水平 Pod 自動スケーリングのチューニングの驚くべき経済性
Roman Arcea
Product Manager, GKE
Marcin Maciejewski
GKE Product Manager
※この投稿は米国時間 2024 年 5 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
Kubernetes HorizontalPodAutoscaler(HPA)は、環境のスケーラビリティと効率を管理するための基本的なツールであり、負荷の増加に応じてデプロイする Pod を増やすことで機能します。しかし、HPA で優れたコスト パフォーマンスを実現するには、HPA の設定、特に CPU 使用率の目標値の微細な部分を理解しなければなりません。一般的に、CPU 目標値を 50% に設定することが出発点として有効であるという認識があります。しかし、これは実際に費用の増加につながりかねません。実際、HPA の CPU 目標値を 50% に設定した場合は、70% に設定した場合よりもはるかに多くのプロビジョニングされたリソースが必要になるにもかかわらず、パフォーマンスへの影響はあまり見られません。また、Pod のリソース リクエストなどの設定を変更することで、費用、パフォーマンス、アジリティのバランスが改善されることもあります。
このブログ投稿では、Google Kubernetes Engine(GKE)の基本的な HPA 最適化戦略の詳細を確認いただけるように、その理由を探っていきます。
リソース効率化の難問
表面的には、HPA の CPU 使用率の目標値を 50% に設定することは、効率を確保する安全な方法のように見えます。しかし、これは費用とパフォーマンスの不均衡につながる可能性があります。これを説明するために、一般的なトラフィック パターンに基づいた合成ワークロード テストを実施しました。2 つの CPU 目標値(50%、70%)を設定した場合と、2 番目の HPA 目標シナリオ(70%)で Pod のリソース リクエストを変更した場合の自動スケーリングを比較しました。
シナリオ 1: HPA の CPU 目標値が 50%、リソース リクエストが 1 CPU/Pod50% の CPU 目標値と適用されたトラフィック パターンにより、HPA は CPU 数を 22 にスケールしました。このセットアップにより、エンドユーザーの平均レスポンス時間は 293 ミリ秒、P95 のレスポンス時間は一貫して 395 ミリ秒となりました。
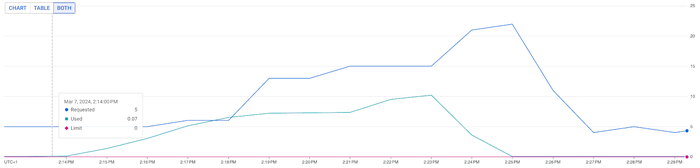
シナリオ 2: HPA の CPU 目標値が 70%、リソース リクエストが 1 CPU/Pod一方で、CPU 目標値が 70% の場合、HPA は同じユーザー負荷下で CPU 数を 12 までしかスケールしませんでした。これは、HPA の CPU 目標値が 50% の場合と比較して、リソースが 84% も削減されたことを意味します。エンドユーザーのパフォーマンスには若干の影響がありましたが(平均レスポンス時間は 293 ミリ秒から 360 ミリ秒に、P95 レイテンシは 398 ミリ秒から 750 ミリ秒に増加)、これはリソース効率とパフォーマンスの間のトレードオフの可能性を示しています。
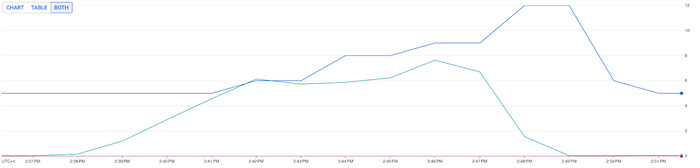
シナリオ 3: HPA の CPU 目標値が 70%、リソース リクエストが 0.5 CPU/Pod費用とパフォーマンスのバランスを取るために使用できるのは、HPA の CPU 目標値の設定だけではありません。Pod のリソース リクエストを調整することもできます。
3 番目のテストでは、HPA の CPU 目標値は 70% のままですが、Pod あたり 1 CPU(1 コア)をリクエストするのではなく、値を 500 ミリコアに設定し、ベンチマークの開始点を同じにするために、Pod のアイドル状態を 5 から 10 に倍増しました。これにより、HPA アルゴリズムは、Pod の一般のベースラインよりも大幅にスケールするようになります。
このシナリオでは、プロビジョニングされた CPU 数は 12 ではなく 14 でしたが、エンドユーザー エクスペリエンスも有意義な改善が見られ、平均レスポンス時間は、前のシナリオの 398 ミリ秒に対して 325 ミリ秒に、同様に P95 のレスポンス時間は 750 ミリ秒に対して 598 ミリ秒になりました。
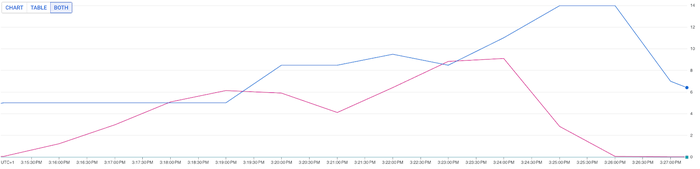
結果の比較
合成テストにおける各シナリオの比較を見てみましょう。
注: テスト結果は HPA とリソース リクエストが最適化に与える影響を概念的に理解するために提供されており、いかなる種類のベンチマークまたは保証を示すものではありません。
トレードオフの理解
HPA を最適化に関しては、効率とパフォーマンスの間に微妙なバランス関係があります。重要なのは、CPU 使用率と、スケールアップ時のパフォーマンス低下(P95)の最適なバランスを見つけることです。これは、以下のような要素の組み合わせ(多くの場合、制御不能)によって左右されます。
-
指標のスクレイピングの頻度: 指標の種類やベンダーによって異なります。
-
トラフィック パターン: 特定のシナリオにおいてトラフィック急増がどの程度であるかを示します。
-
ワークロードの反応性: 負荷が増加した場合に指標の変化(CPU 使用率など)が現れる線形性と速度のことです。
万能のアプローチは存在しないため、こうした要素の測定が非常に重要になります。また、本番環境にどのような戦略を導入する場合でも、その前に必ずワークロードのパフォーマンス テストを実施すべきであることは言うまでもありません。
前述のシナリオからわかるように、コスト パフォーマンスに優れたアプローチとは、70% や 80% といった CPU 目標値をテストしてみることです。ワークロードが使用率の増加に耐えられるとすると、これには以下のような利点があります。
-
費用削減: Pod 数が少ないということはリソースの総リクエスト数が減るということであり、全体的な請求額が最小限に抑えられます。
-
バースト処理が許容可能: 目標を高くすることで、既存の Pod 内でトラフィックのバーストに対応できる余裕が生じ、スケーリング イベントの頻度と強度が軽減されます。
-
さらなる最適化の可能性: 反対に、使用率の目標値が高く、小さいサイズの Pod のほうが、負荷がかかった状態でのパフォーマンスが向上する場合があります。その結果、HPA アルゴリズムの決定にも影響を与え、より効果的なスケールアップを実現できる可能性があります。
HPA 最適化の代替戦略
自動スケーリング戦略を最適化する究極のソリューションとは、効率とパフォーマンスを最大化するバランスの取れたアプローチです。さまざまな戦術を組み合わせることで、特定のワークロードに最適な平衡状態を実現できます。こうした手法に加え、以下の項目も検討する必要があります。
-
スケールアップとスケールダウンの動作の構成: HPA のクールダウンを利用して、インスタンス保持の長期化やスケールダウンの迅速化を図ることができます。これにより、トラフィック急増時の安定性を維持し、不要なリソースの消費を抑えられます。詳細はこちらをご覧ください。https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#configurable-scaling-behavior
-
外部指標またはカスタム指標に基づくスケーリング: HPA のスケーリングの決定をよりきめ細かく制御するために、CPU やメモリの使用率指標と併せて、外部指標やカスタム指標を利用できます。これにより、お客様独自のアプリケーション要件に合わせて自動スケーリングを調整できます。その好例として、ロードバランサからの指標を使用したトラフィックに基づくスケーリングが挙げられます。その際のヒントをご紹介します。https://cloud.google.com/kubernetes-engine/docs/concepts/traffic-management#traffic-based_autoscaling
しかし、最終的に HPA の動作を最適化する鍵は、ワークロードのプロファイルを理解し、継続的なテスト、モニタリング、調整を含む反復プロセスを通じて、適切なノードサイズを選択することにあります。このバランスの取れたアプローチが、GKE クラスタの効率性、パフォーマンス、スケーラビリティを実現する最善の方法です。

