検索インデックスで既存のクエリを最適化する方法
Google Cloud Japan Team
※この投稿は米国時間 2023 年 9 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
2022 年 10 月、BigQuery は検索インデックスとSEARCH 関数をリリースしました。これにより、Google 標準 SQL を使用して非構造化テキストや半構造化データで特定のデータ要素をピンポイントで見つけ出せるようになりました。前回のブログ投稿では、SEARCH 関数で検索インデックスを利用することで、パフォーマンスがどの程度向上するかを説明しました。
本日、BigQuery はこの最適化機能を新しいセットの SQL の演算子と関数に拡張します。セットには、文字列リテラルをインデックス登録されたデータと比較するときに使用される equal 演算子(=)、IN 演算子、LIKE 演算子、STARTS_WITH 関数が含まれます。つまり、テーブル上に検索インデックスがあり、文字列リテラルをテーブルの値と比較するクエリがある場合、BigQuery はインデックスを使用して、クエリに一致する行をより迅速かつ効率的に検索できるようになりました。
どの既存の関数や演算子が検索インデックス最適化の対象になるのかについて詳しくは、検索インデックス データのドキュメントをご覧ください。
このブログ投稿では、インデックスの作成から情報を効率的に取得するまでのプロセスをいくつかの具体例とともに説明し、パフォーマンスを向上させる測定済みの数値をいくつかご紹介します。
既存の SQL で検索インデックス最適化を活用する
今回のリリースの前、BigQuery 検索インデックスを活用する唯一の方法は SEARCH 関数を使用することでした。SEARCH 関数は優秀です。列固有の検索に加えて、クロスカラム検索もサポートしています。これはネストされた列を含む何百もの列を使用した複雑なスキーマで特に有用です。また、大文字と小文字を区別する優れた機能や、大文字と小文字を区別しないトークン化された検索セマンティクスも提供しています。
SEARCH 関数は汎用性が非常に高く、優れていますが、必ずしも求めているセマンティックな結果が得られるとは限りません。たとえば、下のファイル共有システムの簡略化されたアクセスログのテーブルを見てみましょう。
テーブル: イベント
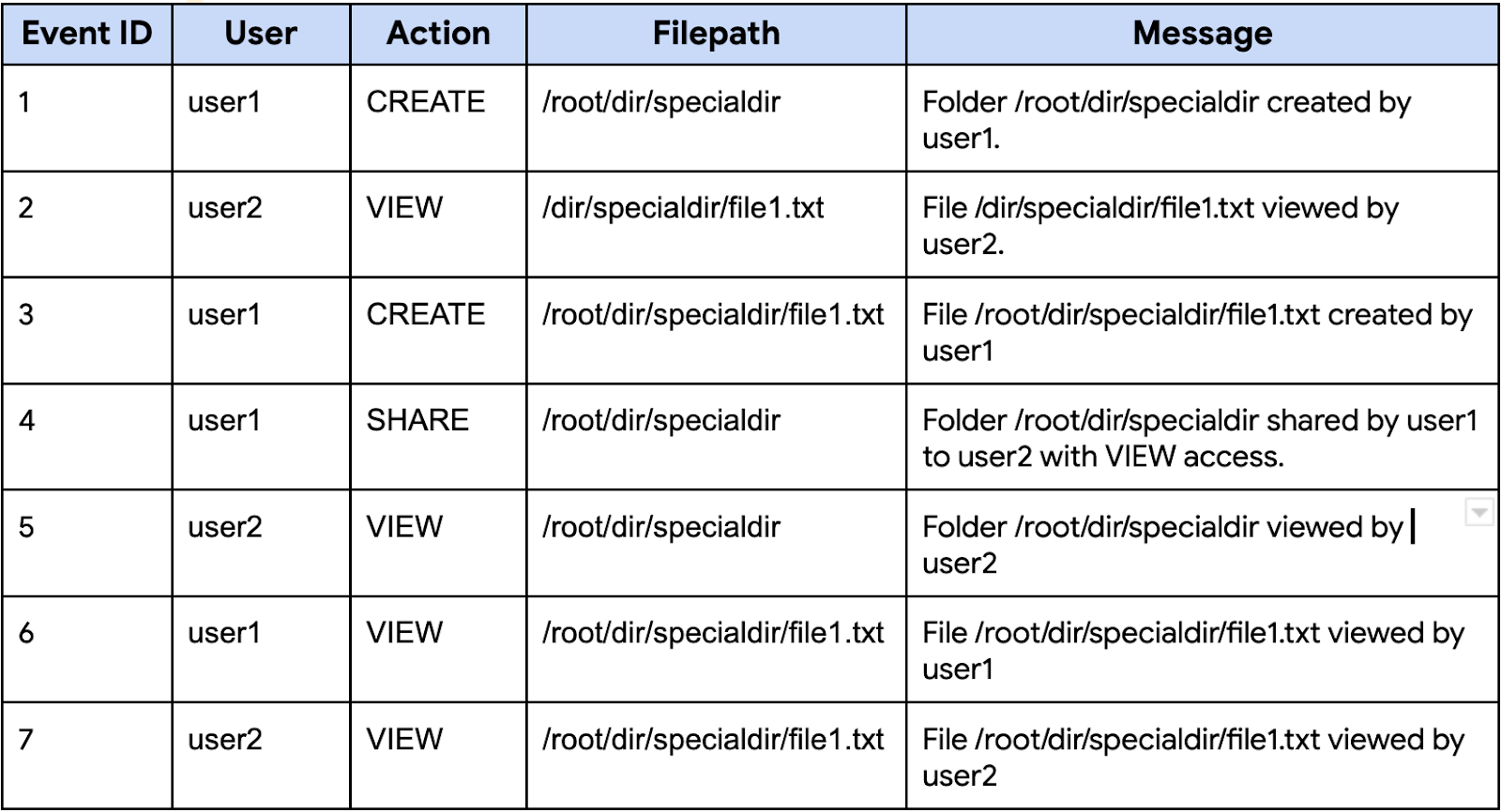
SEARCH 関数は、テーブルのあらゆる場所に出現するトークンを検索できます。たとえば、"specialdir" を含むイベントを、次のクエリを使用して検索できます。
上のクエリは上のテーブルからすべての行を返します。
しかし、より具体的に "/root/dir/specialdir" のフォルダに関連するイベントの結果のみが必要な場合を考えてみましょう。次のクエリで SEARCH 関数を使用すると、必要以上の行が返されます。
上のクエリもイベント ID 2 の行以外のすべての行を返します。なぜなら、SEARCH はトークン検索の関数であり、検索データにすべての検索トークンが含まれている限り、true を返すからです。つまり、SEARCH("/root/dir/specialdir/file1.txt", "/root/dir/specialdir") は true を返します。たとえバッククォートを使用して大文字と小文字の区別を適用し、トークンの正確な順序を指定しても、SEARCH("/root/dir/specialdir/file1.txt", "`/root/dir/specialdir`") も true を返します。
代わりに EQUAL 演算子を使用して、フォルダ内のファイルではなく、フォルダに関連するイベントのみが結果に含まれるようにします。
クエリ 3 の結果
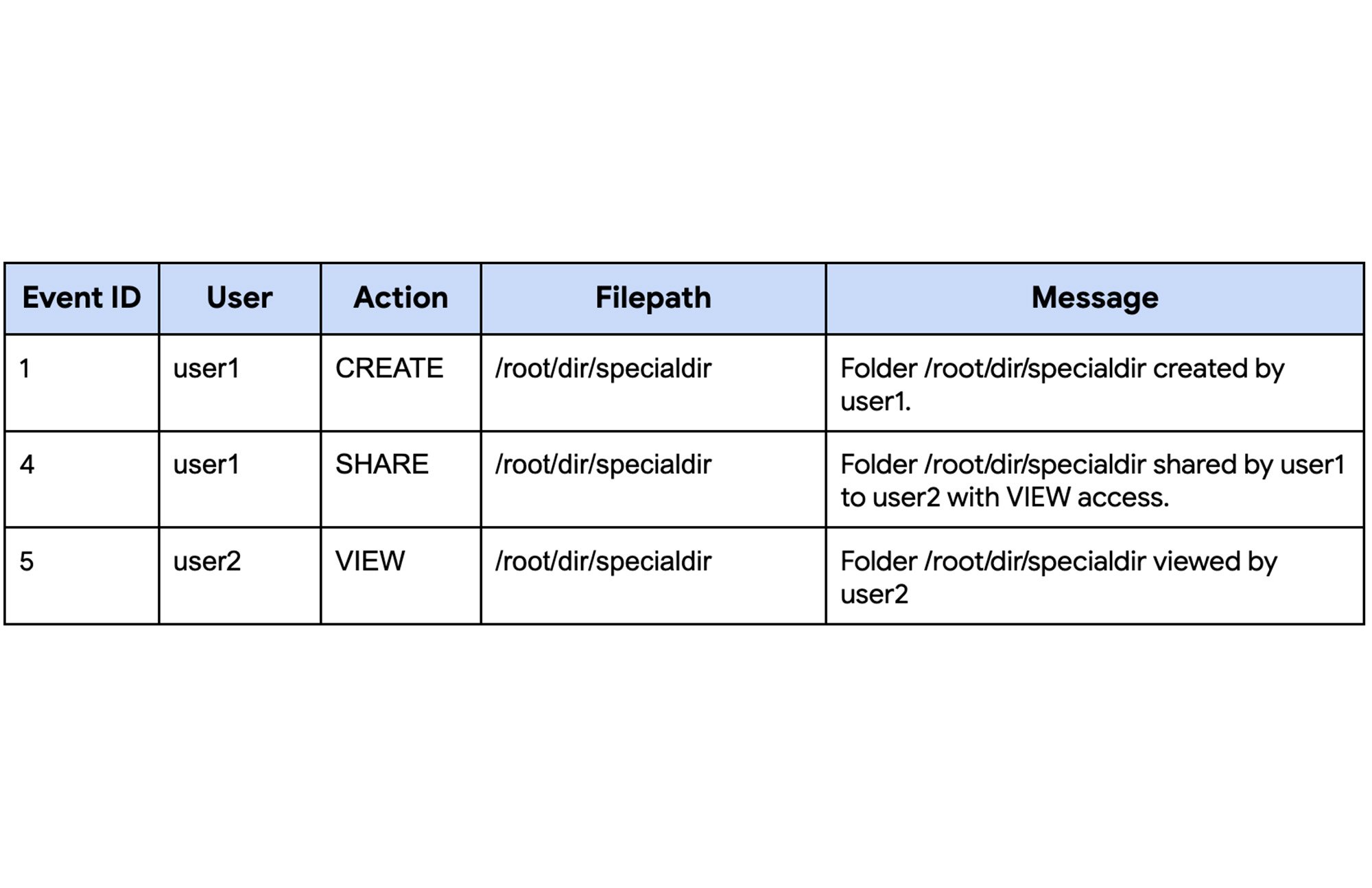
今回のリリースにより、クエリ 3 は検索インデックスを利用して、レイテンシ、スキャンされるバイト、スロットの使用量を削減できるようになりました。
接頭辞検索
現在、SEARCH 関数は接頭辞検索をサポートしていません。新しく追加された STARTS_WITH や(限定された形式の)LIKE でのインデックス使用のサポートでは、インデックス最適化を使用して次のクエリを実行できます。
クエリ 4 もクエリ 5 も、イベント ID 2 の 1 行を返します。SEARCH 関数は、このケースでは理想のオプションではありませんでした。なぜなら、各行には "dir" と "specialdir" の両方のトークンが含まれていたため、テーブルのすべての行を返してしまうからです。
ゲノムデータのクエリを実行する
このセクションでは、一般公開データセットから情報を取得する例を示します。BigQuery は、bigquery-public-data.human_genome_variants(世界各地の 25 の母集団から集められた約 2,500 人のゲノムで構成されている 1,000 人ゲノム データセット)を含む多数の一般公開データセットをホストしています。具体的には、データセットのテーブル 1000_genomes_phase_3_optimized_schema_variants_20150220 には第 3 刊行物で発表されたヒトゲノムの変異体の情報が含まれています(https://cloud.google.com/life-sciences/docs/resources/public-datasets/1000-genomes)。テーブルは 84,801,880 行あり、論理サイズは 1.94 TB あります。
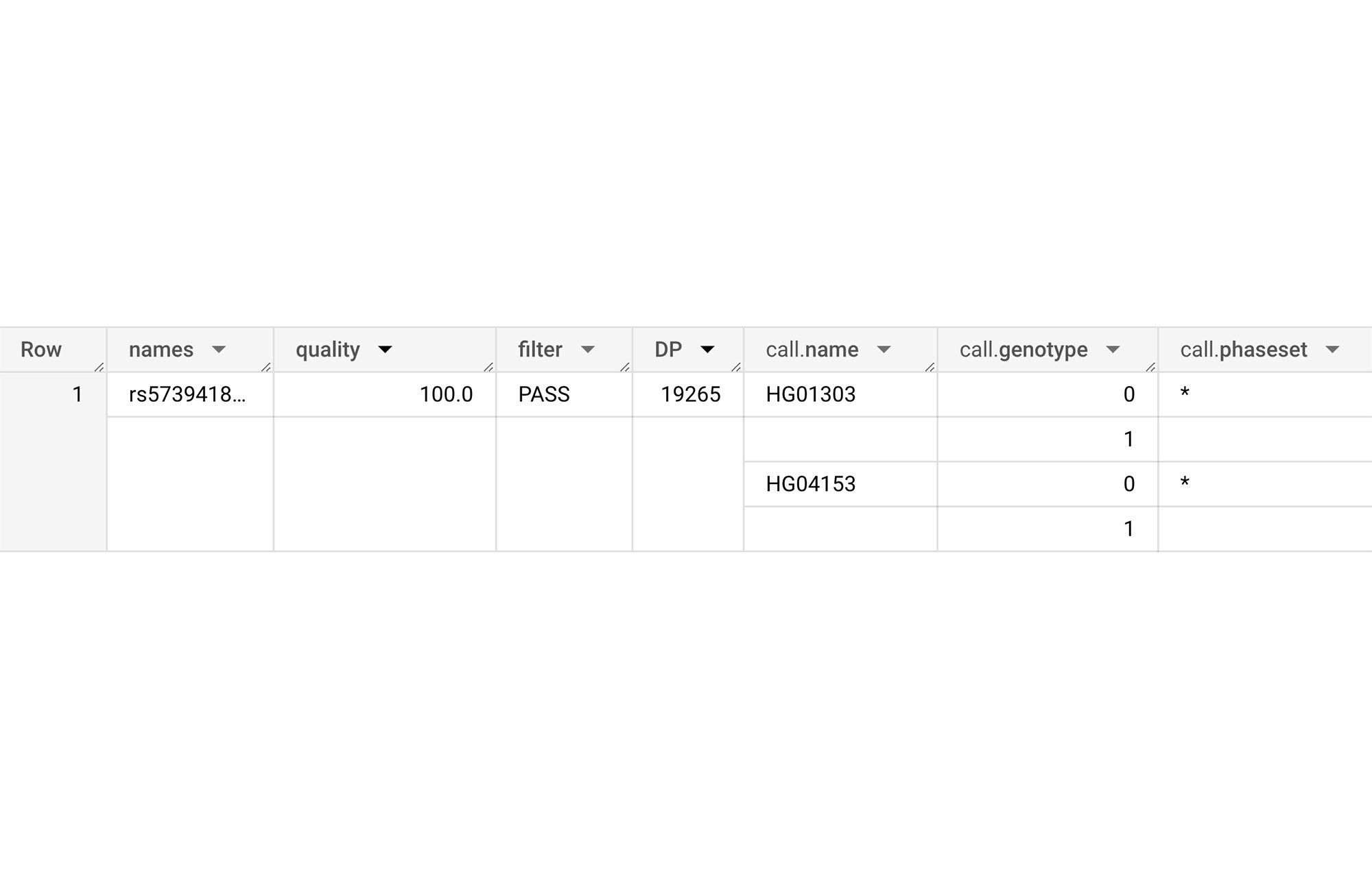
ある科学者が、このコホートの特定のゲノム変異に関する情報(たとえば rs573941896)を見つけようとしているとします。この情報には、品質、フィルタ(合格 / 不合格)、DP(シーケンス深度)、コール統計の詳細(サンプル内のどの個体がこのバリアントを持つか)が含まれます。この場合、次のようにクエリを発行できます。
クエリは 1 行を返します。
テーブルに検索インデックスがない場合、上のクエリは 5 秒かかり、294.7 GB をスキャンし、1 時間 1 分のスロット時間を消費します。
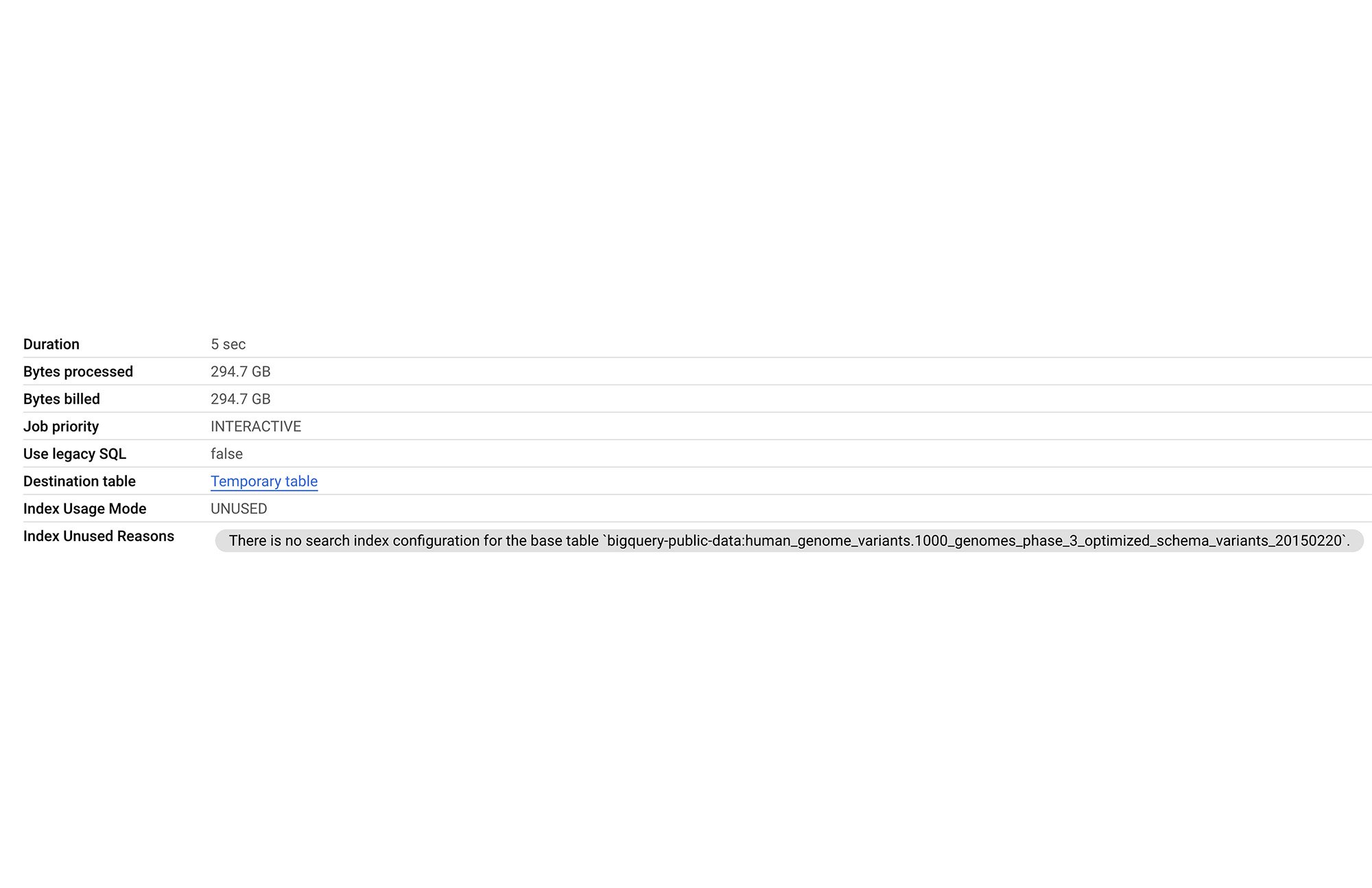
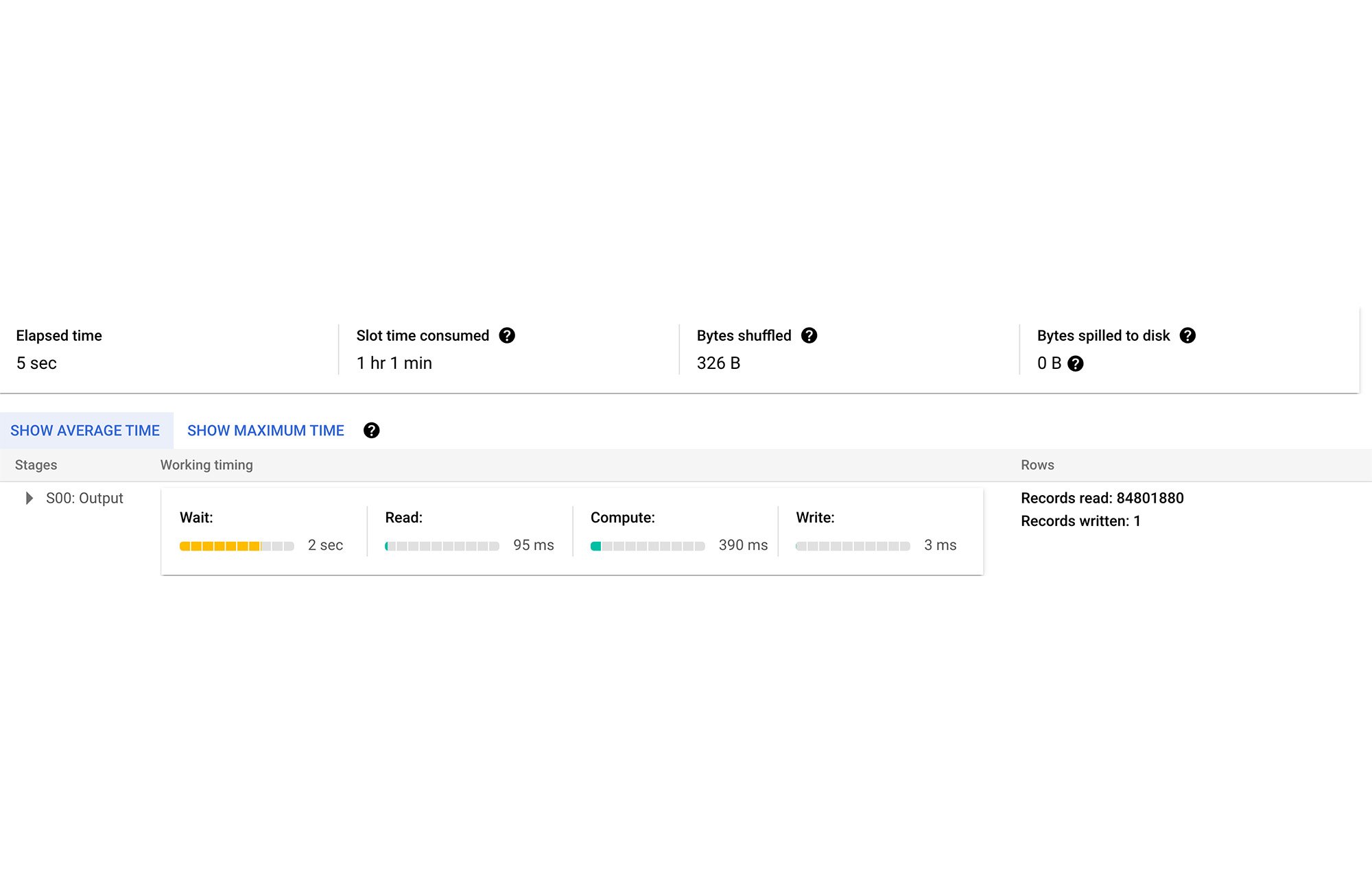
次のセクションでは、このユースケースの検索インデックスでメリットを得るまでのプロセスをご紹介します。
文字列データ検索を高速化する検索インデックスの作成
BigQuery の検索インデックスは、このケースの目的の検索を加速できます。インデックスを作成する前に、一般公開テーブルのコピーをデータセットの一つに作成しました。コピーされたテーブルは my_project.my_dataset.genome_variants です。
次の DDL を使用して、テーブルの名前列で検索インデックスを作成します。
CREATE SEARCH INDEX my_index ON genome_variants(names);
CREATE SEARCH INDEX コマンドが直ちに返され、インデックスがバックグラウンドで非同期で作成されます。インデックス作成の進行状況は、INFORMATION_SCHEMA.SEARCH_INDEXES ビューのクエリを実行して追跡できます。
CREATE SEARCH INDEX コマンドが直ちに返され、インデックスがバックグラウンドで非同期で作成されます。インデックス作成の進行状況は、INFORMATION_SCHEMA.SEARCH_INDEXES ビューのクエリを実行して追跡できます。
INFORMATION_SCHEMA.SEARCH_INDEXES ビューには、検索インデックスの最終更新時間やカバレッジの割合など、検索インデックスに関するさまざまなメタデータが表示されます。SEARCH 関数は、データの一部がまだインデックス登録されていなくても、取り込まれたすべてのデータから常に正しい結果を返します。
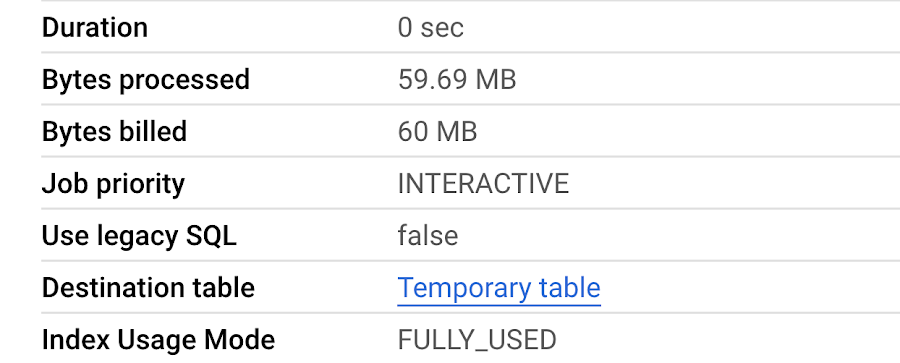
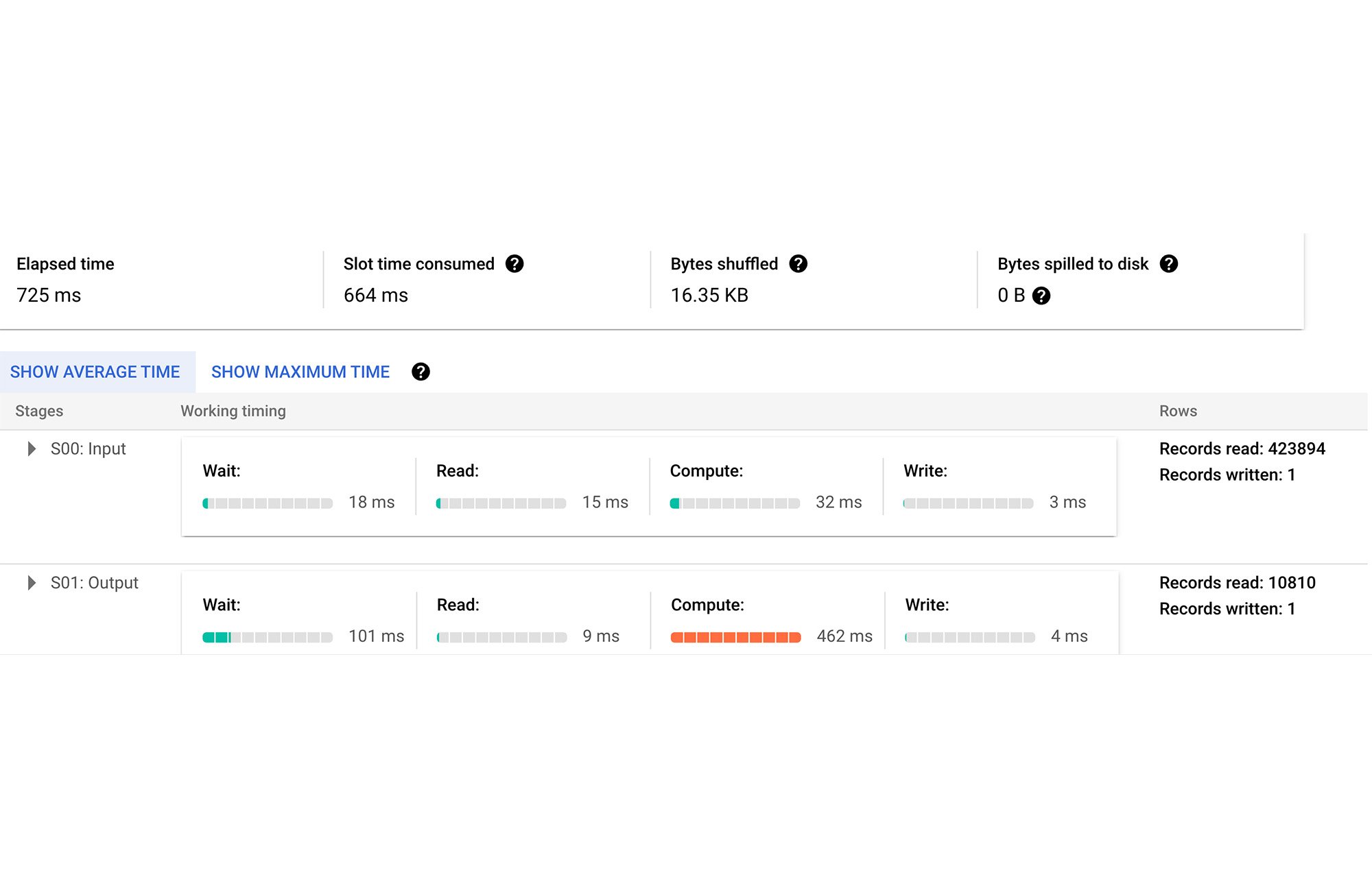
インデックス登録が完了したら、上と同じクエリを実行します。
次の 3 つの面で大幅な向上が見られます。
- クエリのレイテンシ: 725 ミリ秒(検索インデックスなしの場合は 5 秒)
- 処理されるバイト: 60 MB(検索インデックスなしの場合は 294.7 GB)
スロット時間: 664 ミリ秒(検索インデックスなしの場合は 1 時間 1 分)
文字列 EQUAL を含むクエリで検索インデックスを使用した場合のパフォーマンス向上
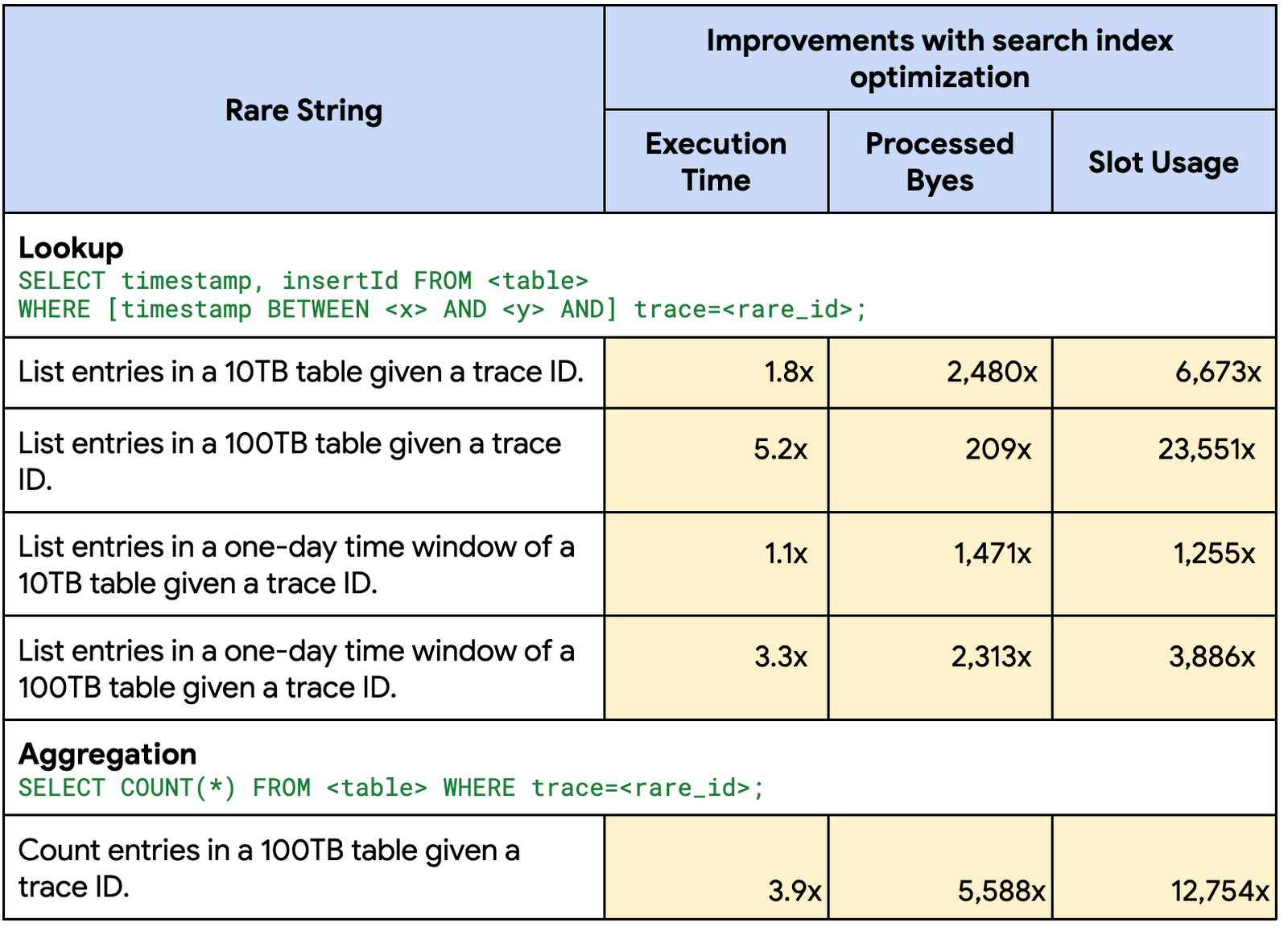
より大規模で現実的なデータの向上をベンチマークするために、Google 社内のテスト プロジェクトの Google Cloud Logging データ(10TB、100TB スケール)で数多くのクエリを実行しました。インデックス最適化の有無でパフォーマンスを比較します。
まれな文字列検索
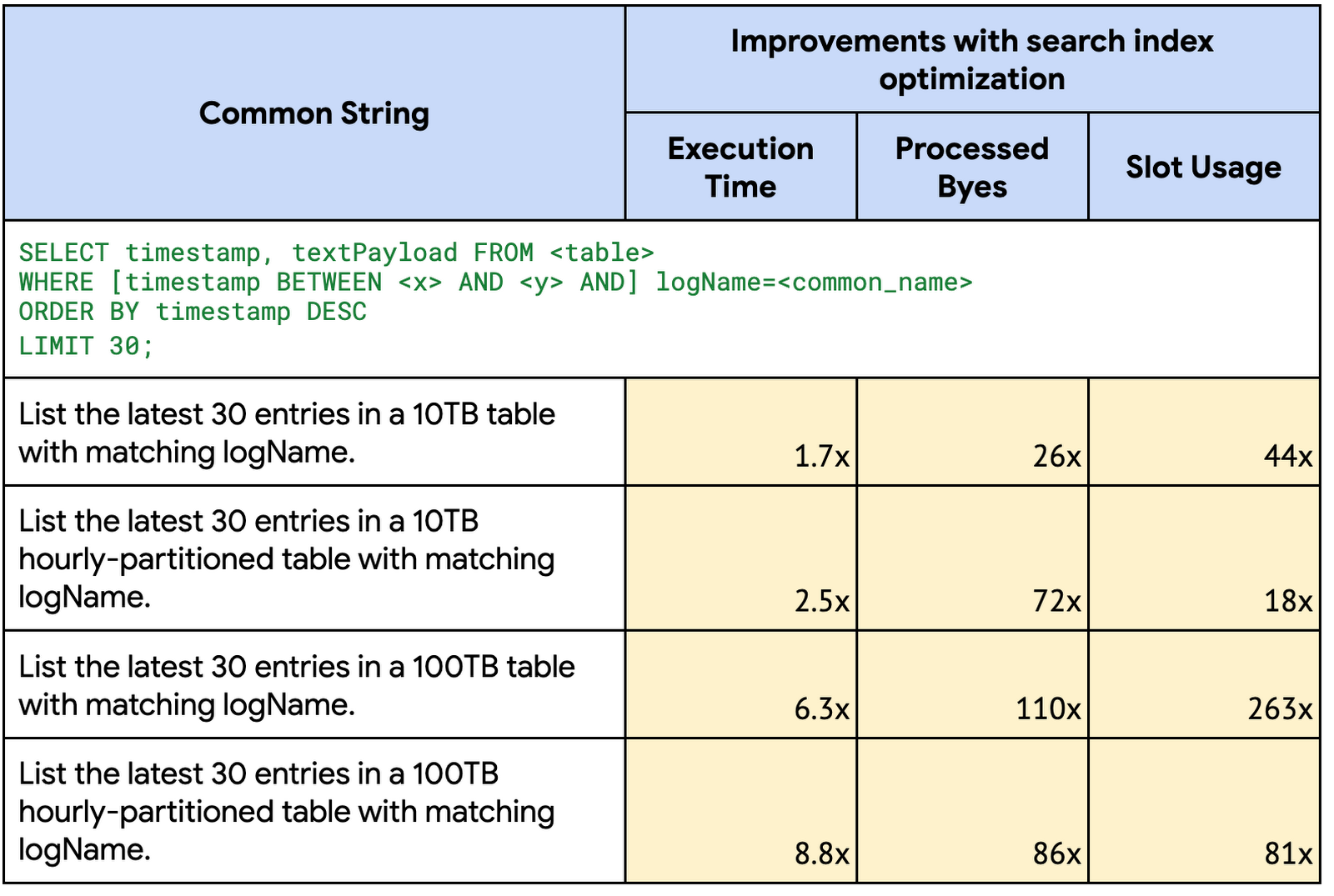
IP アドレス検索

JSON フィールド検索
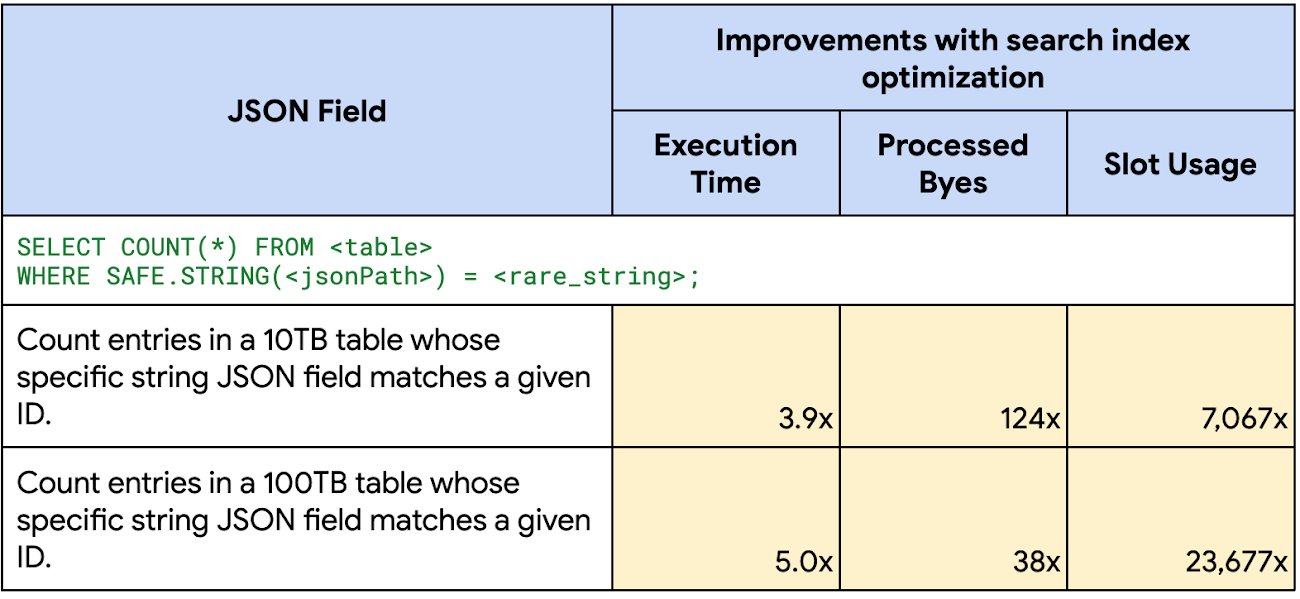
equal(=)、IN、LIKE、STARTS_WITH による検索インデックス最適化の使用は現在プレビュー版です。プロジェクトで検索インデックス最適化を実現または使用するには、この許可リストフォームを提出してください。他にも多くの最適化が進行中です。今後の情報にご注目ください。
-ソフトウェア エンジニア、Huong Phan
-シニア エンジニアリング マネージャー、Omid Fatemieh



