SCIO を使用して Scala で高度な Beam パイプラインを構築する
Google Cloud Japan Team
※この投稿は米国時間 2022 年 11 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Beam は、オープンソースの統合型プログラミング モデルで、データ処理ワークフローを定義および実行する言語別の SDK セットを提供しています。Scio(シーオと発音)は、Spotify が開発した Beam 用の Scala API で、バッチ パイプラインとストリーミング パイプラインの両方を構築できます。
このブログでは、SCIO の必要性といくつかのリファレンス パターンをご紹介します。
Scio を選ぶ理由
開発者に上位レベルの抽象化を提供している SCIO は、次のような理由で選ばれています。
簡潔さとパフォーマンスのバランスが良い。Scala で記述されたパイプラインは java と比較すると、簡潔でありながら同様のパフォーマンスを発揮します。
Beam API と同様のセマンティクスのため、Scalding や Spark 開発者にとって移行が容易です。従って、開発者が短期間で多くのことを学習する必要はありません。
Hadoop、Avro、Parquet といった Java のインフラストラクチャ ライブラリと、Algebird、Breeze のような Scala の高度な数値処理ライブラリの大規模なエコシステムへのアクセスを可能にします。
SCIO REPL を使用したデータとコード スニペットのインタラクティブな探索をサポートしています。
リファレンス パターン
いくつかのコンセプトとその例について確認していきましょう。
1. グラフの構成
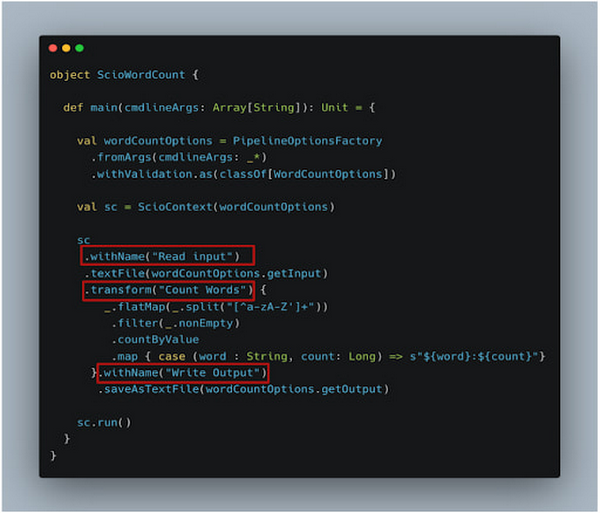
複数の変換で構成される複雑なパイプラインの場合、論理的に関連する変換をブロックに構成することが現実的なアプローチになります。そうすることで、データフロー UI にレンダリングされたグラフの管理とデバッグが簡単になります。一般的な WordCount パイプラインを例に挙げて考えてみましょう。
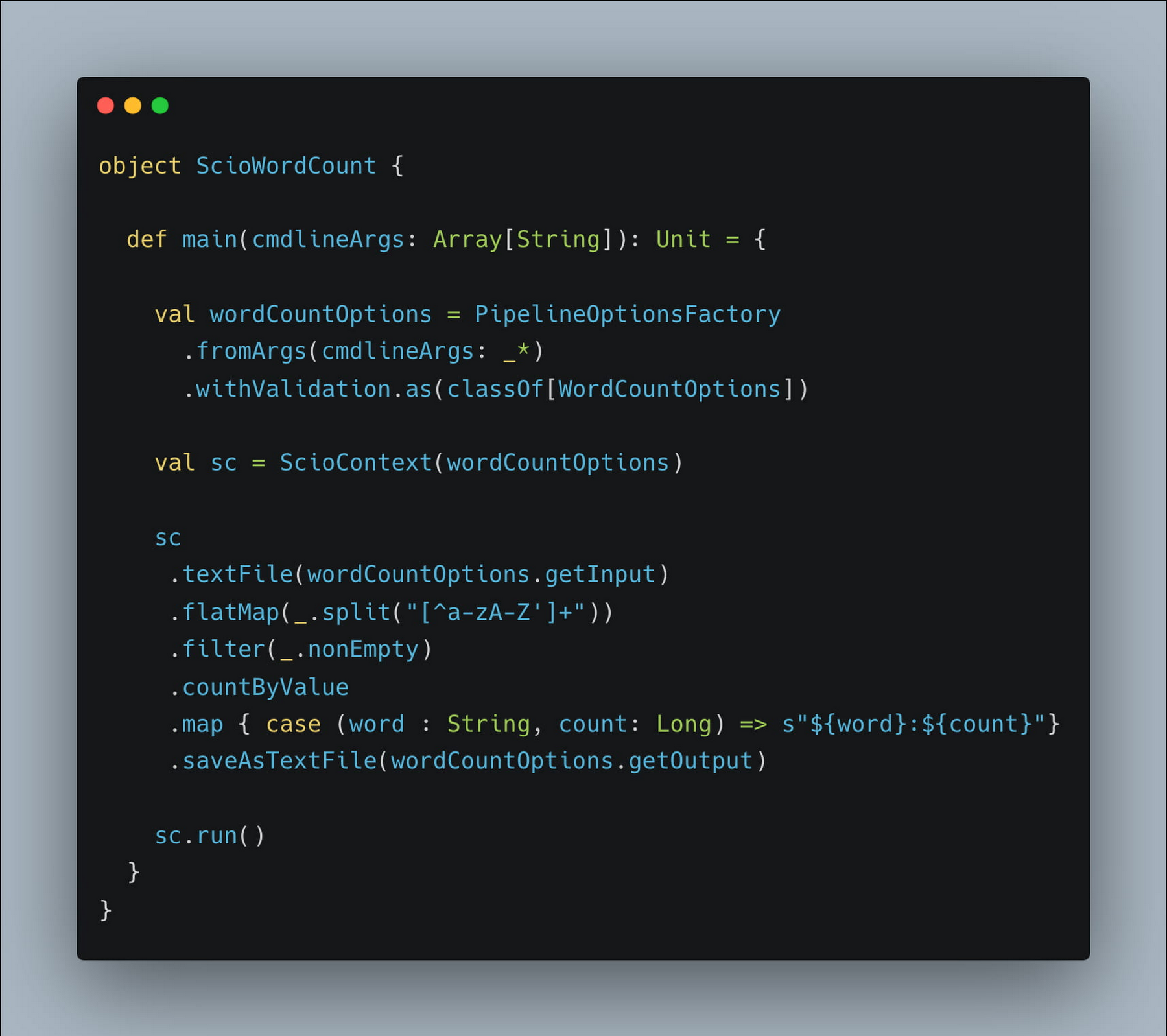
関連する変換をブロックにグループ化するようにコードを変更してみましょう。

2. 分散キャッシュ
分散キャッシュを使用すると、指定された URI からワーカーにデータを読み込み、ワーカーで実行されるすべてのタスク(DoFn)で対応するデータを使用できます。一般的なユースケースとしては、Google Cloud Storage などのオブジェクト ストアからシリアル化された機械学習モデルを読み込んで予測の実行やデータ参照のルックアップなどが行われます。
初期化中にワーカーの CSV ファイルからルックアップ データを読み込み、各入力要素に一致するルックアップ数のカウントに使用する例を確認していきましょう。
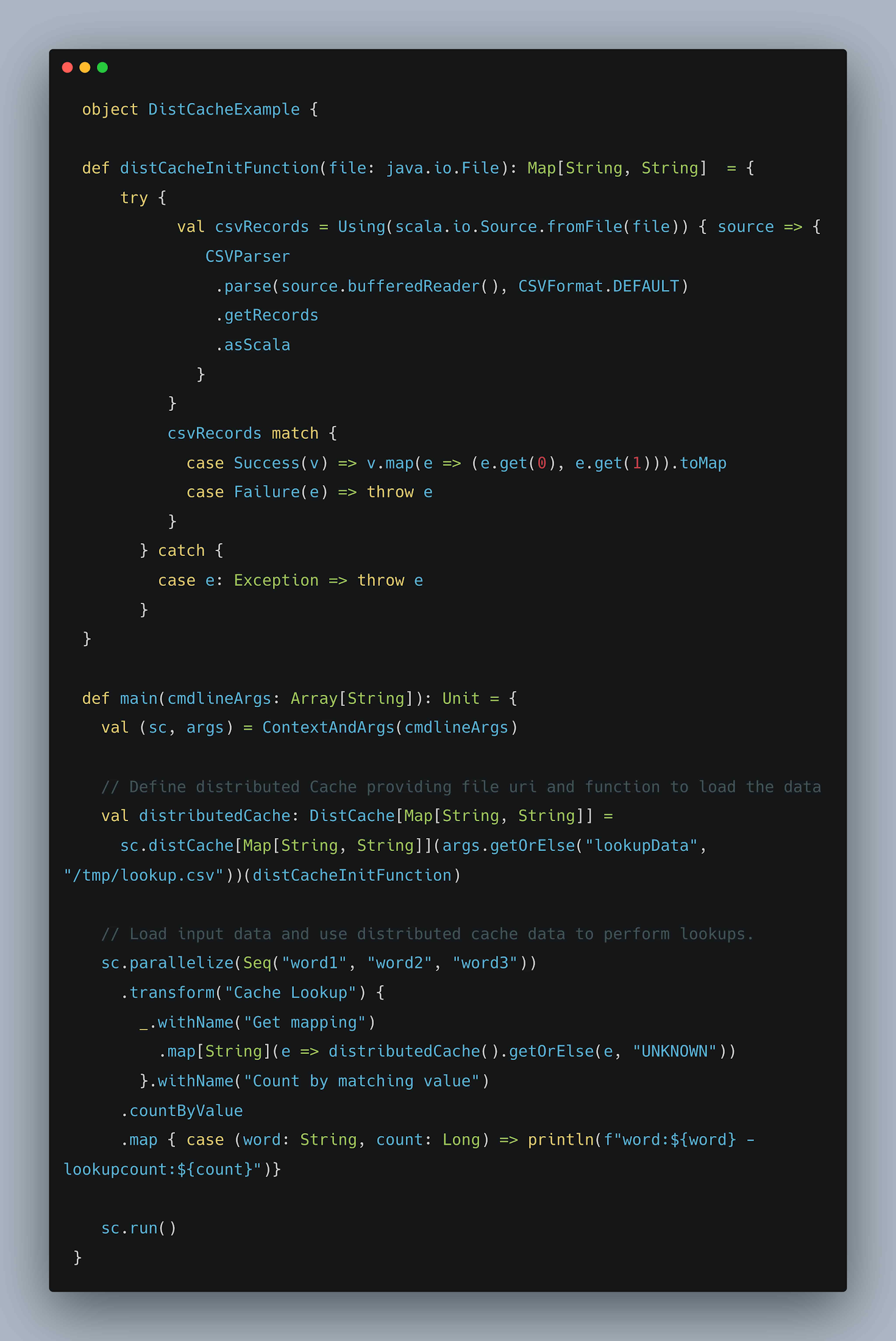
図: キャッシュ分散の記述例
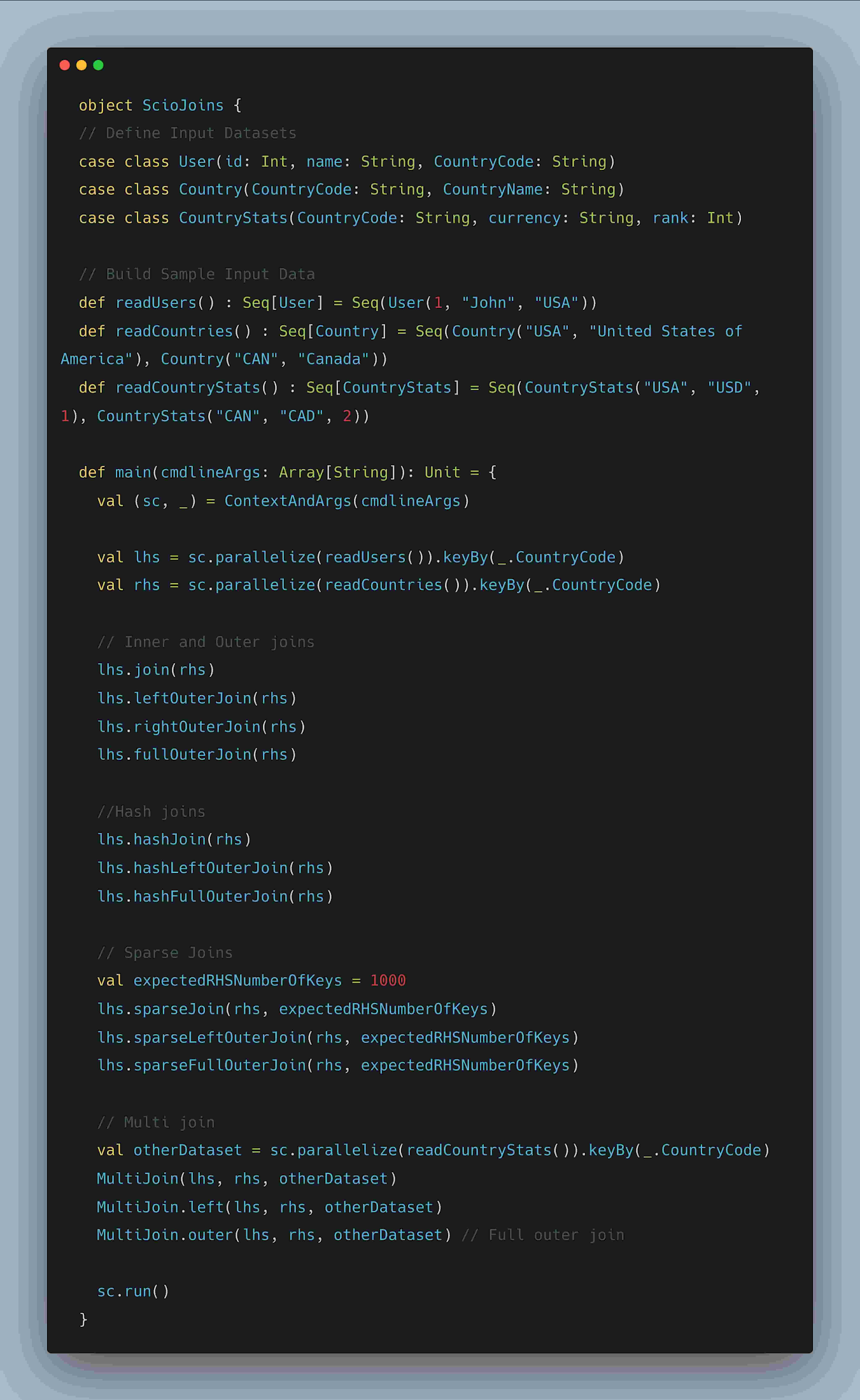
3. Scio 結合
Beam での結合は、CoGroupByKey を使用して表現されますが、Scio では、CoGbkResult をフラット化し、内部結合、左外部結合、完全外部結合などさまざまな結合タイプを表現できます。
ハッシュ結合(beam 副入力に対する糖衣構文)は、データセットの 1 つが非常に小さい(最大~1GB)場合、右側により小さなデータセットを表現することで使用できます。副入力は小さなメモリ内データ構造で、すべてのワーカーにレプリケートされ、シャッフルを回避できます。
MultiJoin を使用することで、最大 22 のデータセットを結合できます。非シャッフル結合では、最大サイズのデータセットを演算子チェーンの左側に配置する必要があるため、すべてのデータセットをサイズの降順で並べることをおすすめします。
スパース結合は、左コレクション(LHS)が右コレクション(RHS)よりもはるかに大きく、メモリには収まりませんが、左のコレクションと一致するキーのスパースな交差を含む場合に使用できます。スパース結合は、右コレクションからキーのブルーム フィルタを作成し、左側のコレクションを 2 つのパーティションに分割することで実装されます。フィルター内のキーを持つパーティションのみで結合が行われ、残りは連結(すなわち外部結合)または、破棄(内部結合)されます。スパース結合は、増分更新を伴う過去の集計を結合する場合に特に有効です。
スキュー結合は、左コレクション(LHS)が非常に大きく、ホットキーを含む場合、より適切な選択になります。スキュー結合では、LHS コレクションにおけるキーの頻度をカウントするために、確率的なデータ構造である Count Mink Sketch を使用します。LHS は、ホット パーティションとチル パーティションに分割されます。ホット パーティションはハッシュ結合を使用して RHS の対応するキーと結合され、チル パーティションは通常の結合を使用して、最終的に両方のパーティションがユニオン演算によって組み合わされます。
Beam Java SDK を使用している場合、結合ライブラリの拡張機能を使用して類似する結合の抽象化も利用できます。
4. AlgeBird アグリゲータとセミグループ(半群)
Algebird は Twitter の抽象代数ライブラリで、並列集計と概算値に適した再利用可能ないくつかのモジュールを提供しています。Algebird のアグリゲータまたはセミグループは、SCollection[T] の集計変換と合計変換、または、SCollection[(K, V)] の aggregateByKey 変換と sumByKey 変換で使用できます。以下の例では、顧客注文の並列集計のコンピューティングと、結果の OrderMetrics クラスへの構成を示しています。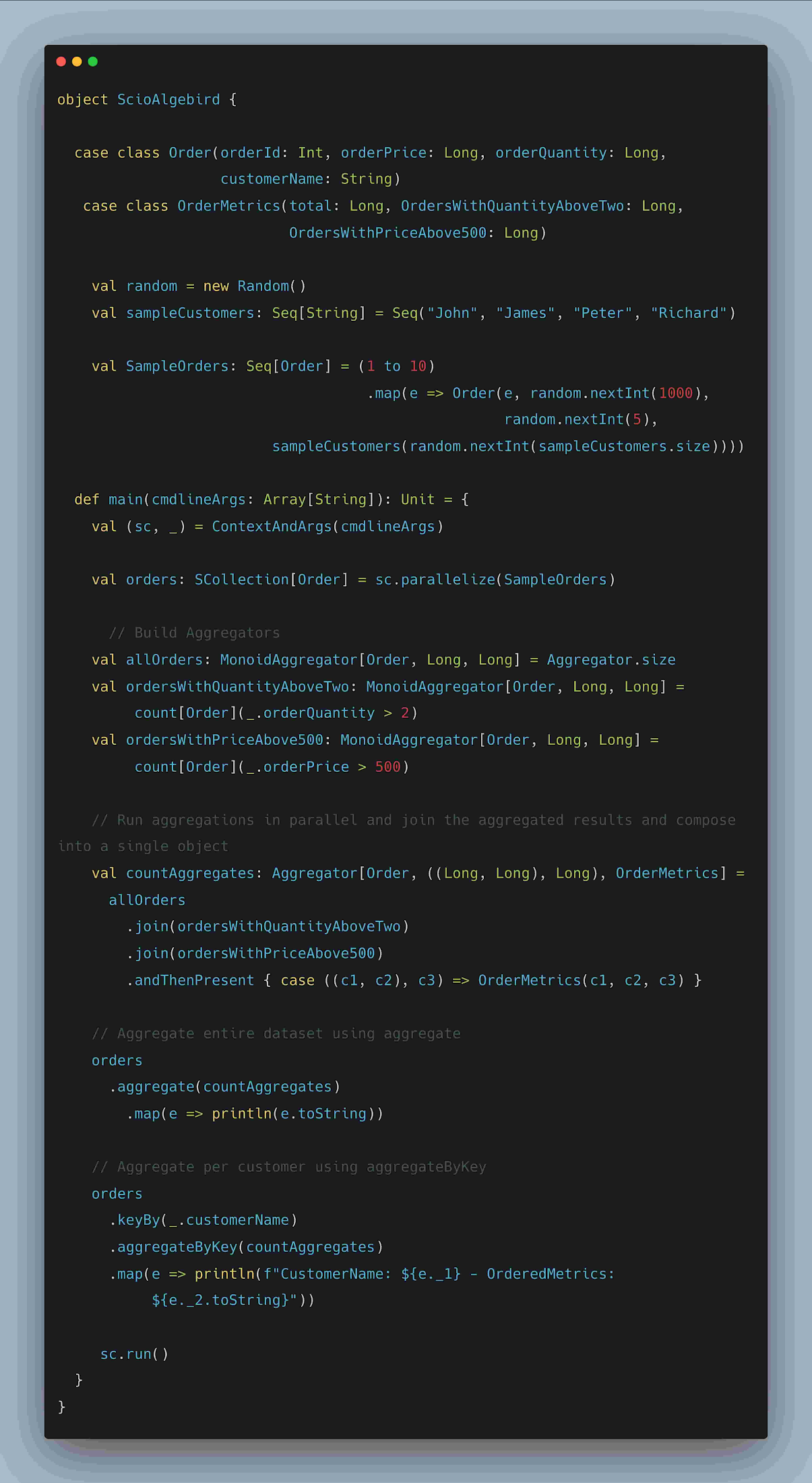
図: Algebird アグリゲータの記述例
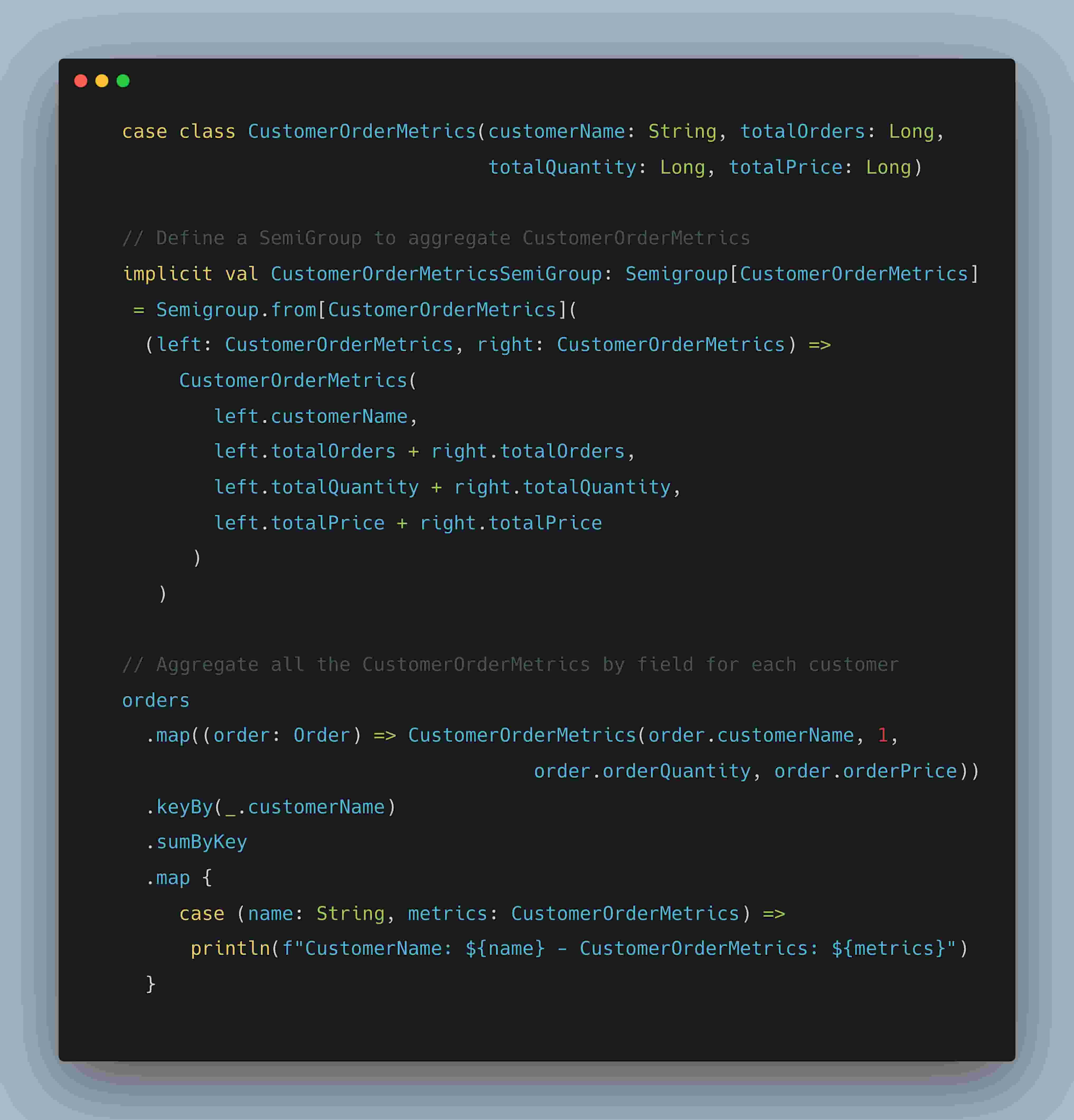
以下のコード スニペットでは、前出の例を発展させ、フィールドを組み合わせてオブジェクトを集計するセミグループを示します。
5. GroupMap と GroupMapReduce
GroupMap は、groupBy(key) + mapValues(_.map(func)) または _.map(e => kv.of(keyfunc, valuefunc)) + groupBy(key) の代わりとして使用できます。
各タイプの単語の長さを計算する以下の例を考えてみましょう。GroupMap では、各タイプごとにグループ化し length 関数を適用する代わりに、keyfunc と valuefunc を適用することで、こうした演算を組み合わせることができます。

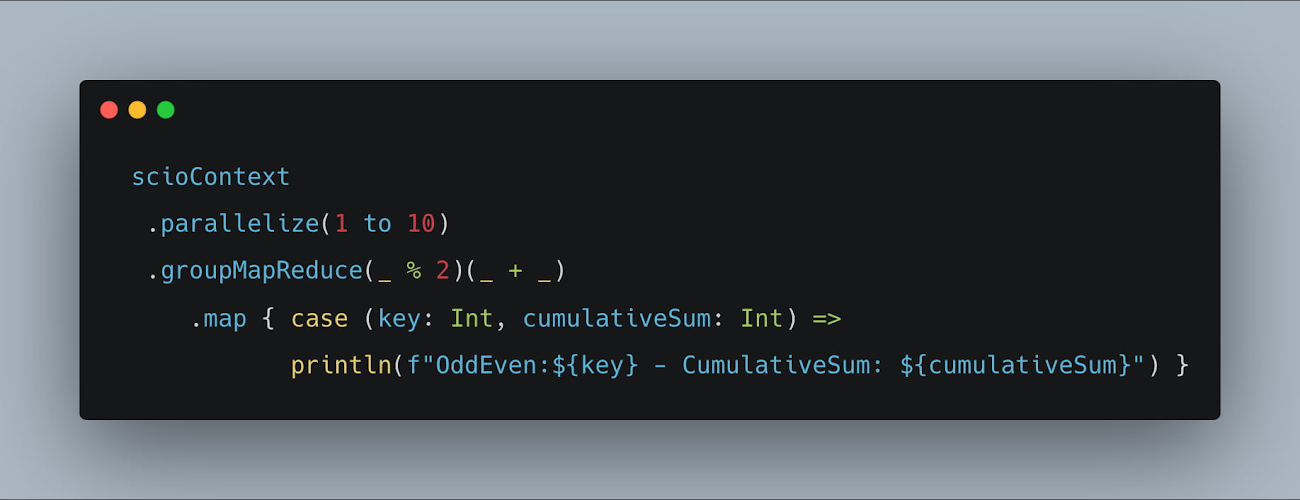
GroupMapReduce は、キーを導出し、各キーに関連付けられた値に対して連想演算を適用するために使用できます。この結合関数は、その結果をレデューサに送る前に、MapReduce の「コンバイナ」と同様に各マッパーでローカルに実行されます(コンバイナ リフティングとも呼ばれる)。これは、keyBy(keyfunc) + reduceByKey(reducefunc) と同等です。
指定された範囲内の奇数と偶数の累積合計を計算する以下の例を考えてみましょう。このケースでは、個々の値は各ワーカーで結合され、ローカル検索の結果を集計して最終結果を計算します。
まとめ
お読みいただきありがとうございます。SCIO についてご興味をお持ちいただけたら幸いです。上記で説明したパターン以外にも、SCIO には Scala ケースクラスの暗黙的なコーダー、I/O タップを使用したジョブの連結、HyperLogLog++ を用いた個別のカウント、並べ替えられた出力のファイルへの書き込みなど、さまざまな興味深い機能が提供されています。また、BigDiffy(大規模なデータセットの比較)や、FeaTran(ML 特徴量エンジニアリングに使用)などのいくつかのユースケース固有のライブラリも、SCIO 上に構築されました。
Scala のバックグラウンドを持つ Beam を愛用しているユーザーにとって、SCIO は複雑な分散データ パイプラインを構築するための完璧なレシピです。
- スタッフデータ エンジニア Prathap Kumar Parvathareddy

