Google Cloud で Monte Carlo を利用してデータ オブザーバビリティを導入する方法
Google Cloud Japan Team
※この投稿は米国時間 2024 年 1 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
重要なダッシュボード、ML アプリケーション、さらには大規模言語モデル(LLM)の基盤となるデータの価値はますます高まっています。逆に言うと、データのダウンタイム(データが間違っていたり、不完全だったり、アクセスできなかったりする時間)により失われるものもますます大きくなっているということです。たとえば、デジタル広告プラットフォーム企業でデータ パイプラインに障害が発生した場合、数十万ドルの収益減につながる可能性があります。
残念ながら、データが壊れる可能性をテストですべて予測することは不可能であり、環境全体にわたって不整合を把握しようとすると、とてつもない時間が必要となります。
データ オブザーバビリティ ソフトウェア プロバイダである Monte Carlo は、Google Cloud と協力して ETL、データ ウェアハウジング、データ分析に最先端の Google Cloud サービスを活用することにより、データのダウンタイムを大幅に削減しています。Monte Carlo の堅牢なデータ オブザーバビリティ機能を組み合わせれば、大規模にデータ インシデントの検出、解決、防止を改善できます。
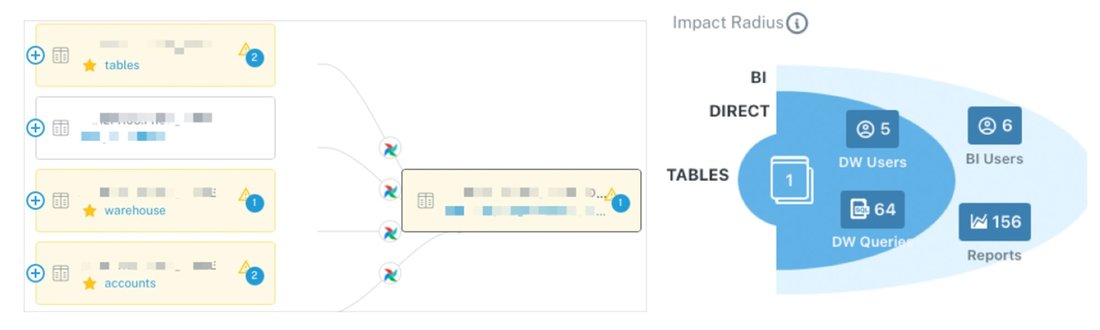
Monte Carlo のデータリネージは、ボリューム インシデントに関連する可能性のある、アップストリームの異常なアセットを示します。一方、Impact Radiusは影響を受けるユーザーを示し、情報に基づいたスマートなトリアージができるようにします。
これはすべて、メタデータ、クエリログへのアクセス、データの構造化に役立つその他の BigQuery 機能、および Looker が提供する API によって実現されます。
このリファレンス アーキテクチャは、以下の主な成果をもたらします。
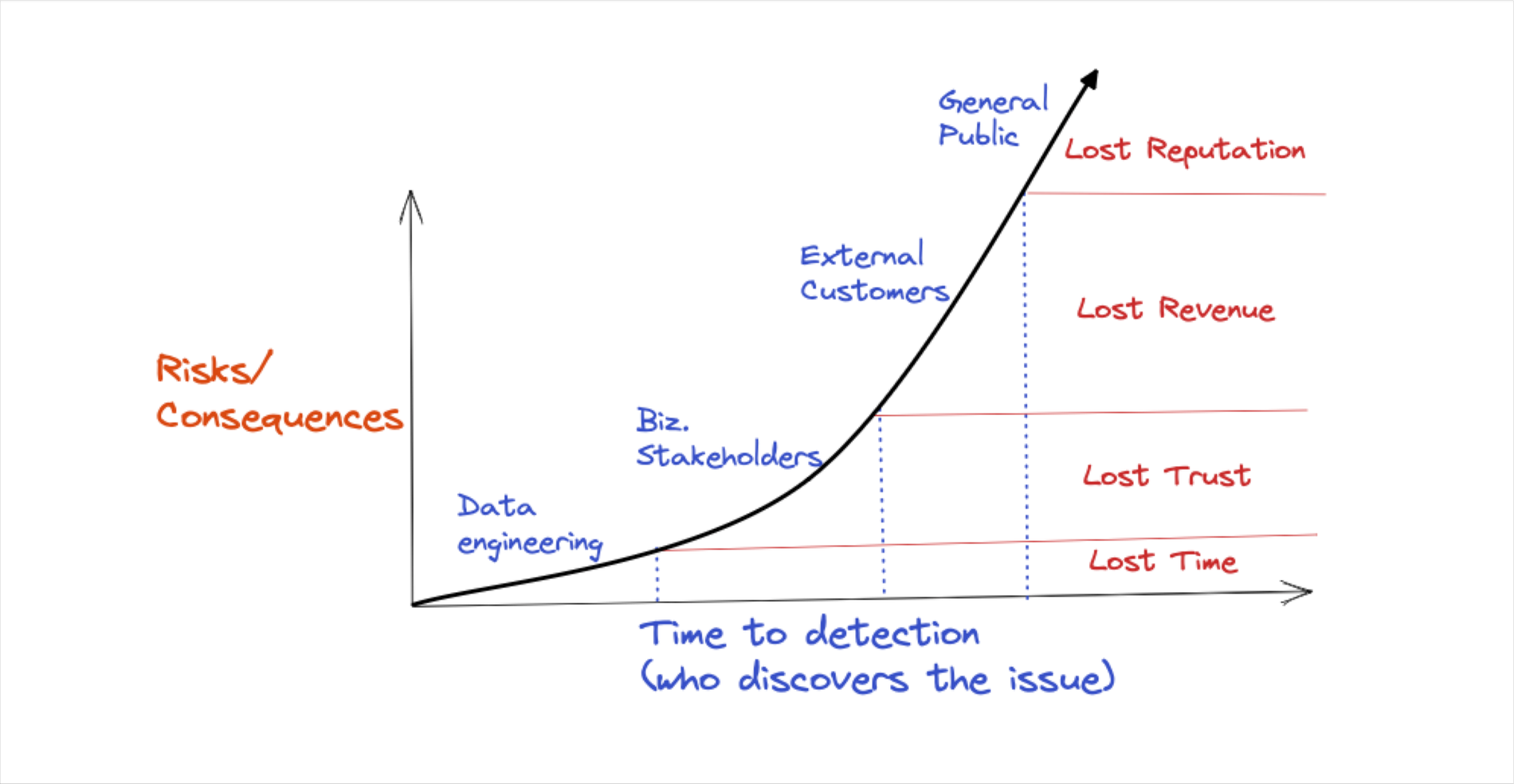
- 不良データによるリスクと影響の軽減: インシデントの発生件数を減らし、解決までの時間を短縮することで、不良データが評判、競争力、財務に悪影響を及ぼす可能性を抑えます。
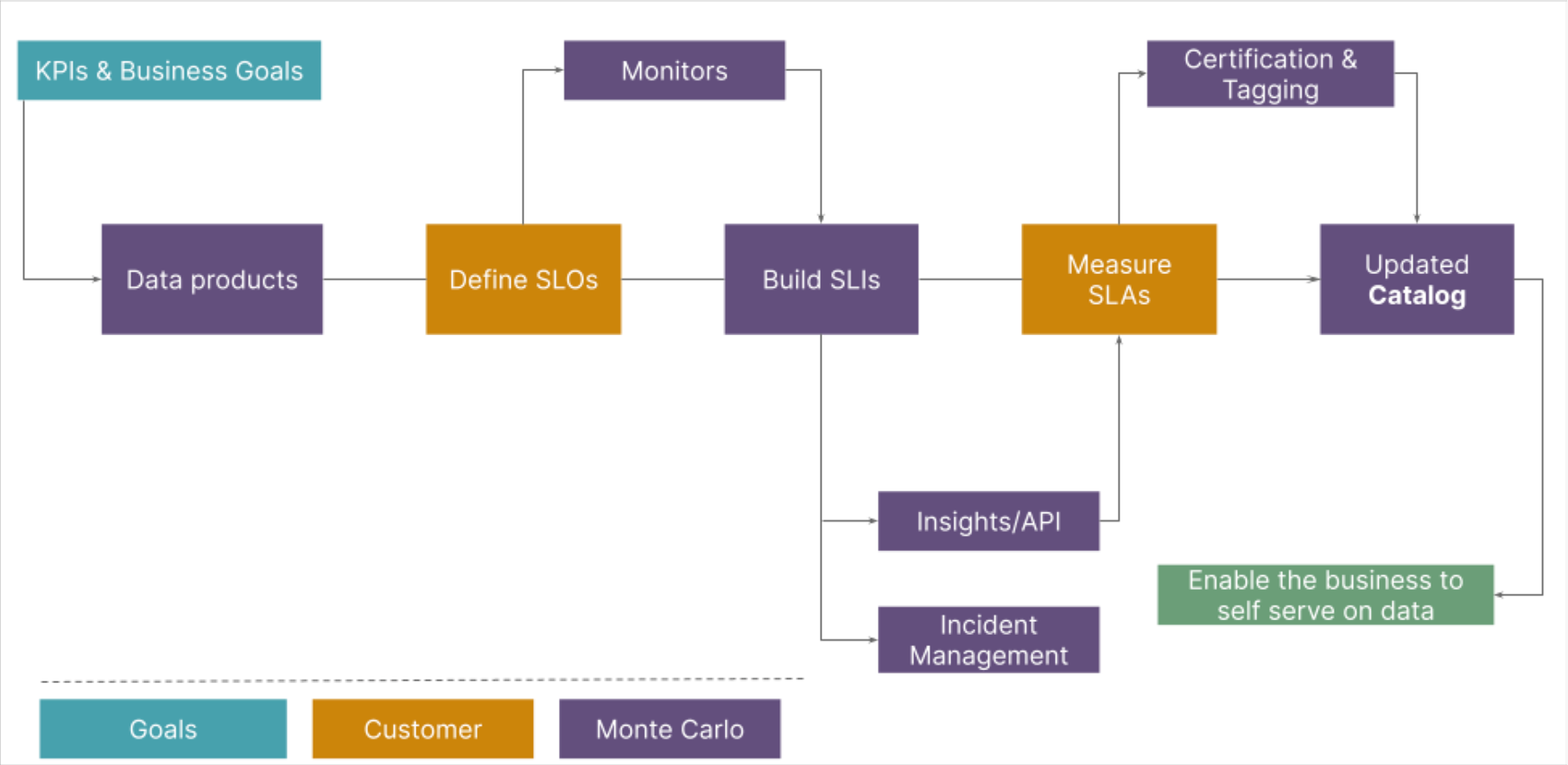
2. データの利用、信頼性、コラボレーションの向上: インシデントを最初に捕捉し、インシデント管理プロセスで事前に通知することにより、データの信頼性が高まり、利用が促進されます。データ品質モニターとダッシュボードは、効果的かつプロアクティブなデータ SLA の作成に必要とされる、適用と可視化のためのメカニズムです。
3. データ品質の確保に費やす時間とリソースの削減: 調査によると、データチームは平均して週の作業時間の 30% 以上を、データやデータ インフラストラクチャへの投資価値をさらに高めるタスクではなく、データ品質の確保やその他のメンテナンス関連のタスクに費やしています。データ オブザーバビリティは、データチームがデータ品質モニタリングの拡張やインシデントの解決に費やす時間を短縮します。
4. データ プロダクトのパフォーマンスと費用の最適化: データチームが迅速に行動すると、次第に「パイプラインの負債」が蓄積されていきます。実行速度の遅いデータ パイプラインは、コンピューティング リソースを過度に使用し、データ品質の問題を引き起こします。その結果、戻りデータ、ダッシュボードの読み込み、AI モデルの更新を待機しなければならないデータ利用者にとって、ユーザー エクスペリエンスの質が低くなります。
アーキテクチャ
Monte Carlo のサービスは最近、Google Cloud のネイティブ テクノロジーを活用してハイブリッド SaaS サービスの提供も開始しました。次の図は、BigQuery、Looker、その他のデータ パイプライン ソリューションを Monte Carlo プラットフォームに接続するための、Google Cloud がホストするエージェントとデータストアのアーキテクチャを示しています。
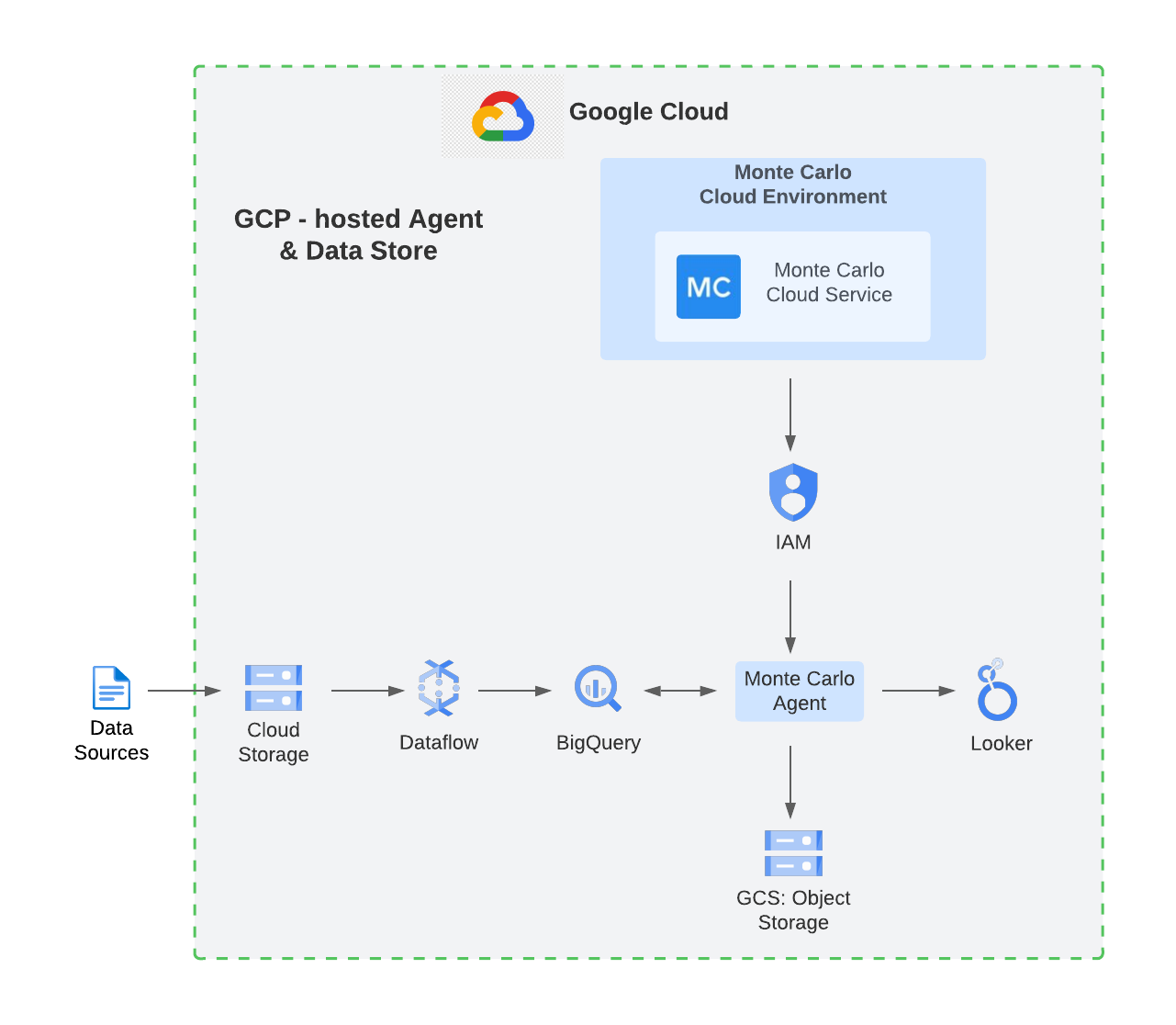
その他のアーキテクチャ オプションには、以下のようなデプロイがあります。
- MC エージェントを Monte Carlo のクラウド環境でホストし、オブジェクト ストレージを Google Cloud Storage バケットとして残す
- MC エージェントとオブジェクト ストレージの両方を MC クラウド環境でホストする
これらのデプロイ オプションは、MC サービスへの接続をどの程度コントロールし、エージェント / コレクタのインフラストラクチャをどのように管理するかを選択するのに役立ちます。
Google Cloud がエージェントとデータベースをホストするオプションでは、以下のコンポーネント上に構築された複数の機能を提供します。
- BigQuery でデータを処理および拡充 - BigQuery は、サーバーレスで費用対効果の高いエンタープライズ データ プラットフォームです。BigQuery のアーキテクチャにより、SQL 言語を使用してエンタープライズ規模のデータをクエリしたり拡充したりできます。また、BigQuery のスケーラブルな分散型分析エンジンを使用すると、数テラバイト、数ペタバイトのデータに対し、数秒もしくは数分でクエリを完了できます。統合された ML と BI Engine への対応により、データを簡単に分析してビジネスのインサイトを取得できます。
- Looker でデータとインサイトを可視化 - Looker は、多数のデータソースとの統合を通じてデータを統合する包括的なビジネス インテリジェンス ツールです。Looker では、ダッシュボードを自動的に作成およびパーソナライズすることにより、データを重要なビジネス指標やディメンションに変換できます。また、BigQuery プロジェクトや特定のデータセットを Looker のデータソースとして直接追加できるため、Looker と BigQuery を簡単にリンクできます。
- Monte Carlo エージェントとオブジェクト ストレージをデプロイ - メタデータ、ログ、統計情報を抽出するために、Monte Carlo はエージェントを使用して、データ ウェアハウス、データレイク、BI、その他の ETL ツールに接続します。エージェントがレコードレベルのデータを収集することはありません。ですが、Monte Carlo のお客様がトラブルシューティングや根本原因の分析プロセスの一環として、プラットフォーム内の個々のレコードの小さなサブセットをサンプリングしたいと考える場合もあります。場合によっては、このようなサンプリング データをクラウド内に保持する必要があるため、そのために Google Cloud Storage の専用オブジェクト ストレージを使用することが可能です。Google Cloud 環境にエージェントをデプロイするには、Terraform Registry の適切なインフラストラクチャ ラッパーにアクセスします。これにより、エージェント用の Cloud Run とサンプリング データ用の Cloud Storage バケットに Docker Hub イメージが起動されます。エージェントには、公共のインターネットにアクセスする安定した HTTPS エンドポイントがあり、Cloud IAM 経由で認証します。
- Monte Carlo のサンプリング データ用にオブジェクト ストレージをデプロイ - Monte Carlo のお客様は、トラブルシューティングや根本原因の分析プロセスのために、プラットフォーム内の個々のレコードの小さなサブセットをサンプリングしたいと考える場合があります。このようなサンプリング データには、Monte Carlo エージェントをデプロイして管理するかどうかにかかわらず、クラウド内に保持したいという要望や要件がある可能性があります。ユーザーは Terraform Registry(GitHub リポジトリ)で、リソースを生成する適切なインフラストラクチャ ラッパーを見つけることができます。
- Monte Carlo と BigQuery を統合 - エージェントをデプロイして接続を確立したら、適切な権限を持つ読み取り専用のサービス アカウントを作成し、Monte Carlo のオンボーディング ウィザードでサービス認証情報を提供します(BigQuery の設定について詳しくはこちら)。BigQuery のメタデータとクエリログを解析することで、Monte Carlo はインシデントを自動的に検出し、エンドツーエンドのデータリネージを表示できます。これは追加構成なしで、デプロイから数日以内にすべて完了します。
- Monte Carlo と Looker を統合 - Looker とLooker Git(旧 LookML コード リポジトリ)も簡単に統合できます。これにより、Monte Carlo は Looker オブジェクトと最新のデータスタックの他のコンポーネント間の依存関係をマッピングできます。これを行うには、Looker 上で API キーを作成し、Monte Carlo がダッシュボード、Look、その他の Looker オブジェクトのメタデータにアクセスできるようにします。その後、秘密鍵 / 公開鍵で接続すると、より詳細なコントロールと接続性を実現できます。MC に接続するリポジトリが多い場合は、HTTPS の使用をおすすめします。
- Monte Carlo を Cloud Composer および Cloud Dataplex と統合 - Monte Carlo エージェントは、Cloud Composer および Cloud Dataplex と効果的に統合し、Google Cloud データ エコシステム全体でデータの信頼性とオブザーバビリティを強化できます。Monte Carlo を Cloud Composer および Cloud Dataplex と統合することで、データ オブザーバビリティの強化、データ インシデントの迅速な特定、より効率的な根本原因分析を実現できます。この統合により、Google Cloud 内の複雑で多面的なデータ環境で高いデータ品質と信頼性を維持できます。
- Monte Carlo と他の ETL ツールを統合 - 多くの場合、組織のデータ プラットフォームは、データの取り込み、オーケストレーション、変換、検出 / アクセス、可視化など、データ ライフサイクルを管理する複数のソリューションで構成されます。組織の規模によっては、同じカテゴリ内で複数のソリューションを使用している場合もあります。たとえば、BigQuery だけでなく、Google Cloud を活用する他の ETL ツールにもデータを保存して処理する組織もあります。このような統合のほとんどは、Google Cloud がホストする Monte Carlo エージェントに接続する際、単純な API キーまたはサービス アカウントを必要とします。特定の統合について詳しくは、Monte Carlo のドキュメントをご覧ください。
まとめ
まとめると、Monte Carlo と Google Cloud を使ってデータ オブザーバビリティを導入することは、ますます重要となっているデータのダウンタイムという問題への貴重なソリューションとなります。高度な Google Cloud サービスと Monte Carlo のオブザーバビリティ機能を活用することで、組織は不良データに関連するリスクを軽減できるだけでなく、データ環境全体の信頼性、コラボレーション、効率性を高めることができます。前述のとおり、BigQuery や Looker のようなツールを Monte Carlo のアーキテクチャと統合すれば、強力な相乗効果が生まれ、データ品質とパフォーマンスを最適化しながら、データ メンテナンスに費やす時間とリソースを減らすことができます。
組織のデータ マネジメント戦略を強化し、データのダウンタイムを最小限に抑えたいとお考えなら、Monte Carlo を Google Cloud 環境に統合することをご検討ください。まずは、現在のデータ設定を評価し、Monte Carlo のオブザーバビリティですぐに改善される領域を特定しましょう。データの世界では、プロアクティブな管理が可能性を最大限に引き出す鍵であることを忘れないでください。
次のステップに進む準備はできていますか。Monte Carlo または Google Cloud チームに今すぐ連絡し、データ オブザーバビリティと信頼性の向上に取りかかってください。一緒に組織のデータ処理方法を変革しましょう!
ー Google Cloud、スタッフ クラウド ソリューション アーキテクト Yang Li
ー Monte Carlo、プロダクト マーケティング Michael Segner 氏

