BigQuery DataFrames で生成 AI を使用してお客様のフィードバックを有効活用する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 12 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
ビジネスを成功に導くには、お客様のニーズを詳細に把握し、フィードバックから貴重な分析情報を抽出することが重要です。しかし、お客様のフィードバックから実用的な情報を抽出する作業は簡単ではありません。フィードバックを調査し分類することでお客様が製品に関して抱えている主な問題点を特定できますが、フィードバックの分量が増加するにつれ、この作業が次第に困難になり、膨大な時間を費やさなければならなくなっていきます。
Google Cloud に追加された新しい生成 AI 機能と ML 機能をいくつか利用することで、この問題に対するスケーラブルなソリューションを構築できます。このソリューションにより、お客様のフィードバックが構造化されていない場合でもフィードバックから有用な情報を引き出し、優先して対処すべき製品の問題点を特定することが可能になります。
今回のブログ投稿では、未加工のお客様フィードバックを実用的なインテリジェンスに変換するソリューションの構築例をご紹介します。
このソリューションでは、大量のフィードバック データセットを分類(またはクラスタ化)して、各論理セグメントに関連付けられたナラティブを要約します。今回は BigQuery 一般公開データセットとして利用可能な CFPB Consumer Complaint Database のサンプルデータを使用します。このデータセットは消費者向け金融商品およびサービスに関する苦情を収集したもので、多様なフィードバックのコレクションを非構造化形式で表しています。
このソリューションを構築するために、Google Cloud の以下の中核的な機能を使用します。
- text-bison 基盤モデル: 大量のテキストとコードのデータセットでトレーニングされた大規模言語モデル。このモデルで、テキストの生成、言語の翻訳、さまざまな種類のクリエイティブ コンテンツの作成、あらゆる種類の質問への回答に対応できます。Vertex AI の生成 AI に含まれています。
- textembedding-gecko モデル: ML アルゴリズム、特に大規模モデルで処理可能な数値ベクトルにテキストデータを変換する NLP 手法。これらのベクトル表現は、対象となる単語の意味論的意味とコンテキストを取り込むように設計されています。これも Vertex AI の生成 AI に含まれています。
- BigQuery ML K 平均法モデル: データの分類のためのクラスタリング モデル。K 平均法は教師なし学習にあたるため、モデルのトレーニングを行う際にラベルは必要なく、トレーニングや評価用にデータの分割を行う必要もありません。
これらの ML および生成 AI オペレーションの実行には BigQuery DataFrames を使用します。BigQuery DataFrames はオープンソースの Python クライアントであり、人気の高い Python API をスケーラブルな BigQuery SQL クエリと API 呼び出しにコンパイルすることで、BigQuery と Google Cloud の操作を簡素化します。
データ サイエンティストは、BigQuery DataFrames を使用して Python コードを BigQuery のプログラム可能なオブジェクトとしてデプロイすることで、データ探索から本番環境のアプリケーションに移行できます。同時に、データ エンジニアリング パイプライン、BigQuery ML、Vertex AI、LLM モデル、Google Cloud サービスとの統合も実現できます。ここでは ML のユースケースをご紹介しますが、サポートされているその他の ML 機能の詳細もご確認ください。
フィードバックの分類と要約のためのソリューションの構築
ソリューションの構築を一緒に進めたい方は、ノートブック Use BigQuery DataFrames to cluster and characterize complaints をコピーしてください。これにより、ご自身の Google Cloud プロジェクトを使用して Colab でこのソリューションを実行できるようになります。
データの読み込みと準備
BigQuery DataFrames を使用するには、その pandas ライブラリをインポートし、Google Cloud プロジェクトと使用される BigQuery セッションの場所を設定する必要があります。
次に、read_gbq メソッドを使用して CFPB Consumer Complaint Database テーブル全体が含まれる DataFrame を作成します。
データの操作と変換のために、この DataFrame で通常どおりに bigframes.pandas を使用できます。ただし、計算はローカル環境ではなく BigQuery クエリエンジンで実行されます。BigQuery DataFrames では 400 種類以上の pandas 関数がサポートされています。その一覧についてはドキュメントをご覧ください。
このソリューションで変換を行うために、元の苦情を非構造化テキストとして含む DataFrame の consumer_complaint_narrative 列を分離し、dropna() を使用してフィールドに NULL 値を含むすべての行を破棄します。
結果として生成される DataFrame のいくつかの行のスニペットを見てみましょう。

次に、現時点で 100 万以上の行を含む DataFrame を 1 万行サイズにダウンサンプリングします。ダウンサンプリングはトレーニング時間の削減に役立ち、これによりノイズが多いデータポイント、つまり外れ値のデータポイントの影響を緩和できます。
テキスト エンベディングの作成
非構造化テキストデータをクラスタ化する場合、クラスタリング モデルを適用する前にテキストをエンベディング、つまり数値ベクトルに変換する作業が不可欠です。BigQuery DataFrames に PaLM2TextEmbeddingGenerator として用意されている text-embedding-gecko を使用すれば、これらのエンベディングを作成できます。
次のコードでは、このモデルをインポートし、DataFrame の各行のエンベディングを作成するために使用しています。これにより、エンベディングと元の非構造化テキストの両方を含む新しい DataFrame が生成されます。
K 平均法モデルのトレーニング
1 万件の苦情を表すテキスト エンベディングを用意できたので、次に K 平均法モデルをトレーニングします。
K 平均法クラスタリングとは、事前に定義した数のクラスタに一連のデータポイントをパーティション化することを目的とした一種の教師なし ML アルゴリズムです。このアルゴリズムは、データポイントと各クラスタの中心との間の距離全体を最小化する一方でクラスタ間の分離を最大化することで、データポイントを個別のクラスタにまとめようとします。
K 平均法モデルは、bigframes.ml パッケージを使用して作成できます。次のコードでは、K 平均法モデルをインポートし、クラスタ数のパラメータに 10 を指定してエンベディングでモデルをトレーニングしてから、このモデルを使用して DataFrame の各苦情のクラスタを予測しています。
結果を見てみましょう。clustered_result という DataFrame で 1~10 の ID を示す列が追加されました。この数字は、各苦情が属す意味的に類似したグループを示しています。
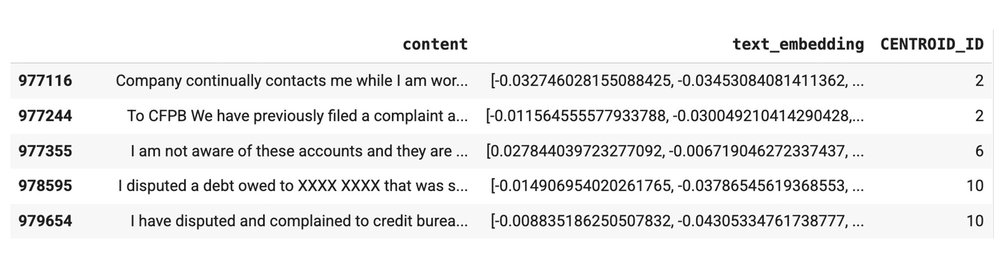
このソリューションではクラスタ数を 10 にしましたが、この数字は調整できます。K 平均法モデルごとの最適なクラスタ数の決定方法については、こちらのチュートリアルをご覧ください。
LLM モデルのプロンプト作成
これで、苦情を 10 個のグループにクラスタ化することができました。しかし、各クラスタ内の苦情の間にはどのような違いがあるのでしょうか。これらの相違点については、大規模言語モデル(LLM)に説明してもらうことができます。ここで、LLM を使用して 2 つのクラスタ間で苦情を比較する例をご紹介しましょう。
最初のステップは、LLM 向けの質問、いわゆるプロンプトを準備することです。この場合は、クラスタ #1 と #2 からそれぞれ 5 件の苦情を集めてリスト化し、2 つのリストの間の最も明白な相違点を指摘するよう LLM に依頼するテキスト文字列と結合します。
作成されるプロンプトの構造は次のようになります。

プロンプトの準備ができたら、bigframes.ml パッケージにある PaLM2TextGenerator を使用して text-bison 基盤モデルにこのプロンプトを送信します。
このソリューションを実行すると、LLM モデルから次のような応答が返されます。
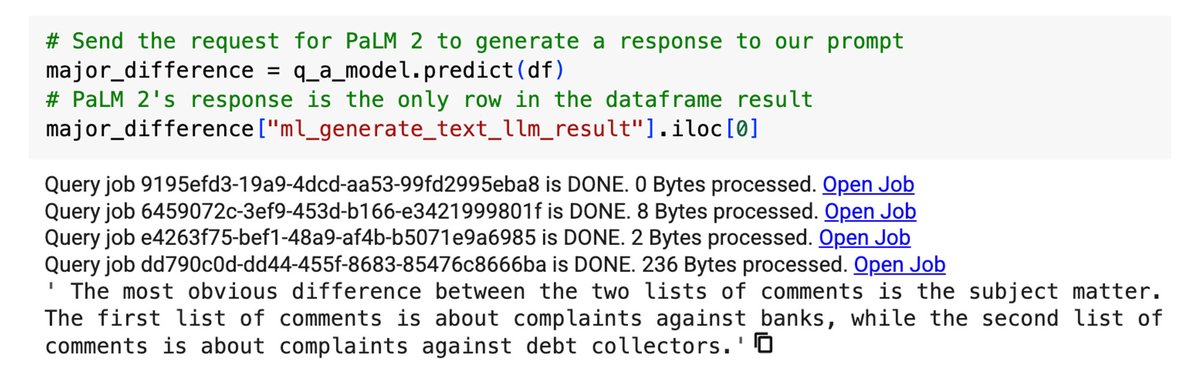
この LLM モデルで、2 つのクラスタの相互関係と相違点をわかりやすく的確に評価できました。このソリューションを拡張し、すべてのクラスタの苦情に関する分析情報と要約を提供することもできます。
次のステップ
これで完了です。BigQuery DataFrames で NLP(自然言語処理)と ML を利用して、お客様のフィードバックを把握するためのソリューションを構築できました。
まず、テキストを数値ベクトルに埋め込んで苦情の意味論的意味を取り込みました。次に、K 平均法クラスタリング アルゴリズムを使用して、埋め込まれた表現に基づいて類似した苦情をグループ化しました。最後に、LLM(大規模言語モデル)を使用して各クラスタを分析し、各グループ内の苦情の概要を示しました。このアプローチにより、苦情に共通のテーマやパターンを効果的に特定し、提起されている問題の本質に関する貴重な分析情報を入手できるようになりました。
BigQuery DataFrames の詳細と導入方法については、クイックスタート ドキュメントをご覧ください。
ー Google、ソフトウェア エンジニア Ashley Xu
ー Google Cloud、デベロッパー アドボケイト Alicia Williams
