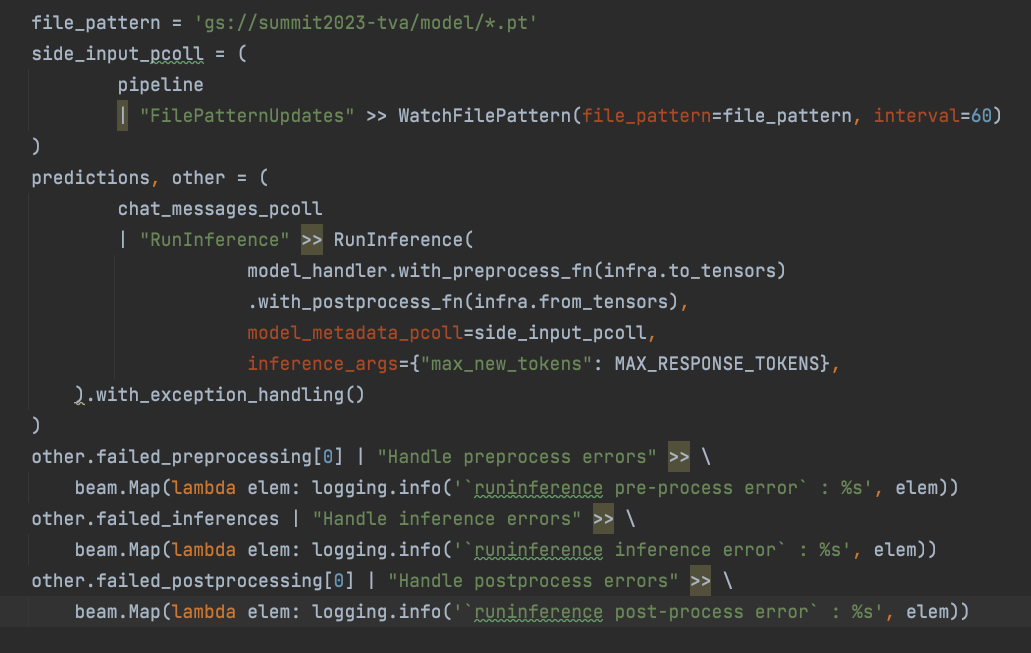
RunInference が使用する「ModelHandler」オブジェクトは、基盤となるモデルをラップし、使用されるモデルを処理する構成可能な方法を提供します。ModelHandler にはさまざまな種類があり、入力を含むフレームワークとデータ構造の種類によって選ぶものが異なります。このことから、ModelHandler は ML パイプラインの構築を簡素化するための強力なツールとなります。
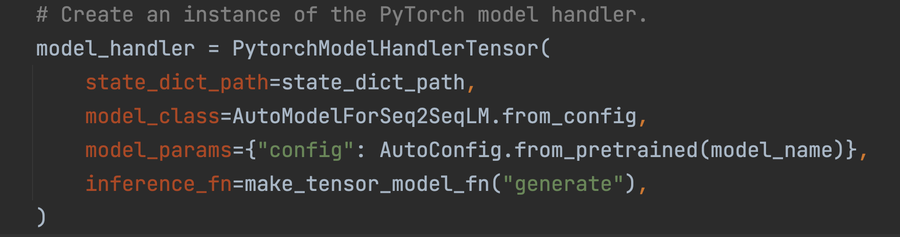
ソリューション アーキテクチャ
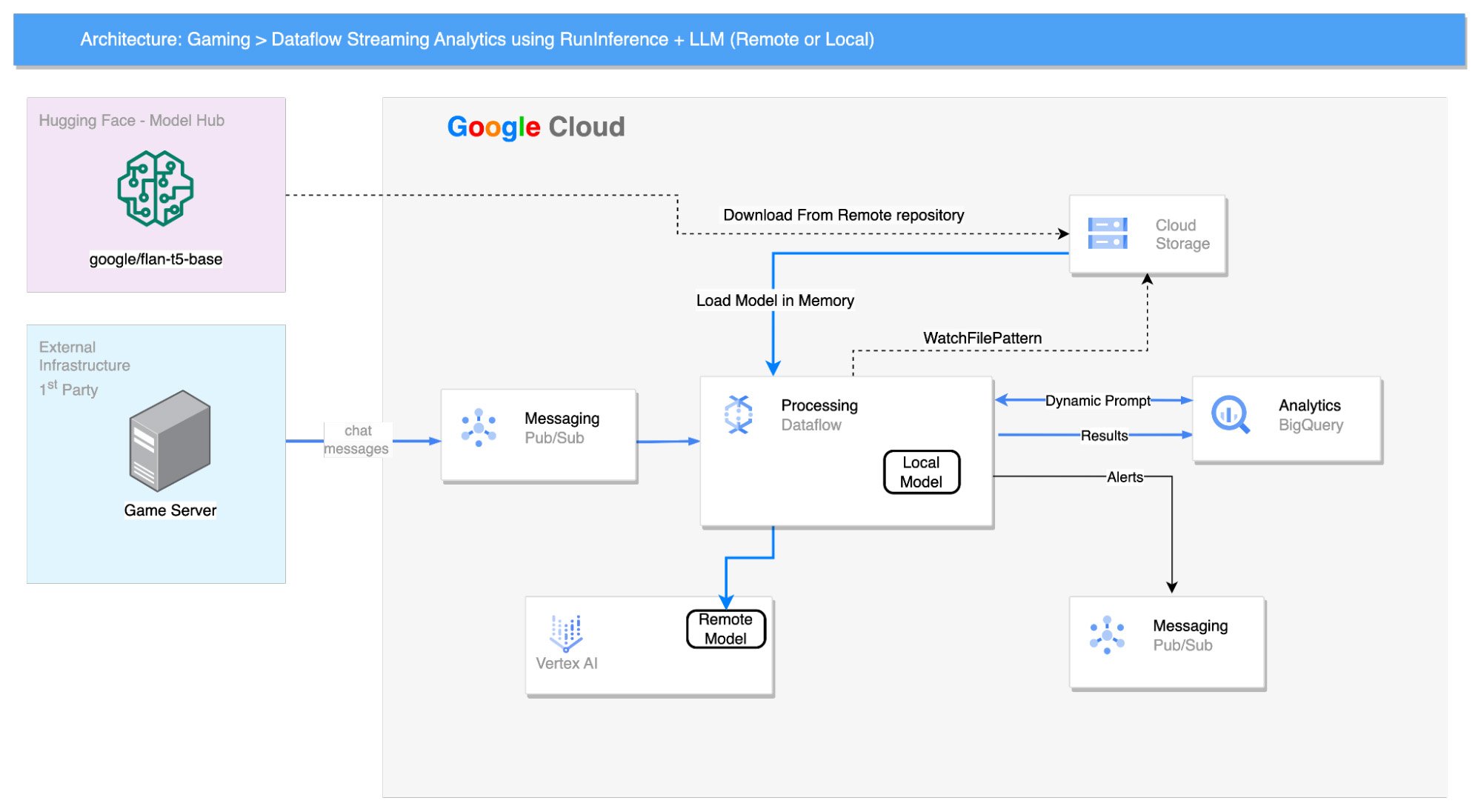
Pub/Sub トピックからゲームチャット メッセージを利用する Dataflow パイプラインを作成しました。このソリューションでは、Dataflow パイプラインをシミュレートするために BigQuery テーブルからデータを読み取り、Pub/Sub トピックにプッシュしました。
Flan-T5 モデルはワーカーのメモリに読み込まれ、次のプロンプトが入力されます。
"Answer by [Yes|No] : does the following text, extracted from gaming chat room, indicate a connection or delay issue : "
BigQuery テーブルから読み取られる Beam 副入力 PCollection により、Beam パイプライン内でさまざまなビジネス検出を実行できるようになります。
このモデルは、60 秒間の固定ウィンドウ内でメッセージごとに Yes または No の回答を生成します。「Yes」の回答の数がカウントされ、回答の合計数の 10% を超える場合、ウィンドウ データは BigQuery に保存され、詳細に分析されます。
まとめ:
このブログ投稿では、LLM とともに Beam Dataflow の RunInference 関数を使用して、ゲーマー同士のチャットに関する分析情報を得る方法を紹介しました。
読み込まれた Google / FLAN-T5 モデルで RunInference 変換を使用して、モデルに特定の単語を入力することなくシステムラグを示すものを特定しました。また、プロンプトはリアルタイムで変更でき、作成されたパイプラインへの副入力として指定できるようにしました。この方法は、カスタマー サポートのチャットログ、ソーシャル メディアの投稿、商品レビューなど、さまざまな種類のデータに関する分析情報を得るために使用できます。
リアルタイム Dataflow ワークストリームの一部として RunInference 変換を使用して ML を統合する方法について詳しくは、Beam ML のドキュメントをご覧ください。生成 AI での RunInference の使用に関する Google Colab ノートブックについては、こちらリンクをご確認ください。
付録:
生成 AI に RunInference を使用する | Dataflow ML
-Google、カスタマー エンジニア - データおよび分析スペシャリスト Kfir Naftali
-Google、カスタマー エンジニア - データおよび分析スペシャリスト Dori Rabin

