マネージド型 Kafka でオンプレミスのデータレイクを移行およびモダナイズ
Google Cloud Japan Team
※この投稿は米国時間 2020 年 7 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
データ分析はテクノロジーの中でも迅速に変化する分野であり、クラウド データ ウェアハウスはビジネスにデータの分析の新たな選択肢をもたらしています。一般的に、組織はビジネスの分析のユースケース向けにデータを収集するためにデータ ウェアハウスを使用しています。データレイクは、より多くの種類のデータを保存および使用できる新しい選択肢として出現しました。しかし、データレイクを正しい方法で設定して、ビジネスのニーズを満たさなくなる事態を避けることが重要です。
「すべてを保存する」データレイクの出現
データ ウェアハウスには、理解の進んだデータの種類に対するよく定義されたスキーマが必要です。これは、長期間使用される変化しないデータソースや、よく整形されたデータの保存場所としての用途には最適ですが、このようなスキーマに適合しないデータが取り込まれないままになる可能性があります。組織が新たな、または変化するデータ形式や分析要件に対応するために従来のウェアハウスを移行するにあたり、データレイクがデータの中央リポジトリとなり、最終的に分析に使用される保存場所に読み込む前のデータの拡張、集約、フィルタなどを行う場として使われるようになっています。
よく定義されたストレージのスキーマにデータを強制的に入れ込むことは難しい場合があり、ましてやデータをクエリするのは言うまでもなく困難なため、データ ウェアハウスを補完し、以前は不可能だった量のデータを格納してさらなる分析や知見を抽出できるようにする手段として、データレイクが出現しました。データレイクでは、ビジネス、アプリケーション、他のソフトウェア システム運用のすべての側面を、データとして単一のリポジトリ内に取り込むことができます。データレイクの前提となっているのは、それがさまざまな種類のデータにアクセスできる低コストのデータ保存場所であるという点です。ビジネスはこのデータから、新たな収益源の増加や、以前はリーチできなかったオーディエンスへのエンゲージメントを可能にする分析情報を手に入れることができます。
データレイクは簡単にペタバイト規模、さらには企業ではエクサバイト規模まで急速に拡大可能で、よく定義されたスキーマへの順応から解放され、データに対する「すべてを保存する」アプローチを採用できます。豊富なインサイトを含む非構造化データの例としてはメール、ソーシャル メディア フィード、画像、動画がありますが、多くの場合はうまく利用されていません。企業はすべての構造化データと非構造化データを将来使用するために保存します。このデータのほとんどは非構造化データであり、独立調査によると、分析に使用される非構造化データは 1% 以下にとどまっています。
オープンソースのソフトウェアとオンプレミスのデータレイク
2010 年代前半に、Apache Hadoop は企業がデータレイクを構築するメインのプラットフォームの一つとして出現しました。Hadoop はデータ ウェアハウスと並んでよりコスト効率の良いリポジトリとなり得るものの、データの保存先のデータレイクの価値を活かしきれない可能性もあります。また、各データソースを Hadoop ファイル システムと直接統合することは、非常に時間のかかる方法であり、結果として Hadoop がデータを利用するのはバッチ処理やマイクロバッチ処理のためのみ、ということになります。この種のデータ キャプチャは、行動につながる一連の知見をリアルタイムに生み出せず、リアルタイム処理や他のリアルタイム アプリケーションとの同期には向いていません。すぐに Hadoop のデータレイクは受動的で、コストがかかるものとなり、価値が下がってしまいます。
ここ数年で、リアルタイムのデータ ストリームの流れにおいて新たなアーキテクチャが出現しています。特に、Apache Kafka は、企業が社内全体でデータ ストリームのための中央ハブを持つことができる、人気のイベント ストリーミング プラットフォームとなるまでに成長しました。大部分のビジネスの中心システムは、イベントのストリームを作り出します。小売業には注文、販売、発送、価格調整というストリーム、金融業には株価の価格変動、注文、購入と販売の実施、ウェブサイトにはクリック、インプレッション、検索というストリームがあります。他の企業ソフトウェア システムには、リクエスト、セキュリティ検証、マシンの指標、ログ、場合によってはエラーというストリームがあります。
オンプレミスの Hadoop システムの管理の複雑性により、多くの組織は、Kafka などの他のオープンソースのテクノロジーへ行った投資を維持しながら、クラウドのデータレイクをモダナイズすることを検討しています。
最新のデータレイクの構築
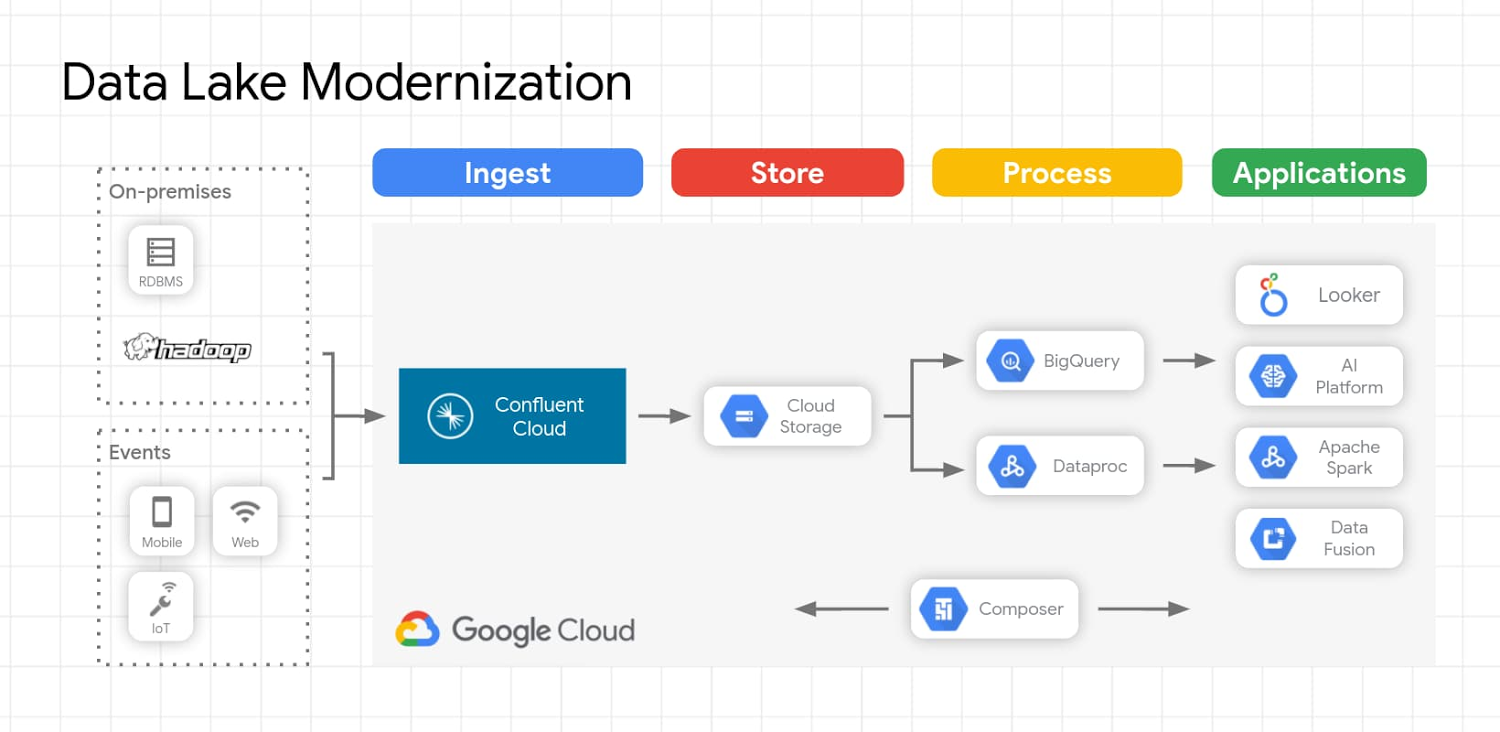
Apache Kafka や、Confluent Cloud などのフルマネージド Apache Kafka サービスを使用する最新のデータレイク ソリューションにより、組織はオンプレミスのデータレイク内の既存の豊富なデータを使用しながら、そのデータをクラウドへと移行できます。組織がデータをオンプレミスからクラウド ストレージに移行する理由は、パフォーマンスと耐久性、強整合性、コスト効率性、柔軟な処理、セキュリティなどさまざまです。こうした理由に加えて、データレイクでは、バッチとストリーミング データの両方からさらなる分析情報を取得するために役立つ AI Platform などの他のクラウド サービスのメリットを活用できます。データレイクへのデータの取り込みは、Apache Kafka や Confluent を使用して実現できます。また、Kafka ワークロードのデータレイクの移行は、Confluent Replicator を使用して簡単に行えます。Replicator を使用すると、ある Kafka クラスタから別の Kafka クラスタへとトピックを簡単に、信頼性の高い方法で複製できます。複数のトピック内のメッセージを継続的にコピーし、必要に応じて、ソースのクラスタと同じトピックの構成を使用して、移動先のクラスタ内にトピックを作成します。これには、パーティションの数とレプリケーション ファクターの維持、個々のトピックに対して指定した構成の上書きが含まれます。
Unity はこの技術を使用して、パブリック クラウド間での大量のデータの転送をダウンタイムなしで実現しました。この機能を使用して個々のワークロードのデータを移行することで、最も重要なワークロードをクラウドへ選択的に移行できたという事例もあります。事前にビルドされたコネクタにより、ユーザーは Hadoop データレイクに加えて、Teradata、Oracle、Netezza、MySQL、Postgres などの他のオンプレミスのデータストアからデータを移動できます。
データレイクが移行され、新たなデータがクラウドにストリーミングされれば、お客様は特定のユースケースに合わせた最適な処理エンジンを使用したデータの分析に注力できます。データのクエリが必要なユースケースでは、データの取り込みと同時にデータを定義済みスキーマ内に保存できます。たとえば、Avro 形式で取り込まれ Cloud Storage に保存されたデータでは次のことが可能です。
Dataproc 上のオンプレミスの Hadoop アプリケーションを再利用してデータをクエリする
BigQuery をクエリエンジンとして活用し、Cloud Storage からデータを直接クエリする
Dataproc や Dataflow などの処理エンジンを使用して事前処理を行い、BigQuery にデータを読み込む
Looker を使用して機能豊富な BI ダッシュボードを作成する
Google Cloud Storage、BigQuery、Pub/Sub などの一般的なエンドポイントへの接続は、Confluent Cloud に含まれるフルマネージドのコネクタとして利用できます。
以下に、このアーキテクチャが Google Cloud でどのようなものになるのか例を示します。
Google Cloud のデータレイクと Kafka のワークロード移行については、7 月 23 日午前 10 時(太平洋時間)から開催されるウェブセミナー、Modernizing Your Hadoop Data Lake with Confluent Cloud and Google Cloud(Hadoop データレイクを Confluent Cloud と Google Cloud で刷新する)で取り上げます。ぜひご参加ください。
-カスタマー エンジニア Jorge Geronimo



