GKE Autopilot の費用対効果と従来のマネージド Kubernetes との比較
Google Cloud Japan Team
※この投稿は米国時間 2023 年 7 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Kubernetes Engine(GKE)の推奨されるデフォルトのクラスタ運用モードとして、GKE Autopilot が従来のマネージド Kubernetes と比較して、Kubernetes の総所有コスト(TCO)を最大 85% 節約できる1ことをお伝えしました。これはかなりの費用削減が見込めます。GKE Autopilot ユーザーのメリットである運用費用の削減は言うまでもありません。
では、どうすればこのような費用削減を実現できるのでしょうか。こうした費用対効果はどこから生じるのでしょうか。さらに言えば、Autopilot モードをどのように使えば最大限に費用を抑えることができるのでしょうか。今回のブログ投稿では、GKE Autopilot の料金の仕組みを詳しく説明し、Kubernetes の費用対効果分析で考慮すべき事項の種類を検討します。
従来のマネージド Kubernetes 料金モデル
少し話が逸れますが、まずは従来のマネージド Kubernetes 環境での料金の仕組みをおさらいしておきましょう。Kubernetes クラスタは、基礎となるコンピューティング リソースおよびインフラストラクチャ リソース(通常は仮想マシン、つまり VM)であるノード上でワークロードを実行します。従来のマネージド Kubernetes では、CPU / メモリ比率やその他の属性(例: どの Compute Engine マシン ファミリーで実行されているか、など)を含め、こういったプロビジョニングされたノードの対価を間接的に料金を支払うことになっています。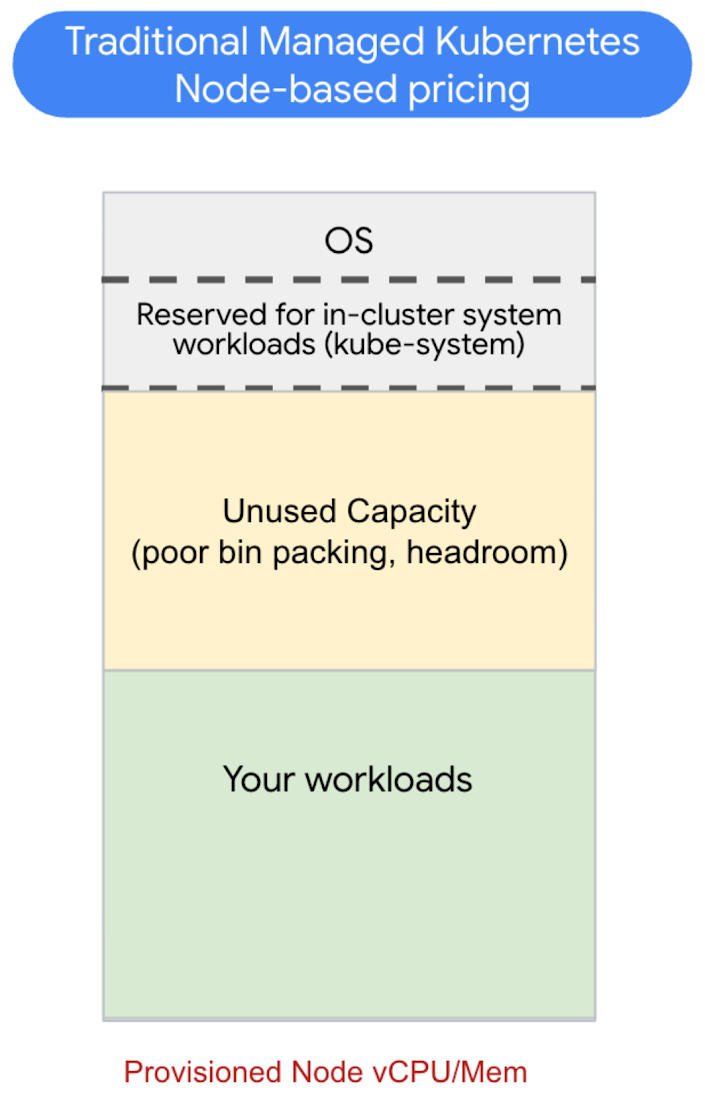
Kubernetes は、それらの利用可能なノードリソースを使用してワークロードを実行し、スケーリングします。これは通常、Kubernetes のスケジュール設定により自動的に行われます。その請求の仕組みはというと、ノードがワークロードによってどれだけ効率的に利用されているかにかかわらず、基礎となるノード全体の対価が請求され、お客様はこれを支払うことになります。つまり、プロビジョニングされたリソースを効率的に利用できるかどうかは、お客様次第なのです。
さらに、実際にワークロードに利用できるのは、これらのノードの一部のみです。ノードでは、コンテナに加えて、オペレーティング システム(Container-Optimized OS など)と、いくつかの最優先システムレベルの Kubernetes システム コンポーネントも実行されます。また、クラウド プロバイダが Kubernetes ノード上で追加サービスを実行することがよくあります。これらはすべてリソースを消費します。つまり、ノードの容量によっては、ノードのかなりの部分が使用できないにもかかわらず、お客様は全体の料金を支払っていることになります。
こういったシステムレベルのリソースすべての料金を支払っていなかったとしても、従来のマネージド Kubernetes 環境の費用を最適化するのはやはり難しいことです。ノードをリソースの「ビン」と考えると、「ビンパッキング」は、利用可能なノード容量でワークロードを効率的に実行する技術と言えます。ノードのリソースには限りがあるため、ワークロードのリソース要件に合わせて、プロビジョニングするノードの形状とサイズを慎重に検討する必要があります。実際には、これを一貫性のある方法でうまく行うのは困難です。スケール イベントに十分な空き容量を残しつつ、スケーリングや Pod のライフサイクルといったワークロードの変化を常に把握しておく必要があります。
GKE Autopilot の料金モデル
さて、Kubernetes クラスタを 100% に近い効率でビンパッキングすることはできそうにないということがわかりましたが、その代替策は何でしょうか。GKE Autopilot モードは、ワークロードがリクエストしたリソースの対価のみを支払い、ビンパッキングは GKE に任せるという新しいアプローチを提供します。このモデルでは、各ワークロードが必要なリソース(マシン ファミリー タイプ、CPU、GPU、メモリ、ストレージ、スポットなど)を指定し、お客様はワークロードの実行中にリクエストされたリソースの対価のみを支払います。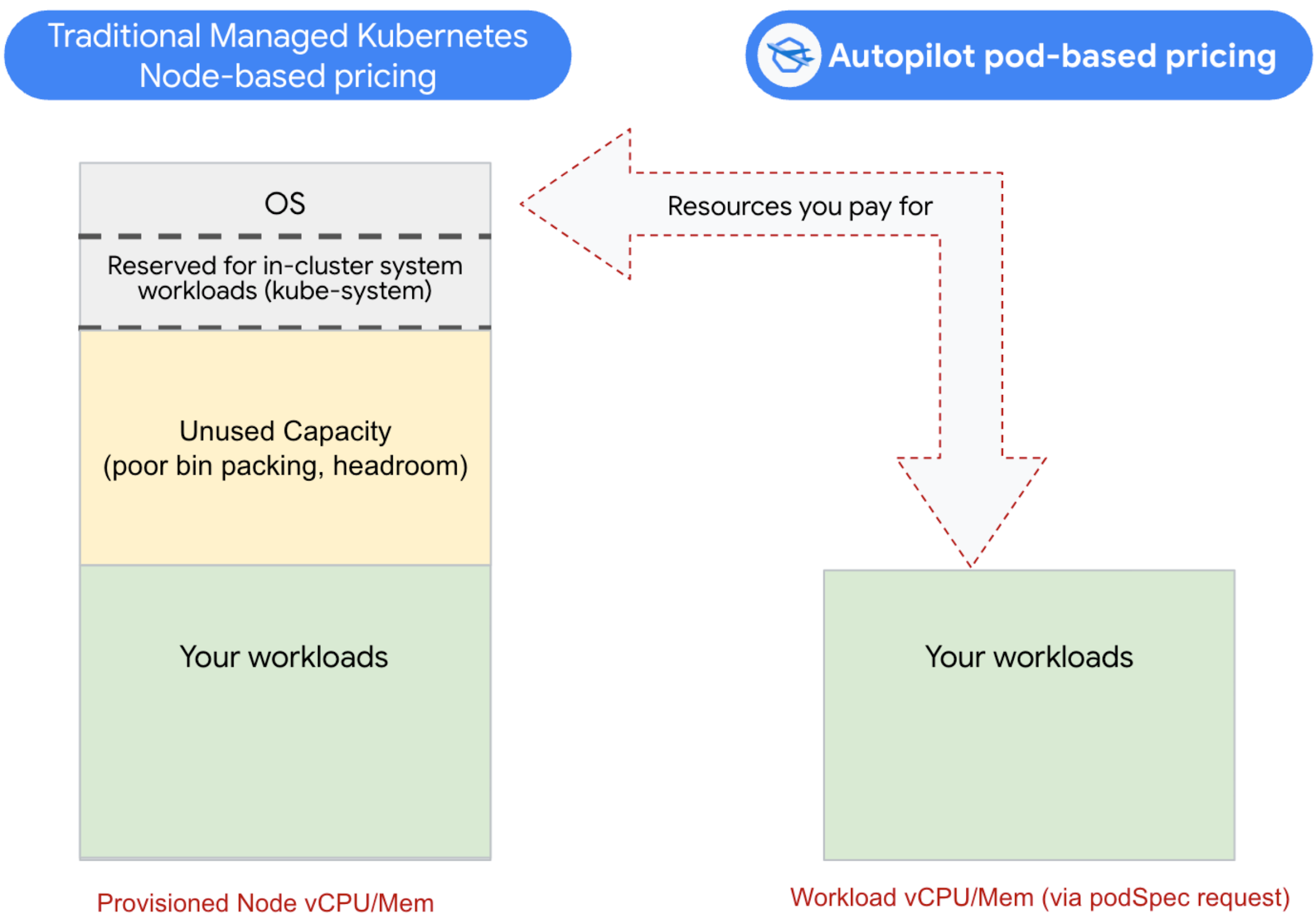
Autopilot では、OS、システム ワークロード、ノード上の未使用の容量の対価を支払う必要はありません。実際には、ノードの効率は完全に GKE が管理します。さらに、有限のノードプールをプロビジョニングする必要がなく、各ワークロードがマシン ファミリーとノードの特性に関して必要なものを定義できるという利点もあります。
では、問題点は何でしょうか。ノード / VM の料金と比較して、Autopilot のリソース単位の料金のほうが高価なのです。ただし、それは GKE Autopilot が従来のマネージド Kubernetes よりも全体的に割高というわけではありません。むしろ、Autopilot がマネージド Kubernetes よりも実際に安くなる利用率の損益分岐点があります。
費用比較のサンプル
独自のワークロードに対する費用分析の方法を説明するために、従来のマネージド Kubernetes と GKE Autopilot モードの両方で、同じワークロードを高可用性構成で実行し、費用を比較してみましょう。わかりやすくするために、ここでは vCPU とメモリに限定しますが、このフレームワークにはストレージも簡単に追加できます。
従来のマネージド Kubernetes では、HA 用に 3 つのゾーンに分散された 12 個の e2-standard-8 タイプのノードを含むクラスタをプロビジョニングします。これにより、最大 96 vCPU / 384 GB メモリが追加され、正規価格での合計費用は 1 か月あたり約 2,545 米ドルになります。
Autopilot の場合、ノードプールを設定する必要はなく、Pod 仕様でワークロードに必要なリソースを指定するだけです。デプロイ後、GKE の組み込み費用最適化ツールを使用して実際の使用状況を分析したところ、周期的な急増はあるものの、ワークロードの使用パターンはほぼ静的であることがわかりました。そのため、リクエストをその静的ベースラインより約 15% 上回る値に設定し、スパイクに対処するために水平 Pod 自動スケーリング(HPA)を構成します。
ターゲット環境には一定数のレプリカが必要であり、それぞれのレプリカが Pod の仕様である resources.requestsを介して CPU と RAM をリクエストします。その結果、約 96% の時間で合計 48 vCPU と 192 GB の RAM になります。HPA は、残りの 4% の時間(1 日あたり約 1 時間)でスケール イベント中にレプリカ数を 3 倍に増加させます。この設定では、Autopilot の正規価格での合計費用は 1 か月あたり約 2,250 米ドルで、マネージド Kubernetes で同等の設定を行うよりも約 12% 安くなります。
この例についていくつか疑問があるかもしれません。まず、なぜ最初から GKE Standard でプロビジョニングするノードの数を少なくしなかったのかと思われるでしょう。これには次の 2 つの理由があります。
ビンパッキングが実際には難しいからです。GKE Standard では Autopilot と同じレベルでのビンパッキングができないため、意図しない制限に達しないように余分な容量をプロビジョニングすることになります。
使用量が急増する場合があり、それに対処できる予備の容量が必要であるからです。
つまり、GKE Autopilot ではリソースをより効率的に使用するため、推測に頼る必要が減り、非効率的な設定を行う場面が減ります。
ゲストの視点: EPAM のお客様が Autopilot でどのように費用を削減しているか
EPAM Systems, Inc.、北米 Google Cloud チーフ テクノロジスト、Stan Drapkin 氏執筆
コスト意識の高いお客様には Autopilot がおすすめ
GKE Autopilot がお客様に広く採用されているのには、いくつかの理由があります。まず、ノードのプロビジョニング、スケーリング、アップグレードなど、時間がかかりエラーが発生しやすい多くのタスクを自動化することで、Kubernetes クラスタの管理が簡素化されます。これにより、開発者やオペレーターはインフラストラクチャの管理ではなく、アプリケーションの構築とデプロイに集中できるようになります。
次に、GKE Autopilot は、安全性と信頼性が高い Kubernetes 環境をデフォルトで提供します。セキュリティに関する業界のベスト プラクティスが実装されており、異常なノードを自動的に置き換えるノードの自動修復や、アプリケーションの需要に基づいてリソースを自動的に調整する水平 Pod 自動スケーリングなどの機能が含まれています。
Autopilot の費用を比較
アプリケーションはさまざまであるため、GKE Autopilot と GKE Standard を適切に定量化できる一般的なベンチマークはありません。最善の比較方法は、GKE Standard と GKE Autopilot の両方に 1 つのアプリケーションをデプロイし、発生する費用を比較することです。
合成データで比較テストした GKE Autopilot デプロイ シナリオのサンプルの 1 つは、決済処理ネットワークをシミュレートするオープンソースの Bank of Anthos(BoA)です。こちらのチュートリアルに従って、このサンプルアプリをデプロイすることも可能です。
BoA のデプロイは 2 つのデータストアと 7 つのサービス(Python で記述された 4 つのサービスと Java で記述された 3 つのサービス)で構成されており、サンプルアプリに関する限り、合理的な「実環境」のテストと言えます。
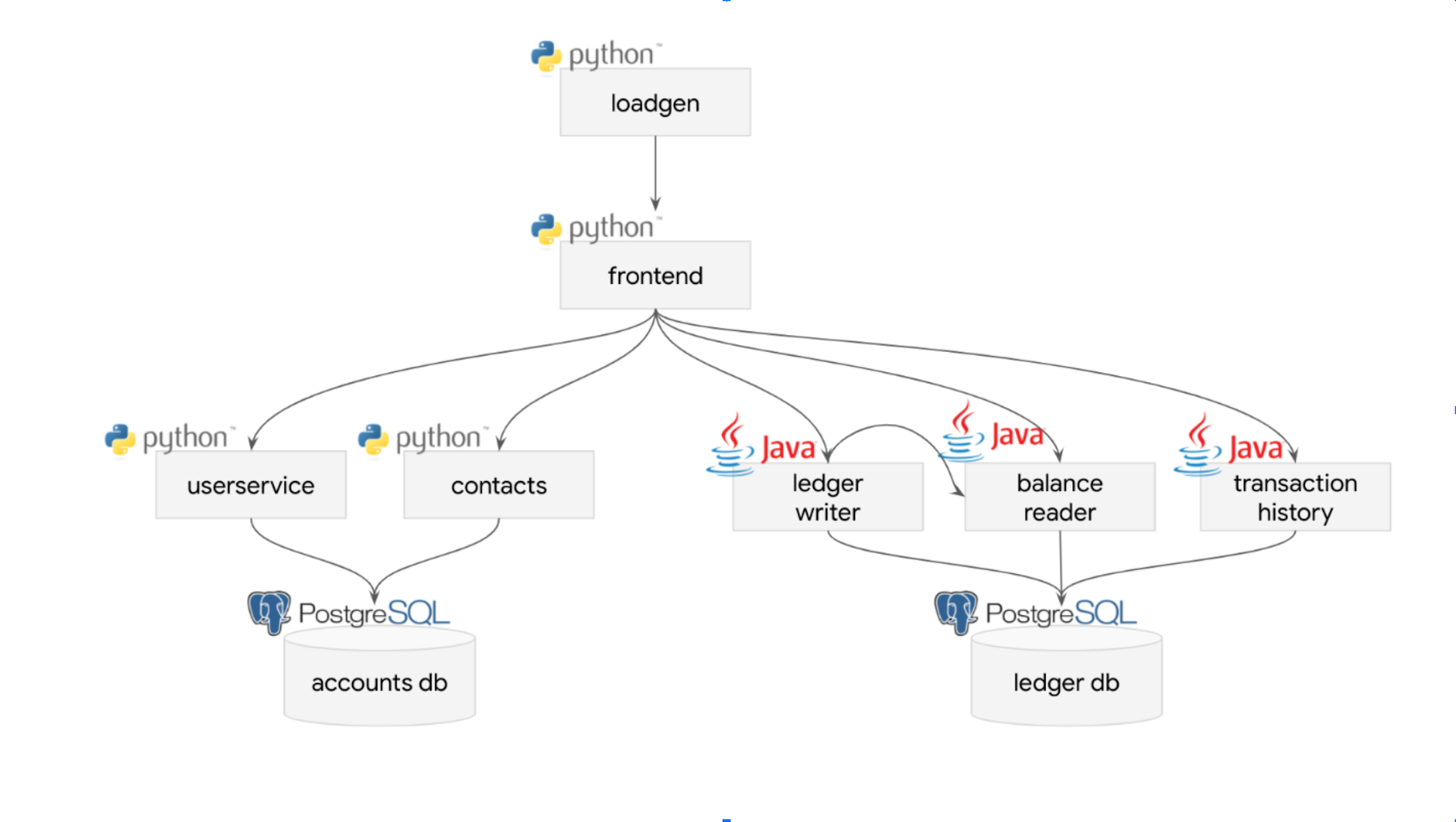
テストでは、Standard と比較して GKE Autopilot で最大 40% の費用削減が確認されました。
また、両方のワークロードの費用を年間ベースで推定しました。GKE Standard ワークロードの場合、年間 3,317 米ドルのクラウド費用が発生します。しかし、GKE Autopilot ワークロードの場合は、わずか 1,906 米ドルで、その差は 1,411 米ドル(42.5%)です。これは単純なワークロードであったため、一般化することはできませんが(特にすでに最適化されたワークロードについて)、特定のケースに対する Autopilot の可能性を示しています。
GKE Autopilot により、Kubernetes ワークロードを実行するための、手間のかからない安全かつ経済的なソリューションが提供されていることがおわかりいただけたと思います。このような理由から、Google Cloud でコンテナ化されたアプリケーションを実行するための主要な選択肢として、GKE Autopilot の採用を検討することをおすすめします。
GKE Autopilot によるソフト セービング
GKE Autopilot には、単なる費用削減以外にもメリットがあります。GKE Autopilot のお客様からは、アプリケーションのために空き容量をそれほど多くプロビジョニングする必要がなくなり、日々の管理作業が大幅に軽減されたと伺っています。それについて、詳しく見ていきましょう。
必要な空き容量を Autopilot で最小化
Autopilot は、高可用性(HA)設定など、プロビジョニングに必要な予備の空き容量を削減するのに有効です。負荷の増加が予想される場合は、追加の空き容量をプロビジョニングすることで、HPA などのオプションで需要の増加に合わせてスケーリングできます。同様に、HA 設定で冗長性を確保するためには、地理的に離れた複数のゾーンに複数のノードを配置する必要がある場合があります。
Autopilot は、スケーリングに応じて新しいハードウェアをオンデマンドでスピンアップするため、アイドル状態にあるインフラストラクチャの空き容量を事前に割り当てる必要はありません。また、Autopilot HA 設定ではノード全体を複製するのではなく、ゾーンごとに Pod をデプロイするだけでよく、はるかに少ない費用で済む可能性があります。また、Autopilot を使用すると、高可用性を必要とする特定のワークロードのみを簡単に複製できるようになり、重要度の低いワークロードを新しい健全なゾーンにオンデマンドで移行できます。
Day 2(運用段階)の運用
従来のマネージド Kubernetes では、プロビジョニング / シェーピング、アップグレード、パッチ適用、セキュリティ インシデントへの対処など、Kubernetes ノードを管理するのはお客様です。
Autopilot では、Google SRE でこれらすべてを行い、GKE Standard SLA に追加する Pod SLA を提供します。同時に、メンテナンス ポリシーにより制御と柔軟性も維持されます。
まとめ
チームがビンパッキングに長けており、ノードを直接管理できる制御レベルが必要な場合は、GKE Standard のような従来のマネージド Kubernetes プラットフォームが最善の選択肢となる可能性が高いです。ただし、たとえビンパッキングという驚異的な仕事をこなしているとしても、多くの時間とエネルギーを費やしている可能性があります。ほとんどの場合、この作業は Kubernetes フリートの規模に比例して増加し、クラスタが小規模になるほど、効率的に実行することにあまり注意を払わなくなります。プラットフォーム チームがビンパッキングに費やした作業を取り戻す必要がある場合、Autopilot を利用することで、Day 2 運用と非効率的なビンパッキングによる財務リスクを軽減できると同時に、より強力なデベロッパー エクスペリエンスを構築できるようになります。
Autopilot の利用をすぐに開始する方法については、次のリソースを確認してください。
コンピューティング クラスを使用してマシンタイプを指定する
Autopilot でフルスタック ワークロードをデプロイする
Redis、高可用性 PostgreSQL、高可用性 Kafka などのワークロードを Autopilot でデプロイする
1. Forrester TEI レポート: GKE Autopilot - 2023 年 1 月 - https://services.google.com/fh/files/misc/forrester_tei_of_gke_autopilot.pdf
- GKE プロダクト マネージャー、Victor Szalvay
- EPAM Systems, Inc.、クラウド、チーフ テクノロジスト、Stan Drapkin 氏

