Dataplex データ プロファイリングと自動データ品質によって信頼性の高い分析情報を提供
Google Cloud Japan Team
※この投稿は米国時間 2023 年 9 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
このたび、Dataplex でのデータ プロファイリングと自動データ品質(AutoDQ)の一般提供が始まりましたのでお知らせいたします。これらの機能により、Google Cloud のお客様は、スケーラブルかつ自動化された方法で分析データの信頼性を高めることができます。
イノベーション、意思決定、差別化されたカスタマー エクスペリエンスを高品質データで促進
データ品質は常に、分析や ML モデルを成功させるために不可欠な基盤です。ここ半年における AI の急速な台頭により、ML モデルの利用が爆発的に増加しました。ML におけるデータ品質の重要性は、ここ数か月でさらに高まっています。データ サイエンティストやアナリストは、モデルを構築する前にデータをより深く理解する必要があり、そのことが最終的に、より正確で信頼性の高い ML の成果につながります。
Dataplex のデータ プロファイリングと AutoDQ を使用すると、スケーラブルかつ効率的な方法で、この情報を簡単に構築および維持できるようになり、以下のことが可能になります。
データに関する分析情報を得るまでの時間を短縮
- Dataplex を使用すると、データのプロファイルや品質を簡単かつ迅速に確認できます。これらの機能には設定要件がなく、BigQuery UI 内で簡単に開始できます。
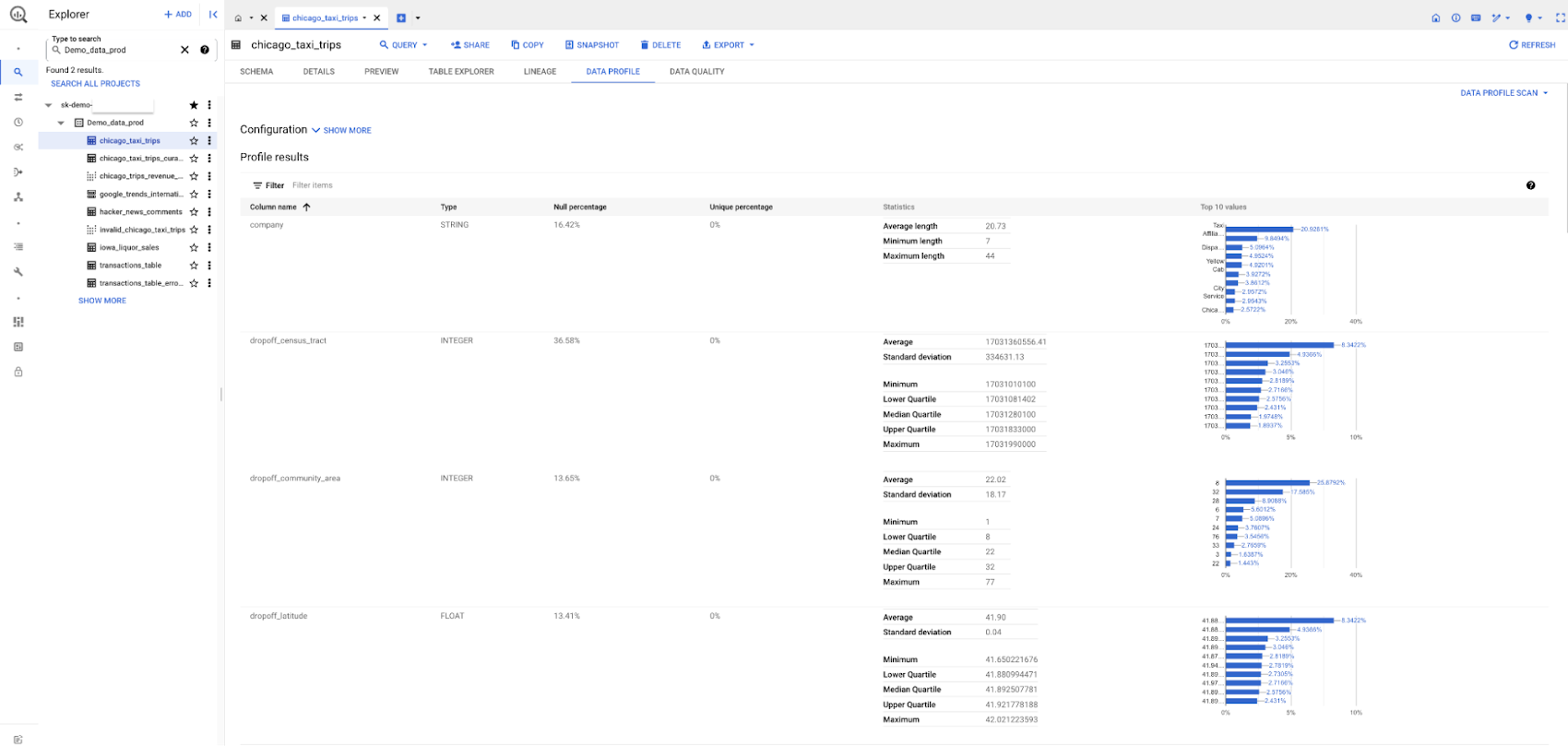
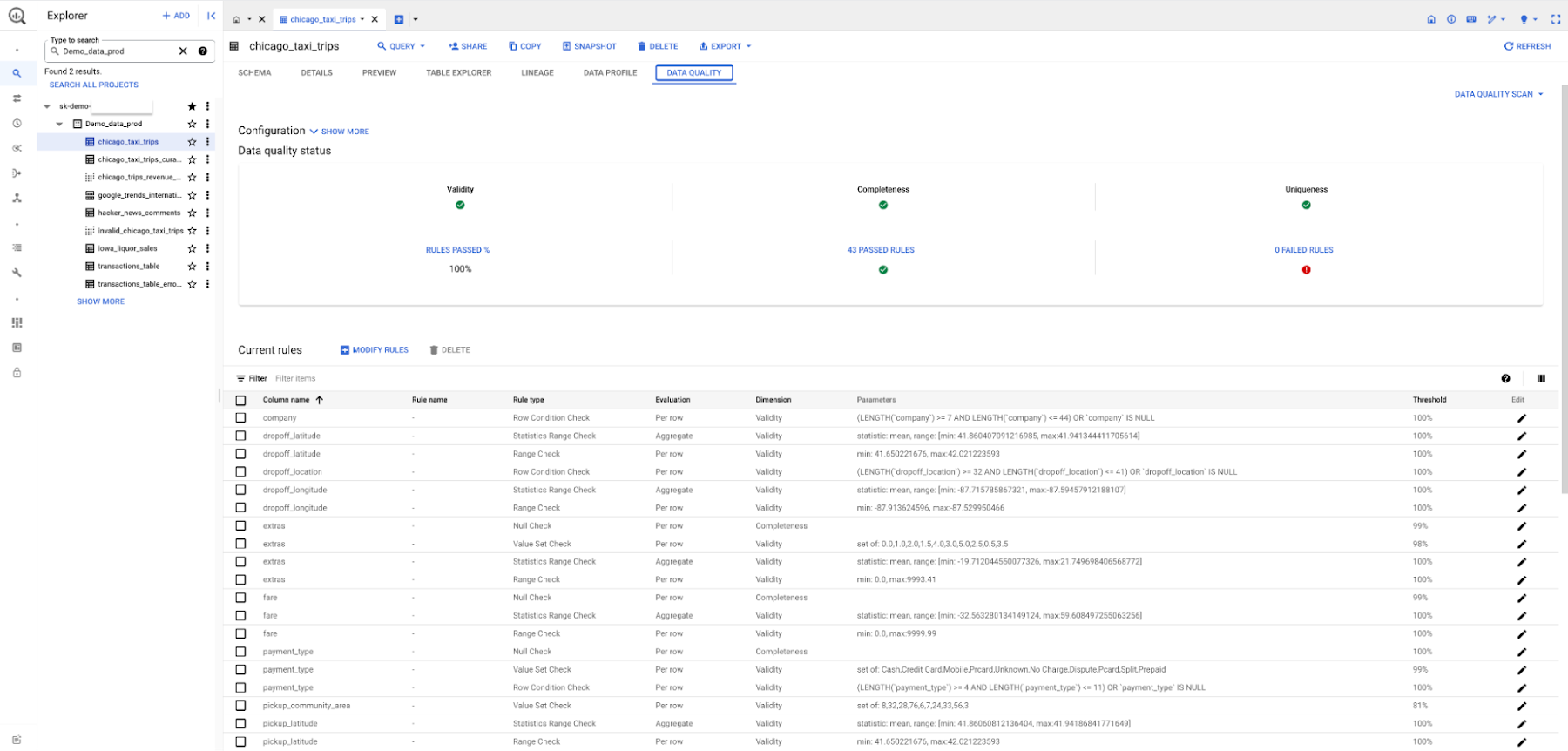
- Dataplex AutoDQ を使用すると、インテリジェントな推奨ルールから始めて、短時間で品質レポートを生成できます。同様に、Dataplex データ プロファイリングを使用すると、データの分散、上位 N、一意の値の割合などの有意義な分析情報をワンクリックで生成できます。
充実したプラットフォーム機能
- プラットフォームの基盤となる機能により、好みに合わせてカスタマイズしたエンドツーエンドのソリューションを構築できます。
- Dataplex AutoDQ は、ルールからレポートやアラートまでのデータ品質ソリューションを可能にします。AutoDQ のルールには、高度なユースケースのために BigQuery ML を組み込むこともできます。
- 一方、データ プロファイリングで生成される情報を使用して、トレーニング データ内の意味のあるシフトを検出するためのドリフト検出などのカスタム AI / ML モデルを構築できます。
セキュリティ、パフォーマンス、効率的な実行
- これらの機能は、データをコピーすることなくペタバイト規模のデータを処理できるように設計されています。BigQuery のスケールアウト能力をバックグラウンドで利用していますが、お客様の BigQuery スロットや予約への影響はありません。
Dataplex のデータ プロファイリングと AutoDQ は、組織がデータ品質を向上させ、より正確で信頼性の高い分析情報やモデルを構築するのに役立つ優れた新しいツールです。
お客様の声
Dataplex のデータ プロファイリングと AutoDQ に関するお客様の声をご紹介します。
「Paramount では、複数のベンダーからデータを入手しているため、ときどき、さまざまなソースや統合チャネルからのデータで異常が発生することがあります。そこで、Dataplex AutoDQ と BigQuery ML を導入し、リアルタイムで異常を検出してアラートを発信するという課題に取り組み始めました。これは効率的であるだけでなく、データの精度も向上します。」- Paramount Global、データ エンジニアリング担当シニア バイス プレジデント Bhaskara Peta 氏
「Orange は、常にイノベーションの最先端に立っており、イノベーションの原動力となる信頼できる分析情報に依存しています。データと AI のワークロードを GCP に移行するにあたり、データ エンジニアリング チームにシームレスなエクスペリエンスを提供できる、エレガントな統合データ品質サービスを探していました。当社は非常に早い段階から Dataplex AutoDQ を利用しており、この機能がデータの民主化への取り組みにおいて強固な基盤になると信じています。今後も Google と提携して、より革新的でより優れたロードマップを構築していきたいと考えています。」 - Orange、データおよび AI 担当テクニカル リード Guillaume Prévost 氏
新機能
公開プレビュー版の提供開始以降、以下の魅力的な機能が追加されています。
Dataplex に加えて BigQuery UI でも構成と結果の表示が可能
Dataplex に加えて、BigQuery からもデータ品質とデータ プロファイリングのタスクを直接実行できるようになりました。データオーナーはデータスキャンを構成でき、データ プロファイリングやデータ品質のスキャンの最新の結果を BigQuery のテーブル情報の横に公開できます。この情報は、テーブルが存在するプロジェクトに関係なく、適切な権限を持つユーザーであれば誰でも閲覧できます。これにより、ユーザーはデータ品質とデータ プロファイリングを簡単に開始できるようになり、データ管理に使用するあらゆるツールでより一貫性のあるエクスペリエンスが提供されます。
新しいデプロイ オプション
充実した UI に加え、データ品質やデータ プロファイリングのスキャンを作成、管理、デプロイするためのサポートが追加されました。以下の方法を利用できます。
- Terraform: データ品質やデータ プロファイリング リソースをデプロイおよび管理するためのファースト クラスの Terraform オペレータを使用できます。
- Python および Java クライアント ライブラリ: コードから Dataplex のデータ プロファイリングや AutoDQ を簡単に操作できるようにする Python および Java 用のクライアント ライブラリを提供します。
- CLI: コマンドラインからスキャンの作成、管理、デプロイに使用できる包括的な CLI も提供します。
- YAML: CLI や Terraform を使用する場合、YAML ベースの仕様を使用してスキャンを作成および管理できます。
また、Airflow オペレータをデータ品質に利用できるようにし、エンジニアがデータ プロダクション パイプライン内でデータ品質チェックを構築できるようにしました。Airflow オペレータにより、データ エンジニアは AutoDQ をより柔軟に使用できるようになり、データ品質チェックを既存のデータ パイプラインに簡単に統合できるようになります。

費用削減と機密データ保護のための新しい構成オプション
Dataplex のデータ プロファイリングと AutoDQ の中核機能を強化したことで、これまで以上にフレキシブルでスケーラブルになりました。
- 行フィルタ: 行フィルタを指定することで、特定のセグメントのデータに焦点を当てたり、特定のデータをスキャン対象から除外したりできるようになりました。これは、コンプライアンスやプライバシーなど、特定のユースケース向けにスキャンをチューニングする場合に便利です。
- 列フィルタ: 列フィルタを指定することで、機密性の高い列のデータの公開を回避できるようになりました。これは、機密データを不正アクセスから保護するのに役立ちます。
- サンプリング: クイックテスト用にデータをサンプリングし、費用を削減できるようになりました。これは、データセット全体をスキャンすることなく、データ品質やデータ プロファイリングの概要を簡単に把握する場合に便利です。
レポートやダウンストリーム ML モデルの構築
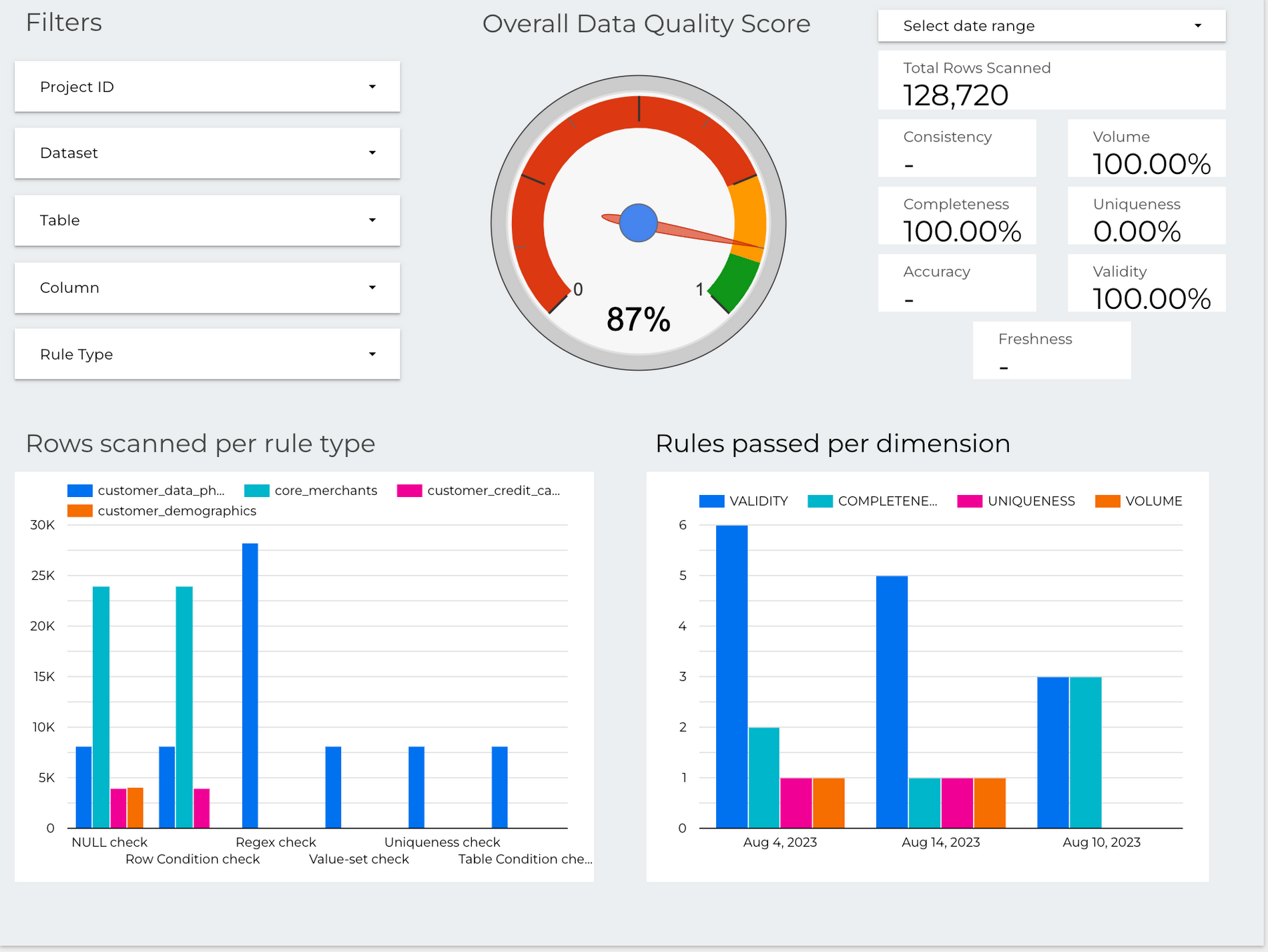
Dataplex のデータ プロファイリングと AutoDQ は、指標を BigQuery テーブルにエクスポートすることもできます。これにより、以下のような指標を使用するダウンストリーム アプリケーションを簡単に構築できます。
- ドリフト検出: BQML を使用して、指標の想定値を予測するモデルを構築できます。その後、このモデルを使用して、データ ドリフトを示す指標の変化を検出できます。
データ品質ダッシュボード: データドメインの指標を可視化するダッシュボードを構築できます。これは、データ品質の問題を特定するのに役立ちます。
データに対する信頼を築くために Google と提携してくださったお客様に感謝しています。Google がこれらの機能を一般提供することで、さらに多くのお客様にメリットを享受していただけることを願っています。
その他のリソース
- 最初に BigQuery 公開データでデータ プロファイリングやデータ品質のスキャンを作成する
- Dataplex データ プロファイリングの詳細
- Dataplex AutoDQ の詳細
- サンプル スクリプトと Airflow DAG を含む Git リポジトリ
-プロダクト マネージャー Sandeep Karmarkar
-エンジニアリング マネージャー Jitendra Koshti



