Google Cloud での最新の分散型データメッシュの構築
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
データはイノベーションの原動力ですが、ビジネスニーズの変化はプロセス側の対応よりも急速に進行しているため、データと価値のギャップが拡大しています。お客様の組織には、意思決定に使用する多くのデータソースがあるはずです。しかし、これらの新しいデータソースに簡単にアクセスできますか?これらのデータソースから生成されたレポートを信頼していますか?これらのデータソースのオーナーやプロデューサーは誰ですか?組織内のすべてのデータソースの作成と配信に責任を持つべき一元化されたチームがありますか?それとも、データの所有権をある程度分散させ、データ制作をスピードアップする時期でしょうか?言い換えれば、データにまつわるコンテキストを最もよく知るチームに、データを所有させるべきときでしょうか?
技術的な観点から見れば、データ プラットフォームはすでにこうした要望に応えるものになっています。以前は、新しいデータソースを分析スタックに組み込むために、十分な容量やエンジニアリング時間があるかどうかを懸念していました。今では、データ処理、ネットワーク、ストレージの障壁が低くなり、さまざまなソースシステムに存在する多くのデータを取り込み、保存し、処理し、アクセスすることが、費用をかけずにできるようになっています。
しかし、物事はそう簡単ではありません。データ プラットフォームが進化しても、分析データを生成する組織モデルや、ユーザーがデータにアクセスし利用するためのプロセスは進化していないからです。多くの組織では、組織内のすべてのデータアセットのリポジトリを作成し、そのデータをユーザーにとって有用かつアクセスできるものにするための作業を、中央チームに依存しています。そのため、企業がデータから求める価値を得るのが遅くなってしまいます。お客様とお話をしていると、2 つの問題のいずれかが見えてきます。
第一の問題はデータのボトルネックです。データにアクセスできるのは 1 つのチーム、時には 1 人の人間やシステムだけなので、データのリクエストはすべてそこを通さなければならないという問題があります。また、中央チームは、要求されたデータに関するドメイン知識があまりないままユースケースを解釈し、必要なデータアセットを判断することが求められます。このような状況は、データ アナリストやデータ サイエンティスト、ひいては意思決定のためにデータを必要とするすべてのビジネスユーザーにとって、大きなフラストレーションとなります。やがて彼らは待つことをあきらめ、データなしに意思決定をしてしまいます。
もう一つの問題は、データのカオスで、ボトルネックに辟易する人が出てくることです。自分にとって最良の選択肢であるかどうかわからないまま、見つかったデータの中から最も関連性の高いものをコピーしてしまうのです。このようなデータの重複(および、その後の利用)が何度も起こると、ユーザーはデータの信頼できる情報源や鮮度、データの意味するところを見失うことになります。これは、データ ガバナンスにおける悪夢であることはもちろんですが、不必要な作業やシステム リソースの浪費を生み、複雑さと費用の増加にもつながります。この問題は、すべての人の仕事を遅らせ、データに対する信頼を損ないます。
上述の課題を解決するために、正当なユースケースを持つデータ プロダクトであれば、データの生成、分析、データ プロダクトとしての公開において、ビジネス ドメインに自律性を持たせることが組織の要望として浮上します。同じビジネス ドメインが、データ プロダクトをそのライフサイクル全体を通して所有することになります。
このモデルにおいて、中央のデータチームはデータそのものの所有権を持たないものの、その必要性は残ります。中央チームの目標は、ユーザーが自律的にデータ プロダクトを構築、共有、利用できるようにすることで、データから価値を生み出すことをサポートすることです。中央チームは、ドメインが安全で相互運用可能なデータ プロダクトを構築、デプロイ、維持するための一連の標準とベスト プラクティス、これらのプロダクトに対する信頼を築くためのガバナンス ポリシー(およびドメインがガバナンス ポリシーを遵守するための支援ツール)、ドメインがデータ プロダクトの検出、利用をセルフサービスで行うことを可能にする共通プラットフォームを通じて、この目標を実現します。すでにセルフサービスとサーバーレスのデータ プラットフォームによって、中央チームの仕事はより簡単になりました。
2019 年、Zhamak Dehghani 氏は、インフラストラクチャのモダナイゼーションで培った DevOps の考え方をデータに適用し、データメッシュという概念を世に送り出しました。偶然にも、この 10 年間、Google の社内では同様の運用がなされてきました。舞台裏で BigQuery を利用することで、分散型のデータ プラットフォームを実現します。その結果、ドメインから中央のデータレイクやプラットフォームにデータを移動する代わりに、ドメインはドメインのデータセットを簡単に消費できる方法でホストし、提供できるようになります。データを生成するビジネスエリアは、そのデータをビジネス上必要とするチームがアクセスできるように、データセットを所有し提供する責任を負うことになります。この 2 年間、データメッシュをぜひ試してみたいというお客様を数多くサポートしてきました。
Google Cloud 上でデータメッシュを構築する方法について詳しくはホワイトペーパーの全文をこちらでご覧ください。実装のためのフォローアップ ガイドは、こちらでご覧ください。データメッシュは、データの所有権を、そのデータに関するビジネス上の文脈を最も把握しているチームに分散させるアーキテクチャ パラダイムであると言えます。これらのチームは、データを最新状態に保ち、信頼性を高め、社内の他のデータ利用者が検出できるようにする責任を担っています。その結果、データは効果的にプロダクトとなり、それを最もよく知るチームによってドメイン内で所有し、管理されるようになります。このアプローチを成功させるためには、ガバナンスをドメイン間で連携させ、データとアクセスの管理をデータオーナーも含めて境界内でカスタマイズできるようにする必要があります。
データメッシュのアイデアは魅力的です。ビジネスニーズとテクノロジーを、通常では見られない方法で結びつけてくれるからです。また、データメッシュは、データから価値を抽出する際の組織の壁を取り払うためのソリューションを約束します。そのためには、「検出可能性」「ユーザー補助」「所有権」「(連携された)ガバナンス」の 4 つの原則を採用し、技術部門とビジネス部門のリーダーの間で協調して取り組む必要があります。実際には、分散した組織全体でデータドメインを所有する各グループは、その領域のデータ プロダクトを所有し維持するために必要なデータ キュレーション、データ管理、データ エンジニアリング、データ ガバナンスのタスク増加に対応するために、データワーカーのハイブリッド グループを採用する必要があるかもしれません。チームの日常業務から従業員の管理、業績評価まで、組織に大きな影響が及ぶため、小さな変更ではなく、会社全体の部門横断的な関係者とリーダーシップからの賛同が必要です。
ビジネス ユニットが通常業務に加えてデータ プロダクトを管理できるようにするためには、CISO(最高情報セキュリティ責任者)、CDO(最高データ責任者)、CIO(最高情報責任者)の各者ができるだけ早い段階で主要ステークホルダーとして関与することが不可欠です。また、この新しい責任を自分のチームに担わせることをいとわないビジネス ユニットのリーダーも必要です。主要なステークホルダーの組織計画への関与が少ない場合、不適切なリソースが割り当てられ、プロジェクト全体が失敗に終わる可能性があります。データメッシュは、単なる技術的なアーキテクチャではなく、ビジネス ユニットがローカルに最適化することでアジリティを確保できるようにするための、データの分散所有とテクノロジーの自律的な利用へ運用モデルの転換です。Thinh Ha 氏によるデータメッシュが適さない組織の特徴についての記事は、自社でこのアプローチを検討されている方には必読の内容です。
Google Cloud は、Delivery Hero のような企業が分析スタックをモダナイズし、データメッシュを実践できるようなマネージド サービスを構築しています。
データメッシュは、データ所有権のドメイン指向な分散化と、各ドメインがデータの作成と消費に責任を持つアーキテクチャを約束します。これにより、データソースやユースケースの数をより速く拡大できます。このことは、データを BigQuery と BigLake に置いたまま、演算とアクセスのレイヤを連携させることで実現できます。そして、異なるドメインのデータ、必要であれば未処理データでも、重複やデータの移動なしに結合することが可能です。そして、Analytics Hub は Dataplex とともににデータ検出に使用されます。さらに、Dataplex は、一元的管理およびガバナンスに対応する機能を提供します。さらに、科学者、アナリスト、ビジネス ユーザーまでもが単一のセマンティック モデルでデータにアクセスできる Looker を利用することで全体の機能が補完されます。このユニバーサル セマンティック レイヤは、ビジネス ユーザーのデータ消費を抽象化し、データアクセスの許可を調和させます。
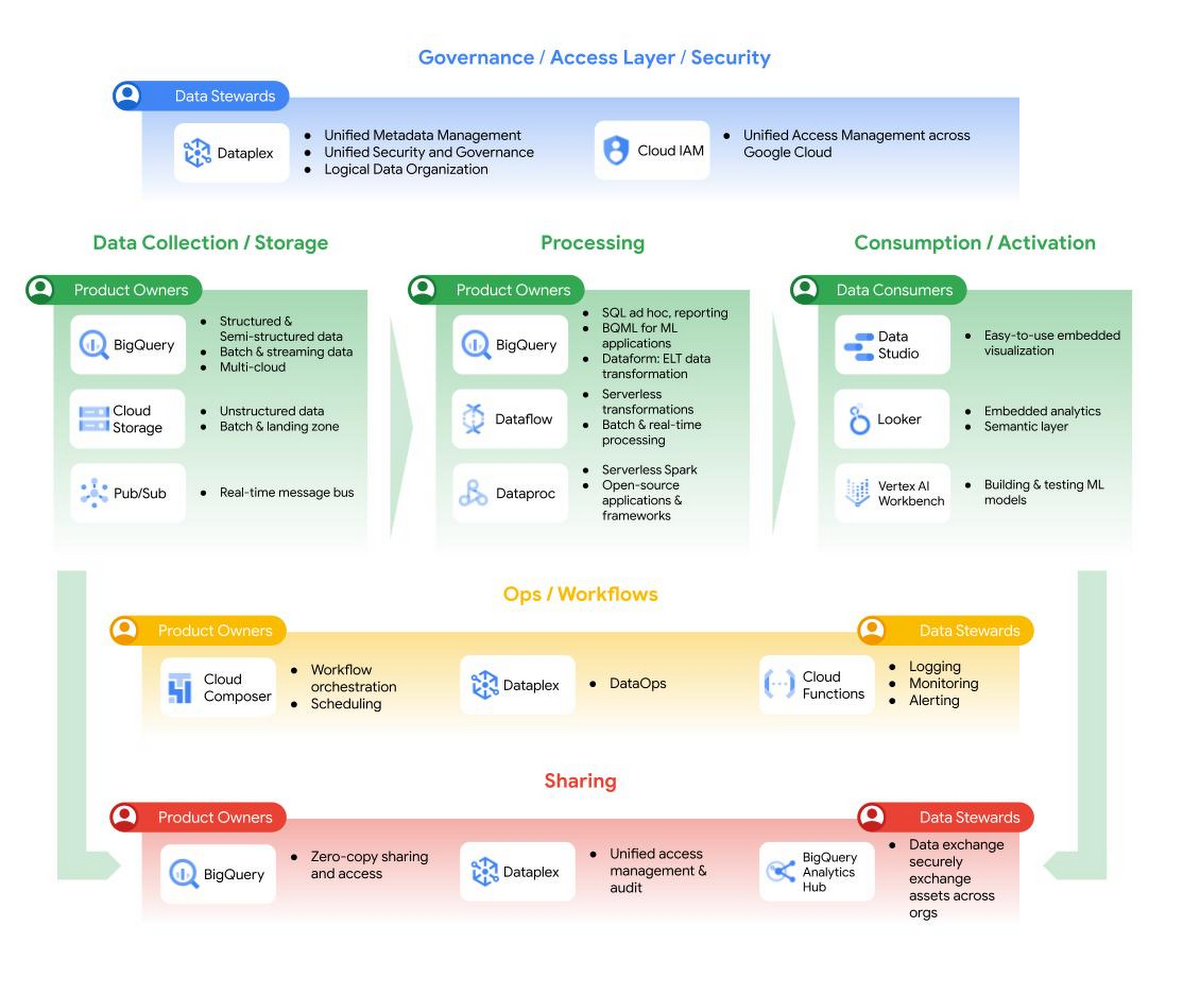
図 1: Google の Data Cloud におけるデータメッシュ
また、BigQuery StorageApi は、ストレージと演算の真の分離により、20 以上の API から他のワークロードに影響を与えることなく高いパフォーマンスでデータにアクセスすることが可能です。このように、BigQuery はデータ ウェアハウスとデータレイクの機能を統合したレイクハウスとして機能し、多種かつ大量のデータを扱うことができます。レイクハウスについては、先日のオープンデータのレイクハウスの記事で詳しく紹介しています。強力な連携クエリを使用すれば、BigQuery はオブジェクト ストレージ(Cloud Storage)上の Parquet や ORC のオープンソース形式ファイル、トランザクション データベース(Bigtable、Cloud SQL)、ドライブのスプレッドシートといった外部データソースを、データを移動せずに処理できます。これらのコンポーネントを組み合わせたアーキテクチャの例を図 2 に示します。
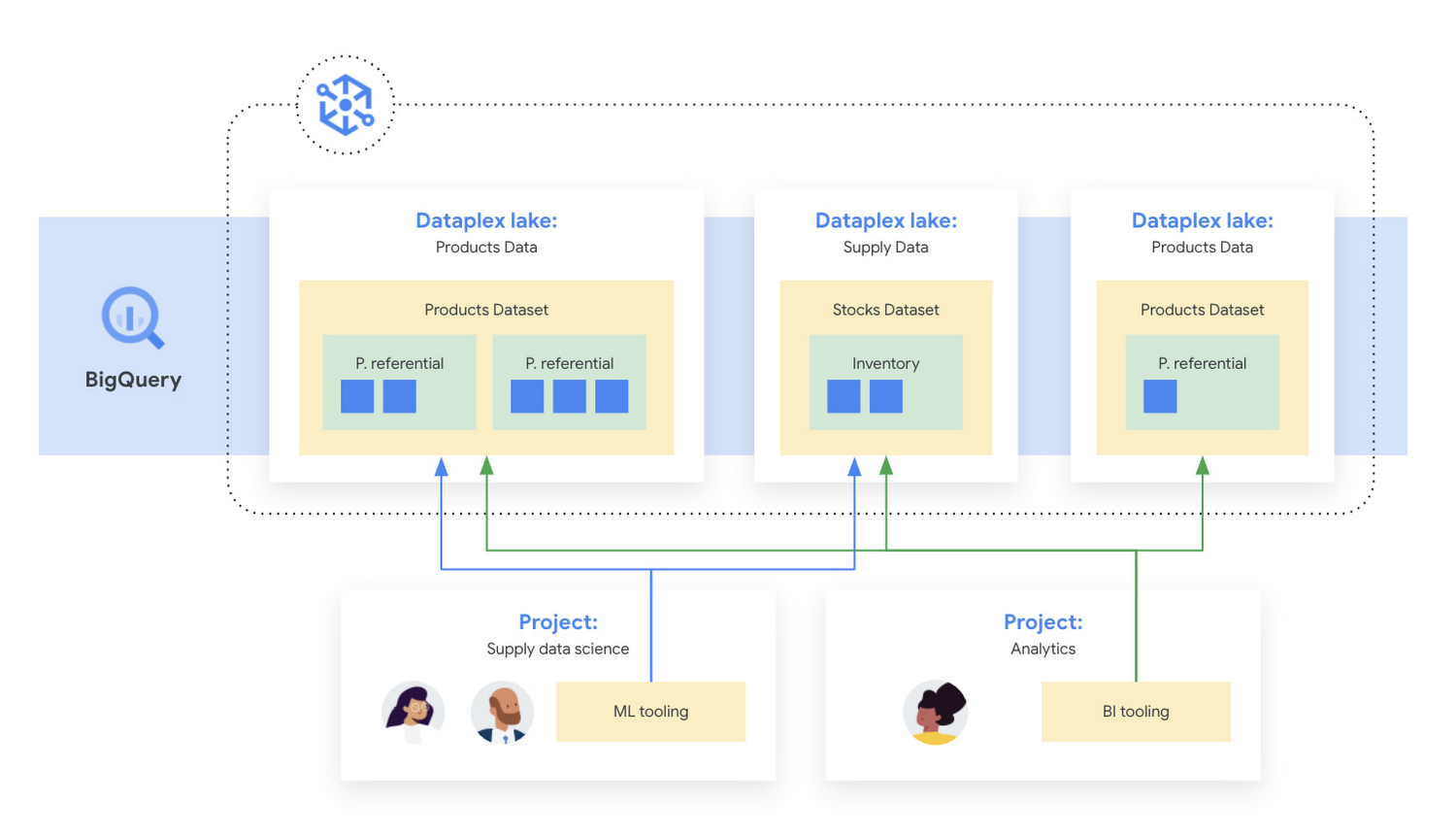
データメッシュがお客様のビジネスに適していると思われる場合は、Google Cloud 上でデータメッシュを構築する方法についてのホワイトペーパーをお読みください。しかし、データメッシュの構築を検討する前に、自社のデータに対する考え方や、組織的にそのような変化を受け入れる準備ができているかどうかをよく考えてみましょう。このジャーニーを始めるにあたり、「データ処理に関する組織の分類における自組織の位置づけを確認する」をお読みになることをおすすめします。この質問に対する答えは非常に重要で、すぐに連携できない既存のプロセスがある場合、データメッシュが組織全体に適しているとは限りません。分析スタック全体のモダナイゼーションをお考えの場合は、統合分析プラットフォームの構築に関する Google のホワイトペーパーをご覧ください。データメッシュに関する興味深いインサイトについては、こちらからホワイトペーパー全文をお読みください。Google Cloud 上でのデータメッシュの実装に関するガイドは、こちらで紹介しています。このガイドでは、Google Cloud 上で実装可能なアーキテクチャ、そのアーキテクチャを実現するために必要な主要職務と役割、データメッシュの各主要タスクで考慮すべき事項の詳細を説明しています。
謝辞
Diptiman Raichaudhuri、Sergei Lilichenko、Shirley Cohen、Thinh Ha、Yu-lm Loh、Johan Pcikard、Yu-lm Loh および Maxime Lanciaux のサポート、作業、議論によって、この課題に取り組むことができたのは光栄であり、特権でした。
- シニア プロダクト マネージャー Firat Tekiner
- シニア プロダクト マネージャー Susan Pierce