Migrate and modernize your on-prem data lake with managed Kafka
Jorge Geronimo
Customer Engineer
Data analytics has been a rapidly changing area of technology, and cloud data warehouses have brought new options for businesses to analyze data. Organizations have typically used data warehouses to curate data for business analytics use cases. Data lakes emerged as another option that allows for more types of data to be stored and used. However, it’s important to set up your data lake the right way to avoid those lakes turning into oceans or swamps that don’t serve business needs.
The emergence of “keep everything” data lakes
Data warehouses require well-defined schemas for well-understood types of data, which is good for long-used data sources that don’t change or as a destination for refined data, but they can leave behind uningested data that doesn’t meet those schemas. As organizations move past traditional warehouses to address new or changing data formats or analytics requirements, data lakes are becoming the central repository for data before it is enriched, aggregated, filtered, etc. and loaded to data warehouses, data marts, or other destinations ultimately leveraged for analytics.
Since it can be difficult to force data into a well-defined schema for storage, let alone querying, data lakes emerged as a way to complement data warehouses and enable previously untenable amounts of data to be stored for further analysis and insight extraction. Data lakes capture every aspect of your business, application, and other software systems operations in data form, in a single repository. The premise of a data lake is that it’s a low-cost data store with access to various data types that allow businesses to unlock insights that could drive new revenue streams, or engage audiences that were previously out of reach.
Data lakes can quickly grow to petabytes, or even exabytes as companies, unbound from conforming to well-defined schemas, adopt a “keep everything” approach to data. Email, social media feeds, images, and video are examples of unstructured data that contain rich insights, but often goes unutilized. Companies store all structured and unstructured data for use someday; the majority of this data is unstructured, and independent research shows that ~1% of unstructured data is used for analytics.
Open-source software and on-prem data lakes
During the early part of the 2010s, Apache Hadoop emerged as one of the primary platforms for companies to build their data lake. While Hadoop can be a more cost-effective repository alongside a data warehouse, it’s also possible that data lakes become destinations for data with no value realization. In addition, directly integrating each data source with the Hadoop file system is a hugely time-consuming proposition, with the end result of only making data available to Hadoop for batch or micro-batch processing. This type of data capture isn’t suitable for real-time processing or syncing other real-time applications; rather than produce real-time streams of actionable insights, Hadoop data lakes can quickly become passive, costly, and less valuable.
In the last few years, a new architecture has emerged around the flow of real-time data streams. Specifically, Apache Kafka has evolved to become a popular event streaming platform that allows companies to have a central hub for streams of data across an enterprise. Most central business systems output streams of events: retail has streams of orders, sales, shipments, and price adjustments; finance has stock changing prices, orders, and purchase/sale executions; web sites have streams of clicks, impressions, and searches. Other enterprise software systems have streams of requests, security validations, machine metrics, logs, and sometimes errors.
Due to the challenges in managing on-prem Hadoop systems, many organizations are looking to modernize their data lakes in the cloud while maintaining investments made in other open source technologies such as Kafka.
Building a modern data lake
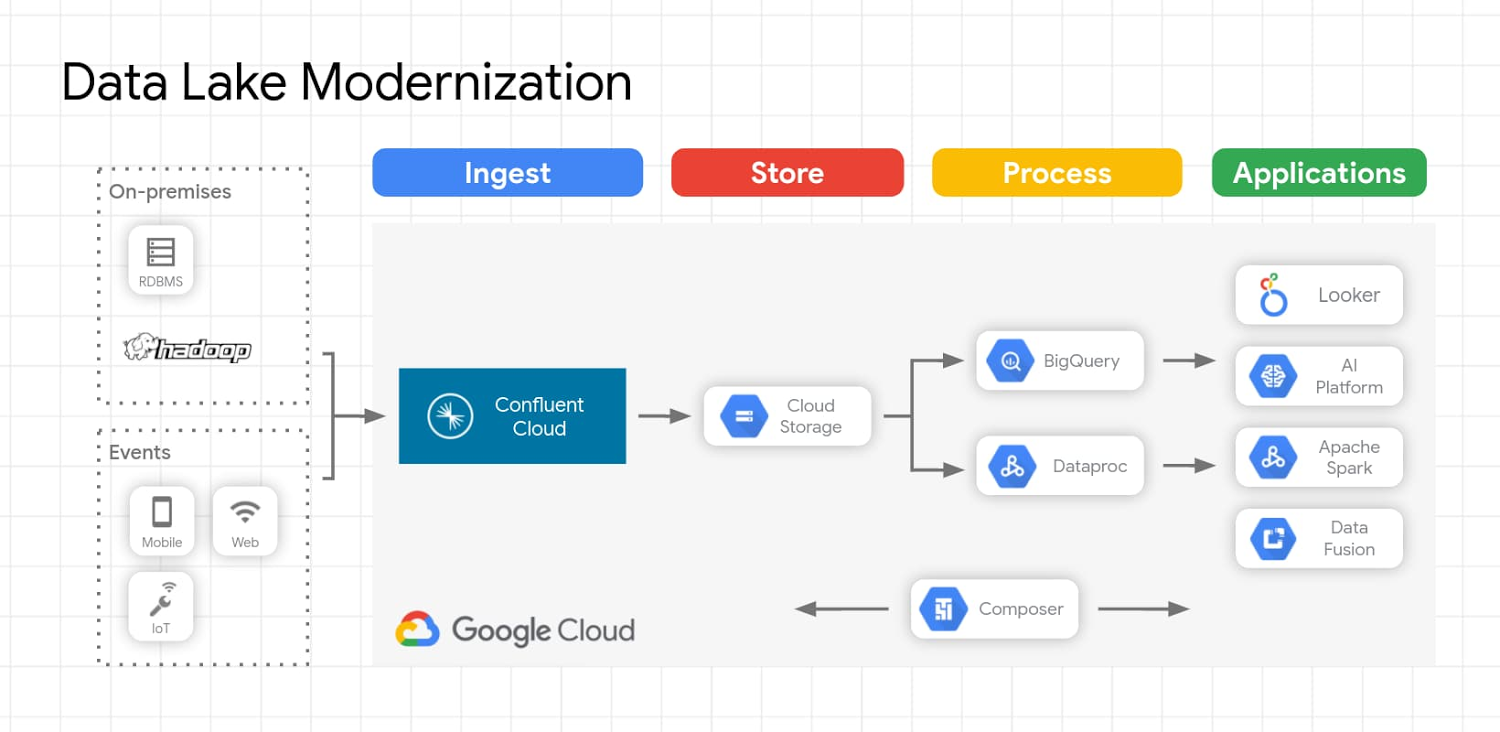
A modern data lake solution that uses Apache Kafka, or a fully managed Apache Kafka service like Confluent Cloud, allows organizations to use the wealth of existing data in their on-premises data lake while moving that data to the cloud. There are lots of reasons organizations are moving their data from on-premises to cloud storage, including performance and durability, strong consistency, cost efficiency, flexible processing, and security. In addition to these reasons cloud data lakes enable you to take advantage of other cloud services including AI Platforms that help gain further insights from both batch and streaming data. Data ingestion to the data lake can be accomplished using Apache Kafka or Confluent, and data lake migrations of Kafka workloads can be easily accomplished with Confluent Replicator. Replicator allows you to easily and reliably replicate topics from one Kafka cluster to another. It continuously copies the messages in multiple topics, and when necessary creates the topics in the destination cluster using the same topic configuration in the source cluster. This includes preserving the number of partitions, the replication factor, and any configuration overrides specified for individual topics.
Unity was able to use this technology for a high-volume data transfer between public clouds with no downtime. We’ve heard from other users that they’ve been able to use this functionality to migrate data for individual workloads, allowing organizations to selectively move the most important workloads to the cloud. Pre-built connectors let users move data from Hadoop data lakes as well as from other on-premises data stores including Teradata, Oracle, Netezza, MySQL, Postgres, and others.
Once the data lake is migrated and new data is streaming to the cloud, you can turn your attention to analyzing the data using the most appropriate processing engine for the given use case. For use cases where data needs to be queryable, data can be stored in a well-defined schema as soon as it’s ingested. As an example, data ingested in Avro format and persisted in Cloud Storage enables you to:
Reuse your on-premises Hadoop applications on Dataproc to query data
Leverage BigQuery as a query engine to query data directly from Cloud Storage
Use Dataproc, Dataflow, or other processing engines to pre-process and load the data into BigQuery
Use Looker to create rich BI dashboards
Connections to many common endpoints, including Google Cloud Storage, BigQuery, and Pub/Sub are available as fully managed connectors included with Confluent Cloud.
Here’s an example of what this architecture looks like on Google Cloud:
To learn more about data lakes on Google Cloud and Kafka workload migrations, join our upcoming webinar that will cover this topic in more depth: Modernizing Your Hadoop Data Lake with Confluent Cloud and Google Cloud Platform on July 23 at 10 am PT.

