Deliver trusted insights with automatic data quality
Sandeep Karmarkar
Group Product Manager
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialToday we announce new Dataplex features: automatic data quality (AutoDQ) and data profiling, available in public preview. Dataplex is an intelligent data fabric that provides a way to manage, monitor, and govern your distributed data at scale. AutoDQ offers automated rule recommendations, built-in reporting, and serveless execution to construct high-quality data. Data profiling delivers richer insight into the data by identifying its common statistical characteristics.
Reliable and consistent data presents an invaluable opportunity for organizations to innovate, make critical business decisions, and create differentiated customer experiences. But poor data quality can lead to inefficient processes and possible financial losses. Data quality used to be more manageable when the data footprint was small and data consumers were few. Data users could easily collaborate to define rules and include those in their analytics. However, organizations are now finding it challenging to scale this manual process as the data grows in volume and diversity, along with its users and use cases. They are struggling to standardize on data quality metrics as multiple data quality solutions sprawl across the organization . Very often, this leads to inconsistency and confusion.
Dataplex AutoDQ and data profiling now enable next-generation data profiling and data quality solutions that automate rule creation and at-scale deployment of data quality. The profiling capabilities also assist in improved discovery and auditability of the data.
Auto data quality and data profiling features offer:
An intelligent and integrated experience. It eliminates the learning curve by providing rule recommendations, an intuitive rule-building experience, and a zero-setup execution. It enables standardized reporting with built-in reports.
Extensibility for different data personas without creating silos. It is also extensible to accommodate the needs of different data personas. It enables data producers to own and publish the quality, while allowing data consumers to extend the reports according to their business needs.
Automation at scale. It scales transparently with the data. It will further utilize Dataplex’s attribute store mechanisms to enable at-scale definition and monitoring.
These preview features are the foundation for a future where data quality will be part of everyday data discovery and analysis.
“Reliable data is incredibly important in our decision- making to ensure we maintain customer trust. These next-generation data quality and profiling capabilities in Dataplex provide us with at-scale automation and intelligence that enables us to simplify our current processes, reduce manual toil, and standardize data quality leveraging built-in reporting and alerting.” — Jyoti Chawla, CTO and Head of Architecture, CDO, Deutsche Bank.
“We use energy data to build innovative models for power prediction, resource planning, and energy trading recommendations. To validate training and prediction data, we are actively evaluating the ‘Auto data quality’ feature from Dataplex. We have so far been impressed by its simplicity, intuitiveness, and intelligent recommendations". — João Caldas, Head of Analytics and Innovations at Casa dos Ventos.
Flexible data model
These Dataplex features offer a data model that can accommodate multiple personas and deployments. As a user of these features, you create one or more “data scans” for a table.
These data scans
are of type “data profiling” or “data quality”
are entirely serverless
can be triggered with a built-in serverless scheduler or triggered on-demand with external triggers
can be run incrementally (on the newer data) or on the entire data.
And, if you are a data producer, you can configure it to publish the results to the data catalog (coming soon!)
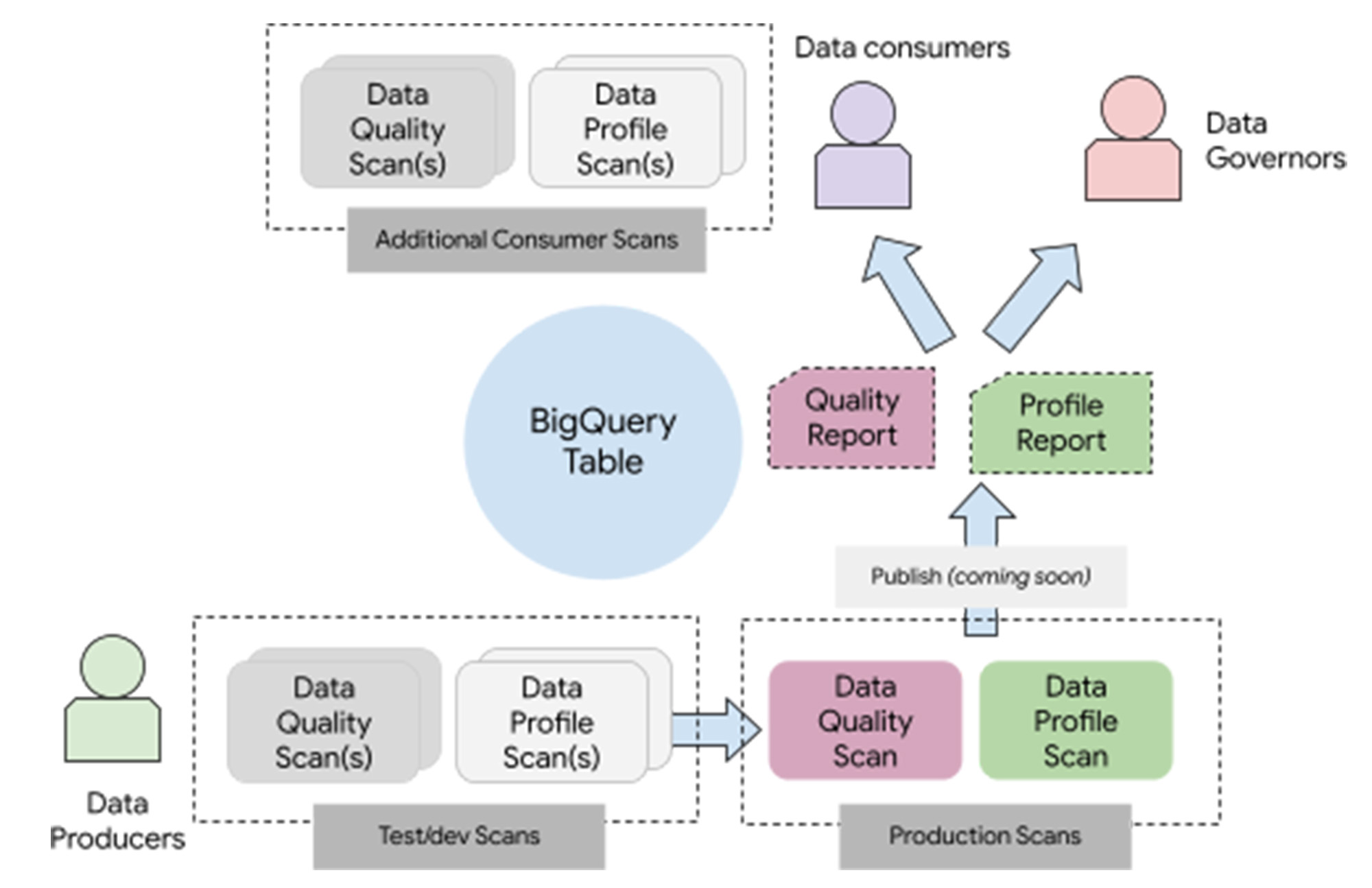
With this model - data producers can create and test new data scans and move them to production by publishing the results. Data consumers can consume the published results and add their data scans if required.
On top of this fundamental model - we have built intelligence and a rich UI to make it easy and intuitive to start.
To elaborate further, let’s take a sample table from BigQuery public datasets - chicago- taxi-trips (source). We will walk through the definition, execution, monitoring, and troubleshooting capabilities offered by these new features.
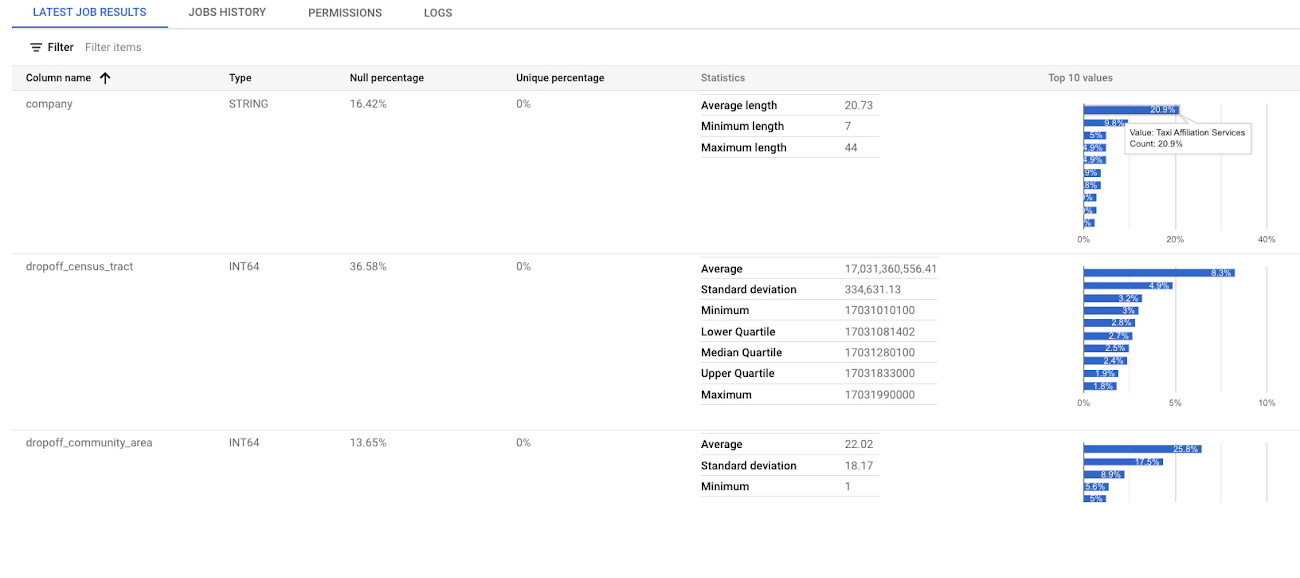
Profile your data with a few simple clicks
With a few clicks - you can create a data profile scan for this table in Dataplex. Data profile scan results are available in the UI and include various column statistics and graphs. Following graph shows Null %, unique %, and statistics for columns in the taxi data, along with the top-10 values in those columns.
Get recommendations for data quality rules
For building a data quality scan, we offer rule recommendations and a UI-driven rule-building experience. You can also create new rules using a few predefined rule types or your SQL code.
For recommendations - you can pick a profile scan to get recommendations from.
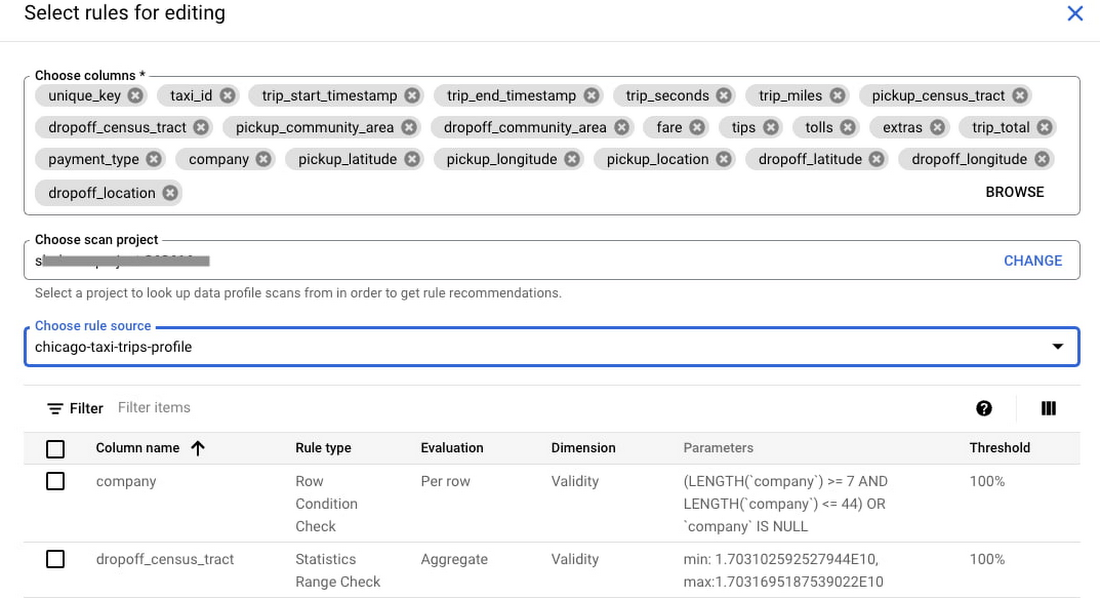
Note that each rule is associated with a data quality dimension and has a passing threshold.
E.g., Here is a recommended rule that recognizes payment_type should be one of the few detected values in the column.

Zero-data-copy execution
Data quality checks are executed in the most performant manner on internal Bigquery resources, and no data copy is involved when executing these queries.
View reports within Dataplex
You can schedule these checks within Dataplex or execute those through external triggers. In either of the cases - the results are available within Dataplex as a data quality report.
Scorecard to view the last seven runs:
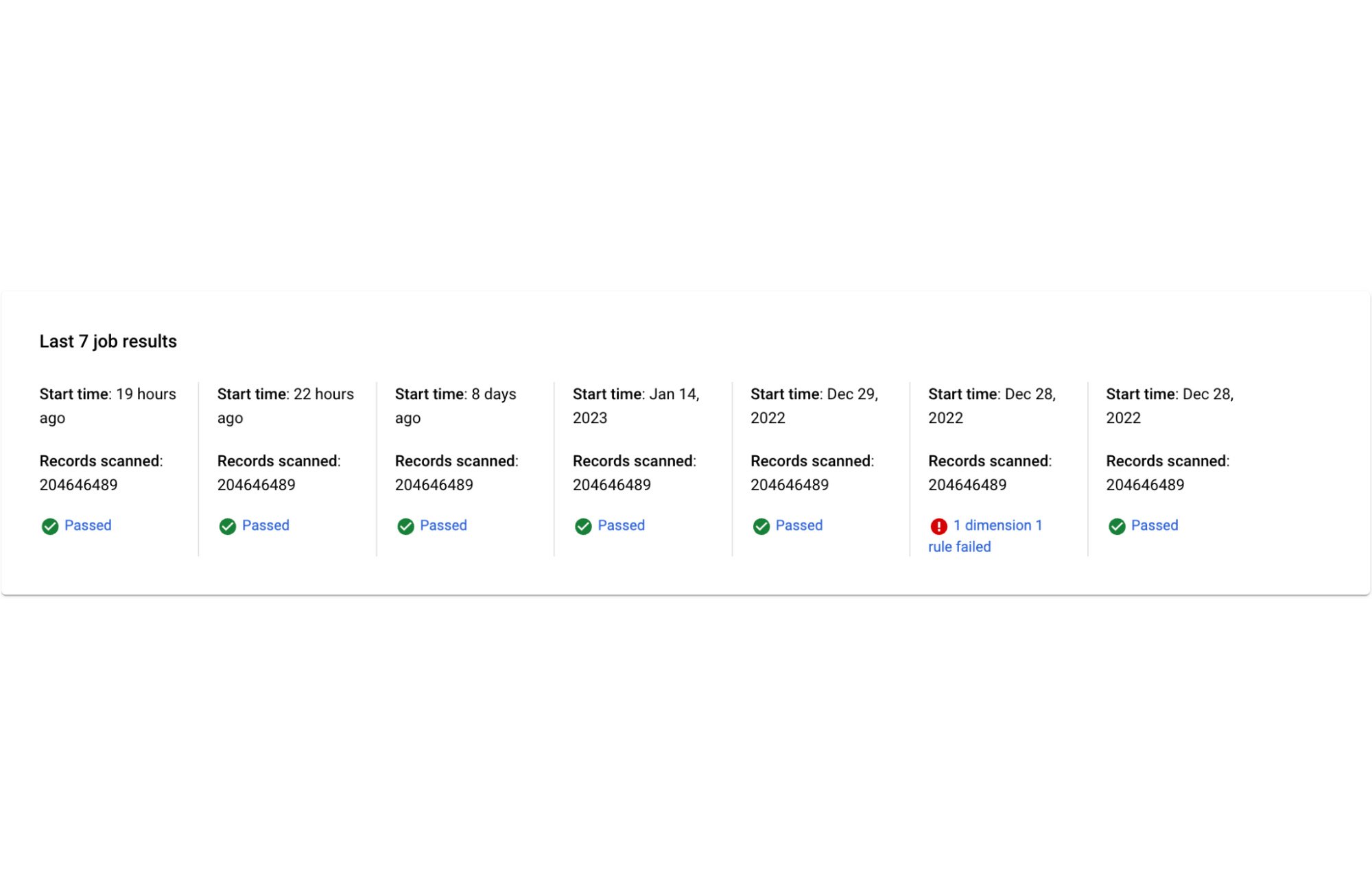
You can also drill down into past runs. Every scan execution also preserves the rules that were used for that execution.
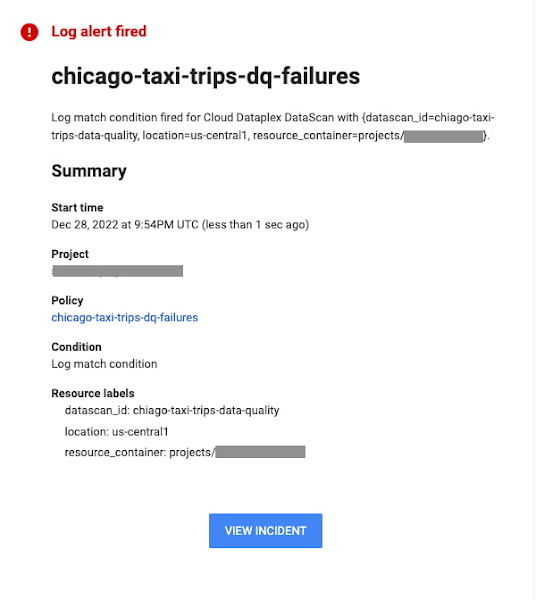
Set alerts through cloud logging
Data quality scan generates log entries in Google cloud logging, using which you can set alerts on failures of a particular scan or even of a particular dimension. Your email alert could look something like this.
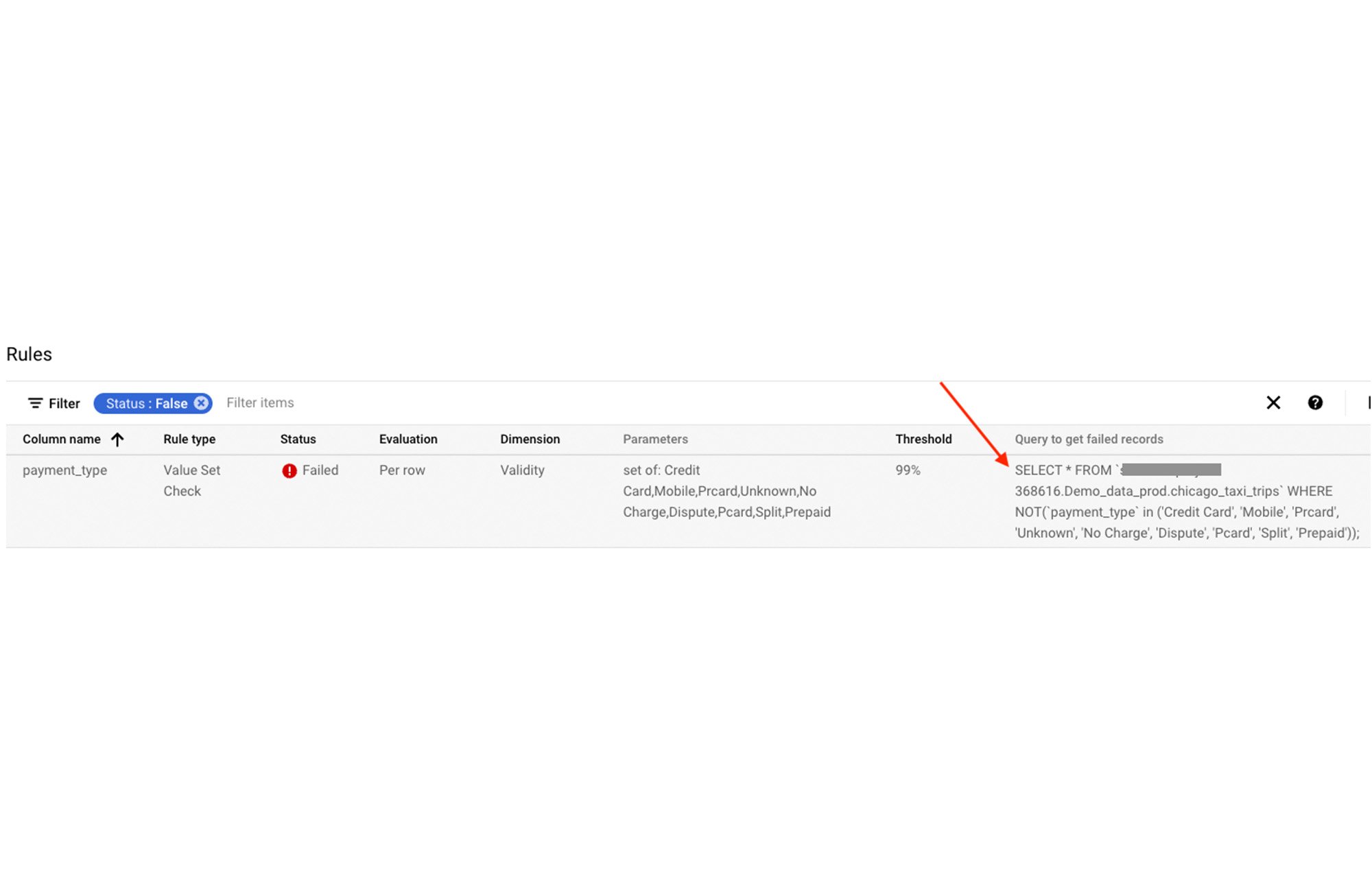
Troubleshoot data quality issues
To troubleshoot a data quality rule failure, we assist users with a query that can generate records that triggered the failure.