BigQuery の自動シャーディングで Dataflow のスループットが 3 倍に
Google Cloud Japan Team
※この投稿は米国時間 2021 年 5 月 25 日に、Google Cloud blog に投稿されたものの抄訳です。
ミッション クリティカルなストリーミング分析パイプラインの構築と運用のために、多くの方に Dataflow をご利用いただいています。私たち Dataflow チームの主な目標は、テクノロジーをユーザーのために機能させることであり、ユーザーをテクノロジーに適合させることではありません。Dataflow が提供する基本的な価値提案である自動チューニングは、その目標を実現するうえで欠かせません。これにより、状況の変化に合わせてアプリケーションの調整や再調整を絶えず行うための費用や負担が必要なくなり、ユースケースに専念できます。Dataflow にはすでに多くの自動チューニング機能が含まれており、本日はストリーミング データ パイプラインをさらに簡素化する新しい機能についてお知らせします。
Google BigQuery は、Dataflow ストリーミング パイプラインが結果をエクスポートする対象として、最も一般的なストレージ システムの一つです。Beam SDK には、BigQuery I/O コネクタと呼ばれる組み込みの変換が含まれており、BigQuery テーブルとの間でデータを読み書きすることができます。この書き込み変換は、さまざまな BigQuery 機能(ダイナミック デスティネーションなど)を利用するように最適化されています。一方、Dataflow では現在、ユーザーが numFileShards や numStreamingKeys を手動で構成して、BigQuery 書き込みを並列化しなくてはなりません。この処理はお客様にとって負担です。正しく構成するのは非常に困難で、数多くの手作業が管理に必要になるためです。
現在の課題
最適なシャード数を手動で選択するのは難題であり、次の問題が発生します。
シャーディング値が低すぎると、実行の並列性が不十分になるため、スループットが制限されます。
シャーディング値が高すぎると、オーバーヘッド(Dataflow 側と BigQuery 側の両方)が増え、収穫逓減のリスクがあります。高いシャーディングが原因で BigQuery の割り当てと上限を超えると、パイプラインのスループットがさらに低下する場合があります。
ここでの根本的な問題は、画一的なアプローチは通用しないことです。つまり、ある状態のデータのシャーディングは、状況が変化した場合(ボリュームが変化した場合や、他に比べてボリュームがはるかに多い「ホットスポット」がある場合など)に適切な選択肢にならないことがあります。
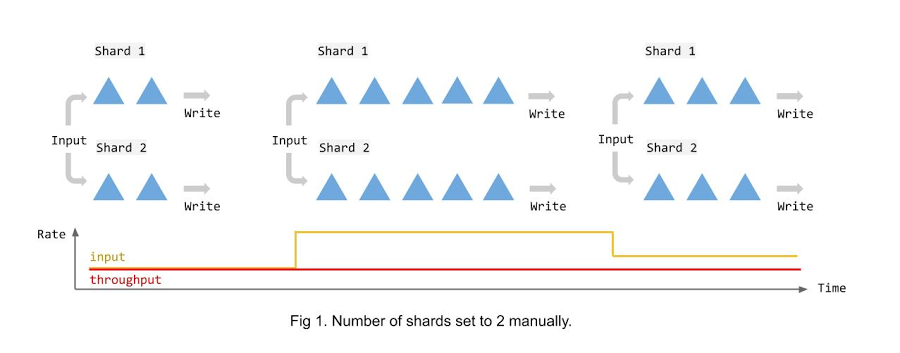
次の図は、データを BigQuery テーブルにストリーミングする際の、手動の固定シャーディングによる影響を示しています。ご覧のとおり、データの量に関係なくシャード数は一定で、入力レートが上昇するとシャード数が不足します。この構成の結果、データ量の変化に関係なくスループットが時間の経過とともに一定に保たれます。この場合にシャードよりもワーカーノードの数を増やしても、ほとんど役に立たない可能性があります。
BigQuery の自動シャーディングの導入
BigQuery シンクの並列処理について面倒な手動調整をしなくても済むように、Dataflow Streaming Engine に新機能の自動シャーディングを導入しています。自動シャーディングを使用すると、Dataflow は BigQuery 書き込みのシャード数を動的に調整し、入力レートに対応するように負荷を分散します。
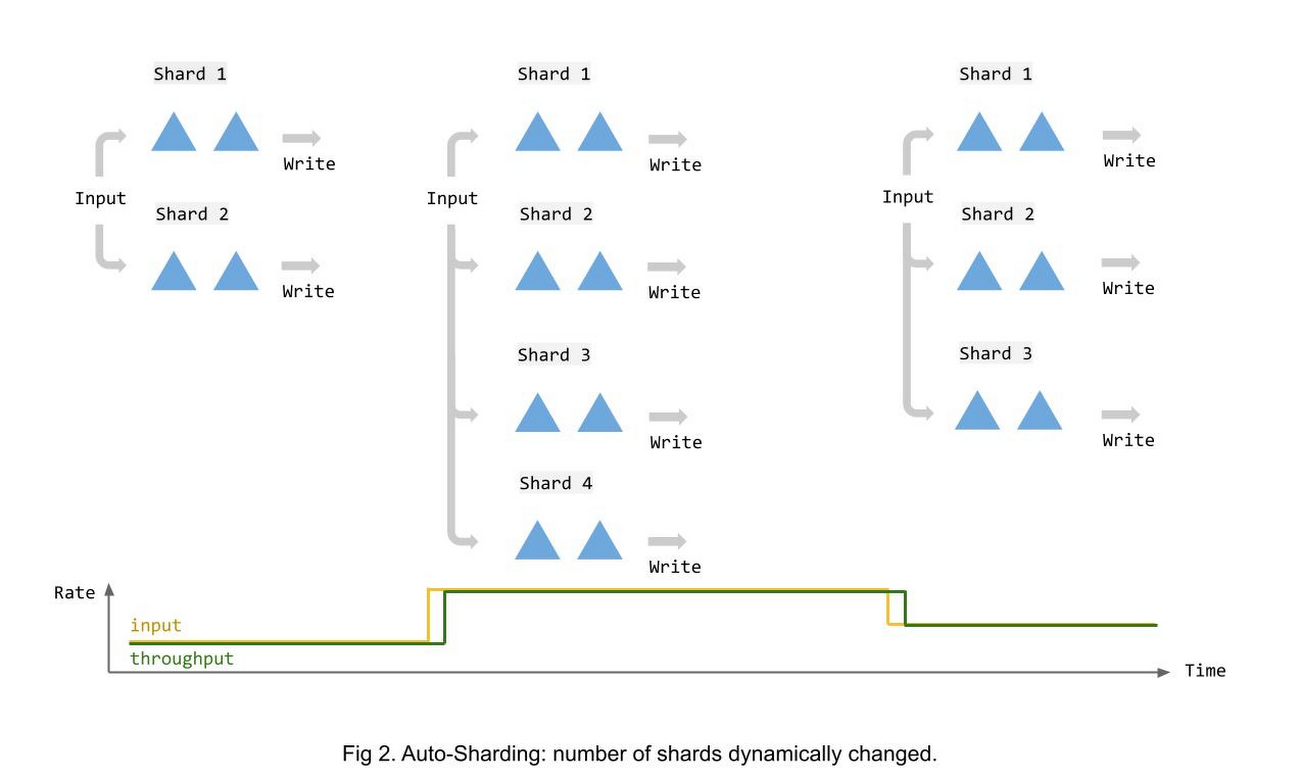
次の図は、入力データ量の変化に応じてシャーディングが時間とともにどのように変化するかを示しています。
利点
メリットの範囲を見極めるために、負荷テストを実施して、自動シャーディングを使用する場合と使用しない場合の BigQuery I/O コネクタのパフォーマンスを比較しました。パフォーマンスのメリットを包括的に把握するために、5~150 のワーカー数のスループットを比べました。
次のグラフに示すとおり、自動シャーディングは BigQuery ストリーミング挿入を使用した手動(および固定)シャーディングよりも性能が優れています。ほとんどの場合、他の変更を加えなくてもスループットが 2~3 倍向上しました。一般に、ワーカーあたりのスループットが向上すると、必要なワーカー数が削減され、ひいてはコスト削減につながる可能性があります。
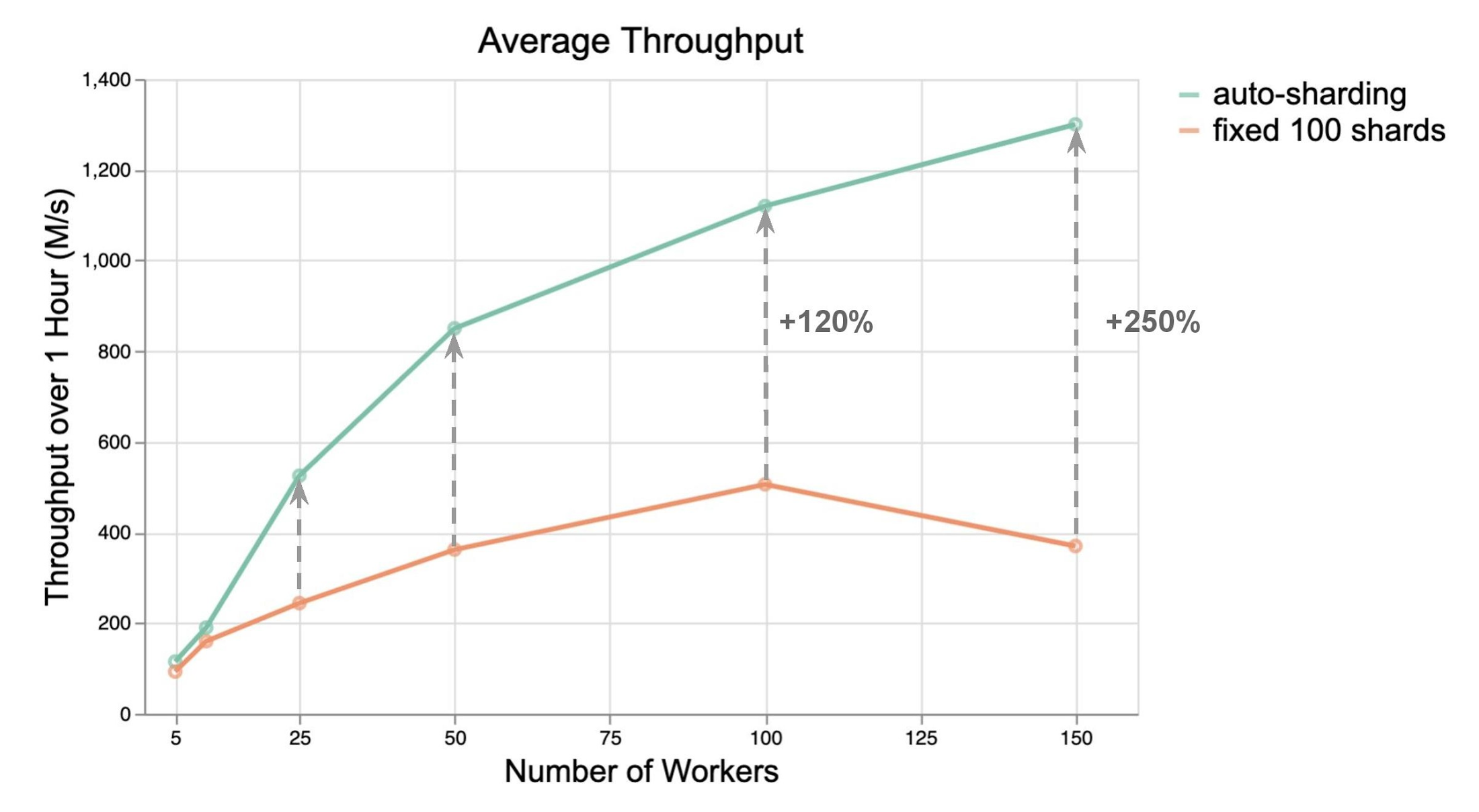
ワーカー数が増えると、スループットの差が広がります。このことは非常に重要です。入力量の増加に対処するためにパイプラインの規模が大きくなるにつれ、シャーディング構成を手動で選択することがとても大変になるからです。
ストリーミングの自動シャーディングは、データの BigQuery バッチ読み込みでも機能し、同様に改善されます。具体的には、スループットが 160~260% 向上します。
BigQuery シンクの自動シャーディングを有効にする方法
コードで BigQuery I/O コネクタを構成する際に新しいオプションを設定すると、Streaming Engine で自動シャーディングを有効にすることができます。このオプションは、ストリーミング挿入モードとファイル読み込みモードの両方でご利用になれます(Java 用 Beam 2.29.0 と Python 用 Beam 2.30.0 以降)。または、Beam 2.28.0 Java SDK を使用してストリーミング挿入の自動シャーディングを選択する際に、追加の Dataflow テスト --experiments=enable_streaming_auto_sharding を指定できます。
自動シャーディングを有効にするコードサンプルは次のとおりです。
Java:
新しいオプションを使用すると、BigQuery の書き込みのシャーディングは実行時に自動的に決定され、使用できるワーカーを最適に利用できます。自動スケーリングがオンの場合、ワーカー数の変更時にすべてのワーカーがビジー状態を保つように、シャーディングが調整されます。シャード数は明示的に公開されませんが、シャーディングの変更はデータの更新頻度やスループットなどのジョブ指標に反映されます。
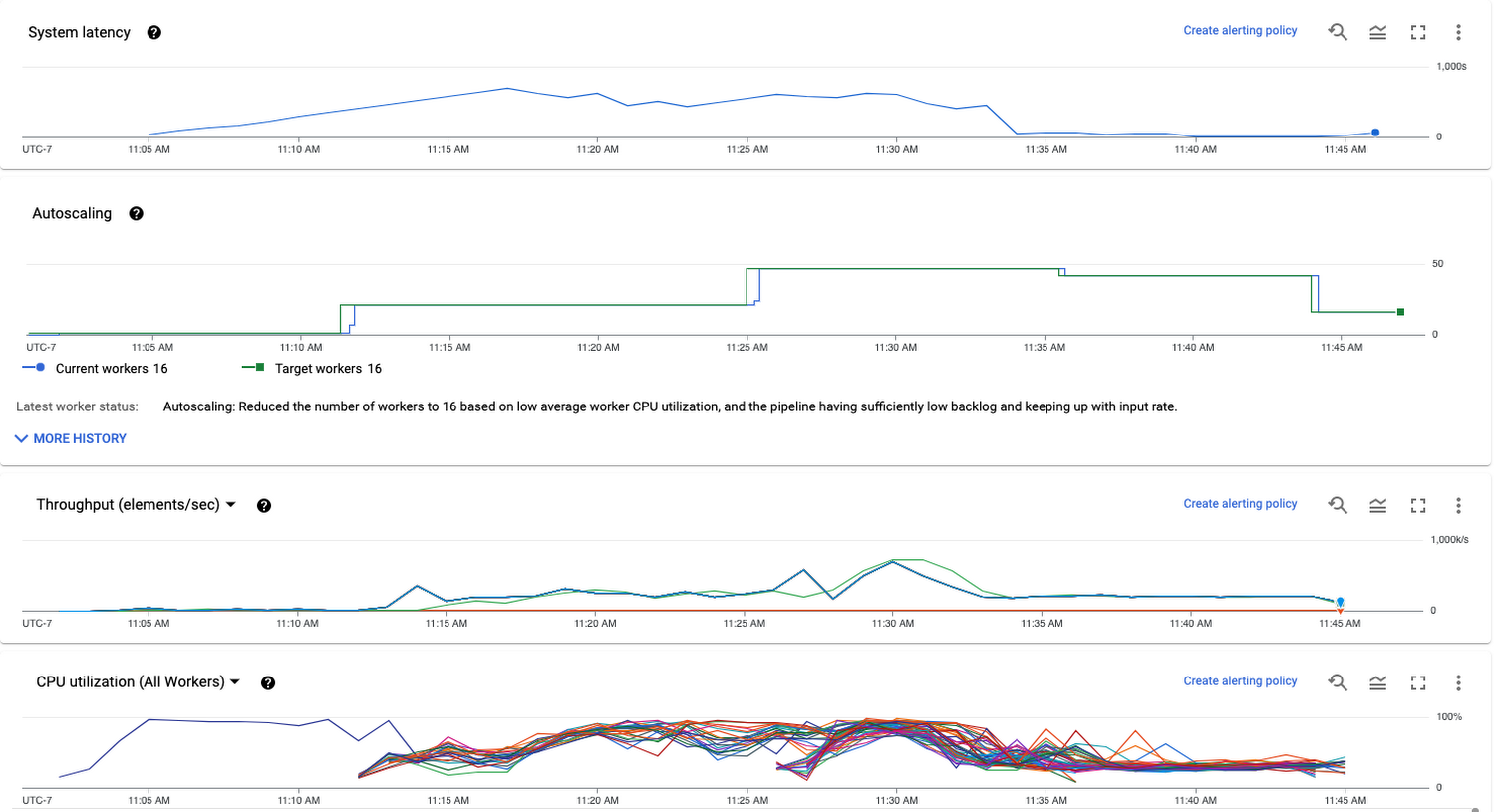
たとえば、システム レイテンシが増大すると、トリガーされるワーカーが増え、シャード数が増加します。その結果、スループットが向上し、バックログがより高速にクリアされます。Dataflow コンソールを使用して、BigQuery 書き込みステージのワーカー数とスループットをモニタリングできます。
使用を開始するには、BigQuery IO コネクタのドキュメントと概要ページを参照して、BigQuery へのデータ取り込みのさまざまな方法や、お客様のニーズに合った方法の選び方について詳細をご確認ください。
-Google Cloud ソフトウェア エンジニア Siyuan Chen
-Google Cloud ストリーミング分析担当プロダクト マネージャー Shanmugam(Shan)Kulandaivel



