Dataflow Prime のストリーミングのジョブにおける垂直自動スケーリングの導入
Google Cloud Japan Team
※この投稿は米国時間 2022 年 8 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
Dataflow は、ジョブに合わせてリソースを自動的にプロビジョニングして、スケーリングすることで、使用率と効率性を向上させる機能を数多く提供しています。以下はその一例です。
水平自動スケーリングでワーカー数を自動的にスケーリング。
Streaming Engine でストレージとワーカーを切り離す。また、ワーカーが無制限のストレージを利用できるようになり、より応答性の高い水平自動スケーリングが可能。
動的な作業の再調整で作業の進捗状況に応じて、利用可能なワーカーに作業を割り当てることが可能。
この強固で差別化された基盤の上に、Google Cloud は最近 Google Cloud 上でお客様のデータ処理のニーズに対応する新しい次世代のサーバーレスで、NoOps の自動チューニング プラットフォームである Dataflow Prime を立ち上げました。Dataflow Prime は、業界初のリソース最適化技術である垂直自動スケーリングを導入し、ワーカーのメモリを自動的にスケーリングすることで、ワーカー構成の手動チューニングの必要性をなくしました。垂直自動スケーリングにより、Dataflow Prime は、ジョブに適したワーカー構成を自動的に決定します。
現在のユーザーの課題
Dataflow では、Apache Beam SDK や Dataflow テンプレートを使ってデータ処理ロジックを記述し、パイプラインの最適化、実行、スケーラビリティの処理は Dataflow に任せることができます。多くの場合、パイプラインはうまく実行されますが、最高のパフォーマンスと費用のために、メモリなどの適切なリソースを手動で選択する必要がある場合もあります。多くのユーザーにとって、これは時間のかかる試行錯誤を繰り返すプロセスであり、単一のワーカー構成がパイプラインに最適であることはまずありません。また、データ処理の要件が変わると、静的な構成が古くなるリスクもありました。
これらの課題を解決し、お客様がアプリケーションとビジネス ロジックに集中できるように、垂直自動スケーリングを設計しました。
垂直自動スケーリングの仕組み
垂直自動スケーリングは、ストリーミング・パイプラインのメモリ不足(OOM)イベントとメモリ使用量を時系列で観測し、これに基づいてメモリ スケーリングをトリガーします。これにより、手動で操作することなく、メモリ不足のエラーに対する耐性を備えたパイプラインを実現できます。
垂直自動スケーリングでは、メモリ使用量が多い場合、ジョブ内のすべてのワーカーを、より大きなメモリ容量を持つワーカーに置き換えます。以下の図では、ワーカー 1、2、3 のメモリ使用量が多く、容量が 4 GB であることがわかります。垂直自動スケーリング実行後、すべてのワーカーのメモリ容量は 5 GB となり、十分なメモリのヘッドルームが確保されます。
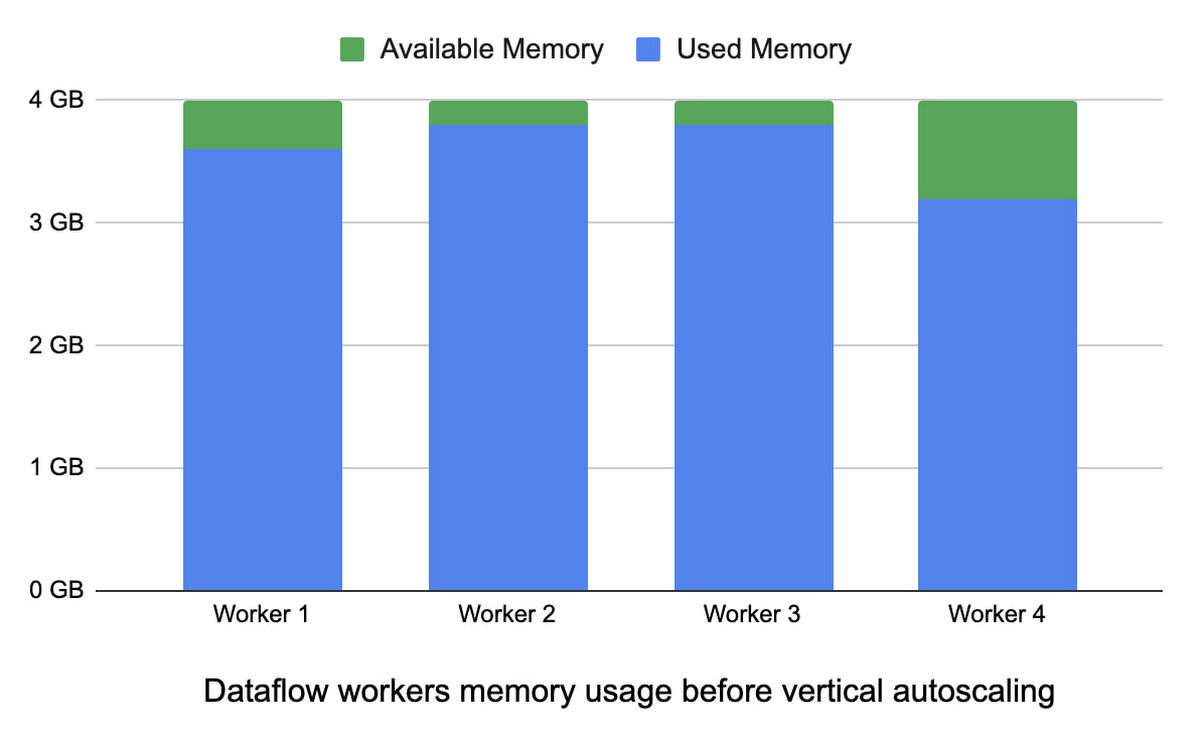

このプロセスは繰り返し行われ、ワーカーの入れ替えに最大で数分かかることもあります。
同様に、メモリ使用量が少ない場合は、垂直自動スケーリングでワーカーを低メモリ容量にダウンスケールすることで、使用率を向上させ、費用削減を図ることができます。パイプラインごとの使用履歴データをもとに、パイプラインの安定性を優先して、安全にスケールダウンするタイミングを知ることができます。メモリ使用量が急増した後、ダウンスケーリングが発生しない時間が長くなることがあります(12 時間以上)。垂直自動スケーリングについては、パイプライン処理の中断を最小限に維持するために、ダウンスケールに対して保守的なアプローチを取ります。
垂直自動スケーリングについて知っておくべきこと
垂直自動スケーリングがジョブに与える影響
ワーカーが入れ替わると、一時的にスループットが低下することはあるが、実行中のパイプラインへの影響(バックログ、ウォーターマーク、スループット指標など)は、水平自動スケーリング イベントと大きく変わることはない。
水平自動スケーリングは、垂直自動スケーリングの実行中および実行後 10 分までは無効。
水平方向スケーリングと同様に、スケーリングの過程でなんらかのバックログが蓄積される場合があり、このバックログがタイムリーにクリアできない場合、そのバックログをクリアするために水平方向のスケーリングが行われることがある。
垂直自動スケーリングはすべての OOM を除去するのか?
垂直自動スケーリングは OOM(メモリ不足)と高いメモリ使用量に対応するように設計されているが、特にワーカーのメモリ使用量が急激に増加して OOM になった場合、必ずしも OOM を防ぐことはできないことに注意することが重要である。
OOM が発生した場合、垂直自動スケーリングは自動的に検出し、ワーカーのメモリをサイズ変更して問題に対処する。その結果、ワーカーログにいくつかの OOM エラーが表示されるが、その後にアップスケール イベントが続くのであれば、無視できる。
Dataflow がメモリ使用率低下を理由にメモリ量を削減した場合、ダウンスケール イベントの結果として一部の OOM が発生する可能性があることにも注意する。このような場合、Dataflow は OOM を検出すると自動的にアップサイズする。しかし、これらの OOM メッセージの後にアップスケール イベントが発生する場合は、無視しても問題はない。
OOM メッセージの後にアップスケール イベントが発生しない場合、メモリのスケーリングの上限に達している可能性がある。この場合、パイプラインのメモリ使用量を最適化するか、リソースヒントを使用する必要がある。
OOM メッセージが継続的に表示され、メモリ スケーリングの上限に達したことを示すジョブ メッセージが表示されない場合は、サポートチームに問い合わせる。OOM がごくまれにしか発生しない場合(パイプラインごとに数時間に一度など)、垂直自動スケーリングにはさらなる混乱を避けるために、ワーカーをスケールアップしないことを選択する場合があるので注意する。
垂直自動スケーリングを有効にする方法
垂直自動スケーリングは、Dataflow Prime ジョブでのみ利用可能です。Dataflow Prime のジョブを起動する手順と、垂直自動スケーリングを有効にする方法を確認してください。
Dataflow Prime で既存の Apache Beam パイプラインを実行するために、コードを変更する必要はありません。さらに、Dataflow Prime のジョブを起動する際にワーカーの種類を指定する必要がありません。しかし、もし最初のワーカーのリソース構成を制御したい場合は、リソースヒントを使用できます。
パイプライン上で垂直自動スケーリングが実行されているかどうかは、以下のジョブログで確認できます。
垂直自動スケーリングが有効になっている。このパイプラインは、ワーカー単位で割り当てられるリソースの推奨値を受信している。
垂直自動スケーリングのモニタリング方法
垂直自動スケーリングがワーカーのメモリを増減して更新するたびに、Cloud Logging に以下のようなジョブログが生成されます。
垂直自動スケーリングが有効になっている。このパイプラインは、ワーカー単位で割り当てられるリソースの推奨値を受信している。
プールのワーカーメモリの上限ごとに X GiB から Y GiB に変更するように垂直自動スケーリングの更新がトリガーされている。
これらのログについては、こちらのセクションで詳しく説明します。
さらに、Dataflow 指標 UI の「ワーカーの最大メモリ使用率」のグラフでワーカー容量を見ることで、垂直自動スケーリングを視覚的にモニタリングできます。
以下は、垂直に自動スケーリングした Dataflow ワーカーのチャートです。このジョブには、3 つの垂直自動スケーリング イベントが表示されています。使用するメモリがメモリ容量に近づくと、垂直自動スケーリングが開始され、ワーカーのメモリ容量をスケールアップします。

まとめ
Dataflow Prime のストリーミング ジョブで、リソースの最適化と費用削減を実現する垂直自動スケーリングをお試しください。
既存の Apache Beam パイプラインを Dataflow Prime で実行するために、コードを変更する必要はありません。
垂直自動スケーリングを使用することによる追加費用は発生しません。Dataflow Prime のジョブは、引き続き消費したリソースに応じて課金されます。
- プロダクト マネージャー Zeeshan Khan
- ソフトウェア エンジニア Zach Zimmerman


