How to build a serverless real-time credit card fraud detection solution
Polong Lin
Developer Advocate
Pavan Kattamuri
Senior Cloud Engineer, Quantiphi
As businesses continue to shift toward online credit card payments, there is a rising need to have an effective fraud detection solution capable of real-time, actionable alerts. In collaboration with Quantiphi, an award-winning Google Cloud Premier Partner with experience engaging with global financial institutions, we developed a smart analytics design pattern that enables you to build a scalable real-time fraud detection solution in one hour using serverless, no-ops products on Google Cloud. In addition to setting up fraud notifications, we also show how you can build dashboards to monitor the performance of the fraud detection pipeline.

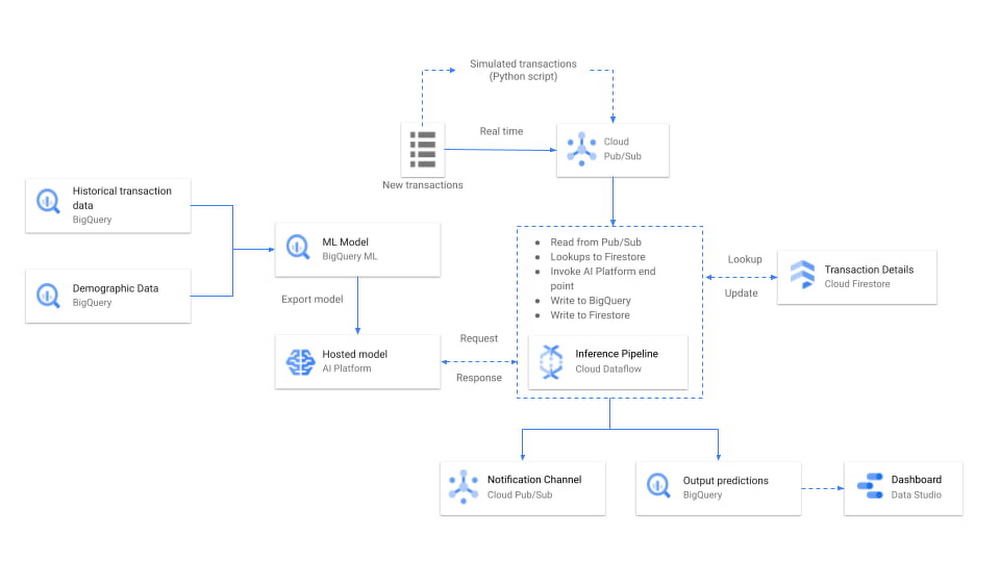
Because all of the Google Cloud products used in this solution are serverless and fully managed, this means you won't need to spend time setting up and maintaining infrastructure, enabling you to focus on getting the solution up and running in an hour. This blog post will be a technical dive into how the solution works:
Preparing the data on BigQuery
building the fraud detection model using BigQuery ML
hosting the BigQuery ML model on AI Platform to make online predictions on streaming data using Dataflow
setting up alert-based fraud notifications using Pub/Sub
creating operational dashboards for business stakeholders and the technical team using Data Studio
Preparing the data on BigQuery
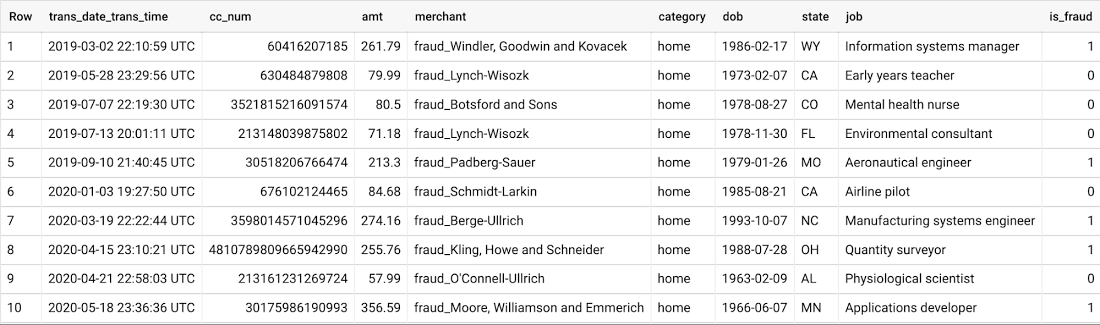
In this first stage, gathering the historical data on credit card transactions as training data is the most important step. We used the Sparkov data generator to store the credit card transactions and customer demographic data records into BigQuery.
The training data contains transaction details like the credit card number, transaction amount, merchant information, category, as well as customer demographics such as state, job, and date of birth. Note that in practice, you may want to consider using Cloud Data Loss Prevention to de-identify any sensitive data. The last column, is_fraud, is the label to be predicted via machine learning.
With data stored on BigQuery, it becomes easy to train machine learning models using BigQuery ML without needing to set up or procure infrastructure, saving time, money and complexity when productionizing the design pattern. So that you can follow along, the BigQuery table is made publicly available and you can follow the code from the Gitlab repo. If you're using your own dataset to follow along, you may want to consider shaping your data into a similar format at this point.
With the data prepared in BigQuery, we can then move on to building the machine learning fraud detection model.
Building the fraud detection model using BigQuery ML

With both transactional data and customer demographics data in BigQuery, we can train a model using SQL with BigQuery ML. You can choose from a variety of classification algorithms, including logistic regression, XGBoost, deep neural networks, or even AutoML Tables to have Google Cloud automatically search and create the best model for you.
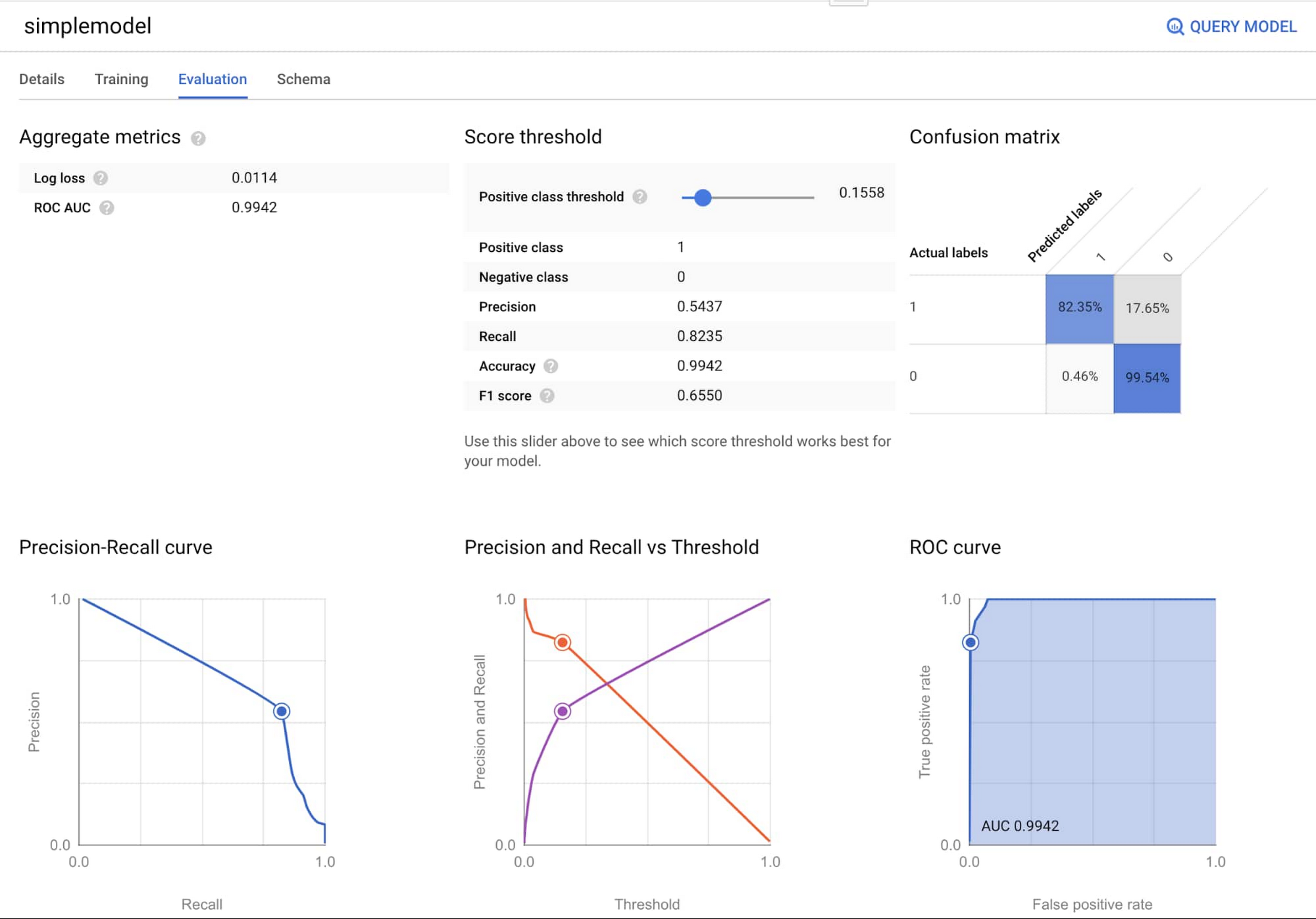
For this pattern, we opted for the XGBoost model, which worked really well because it didn't require much hyperparameter tuning to perform well, and it still retained some level of model explainability. Using the view from the previous section, you can train the model with just a few lines of code. Note that with BigQuery ML, you don't have to worry about spinning up any infrastructure -- BigQuery handles that for you so you can focus on building and using the model.
In the following CREATE MODEL statement, XGBoost is trained to predict is_fraud (1 if fraud, else 0) based on various features like transaction category, transaction amount and demographics.
In practice, just looking at demographics and transactional data superficially may be insufficient to produce a strong-performing fraud detection model. To incorporate a comprehensive approach, we trained another model that uses additional aggregate features around the users' historical activity, such as the transaction frequency, volume and value of transactions over a period of time.
The partial code below shows how to aggregate historical information on the user's activity. The full code can be found in the Gitlab repo.
Using the newly created aggregate features, you can train another BigQuery ML model:
With the two models, you can use ML.EVALUATE to evaluate the F1 scores to compare model performance, with a higher F1 score indicating better overall performance.
Indeed, we can see that the second model that uses aggregate features of historical user activity showed significantly better performance.

Hosting the BigQuery ML model for online predictions on streaming data using Dataflow
With the model trained, we can now export the model and host it for online predictions. To do so, you can follow this tutorial on how to export a BigQuery ML model to Cloud AI Platform for online prediction. You can also follow the code used in this pattern found in the Gitlab repo here.
To give the online model a quick test, we can submit a sample transaction to the deployed model and see the resulting prediction:

Dataflow can be used for both real-time predictions and batch inferences. In the case of credit card transactions, a Dataflow pipeline can ingest real-time data continuously and automatically scales based on the transaction volume without human involvement..
With the model working, we can now add this to the streaming Dataflow pipeline. In other words, adding this step of model inference will allow us to detect fraud as soon as new incoming transactions are ingested in Dataflow.
Building the streaming real time inference pipeline using Cloud Dataflow
In this step, we need to build a streaming Dataflow pipeline which consumes new transactions from a Pub/Sub subscription, invoke the ML models deployed on AI Platform and write the transactions along with model predictions to BigQuery.
For the derived features, we'll still need aggregate data computed in low latency. To this end, we used Cloud Firestore, which is a flexible, scalable, serverless NoSQL cloud database designed to store and sync data for mobile, web and servers. In Firestore, by maintaining only the most recent transactions per user, we can easily perform quick lookups and compute aggregations as needed. In other words, for each streaming transaction, the Dataflow pipeline does a lookup of the user's recent transactions on Firestore, computes the aggregations for that user (e.g., volume, frequency), and updates the Firestore record to only maintain the most recent transactions. Of course, the full data is still stored in BigQuery. Below is an example of recent transactions for a particular credit card stored in Firestore.
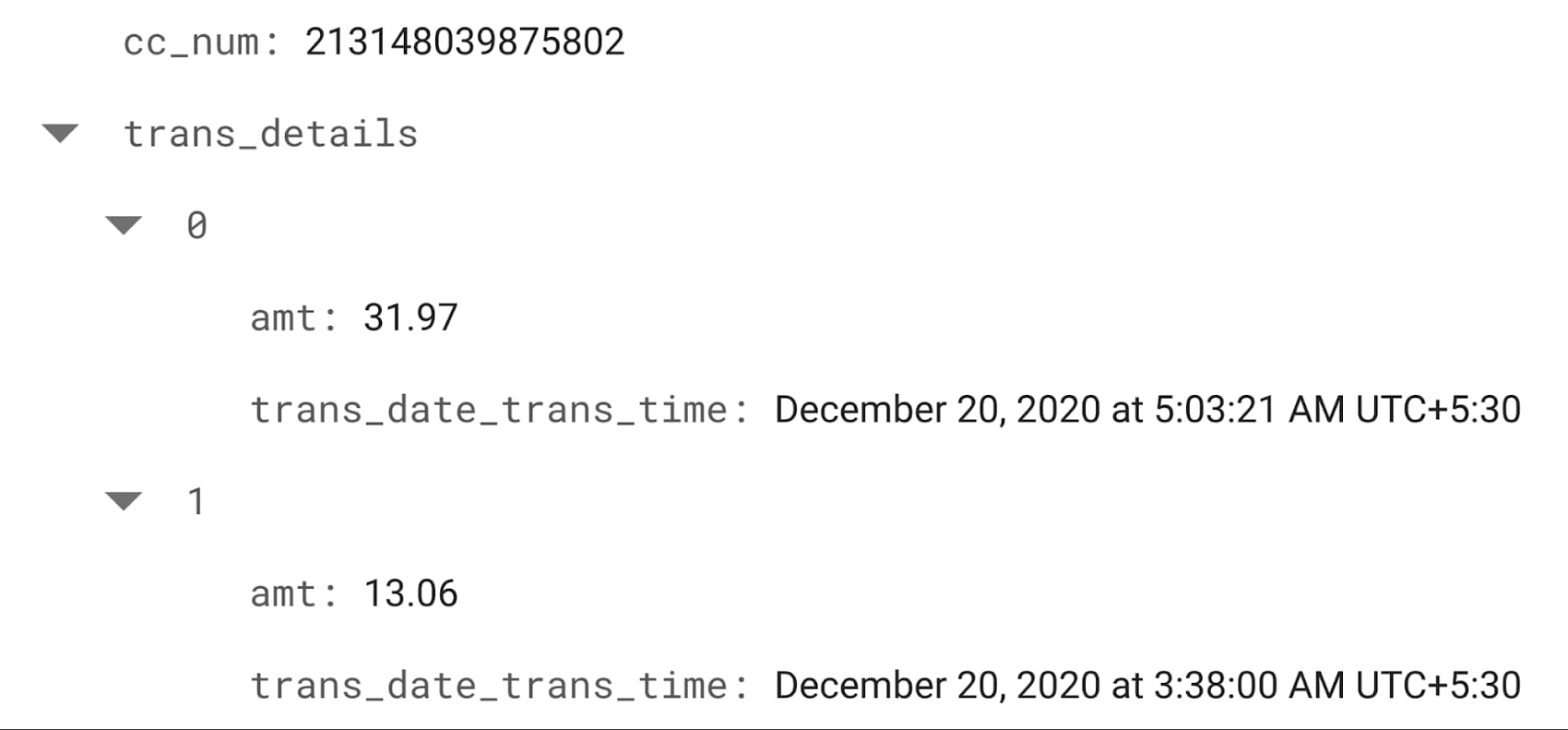
An alternative to Firestore here is Cloud Bigtable, which is a fully managed NoSQL database service for large analytical and operational workloads. If you expect significantly large volumes of transactions to perform lookups, you may want to consider using Bigtable in place of Firestore.
Now that we have all the dependencies covered for the ML models to work, we can integrate all of this into a single Dataflow pipeline which will allow us to detect fraud as soon as new incoming transactions are ingested in real-time.
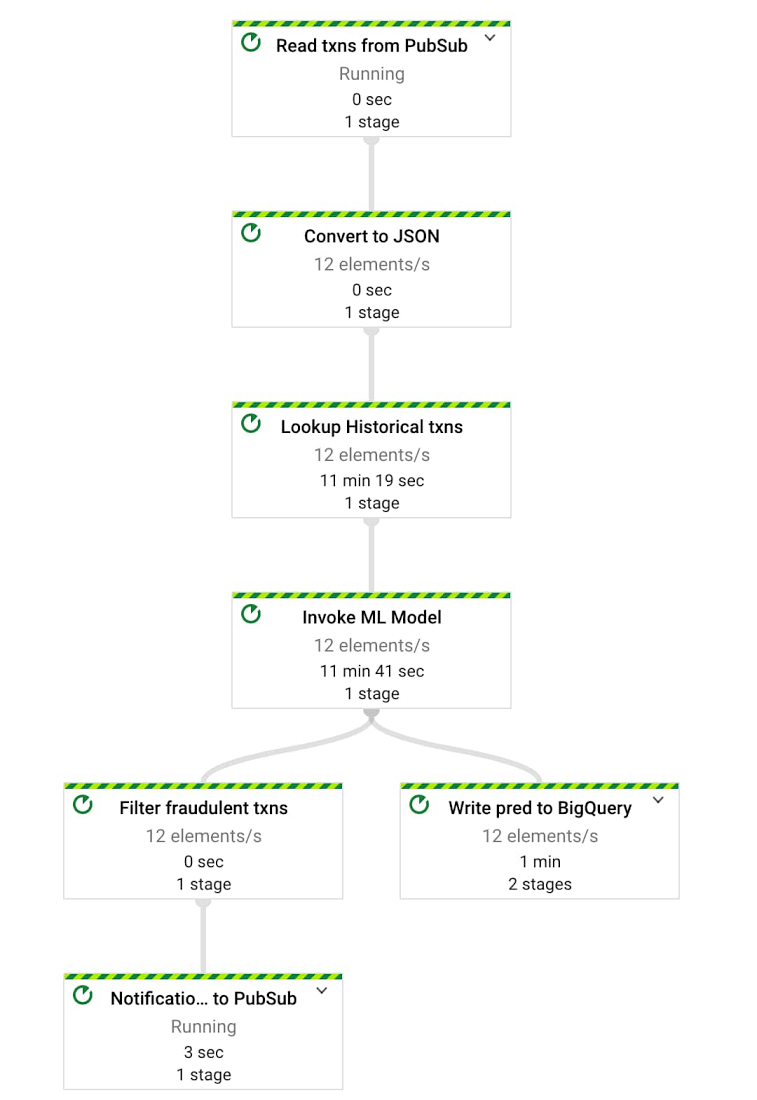
The code used to create this pipeline can be found in the Gitlab repo here.
Setting up real time data simulation using BigQuery and Pub/Sub
To test the Dataflow pipeline we set up, we used a Python script to simulate a real-world scenario of streaming transactions, by sending transactions to Pub/Sub. The full Python code used to ingest transactions into Pub/Sub, and the BigQuery table that the script draws from to generate the transactions can be found in this Gitlab repo. Below is a new sample transaction that gets ingested into Cloud Pub/Sub.
Once the transaction flows through Dataflow, it gets added to a BigQuery table that stores all of the fraud predictions for further analysis and dashboarding.
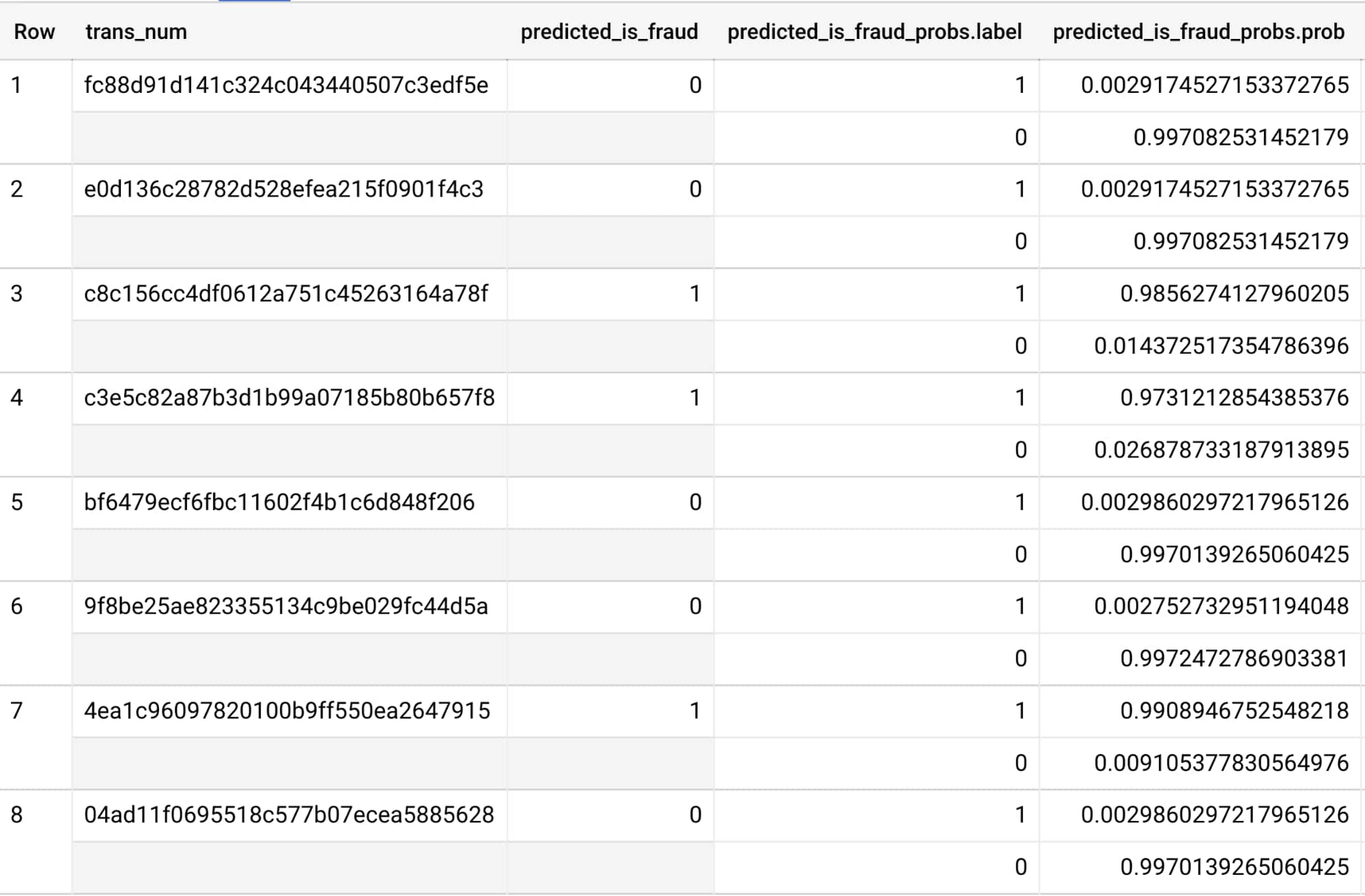
With the auto-scaling functionality of Dataflow pipeline and the model deployed on Cloud AI Platform, Quantiphi found that the streaming dataflow pipeline takes a few seconds end-to-end from the transaction ingestion to outputting the ML prediction to both BigQuery (to maintain a record of predictions) and Pub/Sub (for downstream notifications). Quantiphi observes that the latency in this design pattern typically falls in line with customer requirements. To decrease latency, there are a few ways. First, instead of hosting the model on AI Platform, you can use a local version of the model saved on Dataflow workers and call it directly for prediction during the stream processing pipeline for each transaction, which can improve performance and reduce latency (documentation). Alternatively, if you still want to have the model hosted as its own endpoint, you can try to upgrade the machine type of the AI Platform model and increase the number of nodes (documentation).
With the fraud detection Dataflow pipeline in place, the next step would be to set up fraud alerts.
Setting up alert-based fraud notifications using Pub/Sub
We also want to make sure we can trigger some downstream action when fraud is detected. For example, if a transaction is predicted to be fraud with a probability of greater than 70%, then it should send a Pub/Sub message. Then, any downstream service can actively listen to the Pub/Sub message and trigger notifications (for example, using Twilio) to confirm with the customer whether or not it was indeed them that initiated the transaction. Alternatively, if the transaction has a very high probability of fraud, the Pub/Sub message could also automatically trigger and alert an internal anti-fraud team to flag and freeze the transaction. Of course, with a Dataflow and Pub/Sub pipeline, this can happen within seconds, so fraud can be prevented in real-time.
With the trigger-based real-time notifications in place, the fraud detection system should now be up and running. But for business stakeholders and the technical team, the next step is understanding how this pipeline is affecting the business and where the pipeline could improve.
Creating dashboards for business and technical operations
Operational dashboards are very helpful as they can help teams keep an eye on the data pipeline and provide some actionable insights to further minimize the rate of fraud overall. The dashboards created in this pattern use Data Studio, which is a quick and easy way of creating interactive dashboards using the customer and transactional data on BigQuery. More mature businesses may also want to consider Looker for a richer, multi-cloud business intelligence solution. Although beyond the scope of this pattern, with Looker Blocks, you can also have your fraud detection solution directly trigger text message services like Twilio.
For the business stakeholder, keeping an eye on overall fraud rates, vendors & customers can help them to enable proactive counter measures to mitigate the risk
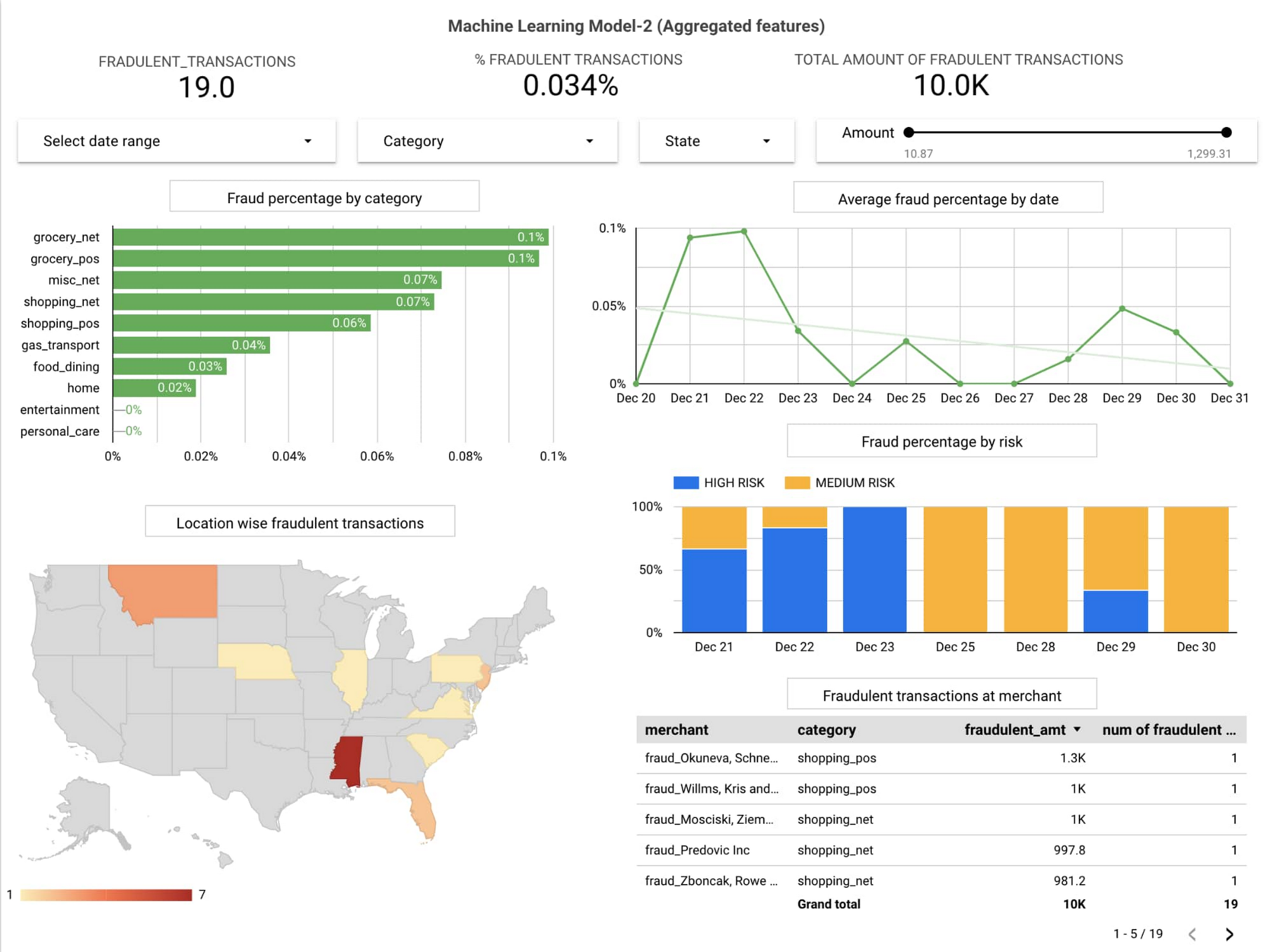
Below is the sample of the business dashboard on Data Studio:
For the technical team to monitor the health of the pipeline, track the incoming transactions, monitor the output from individual components and supervise the output notification channel
Below is the sample of the technical dashboard built on Cloud Monitoring data:
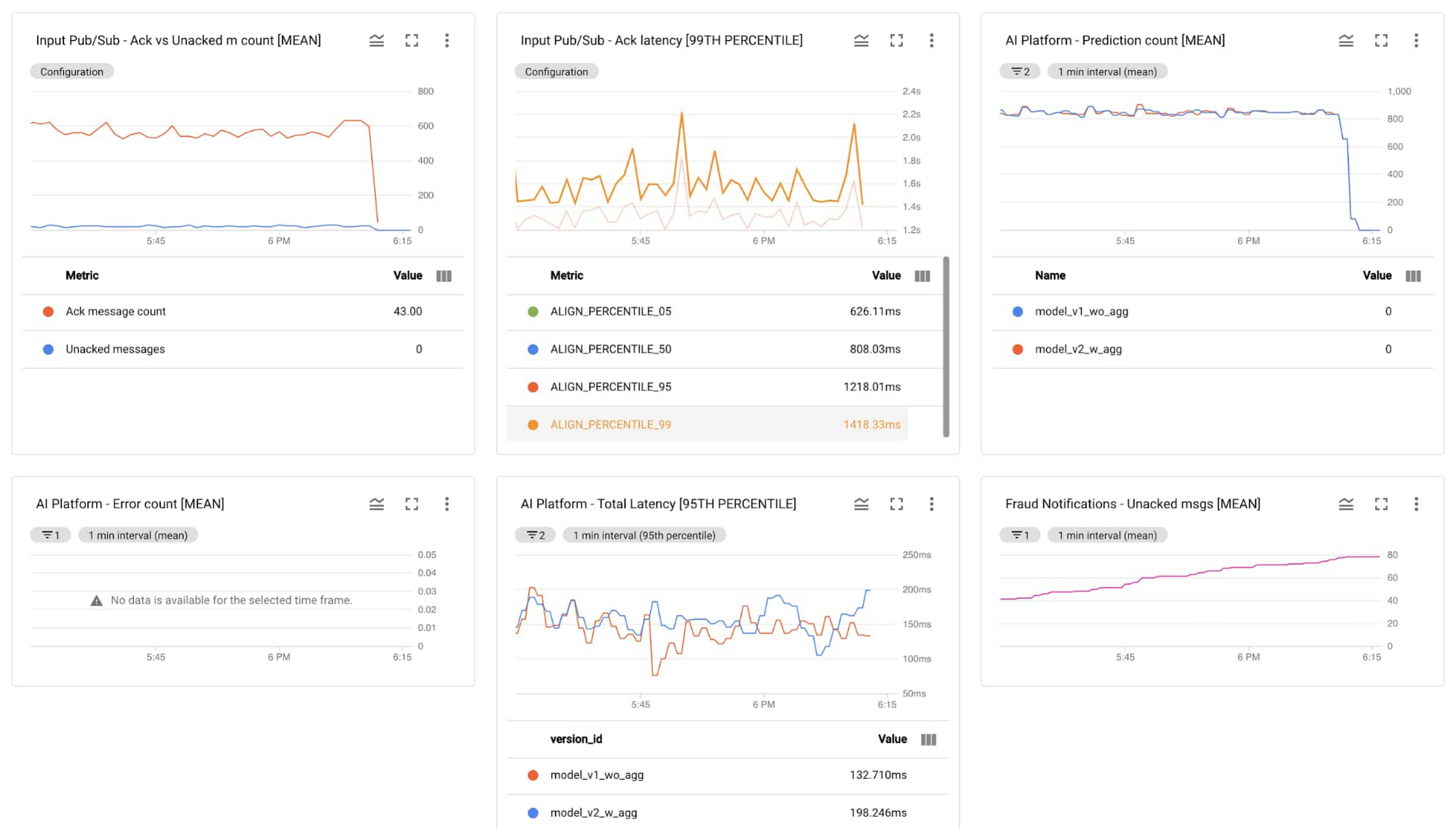
Summary
Whether you are part of the fraud protection team in a financial institution or an online retailer trying to reduce fraudulent losses, real time ML solutions are most impactful when they serve the ultimate business goals and efficiently adapt to the changing environment.
Code on Gitlab
You can find the full code in this Gitlab repo:
https://gitlab.qdatalabs.com/uk-gtm/patterns/cc_fraud_detection/
Join us on March 25 at 9am PDT for a live walkthrough of this pattern on how to build a fraud detection solution using smart analytics on Google Cloud. We’ll also demonstrate how to schedule model retraining on a regular basis so your forecast models can stay up-to-date. You’ll have a chance to have their questions answered by Google Cloud experts via chat.

