マルチモーダル データ サイエンス時代に対応した BigQuery DataFrames 2.0 のご紹介
Sandeep Karmarkar
BigQuery Product Manager, Google
Jiaxun Wu
Tech lead
※この投稿は米国時間 2025 年 4 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
データ サイエンティストや ML エンジニアにとって、Python での分析とモデルの構築は第二の天性のようなもので、データ サイエンス コミュニティにおける Python の人気は、最近の生成 AI ブームに乗って急上昇しています。データ サイエンスの未来は、もはや整然と並んだ行と列だけで構成されるものではありません。何十年もの間、多くの貴重な分析情報が、画像、音声、テキストなどの非構造化形式に閉じ込められてきました。そして今、生成 AI の進化に伴い、データ サイエンス ワークロードは、マルチモダリティを処理し、新しい生成 AI とエージェント手法を利用できるように進化する必要があります。
先週の Google Cloud Next 25 では、未来のデータ サイエンスに備えるためのソリューション、BigQuery DataFrames 2.0 を発表しました。これにより、マルチモーダルのデータ処理と AI が BigQuery Python ワークフローに直接組み込まれます。

Pandas DataFrame を拡張して BigQuery マルチモーダル データに対応
BigQuery では、データ サイエンティストが Python を使用して分析や ML 向けの大規模なデータセットを処理することがよくあります。しかし、ほとんどの場合には、別の Python フレームワークについて学習し、小規模なデータセットでは機能していたコードを書き直す必要があります。10 GB のデータで動作していた Pandas コードを、多大な時間と労力を費やさずに、1 テラバイトのデータで動作させることはまず不可能です。
バージョン 2.0 では、大規模な Python データ サイエンスのための中核的な基盤も強化されています。そして、この基盤の上に、構造化データと非構造化データ両方の可能性を最大限に引き出す画期的な新機能を追加しました。
BigQuery DataFrames の導入
Google は昨年、新しいインフラストラクチャや API を追加することなく Python データ処理をスケーリングできるオープンソースの Python ライブラリとして、BigQuery DataFrames をリリースしました。これは、Pandas や scikit-learn の一般的な Python データ サイエンス API を、さまざまな BigQuery SQL 演算子にトランスパイルするものです。リリース以来、データ処理量は 30 倍以上に増加し、現在では数千のお客様がこのソリューションを使用して毎月 100 PB を超えるデータを処理しています。
昨年は、50 回以上のリリースを通じてライブラリを大幅に進化させ、数千人ものユーザーとの緊密な連携を実現しました。ここで、BigQuery DataFrames を早期に導入したお客様による、本番環境でのこのライブラリの使用事例を 2 件ご紹介します。
Deutsche Telekom は、BigQuery DataFrames を ML の標準プラットフォームとして採用しました。
「BigQuery DataFrames により、スケーラブルなマネージド ML プラットフォームを当社のデータ サイエンティストに提供できます。データ サイエンティストのスキルアップは最小限で済みます。」 - Deutsche Telekom、データ アーキテクチャおよびガバナンス担当バイス プレジデント、Ashutosh Mishra 氏
また、Trivago は PySpark 変換を BigQuery DataFrames に移行しました。
「BigQuery DataFrames のおかげで、データ サイエンス チームは、インフラストラクチャの調整ではなくビジネス ロジックに集中できます。」 - Trivago、データ インフラストラクチャ責任者、Andrés Sopeña Pérez 氏
BigQuery DataFrames 2.0 の新機能
このリリースには、AI と ML のパイプラインを効率化するための機能が豊富に用意されています。
マルチモーダル データと生成 AI 技術の活用
- Multimodal DataFrames(プレビュー): BigQuery Dataframes 2.0 では、従来の構造化データに加えて、テキスト、画像、音声などを処理できる統合データフレームが導入され、構造化データと非構造化データの間の障壁が取り除かれました。その基盤となっているのが ObjectRef による BigQuery のマルチモーダル機能で、これにより大規模なデータセットでもスケーラビリティとガバナンスを確保できます。BigQuery DataFrames は、マルチモーダル データを処理する際に、エンベディング生成、ベクトル検索、Python UDF などの BigQuery の機能をバックグラウンドで活用し、マルチモーダル テーブルの操作とマルチモーダル データの処理のために多くの詳細の抽象化も行います。
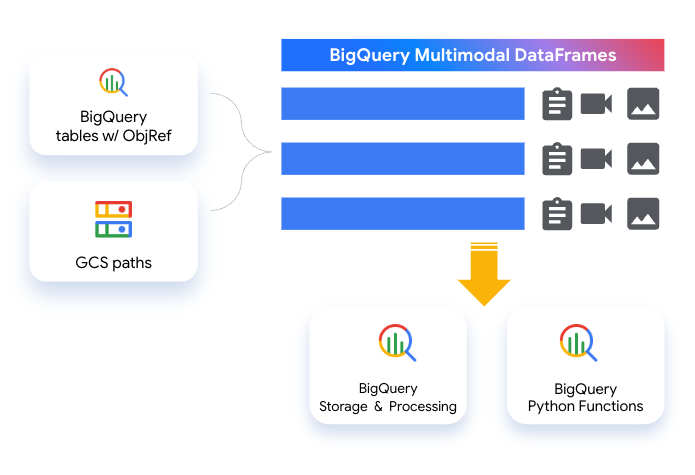
- BigQuery AI クエリエンジンの Python スタイルの演算子(試験運用版): BigQuery AI クエリエンジンでは、マルチモーダル データから簡単に分析情報を生成できます。SQL クエリに自然言語の指示を含めるだけで、非構造化データを分析できるようになりました。テーブルで通話の文字起こしを「サポートの質」を基準にランク付けしたり、列内のレビューに基づいて「満足度が高い」商品のリストを生成したりする SQL クエリを記述するとしましょう。
BigQuery AI クエリエンジンなら、シンプルかつスタック可能な SQL でそれを実現できます。BigQuery DataFrames は、AI クエリエンジンと連携する DataFrame インターフェースを備えています。コードの例は以下のとおりです。
-
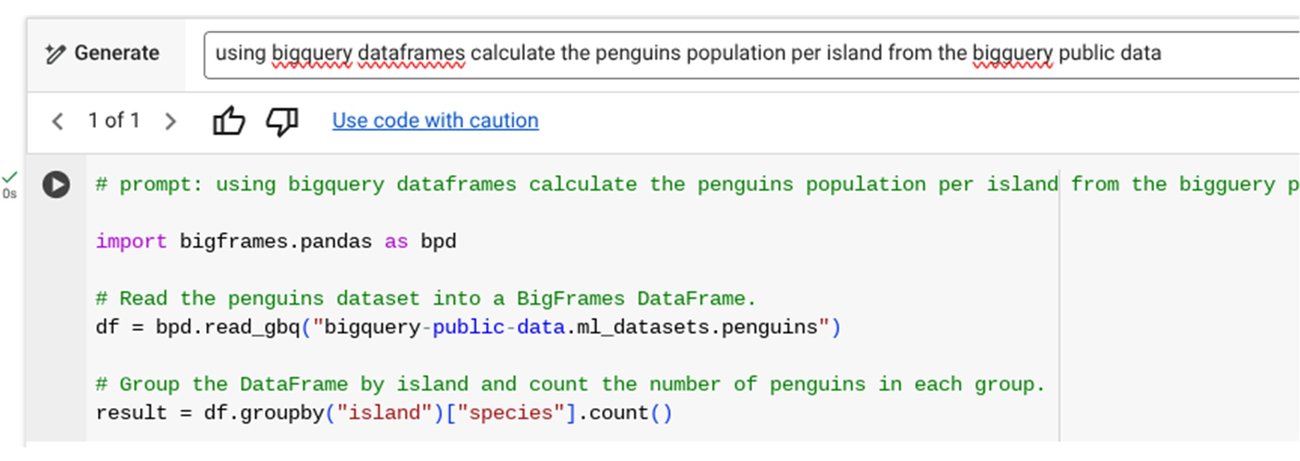
DataFrames 向け Gemini Code Assist(プレビュー): コード生成に関するユーザーの期待の高まりを受け、BigQuery Studio 内で自然言語プロンプトを直接使用して BigQuery DataFrames コードを簡単に開発できるようにする取り組みも行っています。Gemini のコンテキスト理解と DataFrames 固有のトレーニングを組み合わせることで、スマートかつ効率的なコード生成を実現できます。この機能は Gemini in BigQuery の一部としてリリースされます。
- Python UDF への対応(プレビュー): BigQuery Python ユーザー定義関数をプレビュー版で利用できるようになりました(ドキュメントをご覧ください)。
BigQuery DataFrames 内で、サーバーレスのスケールアウト実行により、Python 関数の実行を数百万行に自動スケールできます。サーバーサイドに push する必要がある関数に加えて、「@udf」デコレータを追加するだけです。
Python UDF を使用して、BigQuery の一般公開テーブル(約 9,000 万行)に保存されている stackoverflow データからコメントをトークン化するコードの例を以下に示します。
時代のニーズに応えるソリューション
長年にわたり、非構造化データの多くは、データ ウェアハウス内の構造化データとは別のサイロに格納されていました。このように分離されていることで、包括的な分析を実行し、真に強力な AI モデルを構築する能力が制限されていました。BigQuery のマルチモーダル機能と BigQuery Dataframes 2.0 は、従来データレイクに関連付けられていた機能をデータ ウェアハウスに直接組み込むことでこの隔たりを解消し、以下に対応できるようにします。
-
統合データ分析: すべての構造化データと非構造化データを、一貫性のある Pandas のような単一の API を使用して一元的に分析できます。
-
LLM を活用した分析情報: LLM の性能と構造化データの豊富なコンテキストを組み合わせることで、より深い分析情報を得ることができます。
-
ワークフローの簡素化: データ パイプラインを効率化し、複雑なデータの移動や変換の必要性を軽減します。
-
スケーラビリティとガバナンス: BigQuery のサーバーレス アーキテクチャと強力なガバナンス機能を利用して、形式を問わずあらゆるデータを管理できます。
BigQuery Dataframes 2.0 のデモ
これらの機能すべてのデモは、Google Cloud Next ’25 の動画でご覧いただけます。
今すぐ使用を開始する
BigQuery Dataframes 2.0 は、データと AI を扱うすべての人々の環境を一変させます。構造に関係なく、あらゆるデータの可能性を最大限に引き出しましょう。今すぐ新機能をお試しください。
-
ドキュメントで詳細をご確認ください。
-
マルチモーダル ユースケースの場合 - こちらのリクエスト フォームに入力して、ObjectRef の許可リストにプロジェクト番号を追加しましょう。
-
こちらのクイックスタートを参照して、BigQuery DataFrames で DBT Python モデルをお試しください。
-
コミュニティに参加 - こちらからメールグループに登録して、BigQuery DataFrames チームとつながりましょう。
-プロダクト マネージャー Sandeep Karmarkar
-テクニカル リーダー Jiaxun Wu
