BigLake でクエリのパフォーマンスを向上させて大規模な分析ワークロードを実行する
Google Cloud Japan Team
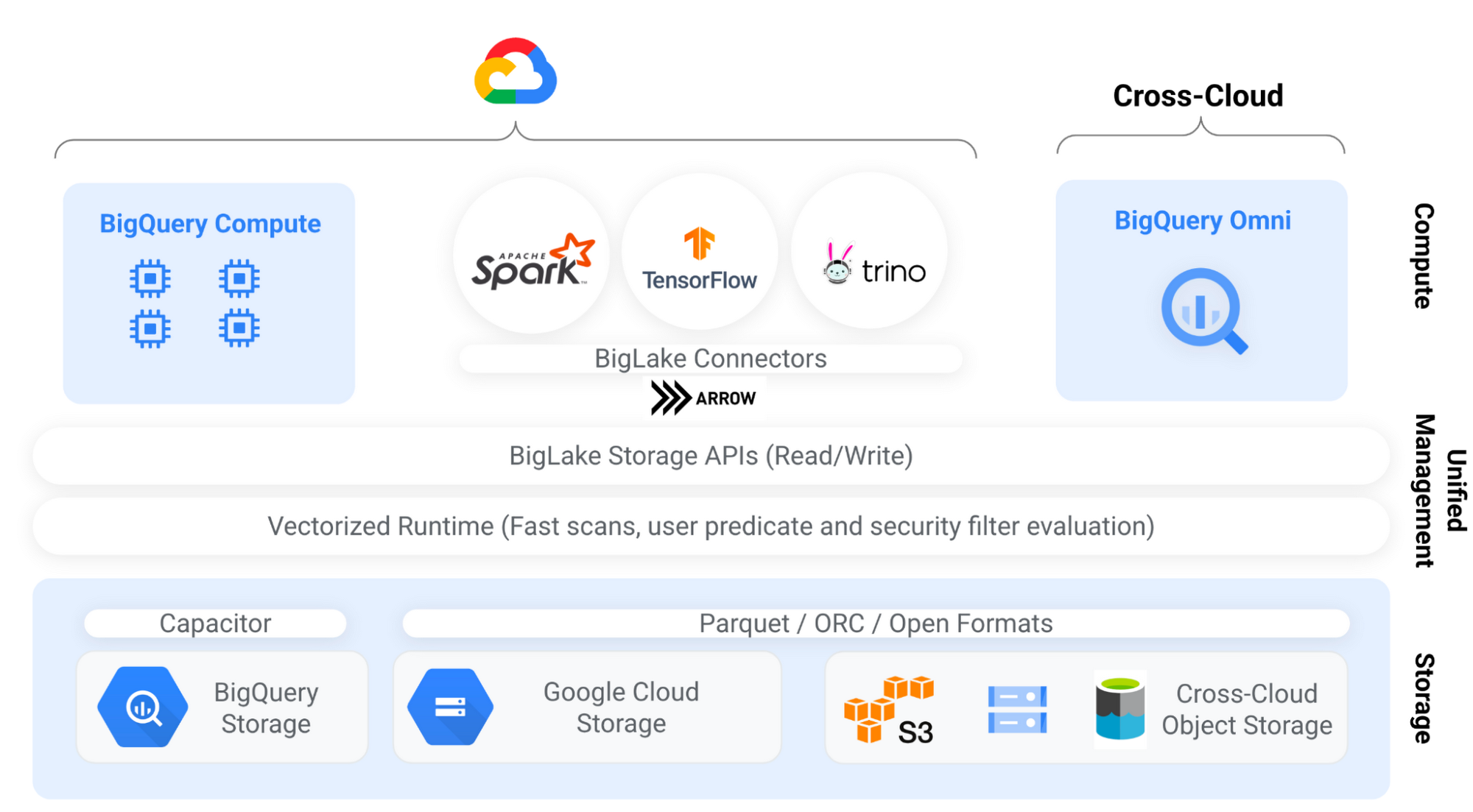
BigLake を使用すると、データの単一コピーをクラウド上のオブジェクト ストレージに保存できます。保存可能な形式は、Parquet や ORC などのオープン ファイル形式、または Apache Iceberg などのオープンソースのテーブル形式です。BigLake テーブルの分析には、BigQuery を使用するか、高パフォーマンスの BigLake Storage API を介して外部のクエリエンジンを使用することができます(現在は BigQuery Omni のサポート対象外)。この API には Superluminal が組み込まれています。これは、データの効率的なカラム型スキャンと、ユーザー述語およびセキュリティ フィルタの適用を可能にするベクトル化処理エンジンです。外部のクエリエンジンを信頼しないゼロトラストのアーキテクチャとなっており、特に任意のプロシージャル コードを実行する Apache Spark などのエンジンを利用する場合において意義をもちます。このことから、BigLake のセキュリティ モデルは業界の先頭を行くものの一つとなっています。
Google Cloud の複数のお客様が、BigLake を利用して大規模なデータ レイクハウスを構築しています。
「Dun & Bradstreet は、Google Cloud の一元的なデータレイクと統合データ処理プラットフォームを活用してデータクラウドを構築することを目指しています。当社の課題はパフォーマンスとデータの重複にありました。Google の分析レイクハウス アーキテクチャのおかげで、データの変換、ビジネス分析、ML のユースケースをデータの単一コピーに対して実行できるようになります。BigLake はまさに当社が必要としていたソリューションです。」 - Dun & Bradstreet、データ アーキテクト Hui-Wen Wang 氏
クエリのパフォーマンスの向上
Google Cloud は最近、メタデータ、クエリ プランニング、マテリアライズド ビューに新しいデータ マネジメントの手法を適用し、BigLake テーブルのパフォーマンスを改善しました。その詳細について、以降でご説明します。
メタデータの効率改善
データレイク テーブルは通常、オブジェクト ストレージ バケットでリスト オペレーションを実行するようクエリエンジンに要求します。その性質上、数百万のファイルを含む大きいバケットのリストには時間がかかります。クエリエンジンがプルーニング(枝刈り)できないパーティションでは、エンジンがファイルのフッターを確認してデータブロックをスキップできるかどうかを判断する必要があるため、オブジェクト ストアに追加で複数の IO が必要になります。効率的なパーティションとファイルのプルーニングは、クエリのパフォーマンスを高速化するうえで不可欠です。
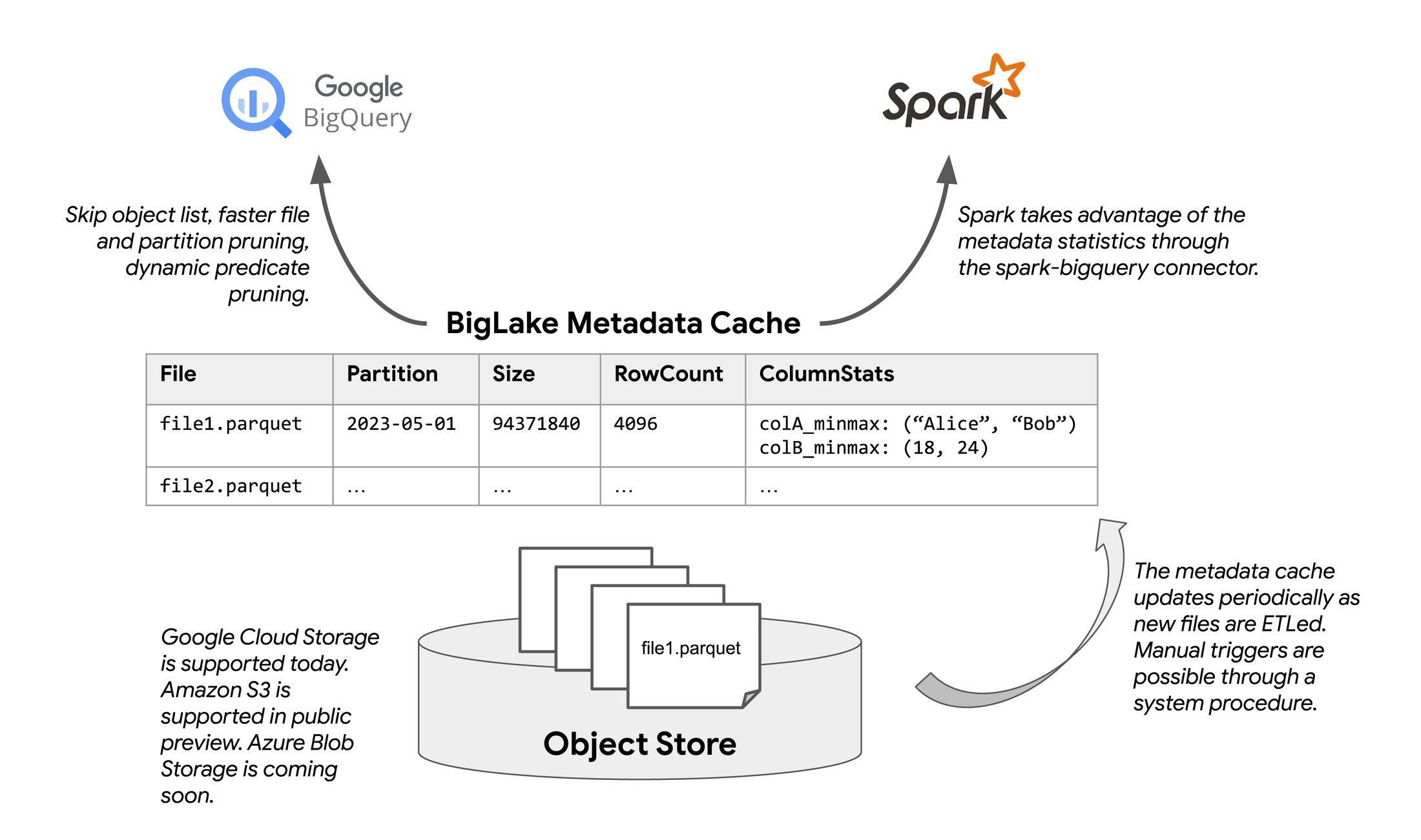
このたび、BigLake テーブル向けのメタデータ キャッシュ保存の一般提供を行うことになりました。この機能により、BigLake テーブルがオブジェクト ストレージ内のファイルに関する物理的なメタデータを自動的に収集し、維持できるようになります。BigLake テーブルは、BigQuery ネイティブ テーブル向けに導入されているものと同じスケーラブルな Google メタデータ管理システム、Big Metadata を使用します。
BigLake は Big Metadata インフラストラクチャを使用して、ファイル名、パーティショニング情報、データファイルの物理的なメタデータ(行数やファイルごとの列レベルの統計情報など)をキャッシュに保存します。このキャッシュは Hive メタストアなどのシステムよりもきめ細かくメタデータを追跡するので、BigQuery と Storage API はオブジェクト ストアからのファイルのリストを回避し、パーティションとファイルの高パフォーマンスなプルーニングを実現できます。
クエリプランの最適化
クエリエンジンは SQL クエリを実行可能なクエリプランに変換する必要があります。通常、特定の SQL クエリごとに複数のクエリプランが考えられます。クエリ オプティマイザーの目標は、最適なプランを選択することです。一般的なクエリ最適化では制約が動的に反映され、クエリ オプティマイザーが、小さなディメンション テーブルから結合した大きなファクト テーブルの述語を動的に推測します。この最適化によって、正規化されたテーブル スキーマを使用したクエリが高速化されますが、ほとんどの実装では、一定の精度があるテーブル統計情報が必要とされます。
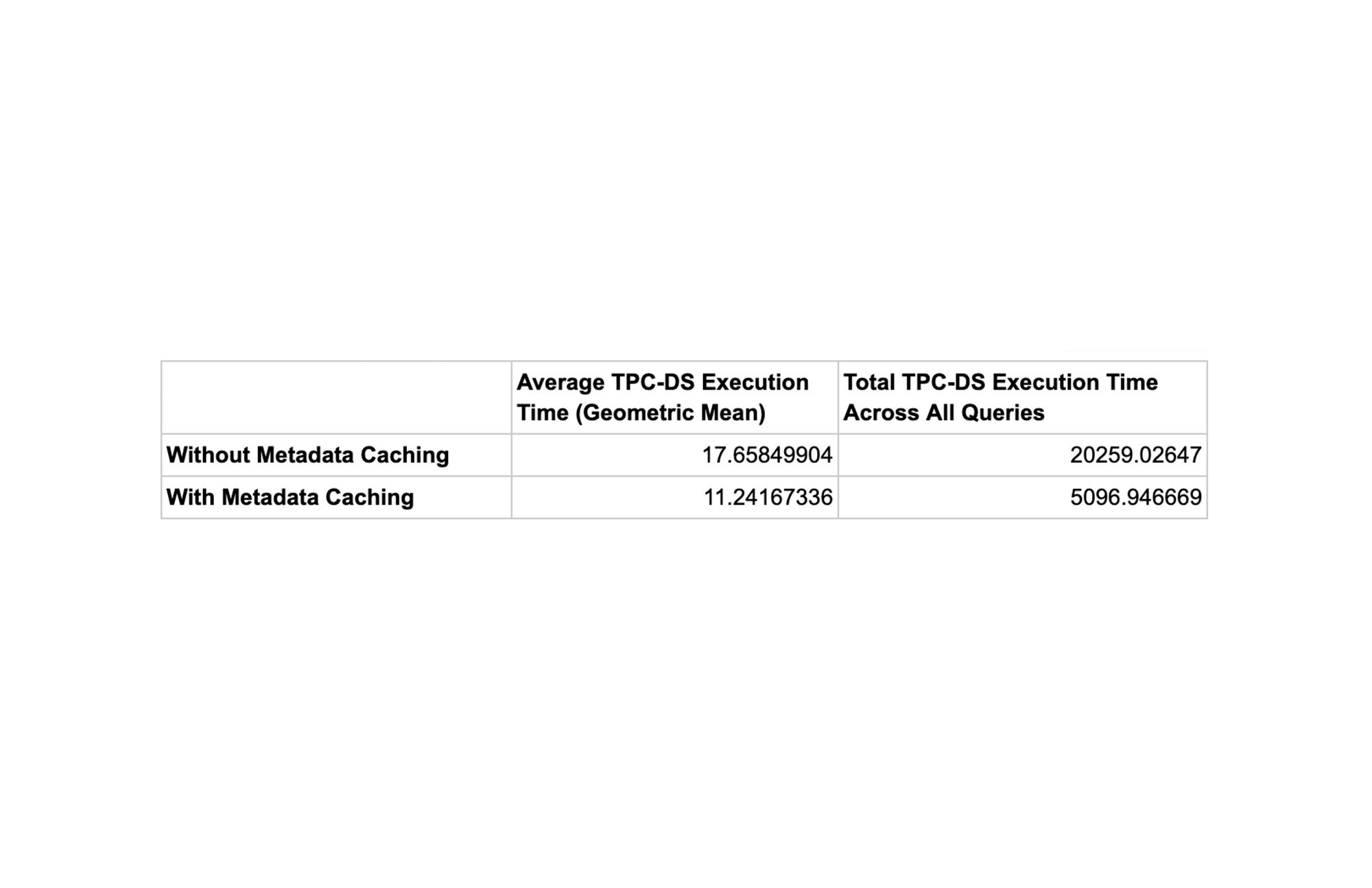
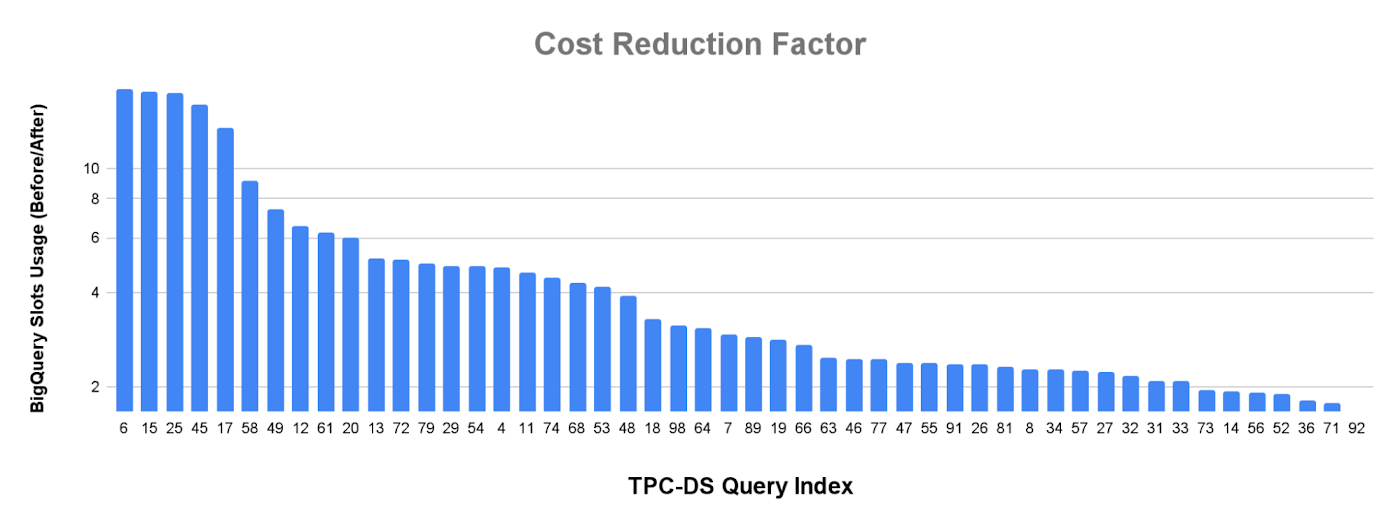
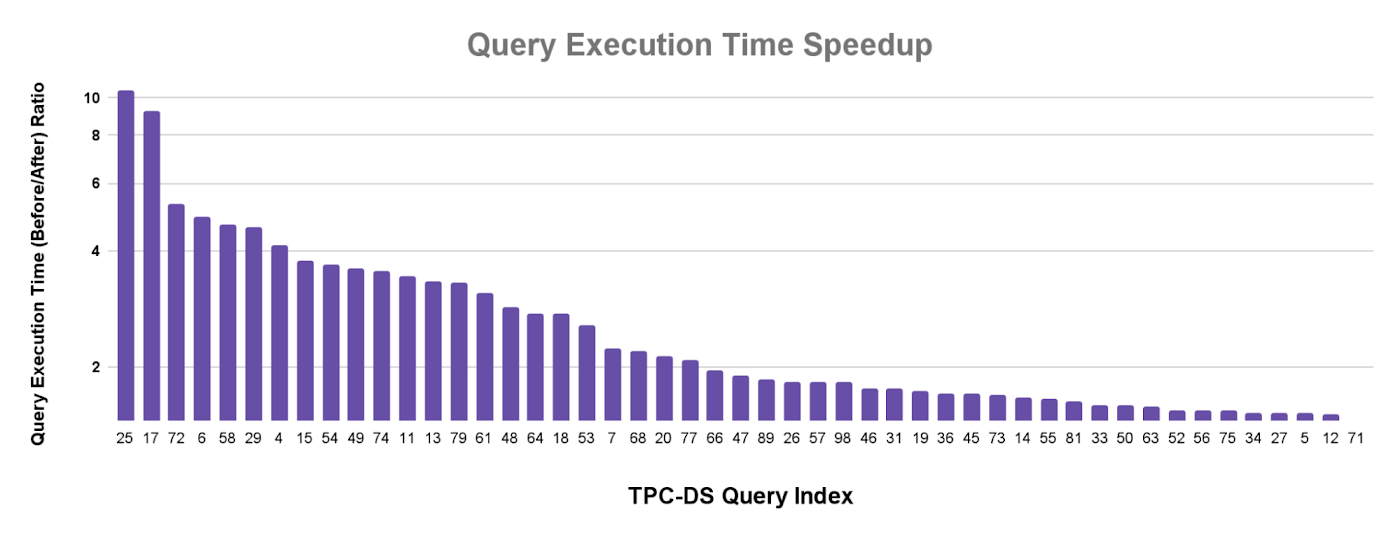
メタデータ キャッシュ保存で収集された統計情報により、BigQuery と Apache Spark の両方が最適化された高パフォーマンスのクエリプランを構築できます。パフォーマンスがどの程度向上したかを測定するために、各クエリが順次実行される TPC-DS ベンチマーク(Hive パーティション分割、10T)のパワーランを実行しました。Cloud Storage バケットと BigQuery データセットの両方が us-central1 リージョンにあり、2,000 スロットの予約が使用されました。以下のグラフは、BigLake メタデータ キャッシュによって収集された統計情報を介して、BigQuery のスロットの使用状況とクエリの実行時間がどのように改善したかを示しています。メタデータ キャッシュ保存によって、実行の実時間がおおむね 4 分の 1 に削減されました。
Spark のパフォーマンスの飛躍的な向上
オープンソースの Spark BigQuery コネクタを使用すると、BigQuery テーブルと BigLake テーブルを Apache Spark DataFrame に読み込むことができます。このコネクタは内部で BigQuery Storage API を使用し、Spark の DataSource インターフェースを使用して Spark に統合されます。
Google Cloud は最近、Spark BigQuery コネクタに以下のような機能改良を加えました。
動的なパーティション プルーニングのサポート
結合の順序変更とエクスチェンジの再利用の強化
改善された Spark のクエリ プランニング: テーブル統計情報が Storage API を介して返されるようになりました
非同期またはキャッシュに保存された統計情報のサポート
BigLake テーブルのマテリアライズド ビュー
マテリアライズド ビューは、クエリの結果を定期的にキャッシュに保存してパフォーマンスを改善する、事前に計算されたビューです。BigQuery のマテリアライズド ビューに対して直接クエリを実行できるだけでなく、BigQuery オプティマイザーでマテリアライズド ビューを使用してベーステーブルに対して直接実行するクエリを高速化することもできます。
このたび、BigLake テーブルのマテリアライズド ビューのプレビューをリリースすることになりました。このマテリアライズド ビューは BigQuery ネイティブ テーブルのマテリアライズド ビューと同様に機能し、自動更新や自動メンテナンスなどを行います。BigLake テーブルのマテリアライズド ビューは BigLake テーブルの集計、フィルタ、結合を事前計算できるため、クエリを高速化できます。マテリアライズド ビューは BigQuery ネイティブ フォーマットで保存され、BigQuery ネイティブ ストレージのパフォーマンス特性をすべて備えています。
次のステップ
外部 BigQuery テーブルを使用している場合は BigLake テーブルにアップグレードし、メタデータ キャッシュ保存とマテリアライズド ビューに関するドキュメントを参考にして各機能をご利用ください。パフォーマンスが改善した Spark を活用するには、新しいバージョンの Spark(3.3 以上)と Spark-BigQuery コネクタを使用します。詳細については、こちらの BigLake テーブルの概要と BigLake のプロダクト ページをご覧ください。
この投稿に協力してくれた、以下の各位に感謝します。
Kenneth Jung、Micah Kornfield、Garrett Casto、Zhou Fang、Xin Huang、Shiplu Hawlader、Fady Sedrak、Thibaud Hottelier、Lakshmi Bobba、Nilesh Yadav、Gaurav Saxena、Matt Gruchacz、Yuri Volobuev、Pavan Edara、Justin Levandoski、その他の BigQuery エンジニアリング チームのメンバー。Abhishek Modi、David Rabinowitz、Vishal Karve、Surya Soma、その他の Dataproc エンジニアリング チームのメンバー。
- Google Cloud、ソフトウェア エンジニア Deepak Nettem



