データ分析
BigQuery BI Engine を読み解く
2023年2月16日
Google Cloud Japan Team
※この投稿は米国時間 2023 年 2 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery BI Engine は BigQuery の高速なインメモリ分析システムです。現在月間 20 億件を超えるクエリを処理しており、その数は増え続けています。BigQuery は Google の Dremel システムに端を発する、スケーラビリティを目標として構築されたデータ ウェアハウスです。一方、BI Engine はデータ アナリストを想定し、最小限の調整で、リアルタイム解析と BI のためのギガバイト~サブテラバイトのデータセットから価値を引き出すことに重点を置いています。
BI Engine の使用方法は簡単です。BigQuery クエリを実行するプロジェクトにメモリ予約を作成すると、データがキャッシュに保存され、最適化が使用されます。このブログ投稿では、BigQuery クエリの非常に高速なパフォーマンスを実現するために BI Engine ができることと、BI Engine の可能性を最大限に活用するためにユーザーができることについて詳しく説明します。
BI Engine の最適化
BI Engine の二本柱は、データのインメモリ キャッシュとベクトル化処理です。最適化には、ほかにも CMETA メタデータ プルーニング、単一ノード処理、小規模なテーブルの結合最適化があります。
ベクトル化エンジン
BI Engine は「Superluminal」ベクトル化評価エンジンを利用しています。これは、YouTube の分析データ プラットフォーム クエリエンジンである Procella でも使用されています。BigQuery の行ベースの評価では、エンジンがすべての行について、行内のすべての列を処理します。通常、エンジンは次の行に進む前に列の種類とメモリ位置を行き来します。これに対し、Superluminal のようなベクトル化エンジンは、1 つの列から同じ種類の値ブロックを可能な限り長く処理し、必要になって初めて次の列に移ります。これにより、ハードウェアは SIMD を使用して複数のオペレーションを一度に行うことができ、レイテンシとインフラストラクチャ費用を両方とも減らすことができます。BI Engine は、キャッシュと利用可能なメモリに合わせてブロックサイズを動的に選択します。
たとえば、クエリ「SELECT AVG(word_count), MAX(word_count), MAX(corpus_date) FROM samples.shakespeare」のベクトル化プランは次のようになります。評価で「word_count」と「corpus_date」が別々に処理されています。
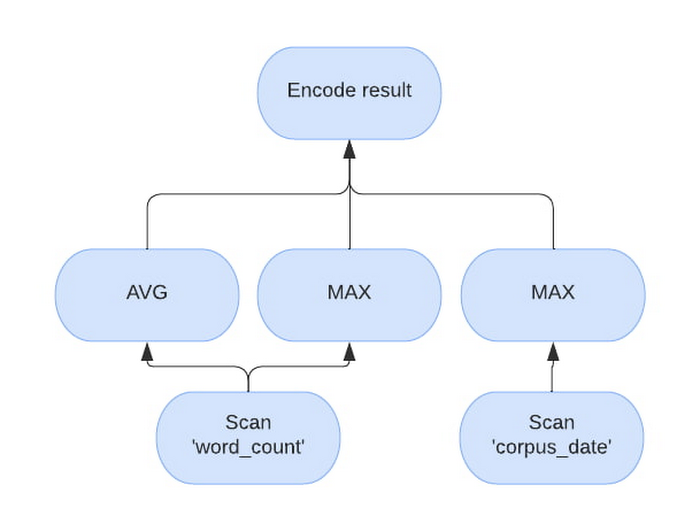
インメモリ キャッシュ
BigQuery は、ストレージとコンピューティングの分散型エンジンです。通常、BigQuery のデータは Google の分散ファイル システム(Colossus。多くの場合 Capacitor 形式のブロック)に保存され、コンピューティングは Borg タスクで表現されます。これにより BigQuery のスケーリング性が実現します。ベクトル化処理を最大限に活用するには、BI Engine が CPU 速度で元データを供給する必要がありますが、これはデータがすでにメモリ内にある場合にしか達成できません。BI Engine は Borg タスクも実行しますが、ワーカーのほうが、Colossus から読み込んだデータをそのままキャッシュに保存できるようにするためにメモリを多く消費します。
1 つの BigQuery クエリを、1 つの BI Engine ワーカーに送信することも、シャーディングして複数の BI Engine ワーカーに送信することもできます。各ワーカーはクエリの一部を受け取り、答えるために必要な列と行のセットを使用して実行します。データが前のクエリからワーカーメモリにキャッシュ保存されていない場合、ワーカーは Colossus からローカル RAM にデータを読み込みます。同じ列と行、または列と行のサブセットに対する後続のリクエストは、メモリからのみ提供されます。なお、データが 24 時間以上使用されなかった場合、ワーカーはコンテンツをアンロードします。複数のクエリが届くと、ワーカーで利用可能な CPU 時間より多くの CPU 時間が必要になる場合があります。利用可能な予約が残っていれば、新しいワーカーは同じブロックに割り当てられ、同じブロックに対する後続のリクエストはワーカー間でロードバランスされます。
BI Engine は、BigQuery テーブルにストリーミングされた最新のデータを処理することもできます。そのため、BI Engine ワーカーで現在サポートされている形式は Capacitor とストリーミングの 2 つとなっています。
インメモリ Capacitor ブロック
一般的に、Capacitor ブロック内のデータは生成時に前処理され、圧縮されます。Capacitor ブロックからのデータをキャッシュに保存する方法はいくつかあり、メモリ効率が高いものもあれば、CPU 効率が高いものもあります。BI Engine ワーカーは、レイテンシを優先するものか、CPU 効率の高い形式をインテリジェントに選択します(選択が可能な場合)。キャッシュ形式が異なるので、実際の予約メモリ使用量が論理または物理ストレージ使用量と同じにはならないことがあります。
インメモリ ストリーミング データ
ストリーミング データは、ネイティブの配列列のブロックとしてメモリに保存され、基となるストレージ プロセスによってブロックが Capacitor に抽出されたとき、遅延アンロードされます。なお、ストリーミングの場合、BI ワーカーは毎回ストリーミング ストレージに移動して新しいブロックを取得するか、少し古いデータを提供する必要があります。BI Engine は、少し古いデータを提供し、代わりに新しいストリーミング ブロックをバックグラウンドで読み込みます。
BI Engine ワーカーはクエリ時に都合に合わせてこれを行います。ワーカーがストリーミング データを検出し、キャッシュが 1 分より新しい場合、クエリと並行してバックグラウンド更新が開始されます。実際は、十分なリクエストがあればデータが前のリクエスト時間より古くなることはありません。たとえば 1 秒ごとにリクエストが届く場合、ストリーミング データは 1 秒ほど古くなります。
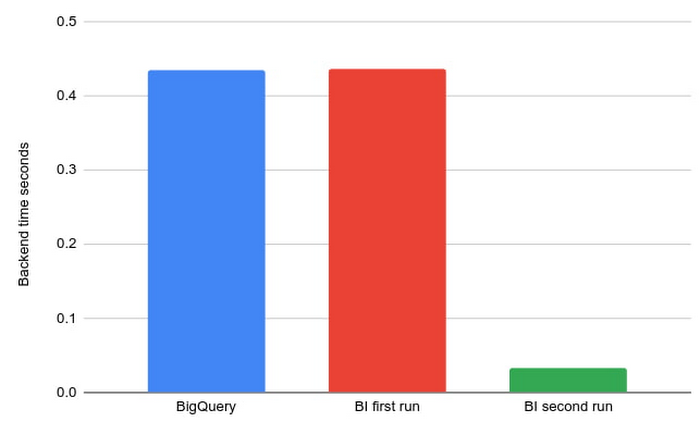
データを読み込む最初のリクエストは遅い
未知の列からのデータの読み込みは、読み取り時間の最適化が行われるため、BigQuery よりも時間がかかることがあります。この最適化により、後続の読み取りは速くなります。
たとえば、これは BI Engine をオフにした状態で同じクエリをサンプル実行したときのバックエンド時間(最初の実行と後続の実行)です。
複数ブロック処理と動的な単一ワーカー実行
BI Engine ワーカーは、入力サイズに比べて出力サイズが小さく、出力がほぼ集約される BI ワークロードに最適化されています。ネットワーク帯域に限りがあるため、通常の BigQuery の実行では単一のワーカーでデータの読み込みを最小限に抑えようとします。その代わり、BigQuery は大規模な並列処理でクエリをすばやく完了します。一方、BI Engine はそれより多くのデータを単一のマシンで並列処理します。データがキャッシュに保存されている場合は、ネットワーク帯域の制限がなく、BI Engine はクエリステージ間の中間「シャッフル」レイヤの数を減らすことで、ネットワーク使用率をさらに削減します。
十分に小さな入力とシンプルなクエリにより、クエリ全体が単一のワーカーで実行され、クエリプランは全体の処理に対して単一のステージとなります。Google は、単一ステージ処理の対象となるテーブルとクエリの形状を増やすよう継続的に取り組んでいます。典型的な BI クエリのレイテンシを改善する非常に有望な方法であるからです。
非常にシンプルでテーブルが非常に小さいクエリ例について、BI Engine 分散実行の場合と単一ノード(デフォルト)の場合の、同じクエリのサンプル実行を以下に示します。
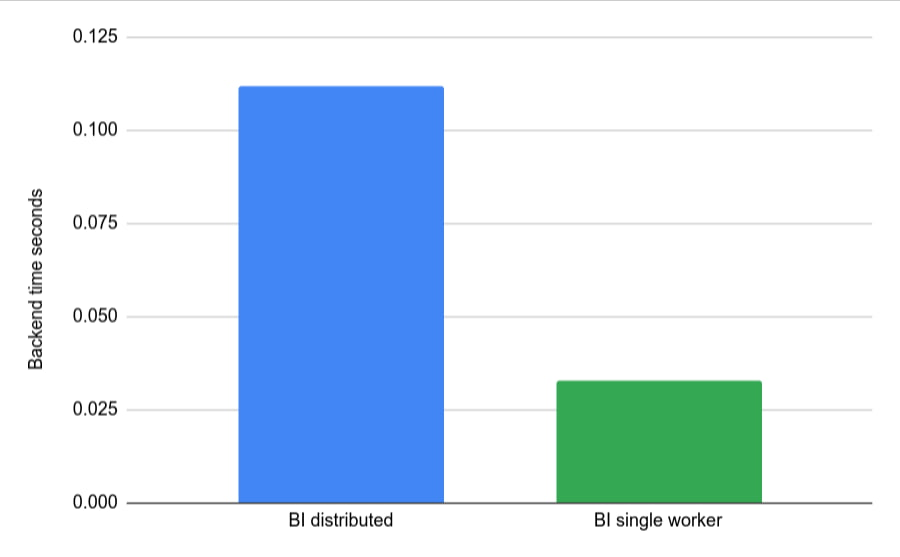
BI Engine を最大限に活用する方法
スイッチを切り替えるだけですべてが高速になればよいのですが、BI Engine を使用するときに考慮すべきベスト プラクティスはまだあります。
出力データサイズ
BI 最適化では、出力データは人が見るものであり、人間が理解できる程度にサイズが小さいことを前提としています。この出力サイズの制限は、選択的フィルタと集約で実現しています。当然ながら、SELECT * ではなく(LIMIT があっても)、適切なフィルタと集約で関心のあるフィールドを提供するほうが適切なアプローチとなります。
たとえば、クエリ「SELECT * FROM samples.shakespeare」は約 6 MB を処理し、BigQuery と BI Engine の両方で 1 秒を超える時間がかかります。MAX をすべてのフィールドに追加すると「SELECT MAX(word), MAX(word_count), MAX(corpus), MAX(corpus_date) FROM samples.shakespeare」となり、両方のエンジンがすべてのデータを読み取り、簡単な比較をいくつか行って、BigQuery では 5 倍速く、BI Engine では 50 倍速く終了します。
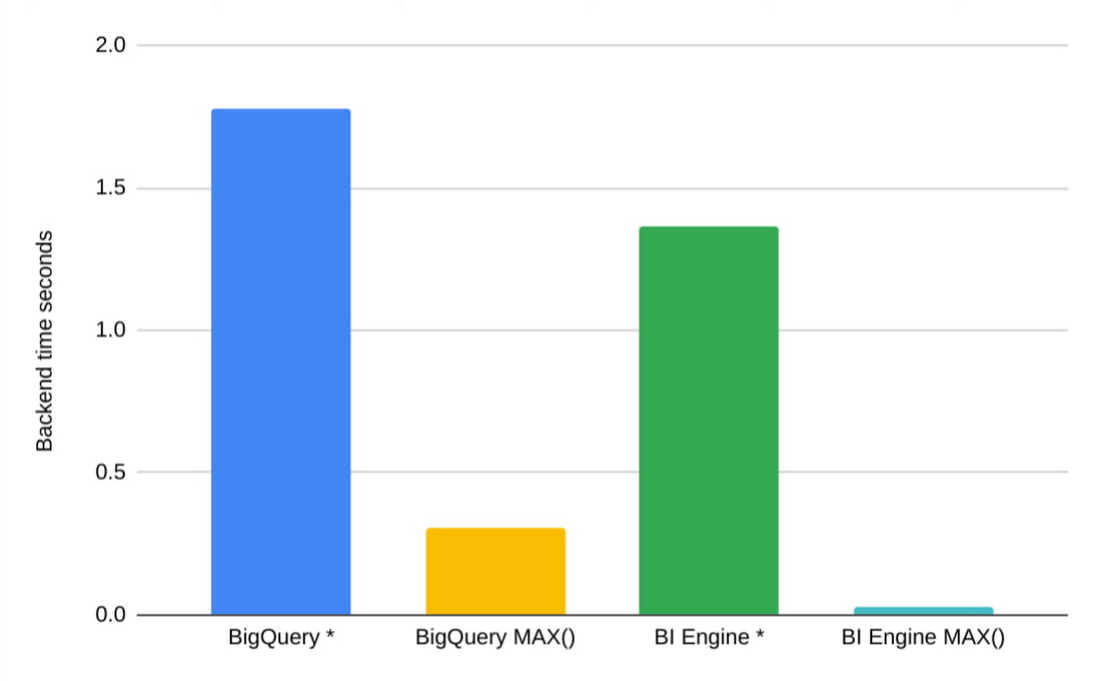
BigQuery によるデータ整理を支援する
BI Engine はクエリフィルタを使用して、読み取るブロックのセットを絞り込みます。そのため、データのパーティショニングとクラスタリングを行うと、読み取るデータの量、レイテンシ、スロット使用量を減らすことができます。ただし、過度なパーティショニングを行うと、つまりパーティションが多すぎると、BI Engine のマルチブロック処理に支障をきたすおそれがあります。BigQuery と BI Engine で最適なパフォーマンスを得るには、パーティションを 1 GB より大きくすることをおすすめします。
クエリの深さ
BI Engine は現在、テーブルからデータを読み取るクエリのステージを高速化しています。これは通常、クエリ実行ツリーのリーフです。つまり実際には、ほとんどすべてのクエリがいくつかの BigQuery スロットを使用することになります。そのため、リーフステージに多くの時間が費やされるとき、BI Engine による高速化が最大となります。これを軽減するために、BI Engine は可能な限り多くの計算を最初のステージにプッシュしようとします。理想的には、ツリーが 1 ノードだけである単一のワーカーで実行します。
たとえば、TPCH 10G ベンチマークの Query 1 は比較的シンプルです。深さは、3,000 万行を処理する効率的なフィルタと集約で 3 ステージですが、出力ではわずか 1 ステージです。
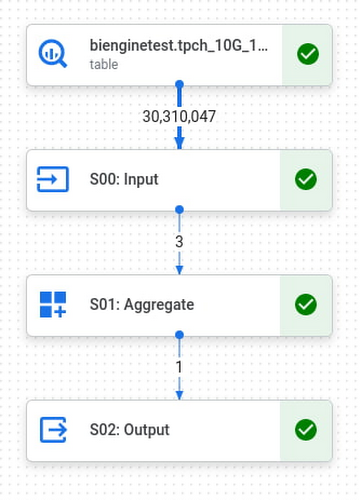
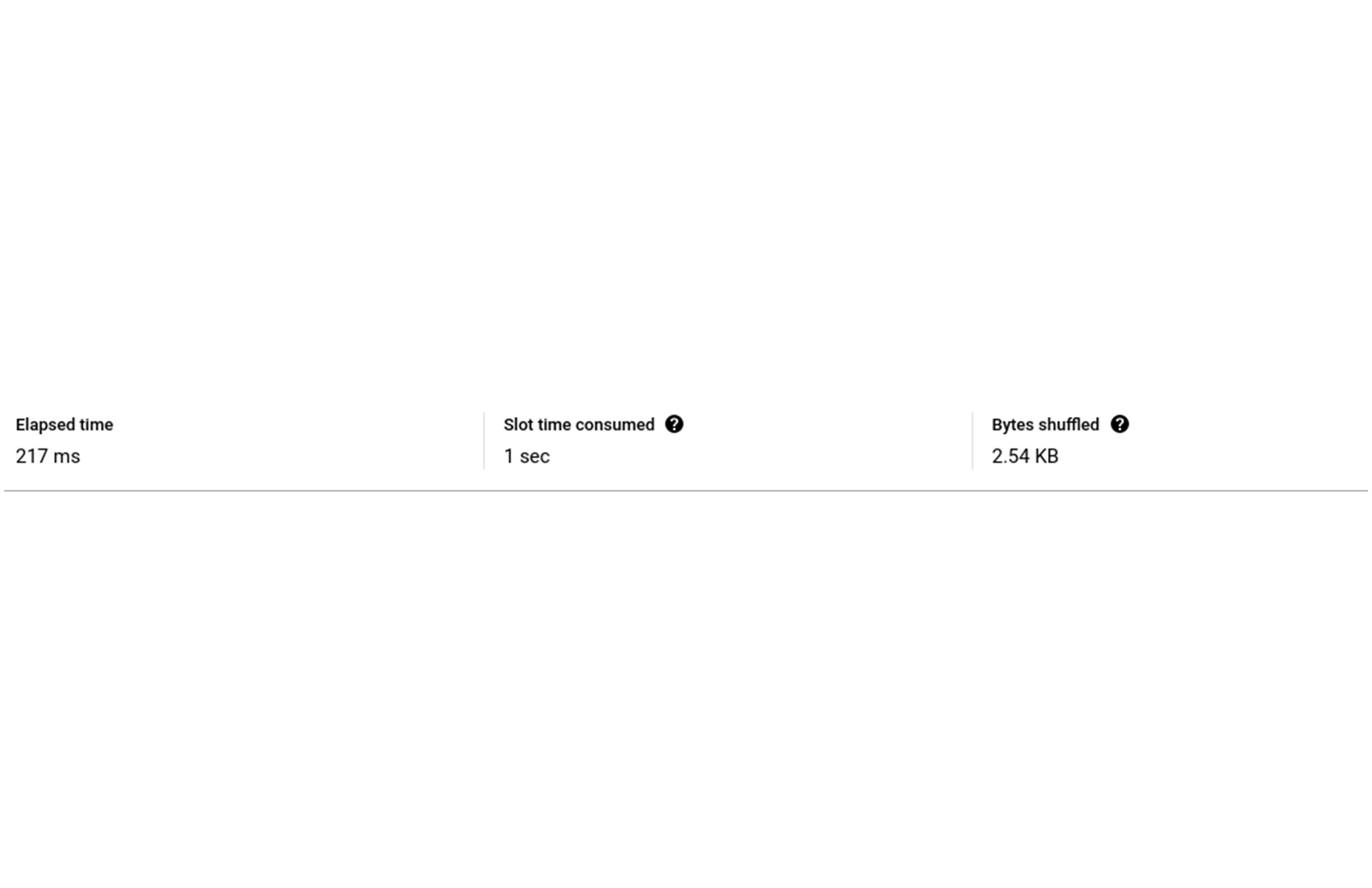
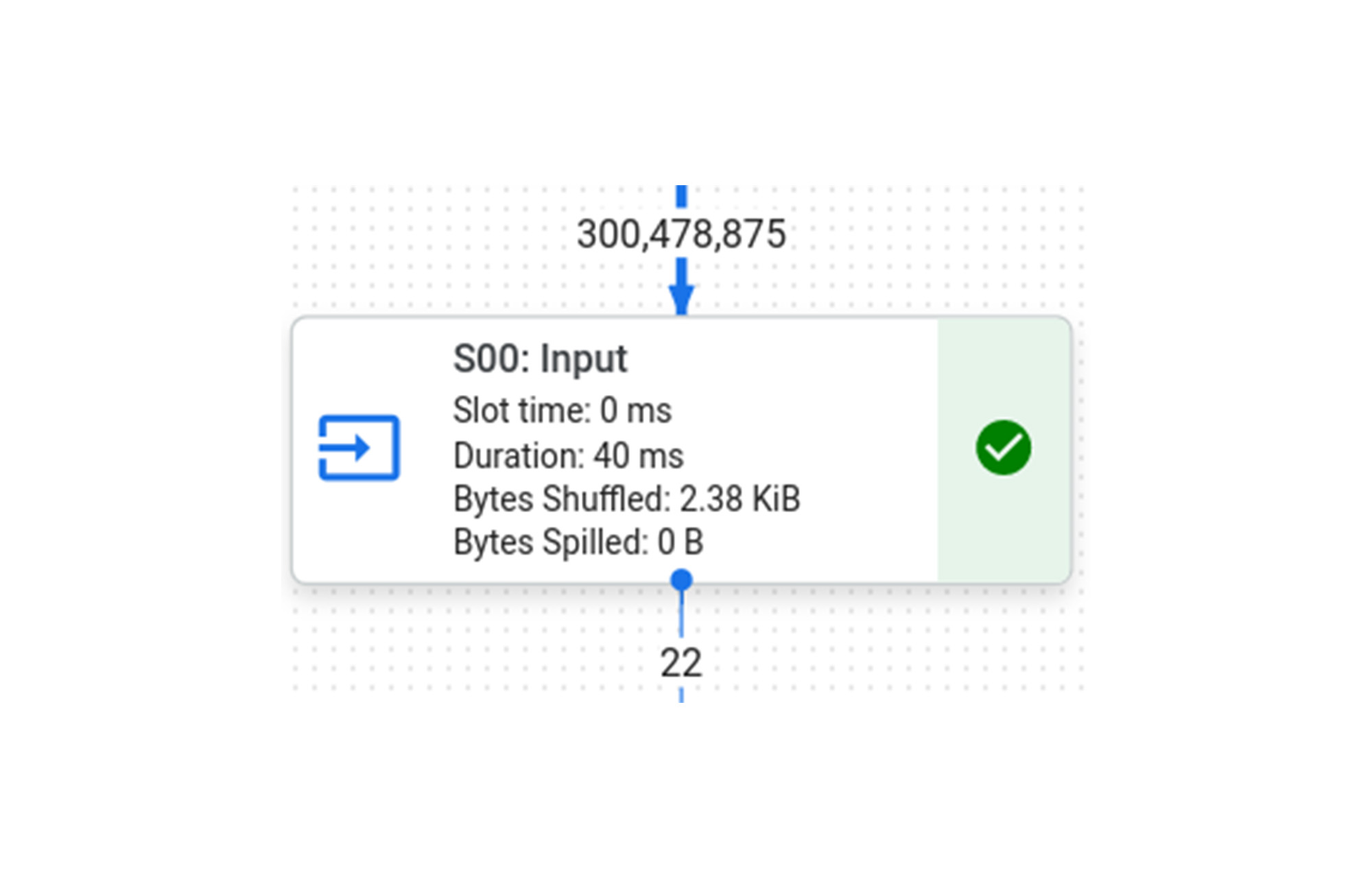
BI Engine でこのクエリを実行すると、クエリ全体に 215 ミリ秒かかり、BI Engine で高速化した「S00: Input」ステージには 26 ミリ秒かかることがわかります。


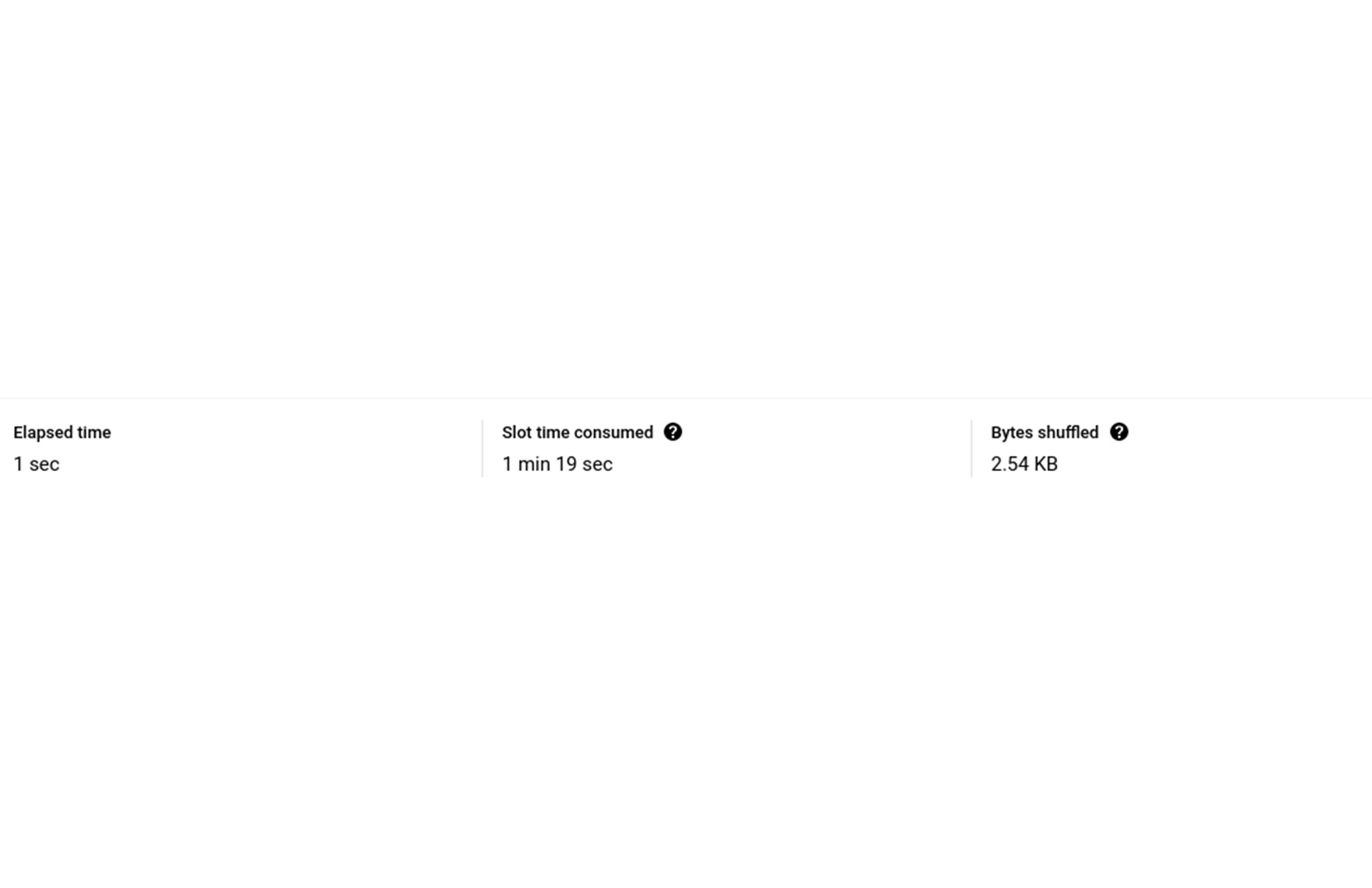
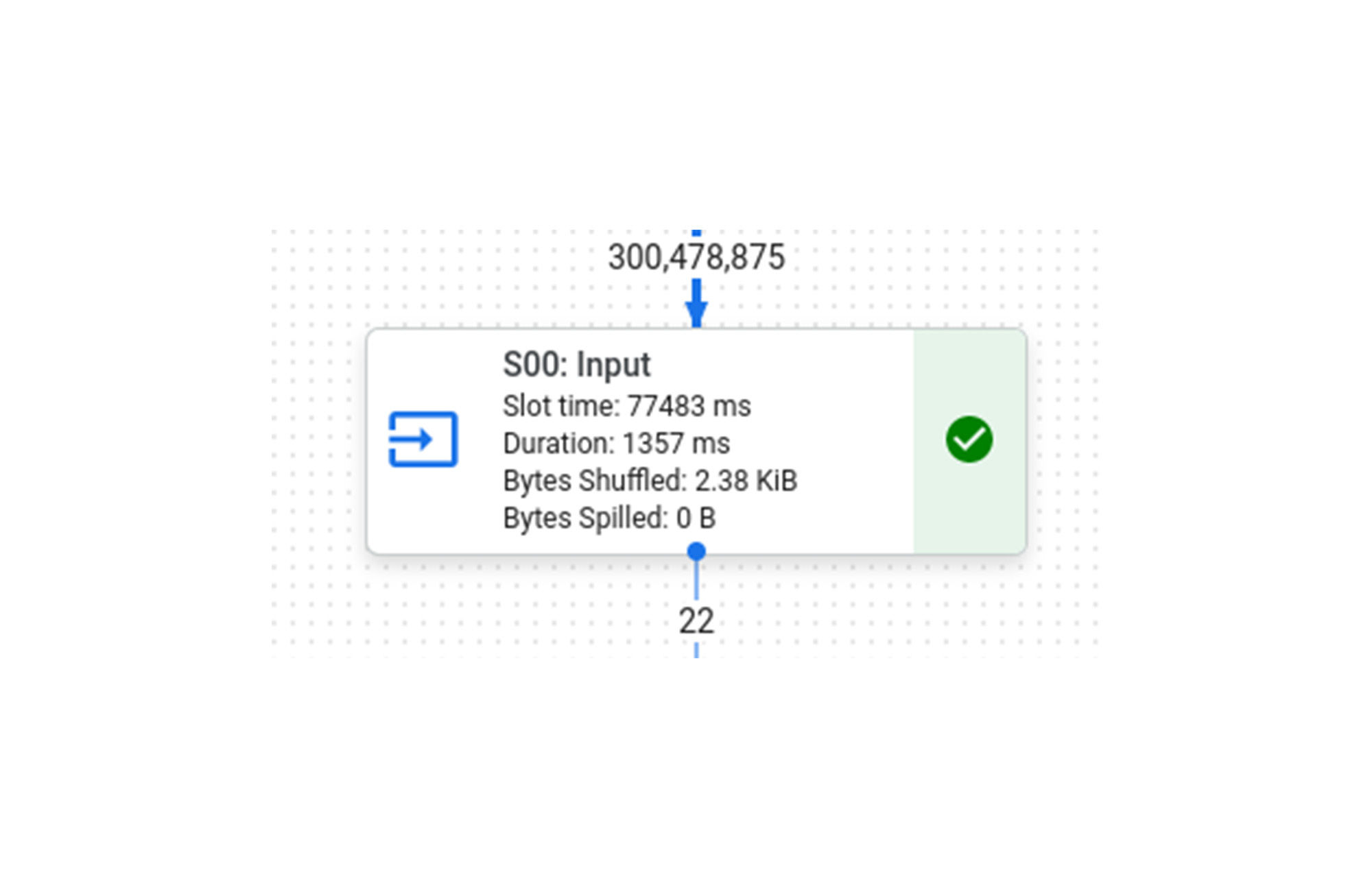
同じクエリを BigQuery で実行すると 583 ミリ秒かかり、「S00: Input」ステージには 229 ミリ秒かかります。
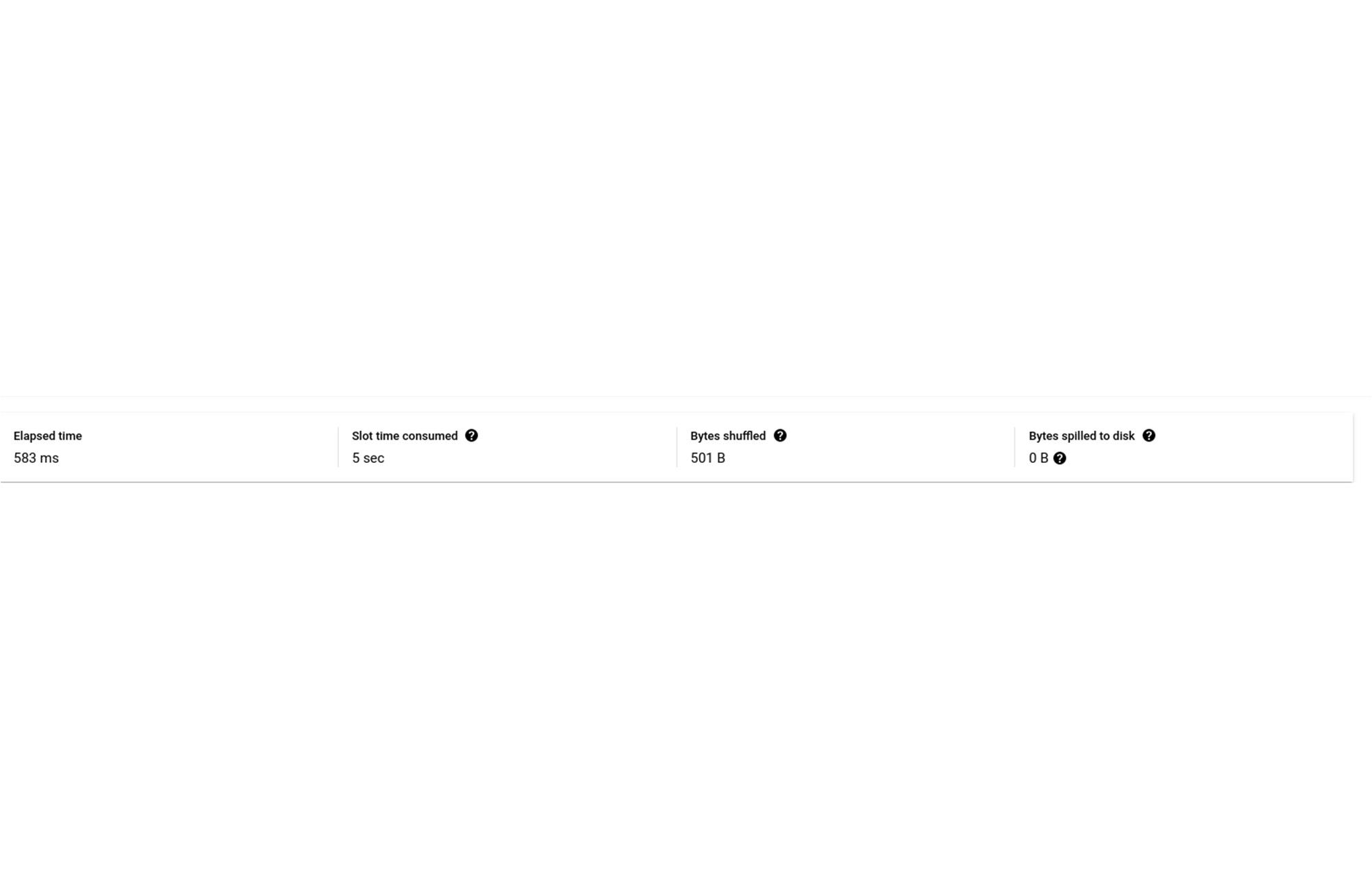
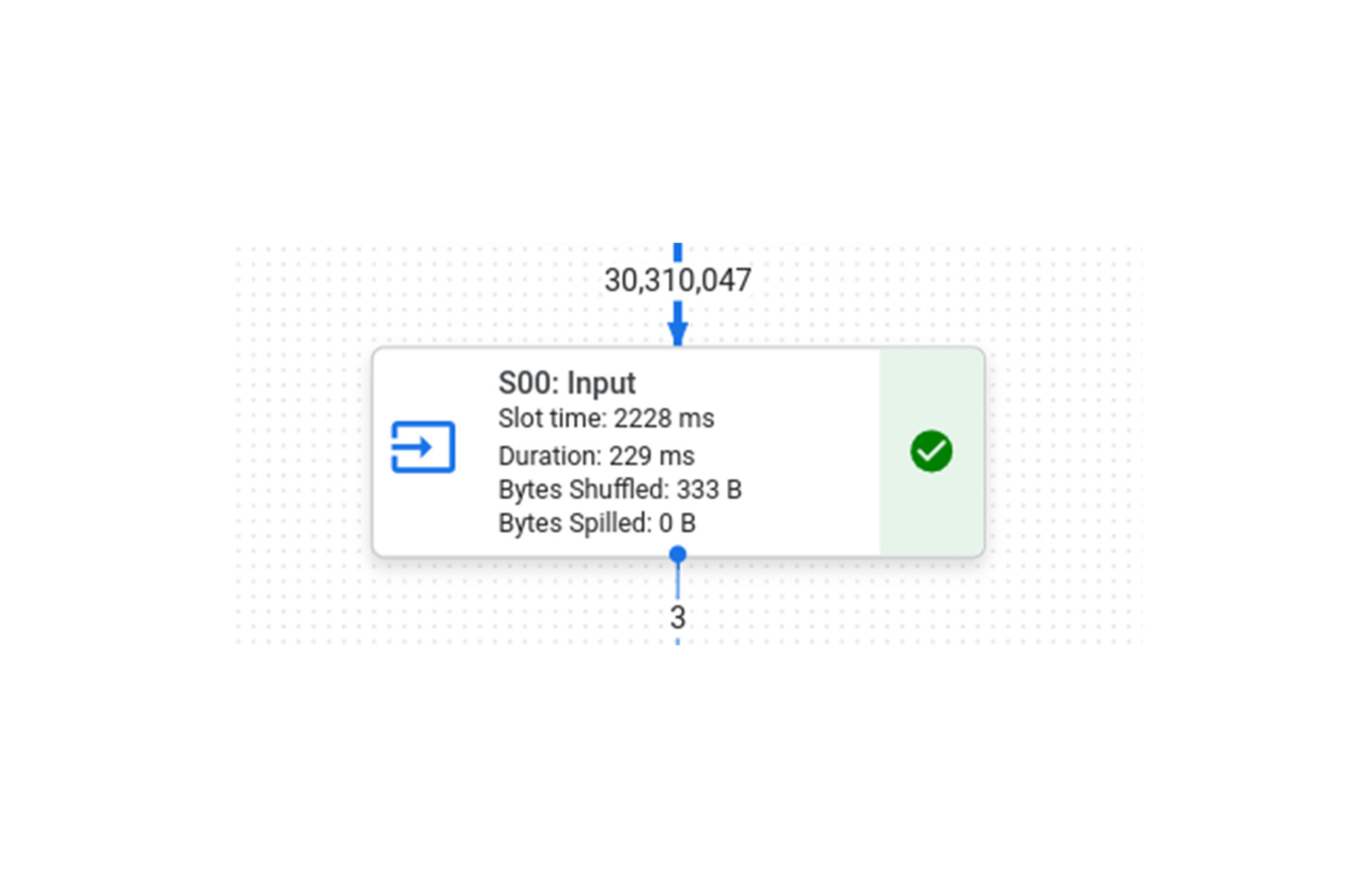
ここでわかることは、「S00: Input」ステージの実行時間が 8 倍になっていても、他の 2 つのステージは高速化されておらず実行時間がほぼ同じままであるため、クエリ全体が 8 倍高速化されているわけではない、ということです。ステージごとの内訳を下図に示します。
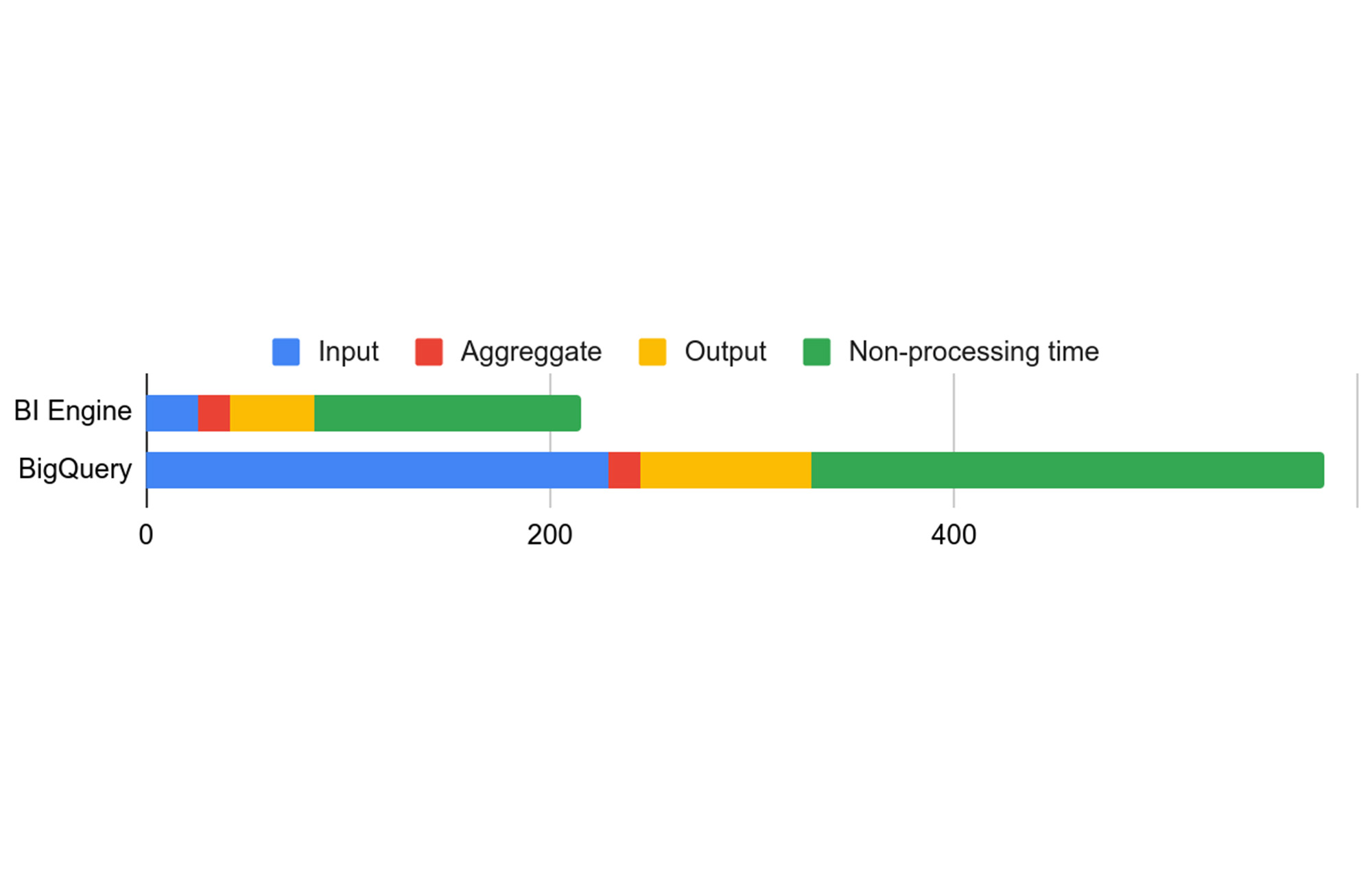
たとえ BI Engine での処理にかかる時間が 0 ミリ秒であったとしても、クエリが完了するまでに 189 ミリ秒かかります。そのため、このクエリによる高速化は最大で約 2~3 倍です。
たとえば、このクエリの最初のステージを重くして、代わりに TPCH 100G を実行すると、BI Engine では BigQuery より 6 倍速くクエリが終了しますが、最初のステージは 30 倍も速くなることがわかります。
BigQuery では 1 秒
いずれ、対象となるクエリとデータの形状を拡大し、可能な限り多くのオペレーションを単一の BI Engine ステージにまとめることで、最大の効果を実現することを目標としています。
結合
前述のとおり、BI Engine はクエリの「リーフ」ステージを高速化します。ただし、BI Engine が最適化する、BI ツールで使用される非常に一般的なパターンが 1 つあります。それは、1 つの大きな「ファクト」テーブルが 1 つまたは複数の「ディメンション」テーブルと結合される場合です。この場合 BI Engine は、いわゆる「ブロードキャスト」結合実行戦略により、1 つのリーフステージで複数の結合をすべて実施できます。
ブロードキャスト結合において、ファクト テーブルは複数のノードで並列に実行されるようにシャーディングされる一方、ディメンション テーブルは各ノードで全体が読み取られます。
たとえば、TPC-DS 1G ベンチマークの Query 3 を実行してみましょう。ファクト テーブルは store_sales、ディメンション テーブルは date_dim と item です。BigQuery では、まずディメンション テーブルがシャッフルに読み込まれ、次に「S03: Join+」ステージが、store_sales の並列部分ごとに、2 つのディメンション テーブルの必要な列すべてを完全に読み取り、結合します。
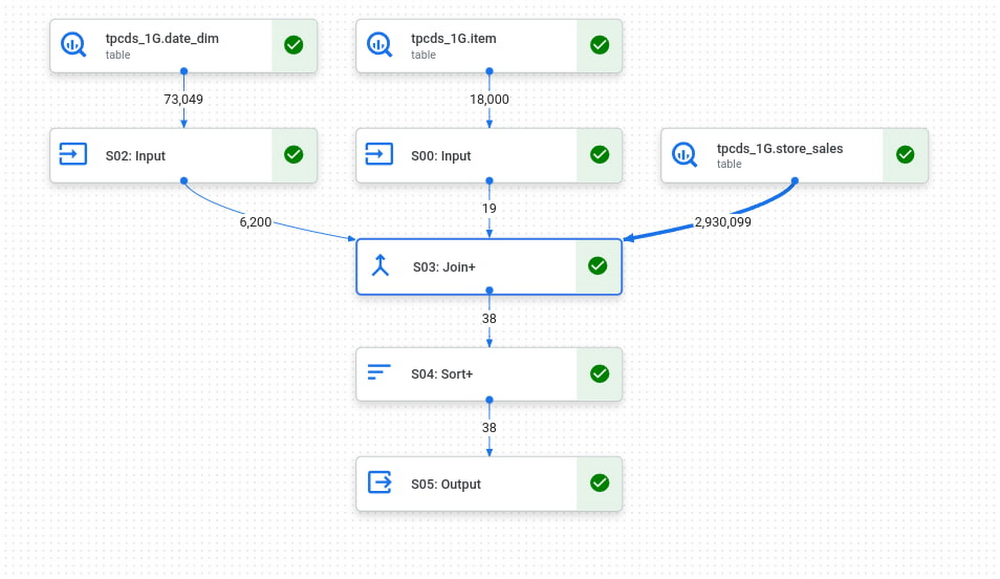
なお、date_dim と item のフィルタは非常に効率的であり、290 万行のファクト テーブルは結合されてわずか 6,000 行ほどになります。BI Engine はディメンション テーブルを直接キャッシュに保存するため、BI Engine のプランは若干異なりますが、同じ原則が適用されます。
BI Engine について、store_sales テーブルが大きすぎて単一ノード処理ができないため 2 つのノードでクエリを処理すると仮定します。下図では、データの読み取り、フィルタリング、ルックアップ テーブルの構築、結合の実施という同様のオペレーションを、両方のノードで行っていることがわかります。それぞれで store_sales テーブルのデータのサブセットのみが処理されていますが、ディメンション テーブルのオペレーションはすべて繰り返されています。
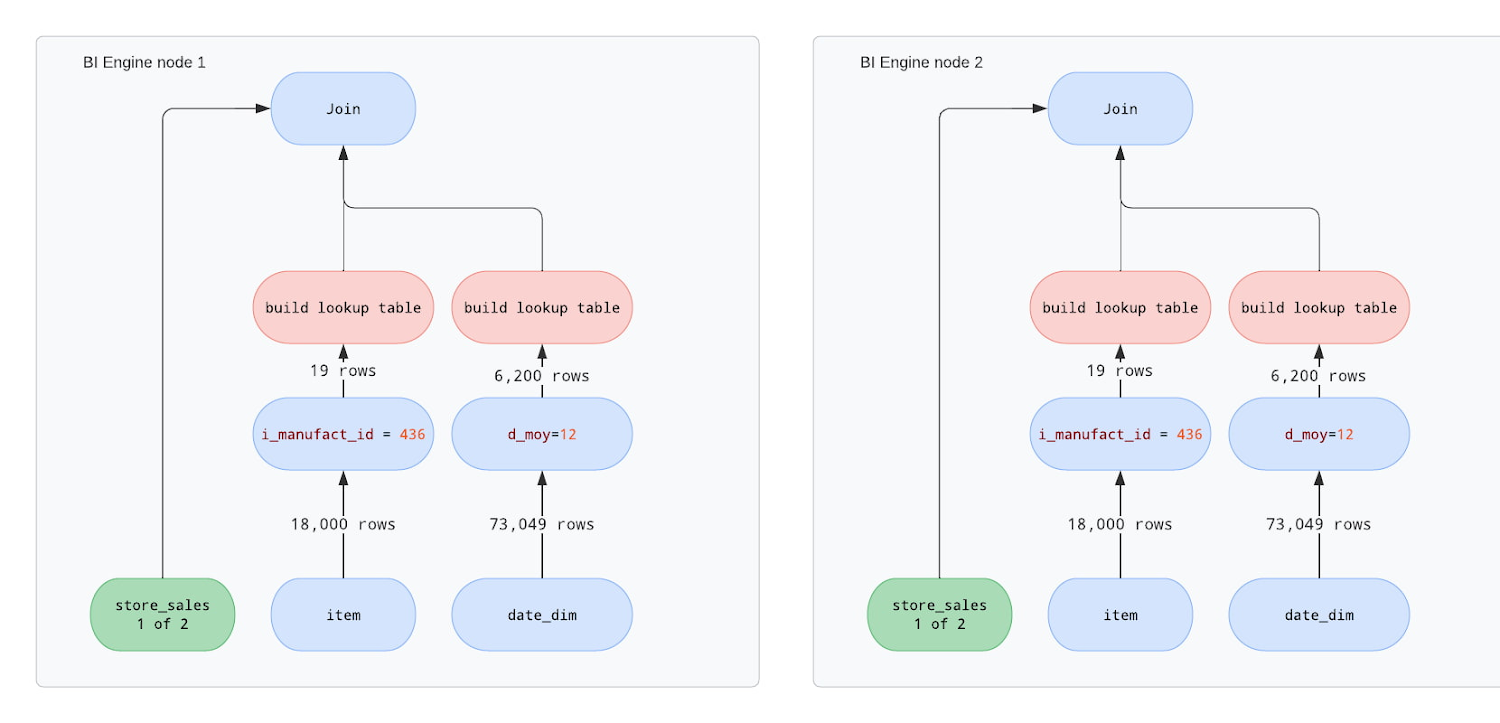
次のことに注意してください。
「ルックアップ テーブルの構築」オペレーションはフィルタリングに比べて CPU 負荷が非常に高い
ルックアップ テーブルが大きい場合、CPU キャッシュの局所性が阻害されるため、「結合」オペレーションのパフォーマンスも低下する
ディメンション テーブルをファクト テーブルの各「ブロック」に複製する必要がある
要点は、BI Engine によって結合が行われるとき、ファクト テーブルが異なるノードに分割される場合があるということです。他のテーブルはすべて、結合を行うために各ノードで複数回コピーされます。ディメンション テーブルを小さく保つか選択的なフィルタを使用することで、最適な結合パフォーマンスを得られます。
まとめ
以上の内容をまとめます。BI Engine を最大限に活用し、クエリを高速化するためにできることはいくつかあります。
返されるデータに関して言えば、少ないほうがよいので、クエリの初期段階で可能な限り多くのデータをフィルタして集約するようにする。フィルタと計算を BI Engine にプッシュダウンする。
クエリのステージ数が少ないほど高速化できる。クエリの複雑さを最小限に抑えるためにデータを前処理すると、最適なパフォーマンスが得られる。たとえばマテリアライズド ビューの使用も推奨される。
結合は費用がかさむことがあるが、BI Engine は一般的なスタースキーマ クエリを非常に効率的に最適化できる。
読み取るデータ量の制限には、テーブルのパーティショニングやクラスタリングが役立つ。
この投稿に協力してくれた BI Engine のソフトウェア エンジニア Benjamin Liles、BI Engine のプロダクト マネージャー Deepak Dayama に感謝します。
- スタッフ エンジニア Stepan Yakovlev
- スタッフ エンジニア Alexey Klishin


