GKE のベスト プラクティス: 事業継続性を確保する Day 2 のオペレーション

Google Cloud Japan Team
※この投稿は米国時間 2020 年 8 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
これまでのところ、アドバイスどおり Day 0 のガイダンスをもとに可用性の高い Google Kubernetes Engine(GKE)クラスタを構築していただきました。Day 2 は正念場です。構築した GKE クラスタはすでに稼働を開始してアプリにトラフィックを提供しているため、ダウンすることは許されません。Day 0 で行ったことがダウンすることを防ぐうえで効果を発揮するはずですが、ワークロードの可用性が高いだけでは本番環境における事業継続性を確保できません。稼働中断を適切に処理したり、最新のセキュリティ パッチやバグの修正を稼働中断することなく適用したりすることも重要です。
このブログ投稿では、GKE 上で動作するアプリケーションを適切な状態に維持するための推奨事項とベスト プラクティスについて説明します。
稼働中断を管理する
他のプラットフォームのライフサイクルと同様に、GKE クラスタが中断する、更新が必要になる、シャットダウンが必要になるということもあるでしょう。それらを見越して適切な数のレプリカを設定する、Pod 停止予算を設定する、シャットダウン猶予期間を指定するなどして、障害の程度を抑えることができます。
レプリカを用意する
Kubernetes のレプリカというコンセプトについては、聞きなじみがあるのではないでしょうか。レプリカは、ワークロードの冗長性を確保することによって、パフォーマンスとレスポンスを向上させ、単一障害点を回避する役割を果たします。構成されたレプリカは、任意の時間に実行される Pod レプリカの数を制御します。
中断の許容範囲を設定する
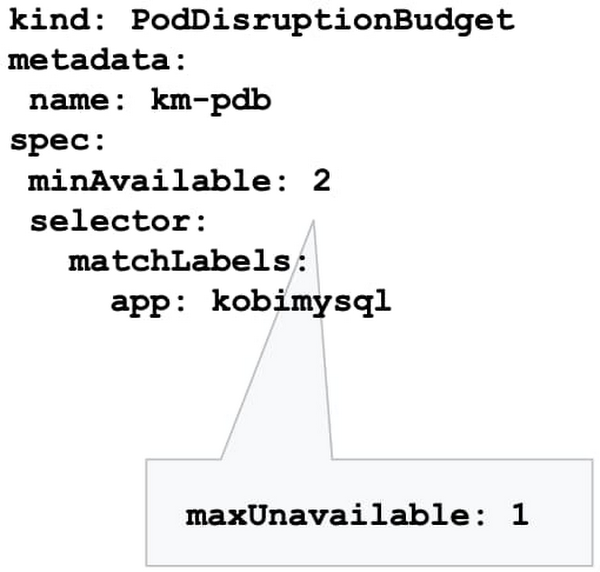
メンテナンス中に基盤となるノード VM が Kubernetes によって削除されることがあり、これがレプリカの数に影響を与えることがあります。どの程度の中断が問題となるか。GKE クラスタのメンテナンス中にワークロードを継続的に運用するために最低限必要なレプリカの数はどのくらいか。これは、Pod 停止予算(PDB)を使用して指定できます。
PodDisruptionBudget を設定すると、メンテナンスの実行中でもワークロードに十分な数のレプリカを提供できます。PDB を使用すると、Pod を停止することで現行のレプリカ数が望ましい値を下回るとしても、停止できる Pod の数(または割合)を定義できます。PDB が構成されると、Kubernetes は構成された中断スケジュールに従ってノードをドレインします。新しい Pod は他の利用可能なノードにデプロイされます。このアプローチにより、PDB の構成に基づいて中断を制御しながら、Kubernetes が確実に最適な方法でワークロードをスケジュールできるようになります。
PDB を設定した場合、Pod の数が構成された上限以下であれば、GKE はアプリケーション内の Pod をシャットダウンしません。GKE では PDB が最大 60 分間適用されます。なお、PDB によって保護されるのは、アップグレードなどの自発的な中断のみであり、ハードウェア障害などの偶発的な障害には対応していません。
停止する前の猶予時間
場合によっては、アプリケーションが予期せず終了することもあります。Kubernetes では、停止する際の猶予時間がデフォルトで 30 秒に設定されています。このデフォルトの猶予時間は、クラウドネイティブの軽量アプリケーションには十分ですが、負担の大きなアプリケーションや、シャットダウン プロセスが長いアプリケーションには短すぎる可能性もあります。
おすすめのベスト プラクティスは、既存の猶予期間を評価し、アーキテクチャとアプリケーションの特定のニーズに基づいて調整することです。猶予時間を変更するには、terminationGracePeriodSeconds の値を変更してください。
更新とパッチ適用をスケジュールする
クラスタのセキュリティ パッチとバグ修正を最新の状態に維持することは、クラスタの健全性と事業継続性を確保するために特に重要です。定期的な更新により、ワークロードが脆弱性や障害から保護されます。
ただし、こうした更新を利用する際はタイミングが重要となります。特に、多くのチームが自宅で仕事をしていたり対応力が落ちていたりする現状では、これらのアップグレードの予測可能性を高め、通常の勤務時間中の変更を避けたいと考えるでしょう。そのためには、メンテナンスの時間枠設定、ロールアウトの順序付け、メンテナンスの除外設定を行います。
メンテナンスの時間枠を設定する
メンテナンスの時間枠を設定することで、クラスタ コントロール プレーンとそのノードの両方の自動アップグレードを制御できます。GKE ではメンテナンスの時間枠が適用されます。つまり、アップグレードのプロセスがメンテナンスの時間枠を超えて実行されると、GKE はオペレーションを一時停止し、次のメンテナンス時間枠の間に再開を試みます。
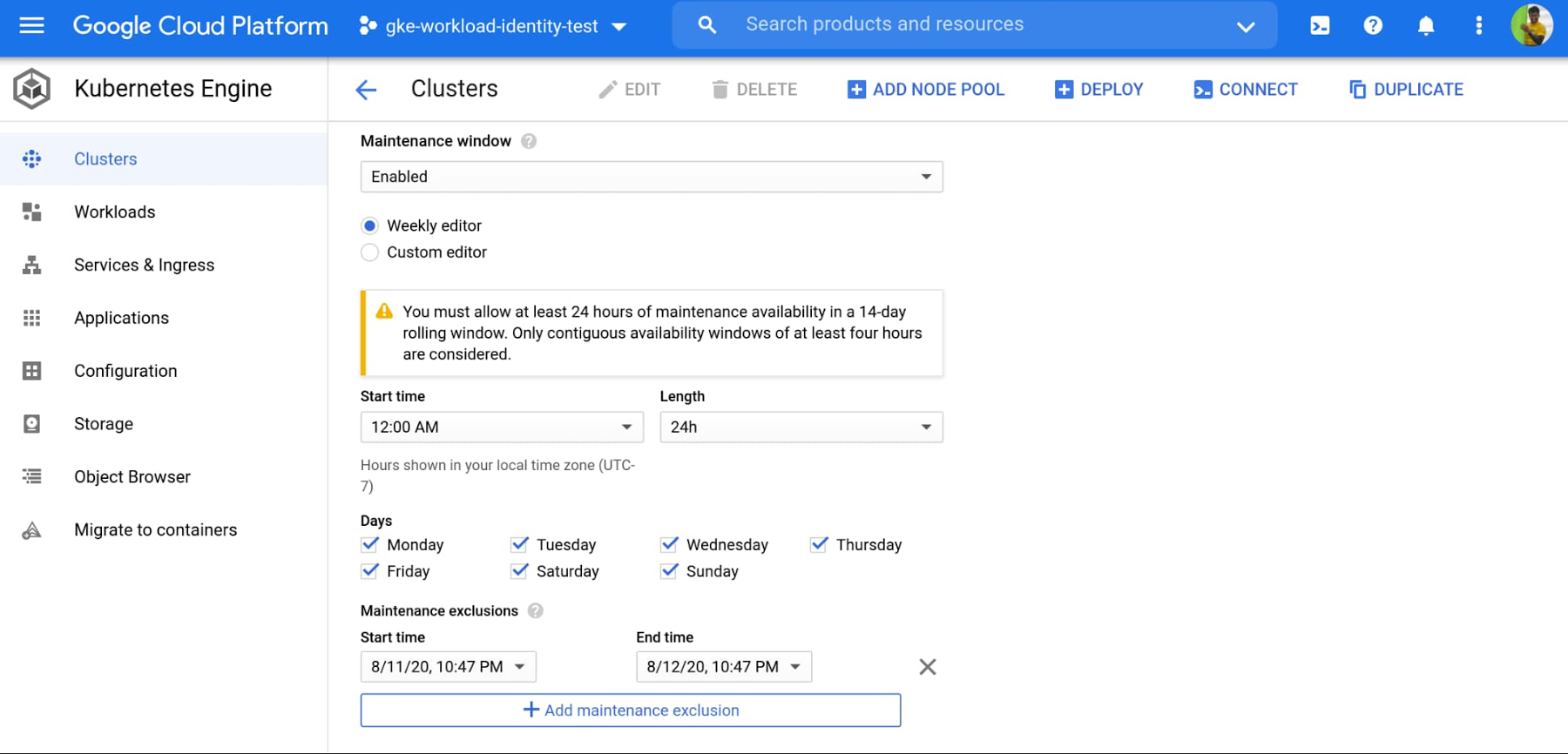
さまざまなクラスタの中断を制御、順序付けするには、マルチクラスタ環境でメンテナンスの時間枠を使用します。たとえば、クラスタごとに異なるメンテナンスの時間枠を設定すると、各種リージョンのクラスタでメンテナンスが行われるタイミングを制御できます。
定期的に更新する
フリートでパッチが利用可能になると、新しい GKE のリリースが定期的にロールアウトされます。
こうした更新のロールアウトは段階的に実施され、一部のアップグレードは GKE フリート全体で完全にロールアウトされるまで数週間かかることがあります。
状況があいまいなときには、メンテナンスの時間枠を設定することで、1 週間内に実施するメンテナンスの曜日と時間を指定して、クラスタのメンテナンスをより適切に計画、予測できます。
メンテナンスを回避する
休日、繁忙期、会社のイベントなど、クラスタが確実にトラフィックを受信できるようにメンテナンスを完全に回避した方がよい場合もあります。メンテナンスの除外を指定すると、特定の期間の自動メンテナンスを回避できます。メンテナンスの除外は新規または既存のクラスタに設定できます。また、除外の時間枠はアップグレード戦略と併用することもできます。たとえば、アップグレードが原因でテストまたはステージング環境に障害が発生する場合は、本番環境クラスタへのアップグレードを延期することも考えられます。
中断せずにノードプールのバージョンをアップグレードする
GKE ノードプールのアップグレードではノードプール内のすべての VM が再作成するため、特に中断を招きがちなプロセスです。このプロセスでは、ローリング アップデート方式で新しいバージョン(アップグレードされたイメージ)を使用して新しい VM が作成されます。この際、古いノードで稼働しているすべての Pod をシャットダウンして新しいノードに移行する必要があります。
上記の推奨事項に従い、十分な冗長性(レプリカ)を確保しながらワークロードを実行することで、中断を最大限回避できます。また、必要に応じて Kubernetes を利用して Pod を移動し再起動することもできます。ただし、レプリカの数が一時的に減少すると業務を中断しなければならない可能性があり、Kubernetes が再び目標の状態(必要なレプリカの最小数)を満たすことができるまで、ワークロードのパフォーマンス低下を招く場合があります。GKE ノードのサージ アップグレード機能を利用すると、このような中断を完全に回避できます。サージ アップグレードを有効にすると、新しいノードが作成された後、古いノードのみがドレイン、シャットダウンされます。これにより、アップグレードに必要なリソース(マシン)が保護されます。こうして、アップグレード プロセスを通じて、想定の容量が維持されます。
大規模なクラスタのアップグレードを高速化する
クラスタが大規模になるほどノードプールも大きくなります。一度に 1 つのノードを更新する場合、特にメンテナンスの時間枠を設定している場合は、アップグレードに長い時間がかかる可能性があります。この場合、アップグレードはメンテナンスの時間枠の最初から開始され、メンテナンスの時間枠中(4 時間)続きます。割り当てたメンテナンスの時間枠内に GKE でノードのアップグレードをすべて完了できない場合、アップグレードは一時停止され、次のメンテナンスの時間枠で再開されます。
アップグレード完了時間を短縮するには、サージ アップグレード機能を使用して複数のノードを同時にアップグレードします。たとえば、maxSurge = 20、maxUnavailable = 0 に設定すると、GKE は既存の容量を一切使用せず、一度に 20 個のノードをアップグレードします。
まとめ
コンテナ化されたアプリケーションは、移植可能で、デプロイとスケーリングが容易です。GKE を利用すると、さまざまなクラスタ管理機能により、手間をかけずにワークロードを実行しやすくなります。アプリケーションについて最も精通しているのはあなたです。上記の推奨事項に従えば、クラスタの可用性と健全性を大幅に向上させることができるでしょう。
詳細については、2020 年 8 月 25 日に開催される Google Cloud Next ‘20: OnAir のセッション先行き不透明なときに、GKE によるビジネスの完全デジタル化で業務を確実に継続するにご登録ください。
-Google Kubernetes Engine プロダクト マネージャー Kobi Magnezi



