Cloud Composer で Cloud Dataprep ジョブをオーケストレートする方法
Google Cloud Japan Team
※この投稿は米国時間 2019 年 10 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
クラウドでデータ分析を行うと優れた分析情報とより大きなビジネス成果が得られますが、最初に適切なデータを用意する必要があります。Google Cloud の Cloud Dataprep by Trifacta は、分析、レポート、機械学習に使用するデータを探索、クリーニング、準備するためのサービスで、使用を開始する前に適切なデータが揃っていることを確認できます。
Cloud Dataprep の最新リリースをお知らせします。オーケストレーション API が公開されるため、Cloud Dataprep をスケジューラや、Cloud Composer などの他のオーケストレーション ソリューションに統合できます。つまり、他のツールとの直接統合によって Cloud Dataflow テンプレート以外にも自動化を拡大し、分析と AI / ML イニシアチブの再現可能なデータ パイプラインを作成することで、時間が節約され、信頼性が向上します。さらに、この API を使用すると、Cloud Dataprep の変数やパラメータにより、Cloud Dataflow テンプレートでは利用できない動的な入出力が使えます。そのため、単一の Cloud Dataprep フローを再利用して、実行時に評価されるさまざまな入出力値で実行できます。
これらの新機能は、定期的に実行される複数のタスクを含む分析パイプラインに対して高品質のデータを提供するのに役立ちます。Cloud Dataprep を含め、Cloud Composer でオーケストレートできる一般的なワークフローの例を以下に示します。
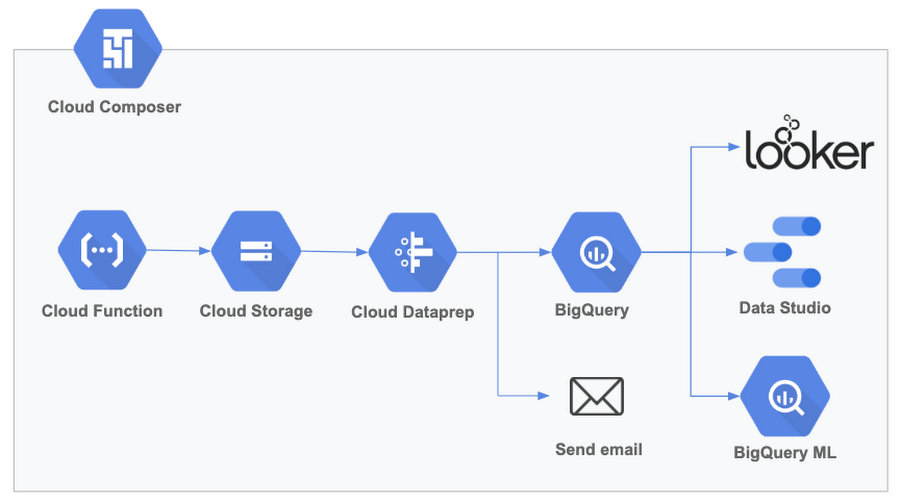
このソリューションを分析イニチアチブ向けに実装している先行ユーザーの事例をご紹介します。
Woolworths はオーストラリアの大手スーパー チェーンで、正確で一貫した時系列レポートを作成するうえで、いくつもの課題に直面していました。同社が利用している社内外のデータソースは形式や標準がばらばらで大量にありました。また、評価や変換を行った後、単一の一貫したビューに結合することが望まれていました。しかも、この複雑なオーケストレーション要件には、複数のサーバーレス コンポーネントや、サードパーティ プロダクトとの連携が関わっていました。
Woolworths はレポートの作成にあたり、Cloud Dataprep を使用してデータの構造化とクリーンアップを行った後、データを組み合わせて集約し、複雑でさまざまな計算で拡張することで対応してきました。しかし、課題は完全に解決されたわけではありませんでした。他のシステムからのデータの取り込み、整合性のチェック、データの準備、BigQuery(データエラーの集積、計算の検証に使用)への読み込みなどの事前処理を、より幅広く包括的なデータ パイプライン内でオーケストレートする必要がありました。こうした作業により、お好みの BI ツールでのレポート作成用にデータを用意したり、Google スプレッドシートやメールでデータを共有したりすることが可能になります。
Woolworths は、Cloud Dataprep オーケストレーション API と Cloud Composer を併用することで、複雑でありながら管理可能で一貫性のある、エンドツーエンドのワークフローを構築することを計画しています。これにより、業務に欠かせないデータの正確性を確保できます。
Woolworths のリード データ エンジニアである Radha Goli 氏はこう述べています。「Woolworths Australia は 1,000 を超える店舗と数十万の従業員を抱え、収益を最大化するために施設の計画と最適化を慎重に行う必要があります。データ収集から高度な分析まで、有用なデータ分析情報を生成するためのすべてのステップは、会社の戦略に大きく影響します。Cloud Dataprep オーケストレーション API を利用すると、Cloud Composer 内でデータ パイプラインを調整して、再現可能で信頼できるデータを業務で活用できるようになります。」
Cloud Dataprep と Cloud Composer を使ってみる
Cloud Composer ワークフロー内で Cloud Dataprep を統合する方法について説明します。
Cloud Composer は Google Cloud Platform(GCP)上で実行されるフルマネージド ワークフロー オーケストレーション サービスで、よく利用されている Apache Airflow オープンソース プロジェクト上に構築されています。Cloud Composer を使用すると、複雑なパイプラインを作成、スケジューリング、モニタリングして、複雑さを軽減し、信頼性を向上させることができます。
この最初のワークフローは非常に単純ですが、この原則を適用すると、はるかに複雑なパイプラインをオーケストレートできます。Composer と Cloud Dataprep を使用して最初のパイプラインを作成する方法は次のとおりです。
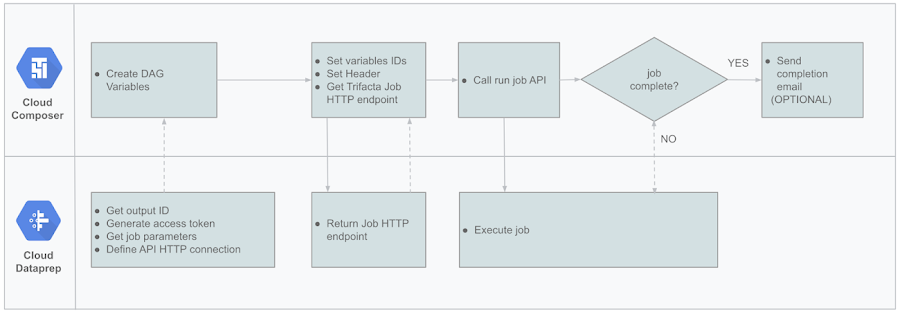
パイプラインの設定方法は次のとおりです。
1. Cloud Composer で変数を構成する
Cloud Composer パイプラインは Python を使用して有向非巡回グラフ(DAG)として構成されているため、簡単に開始できます。DAG を設定する前に、Cloud Composer で 3 つの変数を設定する必要があります。jobGroups API を使用するので、API を通じて実行される出力の「output_id」(以下を参照)と、認証に使用される「trifacta_bearer」トークンを保存する必要があります(API アクセス トークンのドキュメントを参照)。各変数は DAG のコードで使用され、正しい認証トークンで特定の出力を呼び出します。
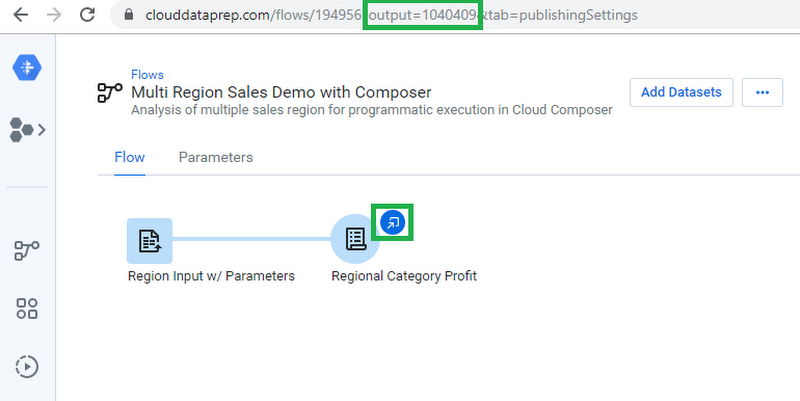
Cloud Dataprep インターフェース: フローから output_id を選択
Cloud Composer で設定する 3 番目の変数は、まったく同じ名前の Cloud Dataprep の概念に対応しています。Cloud Dataprep の変数とパラメータを使用すると、実行時にプラットフォームで使用される入出力値を変更できます。この例では、「region」という名前の入力変数があり、実行ごとに変更可能な値である USA、Germany、Canada を使用します。
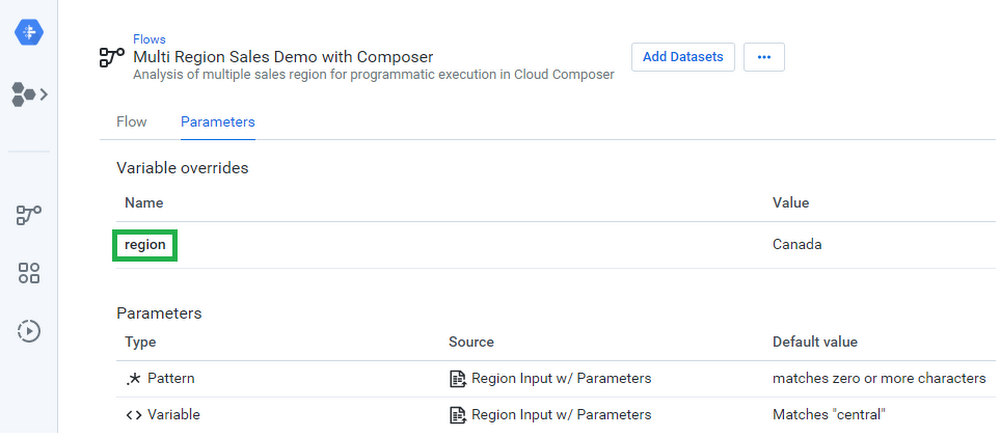
Cloud Dataprep インターフェース: フローで定義された変数とパラメータの表示
Cloud Dataprep の変数を使用すると、Cloud Composer で [Admin] / [Variables] インターフェースを起動して、Cloud Composer で各変数に対応する定義を作成できます。この例では、変数 output_id、region、trifacta_bearer を呼び出し、それぞれの値を設定しました。
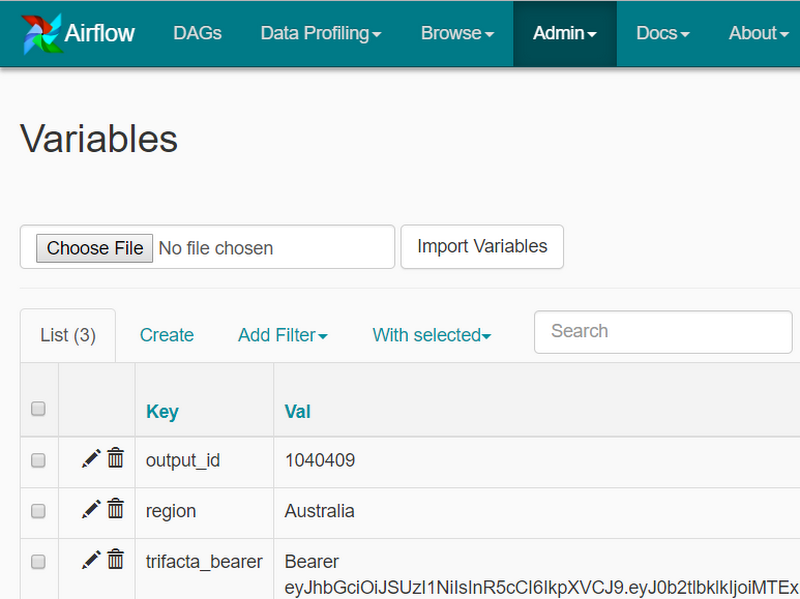
Airflow インターフェース: Cloud Composer による起動
2. HTTP 接続を設定する
また、[Admin] メニューに [Connections] 画面があります。デフォルトの HTTP 接続を使用するか、新しい HTTP 接続を作成します。接続先が https://api.clouddataprep.com/<project-id> になっていることを確認してください。
3. ID で変数値を定義する
DAG の始めに変数を定義して、後で使用できるようにします。
プログラムで Dataprep ジョブを呼び出す
ジョブを実行するには、SimpleHttpOperator() のインスタンスを作成する必要があります。このタスクでは、最近リリースされた jobGroups API にヒットするエンドポイントを定義します。リクエストの本文には、DAG 変数では output_id と呼ばれる wrangledDataset の ID を記載します。その手順を次に説明します。
1. エンドポイントを定義する
ヘッダーの定義には、通常のコンテンツタイプ情報を含めるとともに、変数に以前に保存したトークンを動的に取得するようにしてください。
2. ジョブの完了を待つ
run_flow_and_wait_for_completion() の定義には、ジョブのステータスを確認するロジックも含まれています。このチェックタスクは Airflow の HttpSensor クラスのインスタンスで、定期的に poke メソッドを使用してジョブのステータスをチェックします。
check_flow_run_complete はジョブがまだ進行中の場合は False を返し、ジョブ ステータスが「Complete」の場合は True を返します。
3. 完了時にメールを送信する
すぐに使える EmailOperator() を使用すると、メール通知タスクを簡単に設定できます。
4. タスク シーケンスを設定する
Cloud Composer では、タスクを実行する順序とタスク間の依存関係をカスタマイズできます。DAG のスケジュールを定義し、実行させます。
これで、上記の新しい API を使用し、Cloud Dataprep をスケジューラやオーケストレーション ソリューション内に統合できるようになりました。このリリースには、マクロ、例による変換、Cluster Clean などの新しいエンドユーザー機能も付属しています。これらは実際にお試しいただけます。データ ラングリングを体験してみましょう。
-by Sean Ma, Product Manager, Trifacta and James Malone, Product Manager, Google Cloud


