インサイトの民主化: データ アナリストとビジネス ユーザーを強力にサポート
Google Cloud Japan Team
※この投稿は米国時間 2020 年 11 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
今日は、地域、規模、業界を問わず、すべてのビジネスに共通して望まれることの一つ、「データドリブンになる」ということに焦点を当てた複数回のシリーズを開始します。データが存在する限り、企業はそれを利用して、顧客、マーケット、競合他社をより深く理解しようとしてきました。最近変わってきたのは、データドリブンになるための 3 つの核となる要素、a) データの可用性、b) データへのアクセス、c) インサイトへのアクセスの性質です。
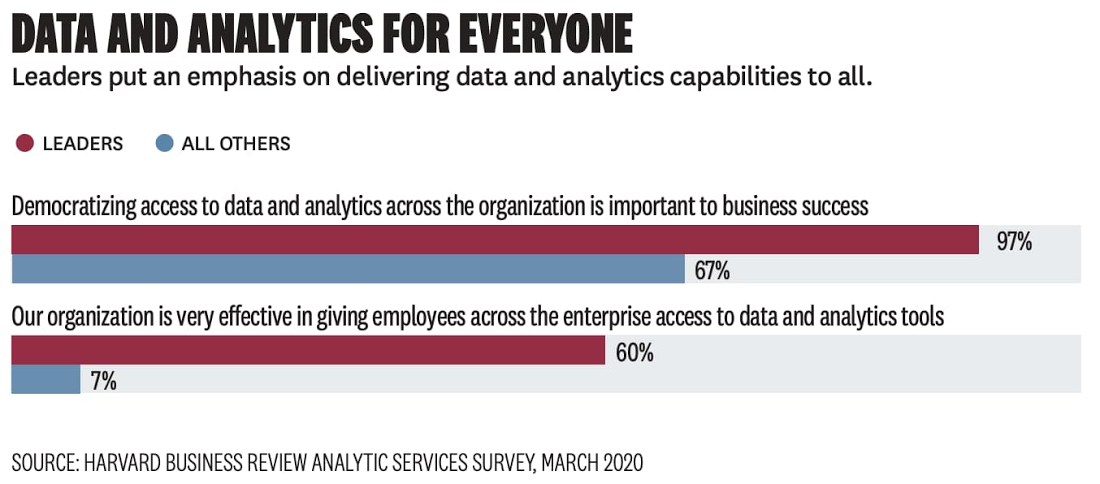
これらの要素が広く展開されたり、「民主化」されたりすることで、企業はトップダウンだけでなく、ボトムアップ、ミドルアウト、そしてその間のあらゆる場合でのマネジメントの改善を可能としてきました。先日の Google Cloud / Harvard Business Review の論文によると、調査対象となった業界リーダーの 97% が、組織全体でデータや分析へのアクセスを民主化することがビジネスの成功に重要であると答えています。このブログシリーズでは、「データドリブン」とは何か、この概念が時代とともにどのように変化してきたのか、そして Google Cloud がお客様がデータを使ってできることの限界を押し広げるために、どのように役立っているのかを探っていきます。
現在のデータ ランドスケープの黎明期とビッグデータの台頭
現代のエンタープライズ レポーティングとビジネス インテリジェンスは、企業が業務レポーティングの基盤としてエンタープライズ データ ウェアハウス(EDW)を使用し始めた 1990 年代に形作られていきました。EDW がビジネスの発展を把握する能力を飛躍的に向上させたことにより、
アナリストは「昨日の売上に基づく今日の在庫は?」や「先週の地域別売上高は?」などといった問いを立て、それに対する回答を導き出せるようになりました。
しかしながら、従来のビジネス指向のデータとシステムは、優位性を長く保持することはできませんでした。セルフサービス BI が利用可能になるとほぼ同時に、データを取り巻く環境が広く変化し、新しい種類のシグナルから差別化されたインサイトを生み出すための新しいツールとスキルが必要になりました。買い物習慣、コミュニケーション、エンターテイメントなど社会全体のデジタル化は、顧客のニーズをより深く理解し、それに応えていくための新たな機会を企業に与えたといえます。
新しい一連のビッグデータ ツール(Google の内部テクノロジーについて述べた学術論文の公開でさらに勢いづきました)により、データ工学の専門家はこの新しいデータを収集して保存する手段を手にし、インサイトを生み出す専門家ユーザーは保存されたデータを利用できるようになりました。組織は初期のデータレイクを構築し、少し前にセルフサービス BI の導入で利益が得られたばかりだったため、今回も早い段階で利益が出ることを期待しました。しかし残念ながら、新しいデータが公開され、アクセスできるようになっていたにもかかわらず、ほとんどのビジネス ユーザーにはインサイトを引き出すスキルがありませんでした。システムが初心者ユーザーには複雑すぎたためです。
このことからはっきりとわかるのは、ビッグデータや非構造化データを扱う新しい世界においては、データを公開して誰もがアクセスできるようにするだけでは、インサイトを得ることはできないということです。本当に重要なのは誰もがインサイトを活用できるようにすることだったのです。そして、これは使い慣れたツールの機能を拡張することで実現されるべきものでした。テクノロジーがユーザーに歩み寄るべきだったのであり、その逆ではなかったのです。こうした状況を打開すべく登場したのが Google Cloud でした。
Google Cloud: ツールを劇的にシンプルにして、インサイトを民主化
Google Cloud は、ユーザーがすでに持っているツールやスキルを活用して、インサイトを得るお手伝いをすることに力を注いできました。最初のステップはユーザーからは見えない領域で始まりました。テクノロジー スタックのバックエンドを自動化し、「サーバーレス」分析のコンセプトの開発を促進しました。このコンセプトは、リソースのプロビジョニング、規模の拡大、パフォーマンス チューニング、デプロイ、スタック管理に関連するその他の技術的なタスクをユーザー入力なしで処理するというものでした。ユーザーが必要としているのは分析だけです。そのため、ユーザー入力を実行する複雑な工程を機械に担当させ、ユーザーは仕事だけに集中する、シンプルインターフェース ツールを開発しました。
データアクセスを通じて、データ アナリストのより深いインサイトの生成をサポート
インサイトの民主化と生成において、データ アナリストほど重要な集団はいないでしょう。このペルソナに該当する人たちは通常、勤務先である Fortune 500 企業内でデータ処理に特化した従業員の最大多数を占めており、データに関する知識が豊富なうえ、解決すべきビジネス上の課題にも精通しています。SQL を介してデータ アナリストの新しい可能性を引き出すことで、お客様のビジネスにまったく新しい風を吹き込むことができました。それはこのように起こりました。
まず、コンピューティングとストレージをデカップリングすることにより、BigQuery がそれらを一緒にスケーリングする他のデータ ウェアハウスよりも多くのデータをより経済的に保存できるようになりました。これにより、お客様がデータ ウェアハウジングに対して「構造化データレイク」アプローチを採用するようになり、データ ウェアハウスの中で SQL を使用する ELT(抽出 - ロード - 変換)の普及率が上昇しました。その結果、より忠実度の高いデータがデータ ウェアハウスに蓄積されるようになったことで、データアクセスが民主化されました。さらに重要なのは、使い慣れた SQL セマンティクスを持つデータ ウェアハウスという、使い慣れたツールの中でデータアクセスが拡張されたために、インサイトの生成も民主化されたということです。
次に、アナリストがデータ ウェアハウスの外部(多くの場合 Google Cloud Storage)にあるデータにアクセスしたいと考えていることが判明しました。そこで、アナリストが SQL を介してこのデータにアクセスできる道筋を用意しました。これにより、以前は利用できなかったデータを組み込むことで、新しいインサイトを生成できるようになりました。このオブジェクト ストレージおよびデータ ウェアハウスは双方向に運用可能です。データ アナリストが SQL を使用してオブジェクト ストレージにクエリを実行できるだけでなく、データ サイエンティストやデータ エンジニアも BigQuery のデータに対して Spark ジョブを実行できます。使い慣れたツールでのデータアクセスが増えた結果、予想通り、ここでもさらに多くのインサイトが得られるようになりました。
直感的なツールを使って、ビジネスユーザーのセルフサービスでのインサイトの活用を促進
自動化システムの大きなメリットは、ビジネス ユーザーにとって使いやすいインターフェースを構築することで、独自のインサイトを簡単に得られるようになり、ビジネス ユーザーが長年当たり前と思ってきた「リクエストして待機する」という典型的なパラダイムを打ち破れることです。
ビジネス インテリジェンス ツールは、独自のインサイトを生み出したり、データ アナリストが生成した分析に基づいて意思決定を行ったりするビジネス ユーザーにとって、最も一般的なエントリ ポイントとなっています。最新の BI ツールは、インタラクティブなセルフサービス機能を提供します。これにより、ビジネス ユーザーは、直面しているビジネス上の問題の解決のための分析をカスタマイズできます。しかし、これらのツールは、データを提供するシステム以上には強力になり得ません。BigQuery はサーバーレスのバックエンドを採用しているため、データ量やユーザー数を問わず必要なスケーラビリティを提供でき、インタラクティブなセルフサービス BI をこれまでにないほど簡単に構築できます。
BigQuery は、Tableau、Qlik、Microstrategy など、一般的に使われているどの BI ツールともシームレスに連携します。Google Cloud では、Looker をポートフォリオに追加したことで、ビジネス ユーザーがダッシュボードの操作やデータドリブン型のワークフローを実行し、組織により多くの価値を生み出すことが容易になりました。企業がワークフローやアプリケーションのあらゆる段階でデータを活用することができるため、フロントライン ワーカーが当たり前のようにデータドリブン型のインサイトを活用できるようになります。このことは、Sunrun による組織横断的な指標を定義する試みや、COVID-19(新型コロナウイルス感染症)の脅威にさらされている患者を治療する医療従事者に CCA がよりよい行動につながるインサイトを提供した例などに見られるように、分野を問わず当てはまります。
データと、それを使って何かをできるはずだという期待との間には、非常に密接な関係があります。
CCA Clinical Informatics & Advanced Analytics 担当バイス プレジデント Valmeek Kudesia 医学博士
Google は、セルフサービス型のビジネス インテリジェンスを改善するだけでなく、使い慣れたツールであるスプレッドシートに新しい機能を導入することで、ビジネス ユーザーがインサイトを生成できるように支援しています。コネクテッド シートは、シンプルなスプレッドシートに慣れ親しんだ何億人ものビジネス ユーザーに、BigQuery のパワーとスケールを提供できます。これは、SQL を知らなくても何十億行、何十億ペタバイトものデータを分析して、分析結果とインサイトを提供し、データのインサイトに規模のメリットをもたらすことができるということを意味しています。
スプレッドシートに特別な機能を与えるだけでなく、BigQuery の機能を、現存する中で最も古い問い合わせシステムである自然言語に導入することで、ビジネス ユーザー(およびその顧客)向けにインサイトを民主化しました。Data QnA を利用すると、技術者ではないビジネス ユーザーでも、データに自然言語で質問をするだけで、必要なデータ インサイトに簡単にアクセスできます。BigQuery やフェデレーション データソースに格納されたペタバイト規模のデータであっても、これにより誰でも会話形式で分析できます。Data QnA は、データ分析のための最も利用しやすいセルフサービス ツールの一つであり、導入した企業に新たなインサイトとデータドリブン型の意思決定を促進する可能性を秘めています。

「Veolia では、ビジネス パートナーからのアドホック分析のリクエストに対応するのに数週間かかっていました。このモデルを使うことで時間を節約でき、より価値の高いアクティビティに時間を割くことができるようになりました」と、Veolia のデータおよびロボティック担当マネージャーである Fabrice Nico 氏は述べています。「BI チームでは、自然言語で質問することによって BigQuery データにセルフサービスでアクセスできるようになりました。スプレッドシートや chatbot を使う Google サービスのおかげで、時間の無駄が大幅に減り、当社のビジネス パートナーも自然言語ベースの分析によってスピードアップが図れるようになりました。」
最後に、リアルタイム分析と機械学習の両方に触れずして、今日のデータ インサイトを議論するのは難しいでしょう。ビッグデータの混沌とした世界からインサイトを得るために、機械学習の活用を必要とする企業がますます増えています。インサイトがデータ世界に埋もれた宝だとするならば、機械学習は金属探知機であるといえます。このたとえは、データの量が多い場合には特によく当てはまります。リアルタイムのデータ分析は、より良いカスタマー エクスペリエンスとより良い(多くは自動化された)意思決定を実現するための鍵となります。Google Cloud は、これらの機能の民主化のため、検討を重ね、多くの投資を行ってきました。詳しくは本ブログシリーズの続編をぜひお読みください。
詳細については、Google Cloud のスマート アナリティクスをご覧ください。
-データ分析担当プロダクト管理ディレクター Sudhir Hasbe
-プロダクト マネージャー Ryan Lippert

