No shard left behind: dynamic work rebalancing in Google Cloud Dataflow
Eugene Kirpichov
Senior Software Engineer
Malo Denielou
Software Engineer
Introduction
Today we continue the discussion of Google Cloud Dataflow's “zero-knobs” story. Previously we showcased Cloud Dataflow's capability for Autoscaling, which dynamically adjusts the number of workers to the needs of your pipeline. In this post, we discuss Dynamic Work Rebalancing (known internally at Google as Liquid Sharding), which keeps the workers busy.
We'll show how this feature addresses the problem of stragglers (workers that take a long time to finish their part of the work, delaying completion of the job and keeping other resources idle), greatly improving performance and cost in many scenarios, and how it enables and works in concert with autoscaling.
The problem of stragglers in big data processing systems
In all major distributed data processing engines — from Google's original MapReduce, to Hadoop, to modern systems such as Spark, Flink and Cloud Dataflow — one of the key operations is Map, which applies a function to all elements of an input in parallel (called ParDo in the terminology of Apache Beam (incubating) programming model).
All of these frameworks execute a Map step by splitting the specification of its input into parts (often called shards or partitions), of roughly equal size, and then reading/processing data in each part in parallel. For example, input specified by a glob file pattern might be split into <filename, start offset, end offset> tuples; input from a key-value storage system such as Bigtable, into <start key, end key> tuples.
In all such frameworks, except Cloud Dataflow, the splitting is done upfront, before starting to execute any of the shards, and doesn't change during execution. The number of shards is usually either specified by the user or determined by the system heuristically, e.g., based on an estimate of the data size or just on the number of input files.
A very common performance problem in Map steps, faced by all frameworks, is stragglers — when a small number of shards takes much longer to be processed than the rest.
Stragglers can easily dominate the runtime of the map step, defeating much of the parallelization benefits. They can also waste resources and increase costs as other workers have to stay idle for long periods of time before they can start working on the next stage.
Here are two examples of jobs that suffer from stragglers. Throughout this post, we'll illustrate work execution using a common type of visualization we call “Gantt charts.” The X axis is time (left to right), the Y axis is worker, each green bar corresponds to a worker processing some part of the input, and white space means idleness.
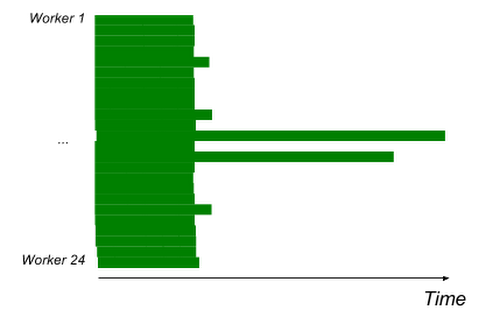
A simple job (read, ParDo, write) with 2 long straggler tasks due to uneven data distribution;
Dynamic Work Rebalancing disabled to demonstrate stragglers.

A classic MapReduce job (read from Google Cloud Storage, GroupByKey, write to Google Cloud Storage), 400 workers. Dynamic Work Rebalancing disabled to demonstrate stragglers. X axis: time (total ~20min.); Y axis: workers
Stragglers can have a variety of causes: an abnormally slow worker; some parts of data being particularly computationally intensive to process; unbalanced splitting of the input where the amount of data in different parts turns out to be drastically different. This last case happens rarely when processing files, but is quite frequent with key-value stores and other complex inputs where not enough information is available about the data distribution to split the input evenly in advance.
Another class of issues is when the amount of data is balanced, but the processing complexity is not. For example, we can imagine a pipeline which takes as input a file containing filenames of videos to be transcoded. It's not enough to give the same number of videos to each worker to ensure a balanced workflow, as the videos can be of very uneven length.
Stragglers effectively introduce long chunks of sequential work into the parallel job, so, due to Amdahl's law, their effect becomes more pronounced as the number of workers grows. It's therefore no surprise that solving this problem became an important challenge at Google, where people routinely run jobs at the scale of many thousands of cores. Since Cloud Dataflow makes this capability accessible on demand to everyone, a good solution to the problem of stragglers was a prerequisite for users to have a great experience.
Dealing with stragglers today
Industry and academia have been attacking the problem of stragglers for a long time:
- Many frameworks provide knobs to tune the number of parts into which an input is split (e.g., this post by Cloudera, as well as the official Spark documentation, provide extensive advice on tuning parallelism in Spark).
In general, finer-grained splitting produces fewer stragglers, however at some point the overhead of a large number of splits starts to dominate.
The downsides of manual tuning are obvious: it's laborious and imprecise. Moreover, the carefully chosen value can quickly become obsolete with changes to the dataset (especially if the same job is being run against different datasets), the processing algorithm, the runtime environment, or even when switching to a new version of the framework. - Some frameworks will identify slow workers and mark their machines as bad, getting those out of the worker pool preventively. This solution only addresses hardware-based stragglers though, and is not really adapted to cloud environments.
- Many systems implement speculative execution (also known as backups), or restarts for abnormally slow shards. This technique also addresses only slow workers, but not data imbalance.
- Sampling or similar techniques can help estimate the data distribution to split the data more evenly. However, such statistics are often expensive to collect, insufficiently precise, or obsolete. Moreover, as noted above, stragglers can happen even if the data distribution is balanced, due to unbalanced processing complexity for different parts of the data.
- Some more involved techniques have been researched in academia for addressing data imbalance, such as SkewTune, which fully materializes the unprocessed input of a straggler, collects statistics about it and splits it more evenly. This is a step in the right direction, however the cost of fully reading the rest of a straggler's input can be prohibitive, in particular, making the technique meaningless if the straggler was already dominated by the cost of reading the input.
Dealing with stragglers using dynamic work rebalancing
Our service, like other data processing engines, initially splits the input into parts using various heuristics. However, our experience running large-scale systems with diverse use cases, like Cloud Dataflow, lead us to the following realization.
No amount of upfront heuristic tuning (be it manual or automatic) is enough to guarantee good performance: the system will always hit unpredictable situations at run-time.
A system that's able to dynamically adapt and get out of a bad situation is much more powerful than one that heuristically hopes to avoid getting into it.
In the spirit of this, Cloud Dataflow continues to adjust the splitting during the execution using a technique similar to work stealing or work shedding. The service constantly monitors each worker's progress and identifies stragglers (e.g., those with an above-average predicted completion time). Next, Cloud Dataflow asks these workers to give away part of their unprocessed work (e.g., a sub-range of a file or a key range). Next, it schedules these new work items onto idle workers. The process repeats for the next identified stragglers. The amount of work to give away is chosen so that the worker is expected to complete soon enough and stop being a straggler.
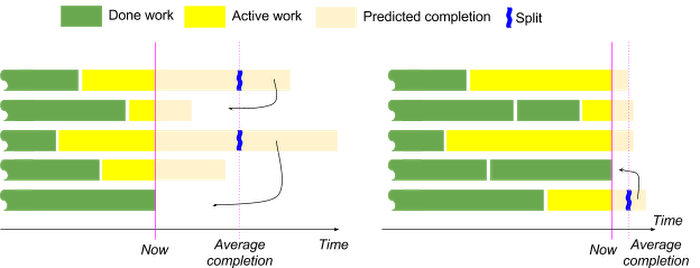
Two rounds of split adjustment. When a worker becomes idle, straggler shards are split
to complete by current average completion time.
Using this technique, the service is able to dynamically eliminate stragglers and repartition the work to achieve near-optimal parallelization and utilization.
Technical challenges
This technique sounds simple enough to make one wonder: why is it not implemented in other data processing engines yet? As it turns out, building a robust implementation of this feature is challenging.
The first challenge is data consistency. When splitting happens upfront, it's straightforward to make sure that the workflow processes all the data, exactly once. This becomes much harder when splitting can be adjusted while the data is concurrently being read or processed (we found such wait-free splitting to be critical for good performance in case some records take very long to read or process), and in the presence of worker or service failures. All parts of the data need to be tracked and not a single record may be lost (or duplicated) under any circumstance. For performance, we would also like to avoid redundant reading or processing of data.
Ensuring data consistency requires intense systematic testing, as well as a careful design that can express the consistency requirements under dynamic splitting in a generic way for the full variety of input types (offset-based such as text files, block-based such as Avro files, key-range-based such as Bigtable, etc.)
This issue becomes harder because Cloud Dataflow is agnostic to the particular sources: they're all merely implementations of the respective Cloud Dataflow (and now Apache Beam) source API. It's a challenge to develop a public API that users will find easy to implement correctly for their sources. We help users with this by providing automatic, easy to use, exhaustive testing utilities that are source agnostic and will thoroughly check if the API is implemented correctly in just a couple lines of code.
Another challenge is in identifying straggler tasks and computing the optimal adjustments to splitting. At the core, this reduces to predicting how a task will progress over time. It's easy to do so for tasks that process input (such as files) at a uniform rate — it's considerably harder in case of sources with non-uniform data distributions (e.g., Google Cloud Bigtable), highly non-uniform or excessively long record processing times, and other situations where reliable information about progress is inherently missing. In these situations, Dataflow has to dynamically make trade-offs between speed and precision of splitting.
Together, these challenges make dynamic work rebalancing one of the most intricate and unique features in Cloud Dataflow. However, the benefits this feature brings justify the challenges, and we would be excited to see other systems learn from our experience.
The advantages of dynamic work rebalancing
Dynamic work rebalancing has some obvious benefits for our users, and some non-obvious but far-reaching ones.
- Better worker utilization, of course, means reduced overall completion time (since the same amount of work is parallelized better).
- Workers are kept busy, which gives significantly reduced costs (idle workers are a waste of resources).
- Reliable near-optimal parallelization also means better predictability, i.e., reduced variance of the job’s completion time. The completion time depends on the amount of computation to be done, rather than on environmental factors that might affect a few workers, or on how accurate the system’s heuristic guesses turn out to be in each run.
- Users can stop worrying about tuning parallelism or sharding and are empowered to focus on their data and the business logic of their computation.
The same pipeline will keep executing optimally, with zero tuning or maintenance, on a small dataset, a large dataset, a dataset with a very different data distribution, on multiple of these at the same time or after the user changes their processing algorithm. - Last but not least, dynamic work rebalancing is essential to enabling autoscaling. It's not uncommon for Cloud Dataflow to start executing a pipeline on, say, three workers, and later to detect during execution that due to the large amount of computation to be done, it should scale up to 30, 120 or 500 workers.
Of course, the execution on 500 workers demands a much finer-grained splitting of the input, and without the ability to adjust the splitting according to the current resource allocation, scalability would quickly plateau due to stragglers. Cloud Dataflow can perform such an adjustment dynamically, without losing or duplicating parts of the work executed so far on the three workers.
Examples
Without further ado, let's look at real performance improvements provided by dynamic work rebalancing.
In this example, we run the same job with uneven data distribution, run with and without dynamic work rebalancing. We see that it eliminates the stragglers and provides a speedup of over 2x.

A job with uneven data distribution running on 24 workers(autoscaling disabled, dynamic work rebalancing disabled); duration ~9min.

Same job, dynamic rebalancing enabled, runtime ~15min.
The next example runs at higher scale. This is a classic MapReduce-type job, using 100 n1-standard-4 machines, that reads some data from files on Google Cloud Storage, groups it by key, performs some processing and writes the result to Google Cloud Storage.
Despite this simple structure, allowing for uniform initial data partitioning, the job still has stragglers (presumably due to slightly different performance of the workers, differences in the data they process, or variances in performance of Google Cloud Storage itself) and dynamic work rebalancing speeds it up by ~25%.

A MapReduce-type job, 100x n1-standard-4 workers, dynamic work rebalancing disabled, runtime ~20min.

Same job, dynamic rebalancing enabled, runtime ~15min.
In this final example, dynamic work rebalancing works in concert with autoscaling: a large job starts with three workers, and, as the service discovers the amount of computation to be done, it gradually scales up to 1000 workers, dynamically adjusting the splitting to keep optimal utilization. (Vertical blue stripes are waves of dynamic rebalancing kicking in and splitting the tasks)

Conclusion
We've presented Dynamic Work Rebalancing, one of the key unique features of Google Cloud Dataflow. Stragglers are a frequent issue in large scale data processing systems, and their impact is particularly significant when scaling to thousands of cores (something that Cloud Dataflow makes very accessible).
Whether stragglers are caused by hardware anomalies, network conditions or uneven data distribution, Cloud Dataflow’s dynamic work rebalancing maintains an near-optimal parallelization of the work across the workers.
This means faster and more predictable execution time, lower cost and better resource utilization, transparent scalability to thousands of cores, and all these benefits keep “just working” when applying the pipeline to different datasets or changing the business logic. It's one more way in which we empower our users to focus on what’s important — their algorithms and data.



