Google Kubernetes Engine 上でコールド スタートによるレイテンシを減らす 4 つの方法
Google Cloud Japan Team
※この投稿は米国時間 2024 年 1 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
Kubernetes でワークロードを実行しているなら、「コールド スタート」の経験がおありではないでしょうか。コールド スタートとは、ワークロードがまだホストされたことがない新しいノードにスケジュールされ、Pod をあらためてスピンアップする必要が生じ、アプリケーションの起動が遅れる現象を指します。起動に時間がかかると応答が遅くなり、ユーザー エクスペリエンスの悪化につながります。特に、アプリケーションがトラフィックの急増に対処するために自動スケーリングが行われるときに、この影響が顕著になります。
コールド スタートでは、何が起きているのでしょうか。コンテナ化されたアプリケーションを Kubernetes 上でデプロイするには、通常、コンテナ イメージの pull、コンテナの起動、アプリケーション コードの初期化など、いくつかの処理が必要となります。これらの処理がすべて完了してから Pod がトラフィックへの対応を開始するという仕組みになっているため、新しい Pod が最初のリクエストを処理する際は、レイテンシが増加します。特に、新しいノードを初めて起動するときは、ノードに既存のコンテナ イメージがないため、時間が極端に長くなる可能性があります。後続のリクエストについては、Pod がすでに起動してウォームアップ済みであるため、追加の時間がかからずにすばやく対応できます。
Pod のシャットダウンおよび再起動を繰り返し行うと、そのたびにリクエストが新しい(コールドな)Pod にルーティングされるため、コールド スタートが頻発します。これを防ぐ一般的な対策として、ウォームアップ済みの Pod プールを準備することによって、コールド スタートのレイテンシを減らすという方法があります。
しかし、AI や ML などの大規模なワークロードになると、ウォームアップ済みのプールを準備しておく方法は費用が高く、特に、料金が高くリソースが不足気味の GPU においては莫大な費用がかかります。そのため、AI / ML ワークロードではリクエストの完了時に Pod をシャットダウンするのが一般的であり、コールド スタートは珍しくありません。
Google Kubernetes Engine(GKE)は Google Cloud のマネージド Kubernetes サービスであり、コンテナ化された複雑なワークロードのデプロイ、維持を簡単に行えるようにします。この投稿では、GKE でコールド スタートのレイテンシを減らし、レスポンシブなサービスを提供できるようにする 4 つのテクニックを紹介します。
コールド スタートに対処するテクニック
ローカル SSD(大規模なブートディスク)でエフェメラル ストレージを使用する
Kubelet およびコンテナ ランタイム(docker または containerd)のルート ディレクトリは、ノードのローカル SSD にマウントされます。そのため、コンテナレイヤはローカル SSD を基盤とすることになります。ローカル SSD の IOPS およびスループットは、ローカル SSD についてに記載されているとおりです。この方法は基本的に、永続ディスク(PD)のサイズを大きくする方法よりも費用対効果が高くなります。
以下の表に、同じ費用に対する各方法の比較を示します。ローカル SSD のスループットは PD の 3 倍以上であり、イメージの pull を高速に行えるため、ワークロード起動のレイテンシが短縮されます。
|
費用 |
ローカル SSD |
バランス PD |
スループットの比較 |
|||
|
月額 |
保存容量 (GB) |
スループット(MB/s) R W |
保存容量 (GB) |
スループット (MB/s) R+W |
ローカル SSD / PD (読み取り) |
ローカル SSD / PD (書き込み) |
|
$ |
375 |
660 350 |
300 |
140 |
471% |
250% |
|
$$ |
750 |
1320 700 |
600 |
168 |
786% |
417% |
|
$$$ |
1125 |
1980 1050 |
900 |
252 |
786% |
417% |
|
$$$$ |
1500 |
2650 1400 |
1200 |
336 |
789% |
417% |
GKE バージョン 1.25.3-gke.1800 以降を実行する既存のクラスタでは、ローカル SSD 上でエフェメラル ストレージを使用するノードプールを作成することができます。
詳しくは、ローカル SSD を使用したエフェメラル ストレージのプロビジョニングをご覧ください。
2. コンテナのイメージ ストリーミングを有効にする
イメージ ストリーミングを使えば、イメージ全体のダウンロード完了を待たずにワークロードを開始できるため、ワークロードの起動時間が大幅に短縮します。たとえば、NVIDIA Triton Server(5.4GB のコンテナ イメージ)の場合、GKE のイメージ ストリーミングを使えば、エンドツーエンドの起動時間(ワークロードが作成されてから、サーバーがトラフィックに対応できるようになるまでの時間)を 191 秒から 30 秒に短縮できる可能性があります。
なお、コンテナに Artifact Registry を使用して、要件を満たす必要があります。クラスタ上でイメージ ストリーミングを有効にするには、以下のように記述してください。
詳しくは、イメージ ストリーミングを使用してコンテナ イメージを pull するをご覧ください。
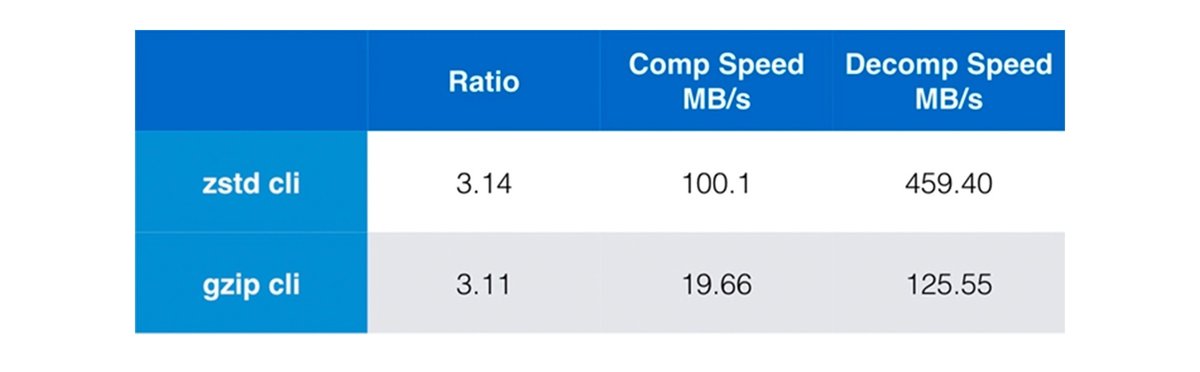
3. Zstandard で圧縮したコンテナ イメージを使用する
Zstandard 圧縮は、ContainerD でサポートされている機能です。Zstandard のベンチマークによると、zstd は gzip(現在のデフォルト)よりも解凍が 3 倍以上高速です。
docker buildx で zstd ビルダーを使用する方法は以下のとおりです。
イメージをビルドして push する方法は以下のとおりです。
なお、Zstandard はイメージ ストリーミングに対応していませんのでご注意ください。アプリケーションの開始前にコンテナ イメージの大半を読み込んでおく必要がある場合は、Zstandard のほうが適しています。アプリケーションの実行開始前にコンテナ イメージ全体の一部のみを読み込んでおけばよい場合は、イメージ ストリーミングをお試しください。
4. プリローダーの DaemonSet を使って、ノード上にベースコンテナをプリロードする
最後に重要なポイントとして、複数のコンテナが同じベースコンテナを共有する場合、ContainerD はそのイメージレイヤを再利用するということが挙げられます。GPU ドライバをインストールする前でも、プリローダーの DaemonSet は開始できます(GPU ドライバのインストールには 30 秒ほどかかります)。つまり、GPU ワークロードが GPU ノードにスケジュールされる前に、必要なコンテナをプリロードして、イメージを前もって pull し始めることができます。
プリローダーの DaemonSet の例を以下に示します。
コールド スタートに賢く対処する
コールド スタートは、コンテナ オーケストレーション システムに共通する課題ですが、綿密に計画して最適化することによって、GKE 上でのアプリケーション実行への影響を軽減することが可能です。具体的には、大規模なブートディスク上でエフェメラル ストレージを使用する、コンテナ ストリーミングを有効にする、Zstandard 圧縮を有効にする、DaemonSet でベースコンテナをプリロードするといった方法によって、コールド スタートの遅延を減らし、レスポンシブで効率的なシステムを実現できるようになります。GKE について詳しくは、ユーザーガイドをご覧ください。
ー ソフトウェア エンジニア Tao He
ー AI / ML プロダクト マネージャー Winston Chiang

