Google Cloud が ADAM と THOR による小惑星の探査を支援

Google Cloud Japan Team
※この投稿は米国時間 2022 年 5 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
小惑星は、太陽の周りを回る比較的小さな天体です。小惑星自体が興味深い天体であることはもちろん、太陽系の構成と形成の理解を深めるため、そして、小惑星が近いうちに私たちの暮らす地球に接近しすぎないことを確かめるためにも、その位置と軌道を把握することは非常に価値のあることです。
小惑星は小さいので確認しづらく、多くの摂動の影響を受けるため、理想的なケプラー軌道とはかけ離れたものになることがよくあります。このような天体を発見して追跡するためには、最も高性能な望遠鏡を使って、長い時間をかけて専門的な調査を行う必要があります。
小惑星研究所は、Google Cloud の協力を得て、既存のデータセット内に隠れている小惑星を発見する新しい方法を見つけました。これらの小惑星を発見できなかったのは、見えないからではなく(既存の空の観測画像にはずっと存在しています)、今まではこうしたデータセット内にある小惑星を認識するコンピューティング能力がなかったためです。
Google Cloud は、非営利団体 B612 財団のプログラムである Asteroid Institute の研究者と協力して、最新のクラウド コンピューティング ツールやアルゴリズムをディープ フィールドのスカイサーベイに適用し、太陽系内の小惑星の発見とマッピングを行っています。Asteroid Institute は本日、この新しい手法で 104 の新しい小惑星を発見し、確認したと発表しました。この手法を使うことで、古いデータセットに隠れている何百、何千もの新しい小惑星を発見できる可能性が開けただけでなく、新しい望遠鏡による小惑星の探索方法も変わっていきます。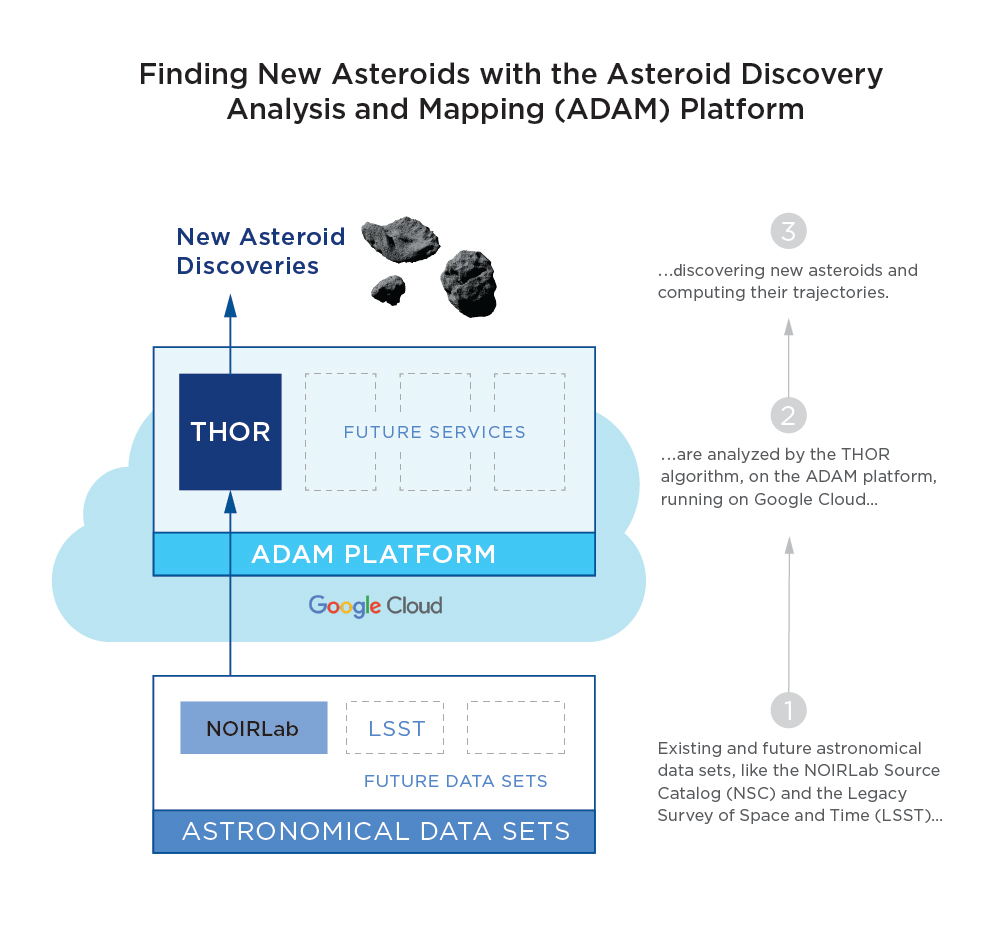
Asteroid Institute のエグゼクティブ ディレクターで元 NASA 宇宙飛行士の Ed Lu 博士は、Google バイス プレジデント兼チーフ インターネット エバンジェリスト Vint Cerf との対談で、小惑星を発見するための新しいコンピューティングの手法について次のように語っています。「私たちはコンピューティングによって小惑星を発見する新しい手法を実証しました。小惑星センターは、新しく発見されたこれらの小惑星を確認し、登録しました。Asteroid Institute が支援する研究者たちがさらに数千もの新しい発見を提出する道が開かれたのです。これは以前にはなかったことでした。これまでの手法では特定の望遠鏡を使ったサーベイ操作に依存していたからです。代わりに、膨大なコンピューティング能力を駆使して小惑星を特定、追跡できるようになりました。」
ADAM と THOR: 共に空を探索する
Asteroid Institute では、太陽系内の小惑星を探索するために、Asteroid Discovery Analysis and Mapping(小惑星検出分析およびマッピング、ADAM)と呼ばれるクラウドベースの軌道力学プラットフォームを採用しています。ADAM は、Google Cloud で軌道力学のアルゴリズムを膨大な規模で実行するオープンソースのコンピューティング システムです。
これらの新しい小惑星の発見に使用される新しいアルゴリズムは、Tracklet-less Heliocentric Orbit Recovery(トラックレットレスの太陽周回軌道回復、THOR)と呼ばれます。このアルゴリズムは、異なる空の画像から、小惑星の軌道と一致する光の点を結びつけます。小惑星の軌道を計算するためには、小惑星をある程度の時間の範囲内で複数回観測することが必要です。THOR による小惑星の識別と軌道計算は、小惑星センターが追跡観測された小惑星として認定するための基準を満たします。
最初のデモンストレーションでは、Asteroid Institute とワシントン大学の研究者らが、2012 年から 2019 年の間にアメリカ国立光学天文台の望遠鏡で撮影された約 680 億の観測データを集めた NOIRLab Source Catalog(NSC)から、30 日間の画像を検索しました。
小惑星の発見と追跡が困難な問題である理由はいくつかあります。宇宙は巨大です。それは見るべき場所がわかっていても同様です。太陽系の惑星や遠くの恒星に比べると、相対光度(天体の固有の明るさ)が低くなります。また、地球と小惑星は、どちらも太陽系内で常に移動しています。異なる空の画像をデータの過去のシグナルに関連付けることで変数が増え、大規模なデータセットを扱う場合、全体の作業の計算コストは非常に高額となります。
研究者たちは 2021 年 5 月の THOR 紹介の論文で、「第一に、小惑星の検出を複数日にわたって関連付けることは、潜在的な関連付けの数が非常に多いために難しく、偽陽性の存在によってさらに困難になります。第二に、小惑星は数週間のうちに天球上で高次の秩序運動を示すため、観測者の動きによって関連付けの問題が非線形になります」と説明しています。
これまでの小惑星探査は、空の同じ場所を約 1 時間以内に複数回撮影する必要がありました。その場合小惑星がわずかな距離しか移動せず、トラックレットと呼ばれる小惑星のつなぎ合わせを行いやすくなるためです。その後、より長い期間(1 週間以上)にわたって複数のトラックレットが撮影されれば、軌道を判断できます。しかし、望遠鏡の観測パターンにこのような制約があることで、ほとんどの天文データセットは小惑星の検出に不適格となっていました。THOR では、データ内の小惑星のトラックレットに依存する必要がなくなります(だから「トラックレットレス」なのです)。非常に狭い間隔での観測という制約が緩和され、小惑星が天空を横断する距離にかかわらず観測できるようになりました。THOR では、一連のテスト軌道を想定し、天空画像をそれらのテスト軌道のフレームとして変換することで、これらの遠距離観測を関連付けることができます。
「これにより、膨大な 6 次元位相空間を有限数のテスト軌道を使用して実現可能なコンピューティング費用でスキャンする道が開かれました」と研究者は論文に記述しています。
THOR 手法の主な利点の一つとして、1 つの天体サーベイのスコープを超えたデータセットに使用できることが挙げられます。これにより、多種多様なデータセットを調査して、それらを関連付ける可能性が広がります。このように、THOR は観測者(望遠鏡の調査データ)とは独立したエージェントとなり、異なる時間の異なるデータセット間の関連付けを行うことができます。それだけでなく、THOR を使えば、将来の小惑星探査望遠鏡を、より効率的な頻度で(つまり、同じ天域を何度も撮影する必要なく)観測できるように設計できます。
THOR の興味深い点の一つは、機械学習やニューラル ネットワークをベースにしていないことです。THOR のメリットは、テスト軌道からデータを取り、統計学と物理学を、線形およびクラスタリングのアルゴリズムを通して適用し、クラウドを通して膨大なコンピューティング能力を使うことにあります。今後、機械学習が応用できる分野は、DeepMind の AlphaGo アルゴリズムが碁盤上で非常に多くの可能性の中から次に打つべき手を効率的に決定するのと同じように、無限に可能性のある軌道をよりスマートに迅速に検索する分野です。
Google Cloud を使用した ADAM のスケーリング
THOR は、Google Cloud を利用した Asteroid Institute の Astrodynamics-as-a-Service(サービスとしての軌道力学)プラットフォームである ADAM 上で動作します。このプラットフォームには、Compute Engine、Cloud Storage、Google Kubernetes Engine のスケーラブルなコンピューティング機能とストレージ機能が搭載されています。
2019 年と 2020 年、Google Cloud の CTO オフィスは、Google Cloud のソリューション アーキテクトとともにアーキテクチャ セッションを実施し、ハッカソンを開催して、Google Cloud に ADAM を大規模に実装するための最適な方法を探りました。また、Google Cloud は、ADAM プラットフォームの現在の開発および将来の作業に対して、Cloud クレジットとテクニカル サポートも提供しました。
「さらに開発を進めれば、このソフトウェア エコシステムの可能性は過去のデータをはるかに超えるものになります。ADAM と THOR の組み合わせにより、世界中の望遠鏡から送られてくる観測データをもとに、リアルタイムで小惑星を発見することが可能になるでしょう」と THOR の共同開発者で Asteroid Institute フェローの Joachim Moeyens 氏は言います。
THOR は既存の天文学的データセットの掘り起こしをコンピューティングの点で実現可能にしますが、連続した軌道を探索するためのデータが膨大な空間から構成されていることを考慮することが重要です。検索が必要な軌道の候補は依然として非常に多いため、パブリック クラウドならではのストレージ容量やコンピューティング リソースが必要です。元の天文データは Google Cloud Storage に保存され、調整されたデータはその後 BigQuery に抽象化されます。Google Cloud は、ADAM を数千台のマシンで同時に動作させることでスケーリングを実現し、合理的な時間でデータを分析することを可能にします。
B612 と Google Cloud がパートナーシップを組むことには、ADAM を「Discovery-as-a-Service(サービスとしての検出)」プラットフォームにして将来の研究者たちが利用できるようにするという非常に優れた一面があります。
「パブリック クラウドの登場により、研究者は必要なときに必要なだけの大規模なコンピューティング リソースを、全体的な費用と時間を大幅に削減しながら利用できるようになりました。そして実際に、大規模なデータセットが新たな問題に適用できることがわかってきています」と Vint Cerf は話します。

- Google Cloud AI 応用担当上級テクニカル ディレクター Massimo Mascaro
- Google Cloud AI 応用担当ディレクター Scott Penberthy