サーバーレスのクレジット カード不正利用リアルタイム検出ソリューションの構築方法
Google Cloud Japan Team
※この投稿は米国時間 2021 年 3 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
オンライン クレジット カード決済への移行が進む中、リアルタイムでアクションにつながるアラートを送信する効果的な不正検知ソリューションへのニーズが高まっています。こうした状況を受け、Google では、世界中の金融機関との業務経験を持ち、受賞歴もある Google Cloud プレミア パートナー、Quantiphi と連携し、Google Cloud のサーバーレス NoOps プロダクトを使って 1 時間でスケーラブルな不正利用リアルタイム検出ソリューションを構築できる、スマート アナリティクス デザイン パターンを開発しました。不正利用通知の設定に加えて、不正利用検知パイプラインのパフォーマンスをモニタリングするためのダッシュボードを構築する方法もご紹介します。

このソリューションで使用されている Google Cloud 製品はすべてサーバーレスかつフルマネージドであるため、インフラストラクチャの設定やメンテナンスに時間を費やす必要がなく、わずか 1 時間でソリューションを立ち上げ、運用に集中することができます。本ブログ投稿では、ソリューションがどのように機能するのかについて、技術的な観点から掘り下げていきます。
BigQuery でデータを用意する
BigQuery ML を使用して不正利用検出モデルを構築する
AI Platform で BigQuery ML モデルをホストし、Dataflow を使用してストリーミング データでオンライン予測を行う
Pub/Sub を使用して、アラートベースの不正利用通知を構築する
データポータルを使用して、ビジネスの関係者やテクニカル チーム向けのオペレーション ダッシュボードを作成する
BigQuery でデータを用意する
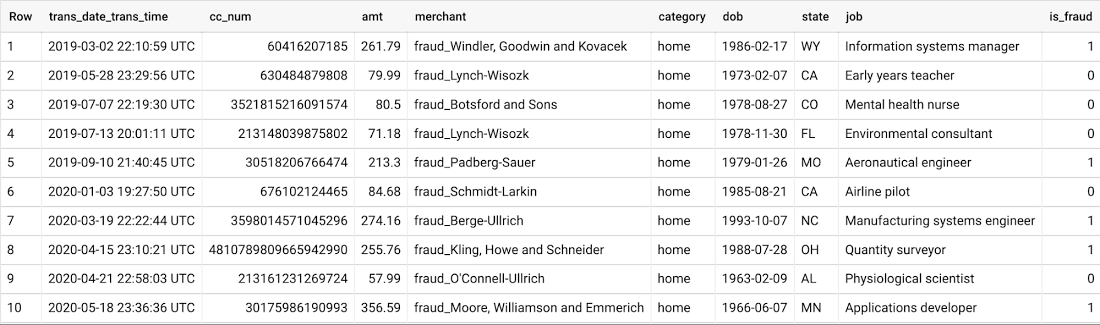
この第一段階では、トレーニング データとしてクレジット カード取引の履歴データを収集することが最も重要な手順となります。Sparkov データ生成ツールを使用して、クレジット カードの取引データと顧客のユーザー層データの記録を BigQuery に保存しました。
トレーニング データには、クレジット カード番号、取引金額、販売者情報、カテゴリなどの取引明細に加え、状態、仕事、生年月日などの顧客属性が含まれます。実際には、センシティブ データを匿名化するため、Cloud Data Loss Prevention の使用を検討することをおすすめします。最後の列、is_fraud は、機械学習で予測の対象となるラベルです。
BigQuery に保存されたデータを使用することで、インフラストラクチャの設定や調達を行うことなく、BigQuery ML を使用した機械学習モデルを簡単にトレーニングすることができ、設計パターンを製品化するための時間、コスト、複雑性を軽減できます。BigQuery テーブルは一般に公開されており、Gitlab リポジトリからコードをフォローすることができます。もしご自分のデータセットを使ってフォローしているのであれば、この時点で、データを似たような形式に整形しておくことをおすすめします。
BigQuery で用意されたデータを取得したら、機械学習不正利用検出モデルの構築に移りましょう。
BigQuery ML を使用して不正利用検出モデルを構築する

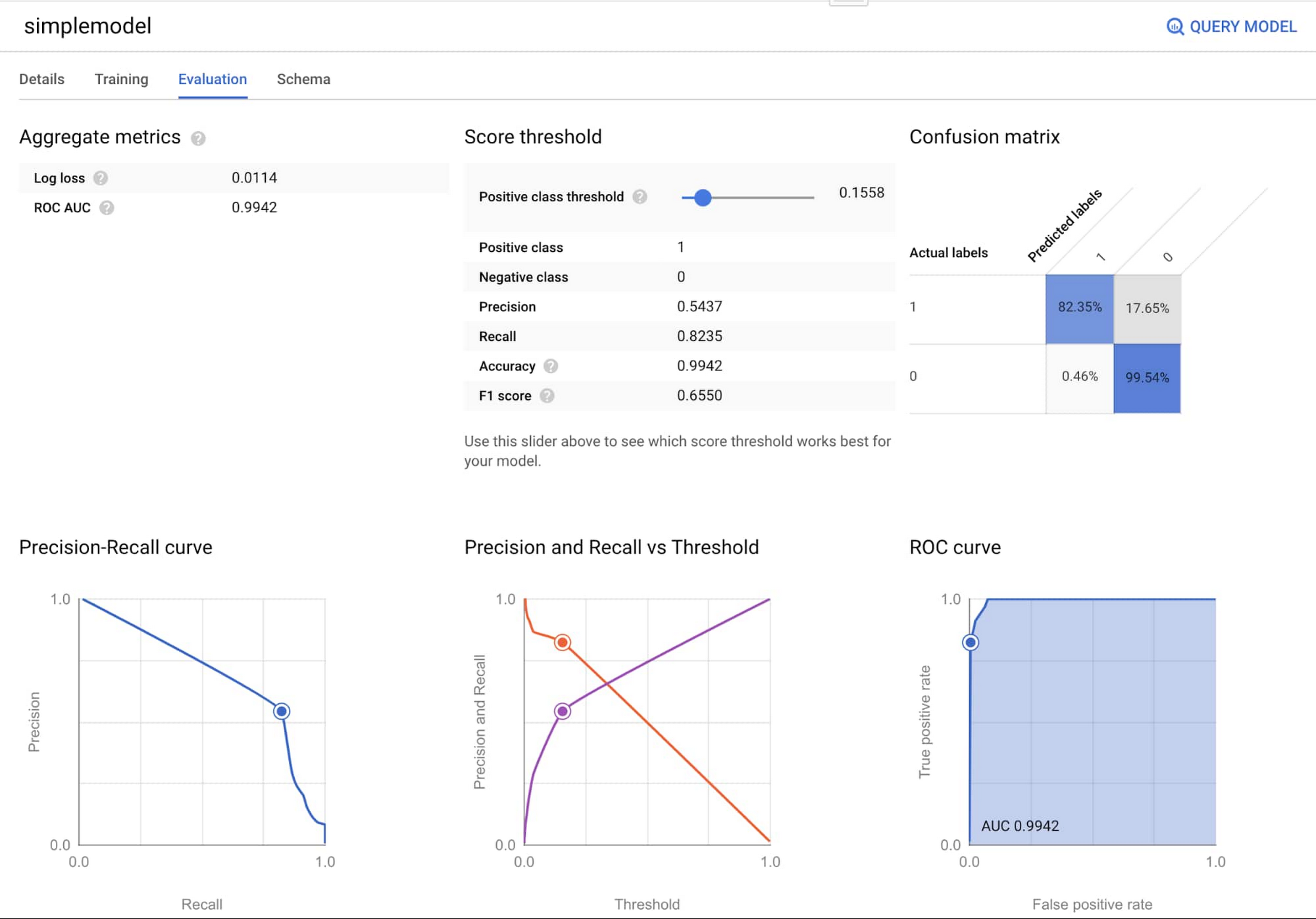
取引データと顧客属性データの両方が BigQuery にあれば、BigQuery ML で SQL を使ってモデルをトレーニングできます。選択できる分類アルゴリズムには、ロジスティック回帰、XGBoost、ディープ ニューラル ネットワーク、AutoML Tables(Google Cloud が最適なモデルを自動的に探して作成)などがあります。
ここでは、XGBoost モデルを選択しています。ハイパーパラメータの調整をさほど必要とせずうまく機能し、モデルの説明可能性をある程度保つことができます。前のセクションのビューを使用して、わずか数行のコードでモデルをトレーニングできます。BigQuery ML では、インフラストラクチャの立ち上げについて心配する必要はありません。BigQuery が処理してくれるため、モデルの構築と使用に集中できます。
以下の CREATE MODEL 文では、XGBoost は取引カテゴリ、取引金額、ユーザー属性などのさまざまな特徴に基づいて、is_fraud(不正利用の場合は 1、そうでない場合は 0)を予測するようにトレーニングされています。
実際には、ユーザー属性や取引データを表面的に見ただけでは、強力な不正利用検出モデルを作成するには不十分かもしれません。包括的なアプローチを組み込むため、一定期間の取引頻度、取引量、取引額などのユーザーの過去の活動に対する追加の集約的特徴を利用する、別のモデルをトレーニングしました。
以下は、ユーザーの活動に関する履歴情報を集計するコードを一部抜粋したものです。完全なコードは Gitlab リポジトリにあります。
新たに作成した集約的な特徴を使用して、別の BigQuery ML モデルをトレーニングできます。
2 つのモデルでは、ML.EVALUATE を用いて F1 スコアを評価し、モデルの性能を比較できます。F1 スコアが高いほど、全体的なパフォーマンスが高いことを示しています。
過去のユーザー アクションの集約的な特徴を使用する第 2 のモデルが、はるかに優れたパフォーマンスを示していることがわかります。

Dataflow を使用したストリーミング データ上でのオンライン予測を目的とした BigQuery ML モデルをホストする
トレーニングされたモデルをエクスポートして、オンライン予測のためにホストすることができます。このチュートリアルでは、オンライン予測を行うために BigQuery ML モデルを Cloud AI Platform にエクスポートする方法を説明しています。このパターンで使われているコードは、こちらの Gitlab リポジトリにもあります。
デプロイされたモデルに取引のサンプルを送信し、その結果の予測を確認することで、オンライン モデルに対して簡単なテストを行うことができます。

Dataflow は、リアルタイム予測とバッチ推論の両方に使用できます。クレジット カード取引の場合、Dataflow パイプラインはリアルタイム データを継続的に取り込み、ユーザーの操作を必要とせず、取引量に基づいて自動的にスケールできます。
モデルが動作するようになったら、これをストリーミング Dataflow パイプラインに追加できます。つまり、このモデル推論の手順を追加することで、Dataflow に新たな着信取引がインポートされるとすぐに不正利用を検知できるようになります。
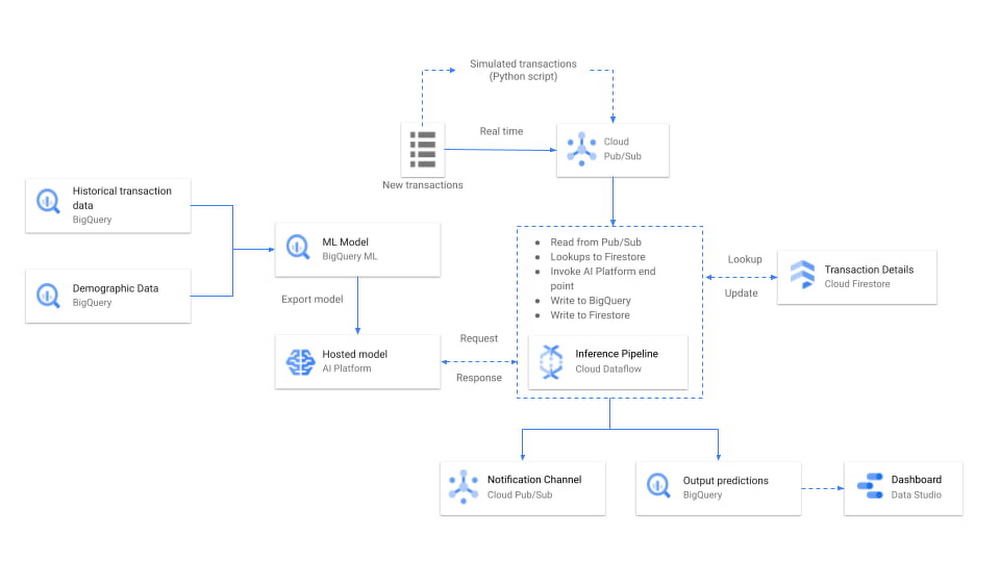
Cloud Dataflow を利用したストリーミング リアルタイム推論パイプラインを構築する
この手順では、Pub/Sub サブスクリプションから新しい取引を消費するストリーミング Dataflow パイプラインを構築し、AI Platform 上にデプロイされた ML モデルを呼び出して、モデル予測とともに BigQuery に取引を書き込む必要があります。
ここで得られた特徴に対しても、低レイテンシで算出された取引データが必要になります。そのため、モバイル、ウェブ、サーバー向けのデータを保存、同期する目的で構築された、柔軟でスケーラブルなサーバーレス NoSQL クラウド データベースである Cloud Firestore を使用しました。Firestore では、ユーザーごとに最新の取引のみを管理することで、必要に応じて迅速な検索や集計を簡単に行うことができます。つまり Dataflow パイプラインは、各ストリーミング取引に対して、Firestore 上のユーザーの最近の取引を検索し、そのユーザーについて(取引の量、頻度など)集計を行い、Firestore レコードを更新して、最新の取引のみを維持します。もちろんすべてのデータは引き続き BigQuery に保存されます。Firestore に保存されているクレジット カードの最近の取引の例を次に示します。
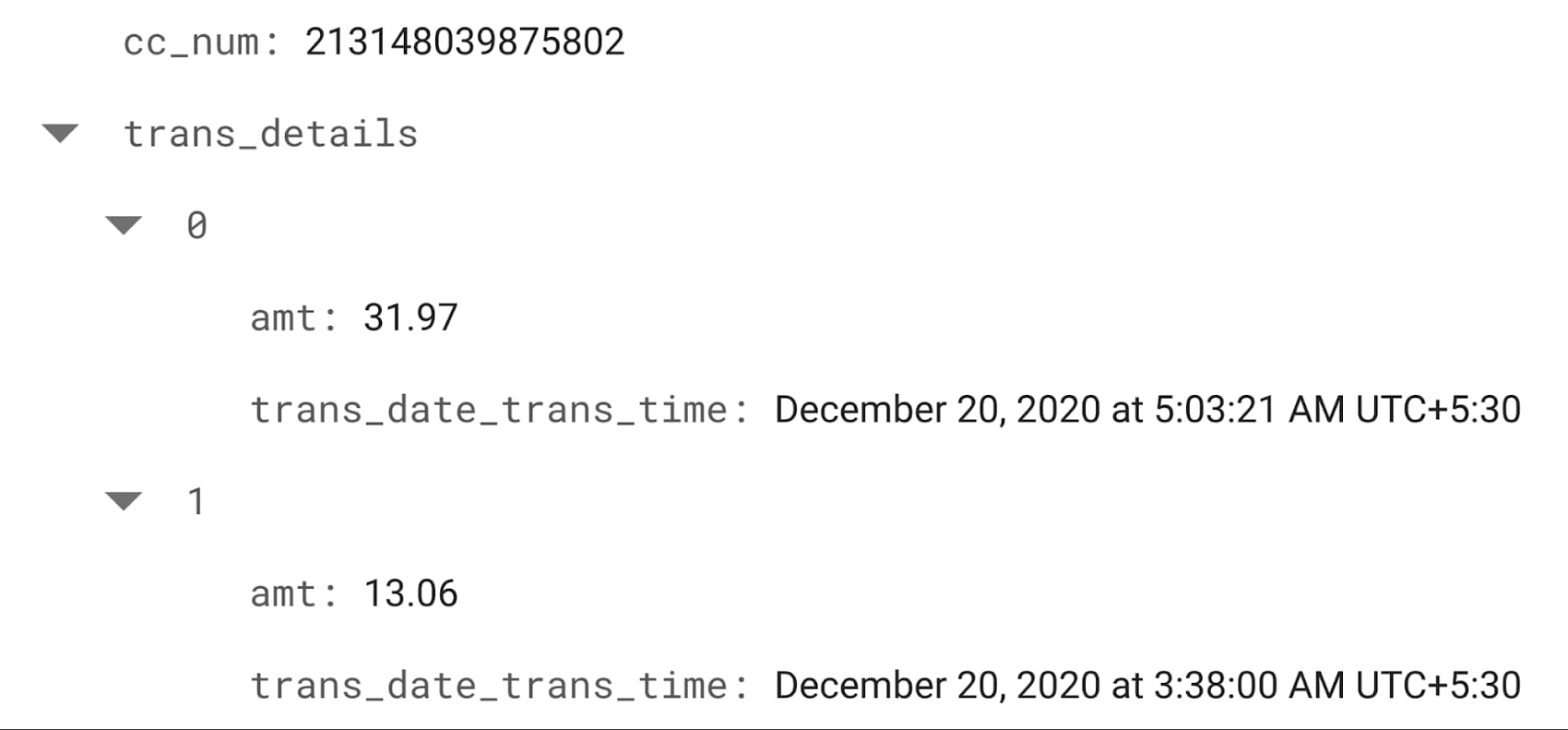
Firestore の代わりに、大規模な分析、オペレーション ワークロードに対応したフルマネージドの NoSQL データベース サービスである Cloud Bigtable を使用することもできます。ルックアップを実行するうえで膨大な量の取引が予想される場合は、Firestore の代わりに Bigtable の使用をご検討ください。
これで、ML モデルが動作するためのすべての依存関係をカバーできました。これらすべてを単一の Dataflow パイプラインに統合することで、新しい着信取引がリアルタイムで取り込まれた直後に不正利用を検出できるようになります。
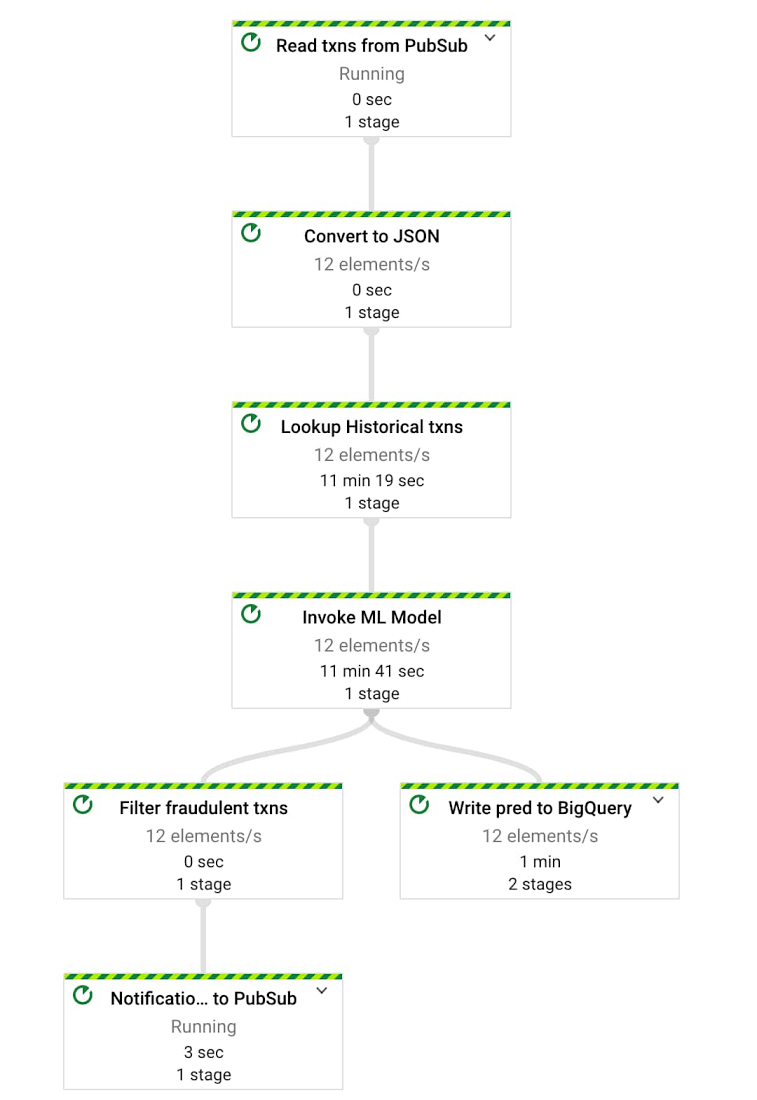
このパイプラインの作成に使用されるコードはこちらの Gitlab リポジトリにあります。
BigQuery と Pub/Sub を使ってリアルタイム データ シミュレーションを設定する
設定した Dataflow パイプラインをテストするため、Pub/Sub に取引を送信し、Python スクリプトを使用して実際のストリーミング取引のシナリオをシミュレートしました。Pub/Sub に取引を取り込む目的で使用した Python の完全なコードと、スクリプトが取引を生成するために使用した BigQuery テーブルは、こちらの Gitlab リポジトリにあります。Cloud Pub/Sub に取り込まれる新たな取引の例を以下に示します。
取引データは Dataflow を経て BigQuery テーブルに追加されます。そこですべての不正利用の予測が保存され、詳細な分析とダッシュボード化が可能になります。
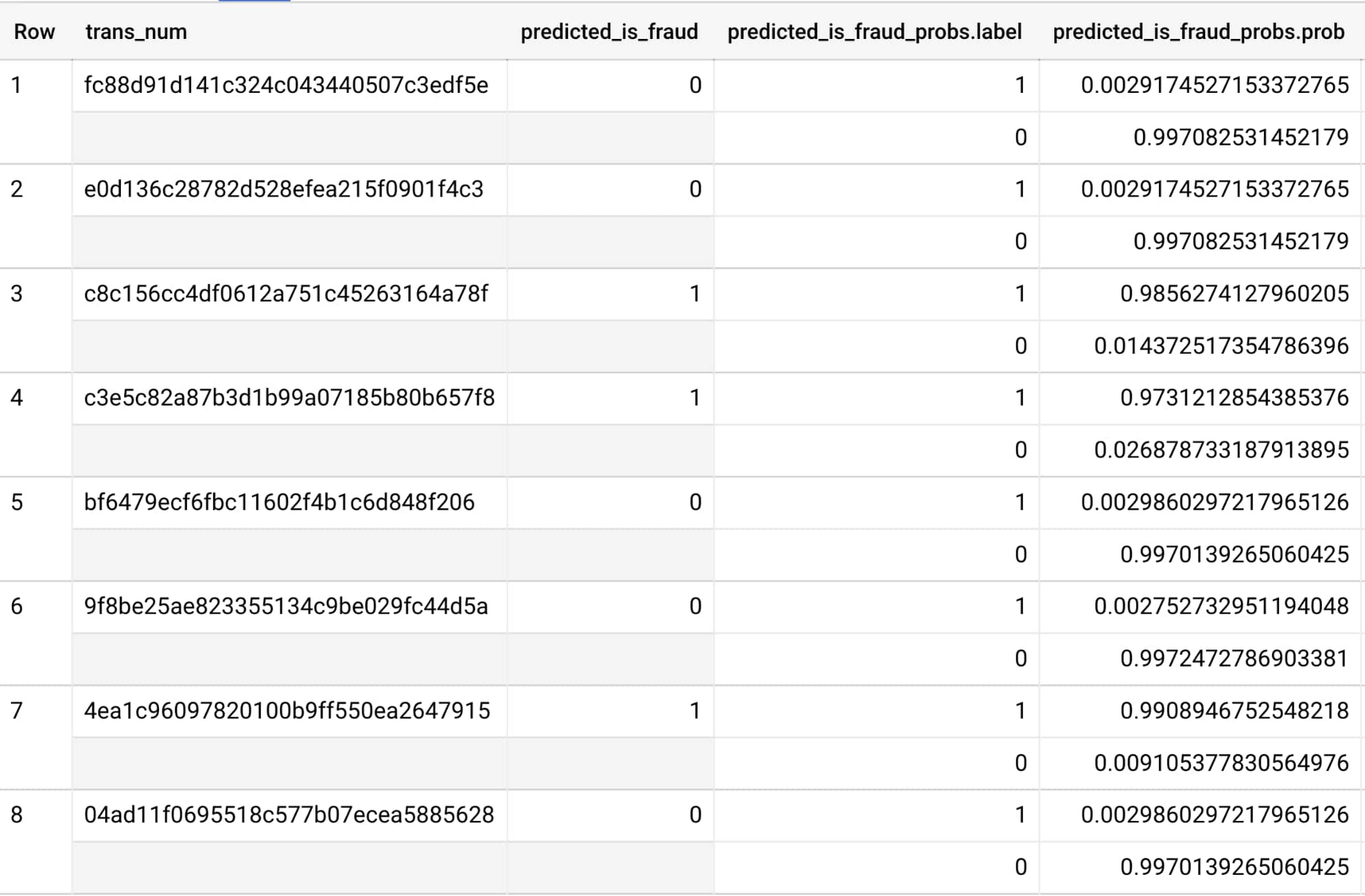
Dataflow パイプラインの自動スケーリング機能と Cloud AI Platform 上にデプロイされたモデルにより、取引の取り込みから BigQuery(予測の記録を保持)と Pub/Sub(ダウンストリームに通知)への ML 予測の出力まで、ストリーミング データフロー パイプライン全体でわずか数秒しか要しませんでした。そのため Quantiphi では、この設計パターンのレイテンシはほとんどのケースで顧客要求を満たすと判断しています。レイテンシを低減する方法はいくつかあります。まず、モデルを AI Platform 上でホストするのではなく、Dataflow ワーカー上に保存されたローカル バージョンのモデルを使用します。取引ごとにストリーム処理パイプラインでこれを直接呼び出して予測を行うことで、パフォーマンスの向上とレイテンシの低減を図ることができます(ドキュメント)。または、モデルを独自のエンドポイントとしてホストする場合、AI Platform モデルのマシンタイプをアップグレードしてノード数を増やすという方法もあります(ドキュメント)。
不正利用検知 Dataflow パイプラインが設定されたら、不正利用アラートの設定を行います。
Pub/Sub を使用してアラートベースの不正利用通知を設定する
不正利用が検出されたら、なんらかの下流のアクションをトリガーできるようにしておきます。例えば、70% を上回る確率で不正利用であることが予測される取引に対しては、Pub/Sub メッセージを送信する必要があります。その後、すべてのダウンストリーム サービスがアクティブに Pub/Sub メッセージをリッスンし、取引を開始したのが本当に本人であったかのかを顧客に確認するための通知をトリガーできます(Twilio を使用するなど)。取引が不正利用である可能性が非常に高い場合は、Pub/Sub メッセージを自動的にトリガーし、社内の不正利用防止チームに対してフラグを立てて取引を凍結するよう警告することも可能です。Dataflow と Pub/Sub パイプラインを使用すれば、これを数秒以内で行えるため、不正利用をリアルタイムで防ぐことができます。
トリガーベースのリアルタイム通知機能が実装されました。これで不正利用検知システムを稼働することができます。ただし、ビジネスの関係者やテクニカル チームは次の手順として、このパイプラインがビジネス全体にどのような影響を与えるか、どこに改善の余地があるかを把握する必要があります。
ビジネスおよびテクニカル オペレーション用のダッシュボードを作成する
オペレーション ダッシュボードは、チームがデータ パイプラインを監視し、全体的な不正利用の発生率を最小限に抑えるための、アクションにつながるインサイトを手に入れるうえで非常に役立ちます。データポータルを利用すると、BigQuery の顧客データや取引データを使ってインタラクティブなダッシュボードを素早く簡単に作成できるため、こうしたパターンのダッシュボードを作成するうえで有用です。よりリッチでマルチクラウドなビジネス インテリジェンス ソリューションを実現したい場合は、Looker の使用もご検討ください。今回必要なパターンを超えますが、Looker Blocks を使えば、Twilio のようなテキスト メッセージ サービスを直接トリガーできる不正利用検知ソリューションを構築することもできます。
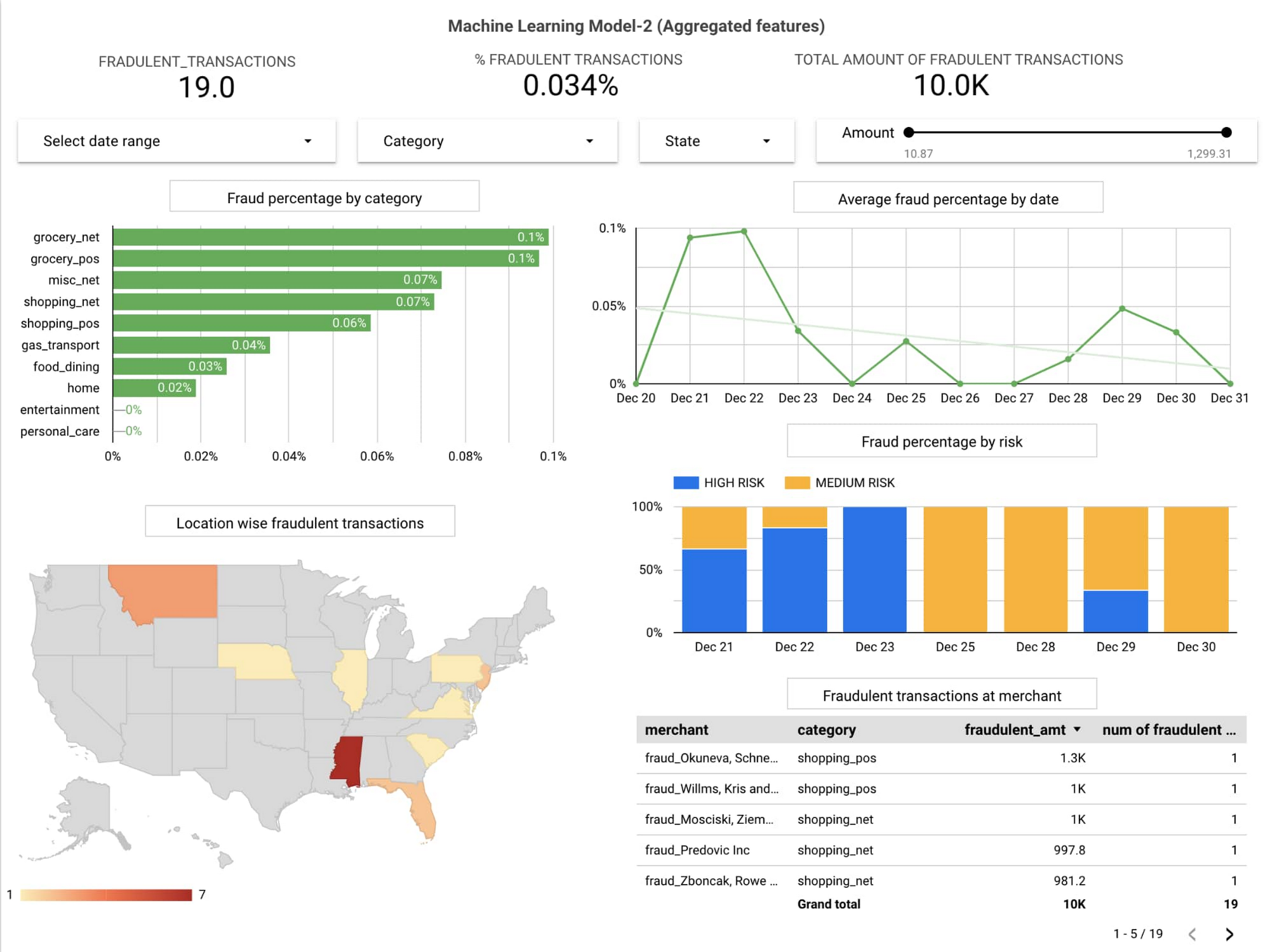
ビジネスの関係者は、全体的な不正利用率、ベンダー、顧客を監視することで、リスクを軽減するための積極的な対策を行うことができます。
データポータル上のビジネス ダッシュボードの例を次に示します。
実際のダッシュボードはこちらでご確認いただけます。
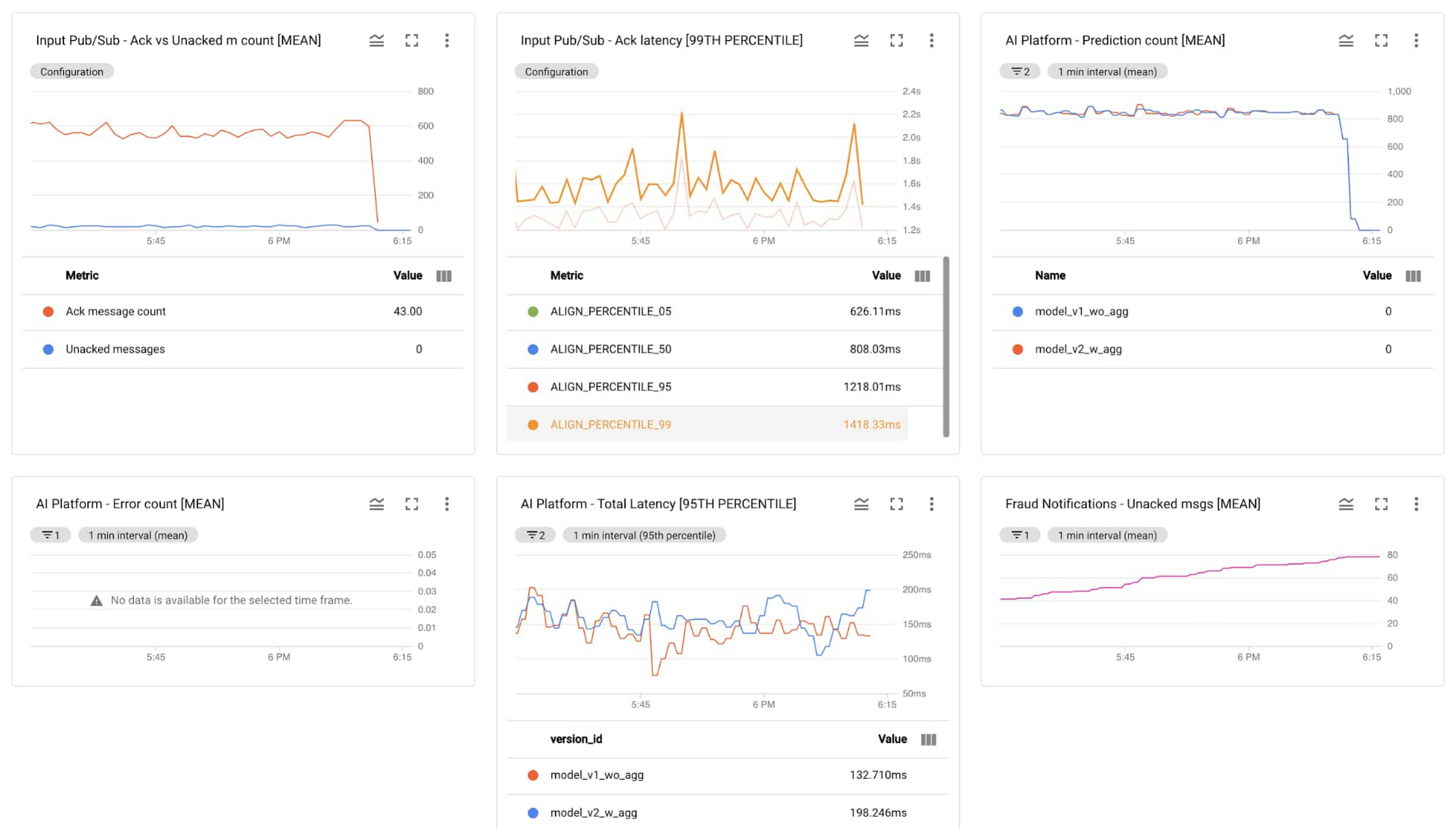
テクニカル チームは、新着取引をトラックし、パイプラインの健全性や個々のコンポーネントの出力をモニタリングし、出力通知チャネルを管理することができます。
Cloud Monitoring のデータをもとに構築されたテクニカル ダッシュボードの例を次に示します。
まとめ
金融機関の不正防止チームのメンバーであれ、不正利用による損失を削減したいと考えるオンライン小売ビジネスのオーナーであれ、ビジネスの根本的な目標を達成し、変化する環境に効率的に適応したいと考える方にとって、リアルタイムの ML ソリューションは非常に有効です。
Gitlab のコード
完全なコードはこちらの Gitlab リポジトリにあります。
https://gitlab.qdatalabs.com/uk-gtm/patterns/cc_fraud_detection/
Google Cloud 上でスマート アナリティクスを使用して不正利用検知ソリューションを構築するパターンのライブ チュートリアルを、3 月 25 日午前 9 時(太平洋夏時間)より行います。こちらからぜひご参加ください。同時に、予測モデルを最新状態に保てるよう、モデルの定期的な再トレーニングのスケジュールを設定する方法に関するデモも行います。チャットで Google Cloud のエキスパートに質問して回答してもらう機会もあります。
-デベロッパー アドボケイト Polong Lin
-Quantiphi シニア クラウド エンジニア Pavan Kattamuri